データベースとは
データベース(DB:Data Base)
「データの基地」→使用するデータを管理
データモデル
データベースを設計するとき: 実世界のデータの集まり → データベースで利用できるように整理
- 種類
- 階層モデル(木構造)
- ネットワークモデル(網状)
- 関係モデル(2次元の表)
関係モデル
データの関係を数学モデルで表現したもの → これをコンピュータに実装=関係データベース
<関係モデルと関係データベースの対応表>
| 関係モデル | 関係データベース | |
|---|---|---|
| 関係 | Relation | 表・テーブル |
| 属性 | Attribute | 列・項目・カラム |
| タプル(組) | Tuple | 行・レコード |
| 定義域 | Domain | 整数型・文字列型 |
* 定義域 : = データ型
関係データベース(リレーショナルデータベース)
「表」でデータを管理するデータベース
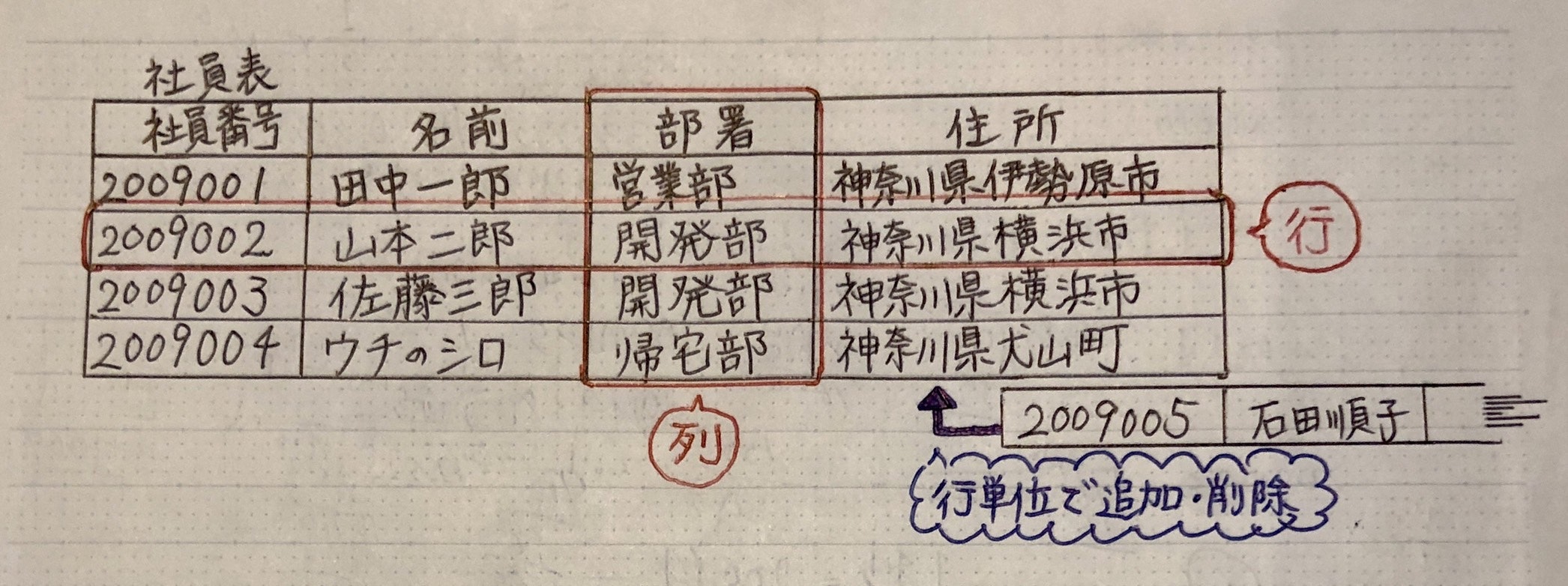
| 表(テーブル) | 複数のデータを入れる場所 |
| 行(レコード) | 1件分のデータ |
| 列(カラム) | データの項目 |
複数の表を「列の値」で関係づけて管理
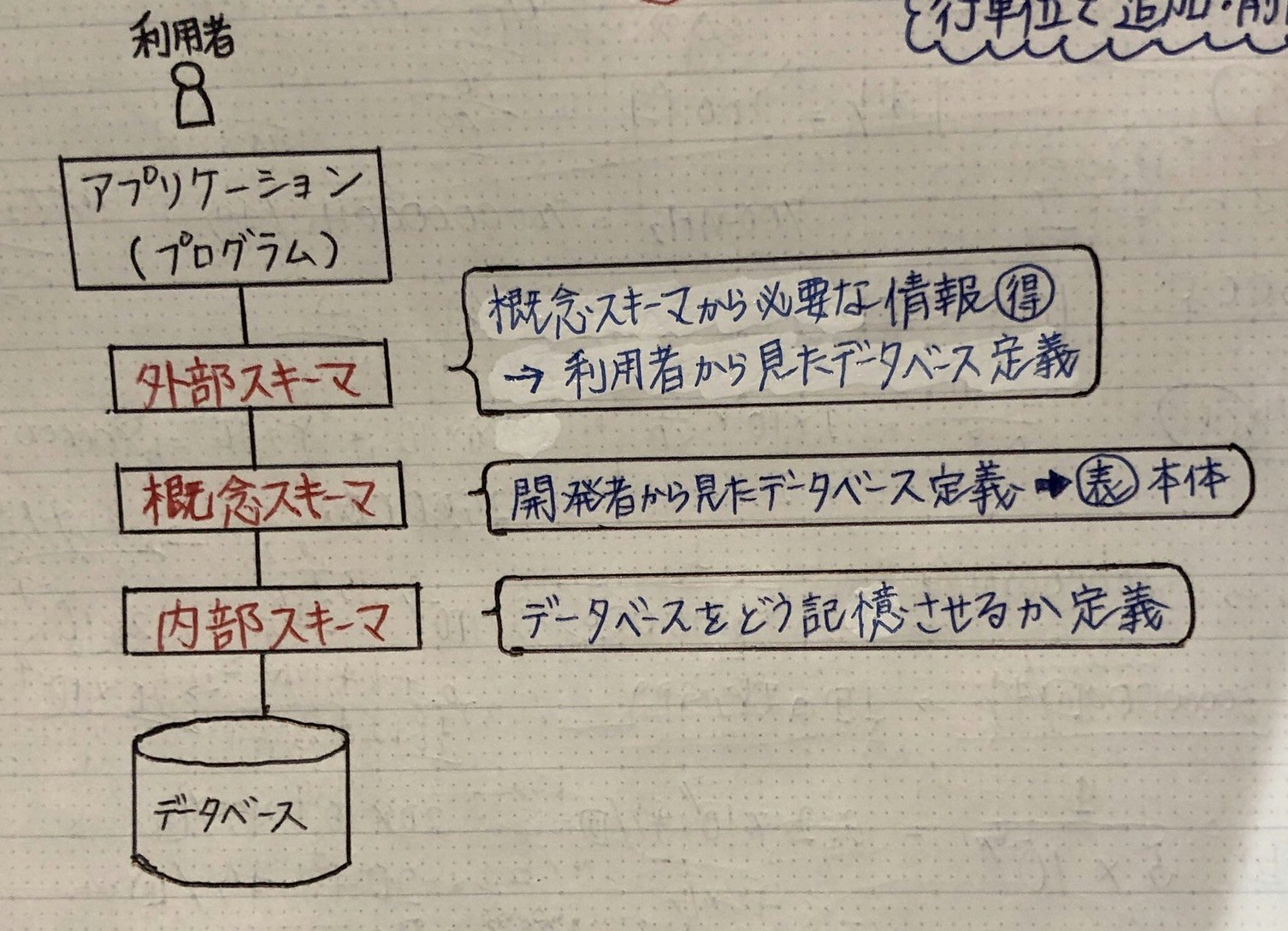
スキーマ(概要)
データ自体・データ間の関係を定義 → スキーマを使ってDBの構造を定義
→ コンピュータにデータベースを実装するため
※ 3層スキーマ : 「外部・概念・内部スキーマ」に分けて定義
→同じデータベースを視点の違いで定義
データベース管理システム(DBMS:Data Base Manegement System)
データベースを管理するソフトウェア(データの追加/検索/更新/削除...)
* 再編成
- DBの変更操作が繰り返す
- データの物理的な格納位置が不規則になる、削除領域が使えなくなる
- これを修復して、アクセス性能を向上させること
データベースの設計
対象を分析するとき、まずはE-R図を使う。→ E-R図をもとに表を設計
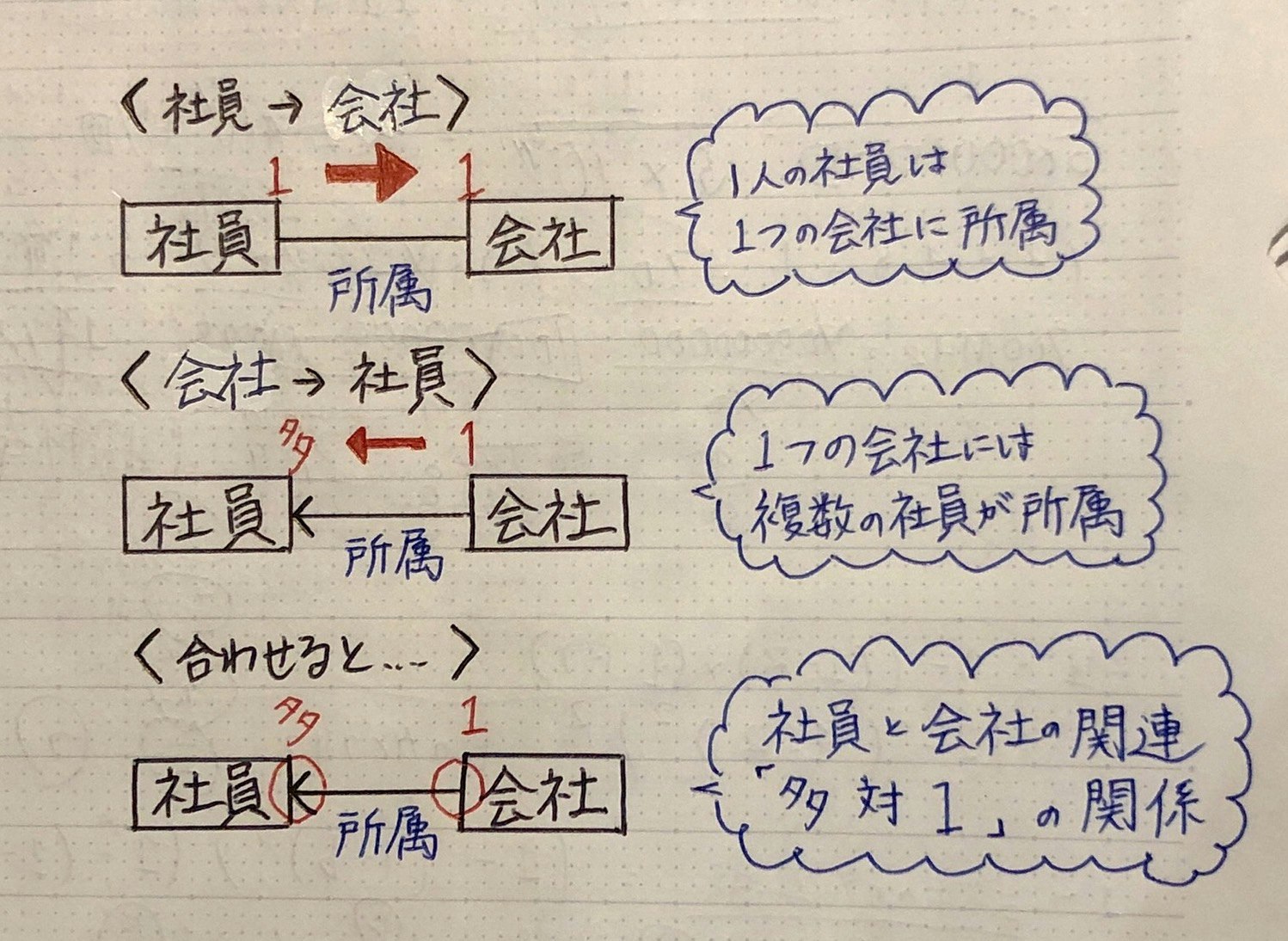
E-R図
実体(人・物・場所)と実体同士の関連を表した図
→ 実体:エンティティ(Entity)
→ 実体同士の関連:リレーションシップ(Relationship)
→ 矢印の有無・方向で関連を示す
(社員100人の会社をER図化)
実体:社員・会社
関連:所属
表の設計
「主キー&外部キー」検討 → データの正規化
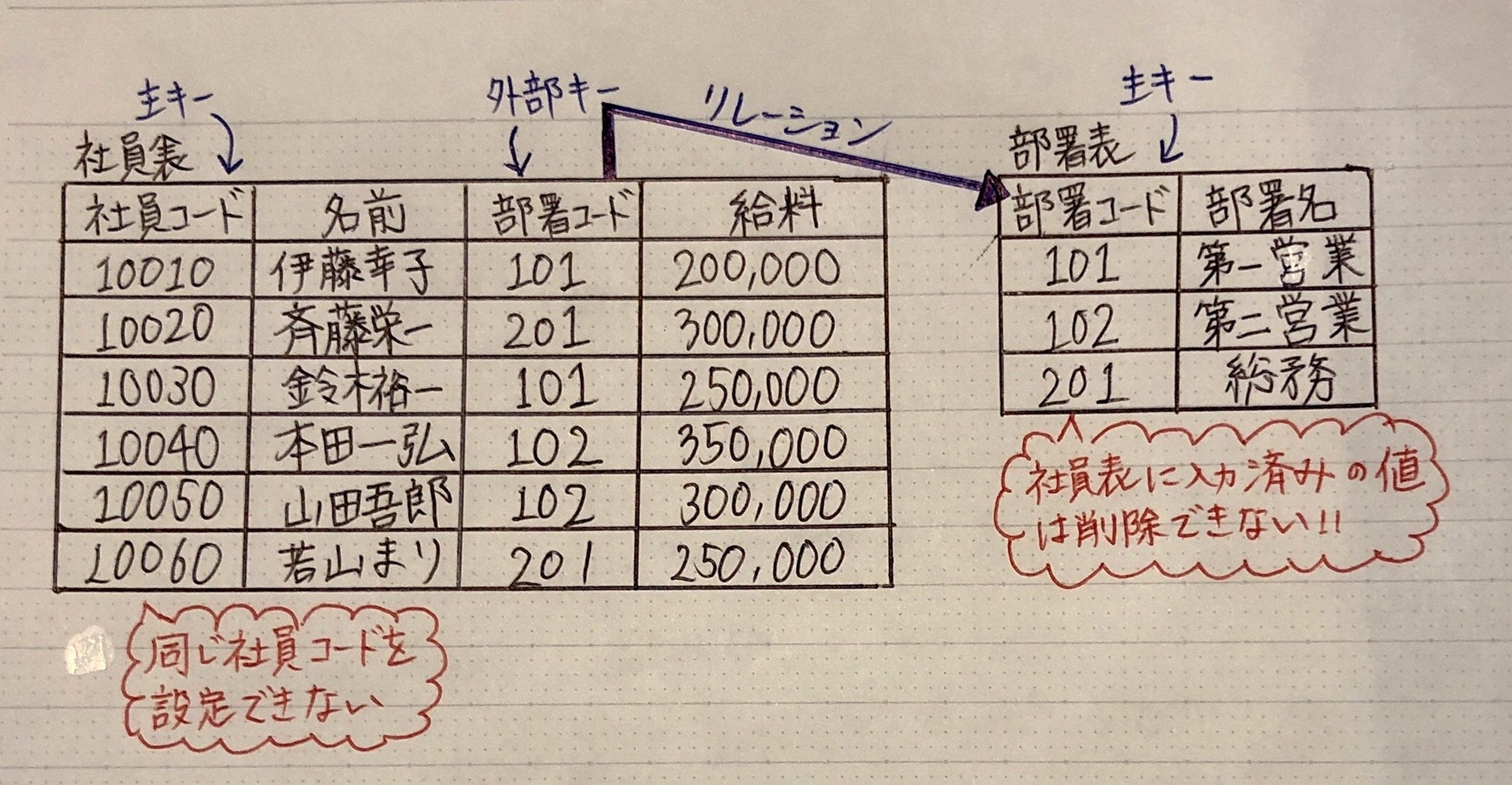
主キー & 外部キー
表同士に関係を持たせる・データを特定するための鍵
主キー(Primary Key)
表中の行を特定する列
(特徴)
一意制約:主キーの値が同じ行はない
非NULL制約:必ず値が存在する
外部キー(Foreign Key)
他の表の主キーを参照してる列
(特徴)
参照制約:データに変更があった時、参照に矛盾がないようにする
→ 外部キーによって参照されてる行は削除できない
※ リレーション: 表同士を関連づけること
※ インデックス: データの場所を示したもの
- 大量のデータから検索するときの検索項目
- インデックスにした場合
- 検索時間 短い & 一定した時間内に収まる
- データ追加/削除 多い → インデックスの更新もあるので、処理時間は遅くなる
- インデックスにした場合
データの正規化
データが重複しないように、表を分けること
(正規化の手順)
非正規形 → 第1正規形 → 第2正規形 → 第3正規形
(受注伝票)
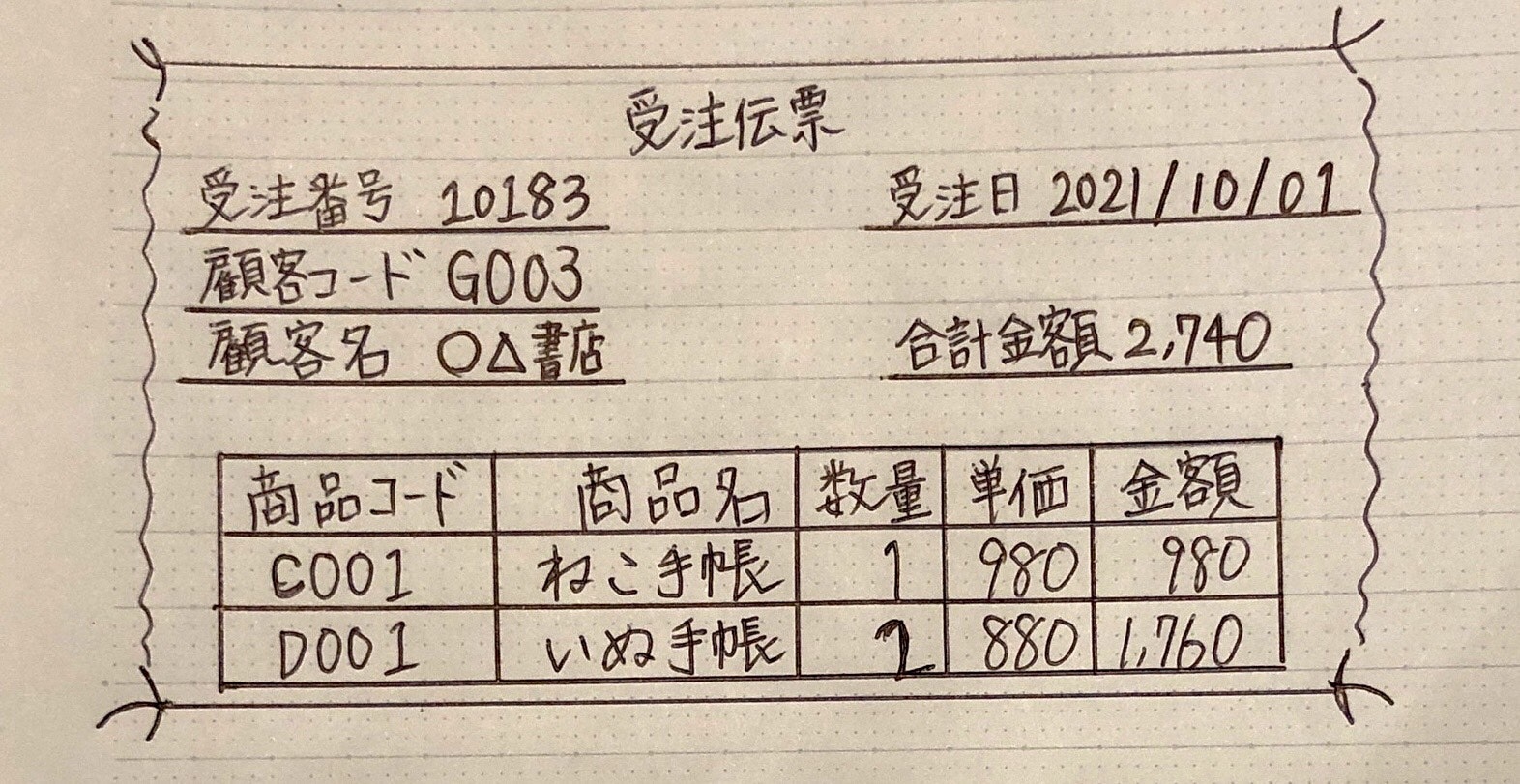
非正規形
正規化されていない表

第1正規形
- 繰り返し項目を分割
- 主キーを見つける
-
表同士の関係づけをする

* 受注伝票は複数ある
→ 受注番号だけでは一意に決まらない
→ 「商品コード」も主キーに
→ 複合主キー : 複数の列を組み合わせて、主キーにする
第2正規形
-
主キーの片方で決まる項目を分割
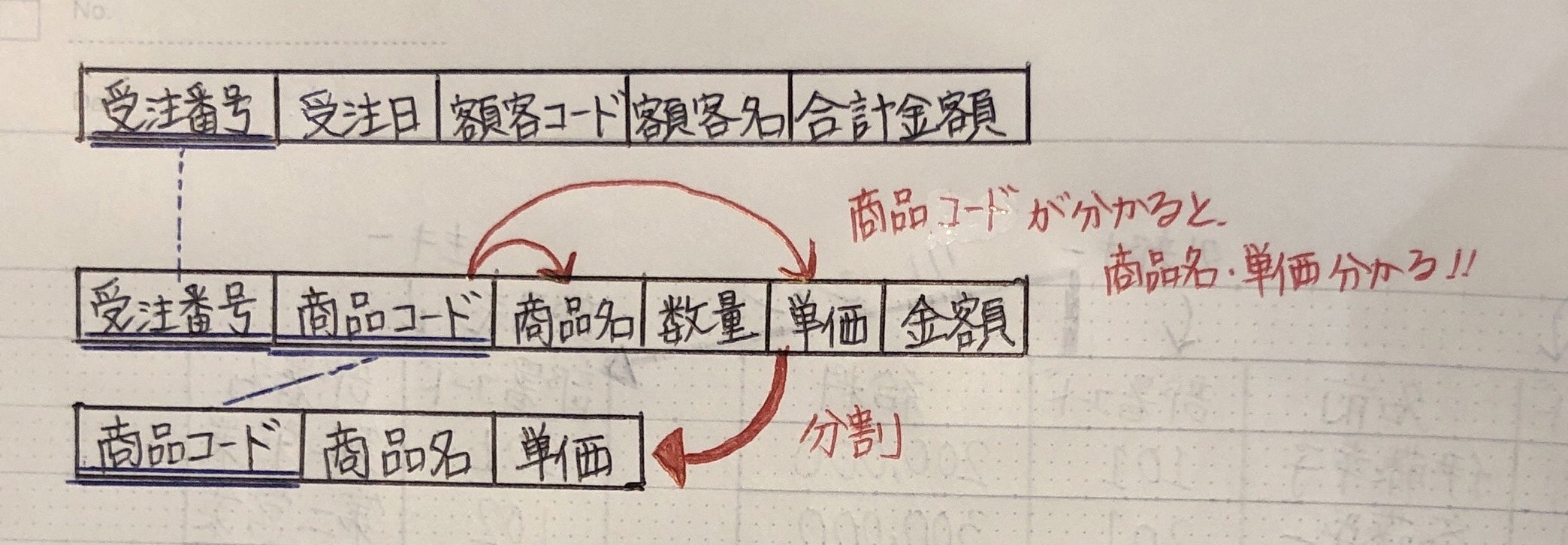
第3正規形
- 主キー以外の項目で決まる項目を分割
-
計算で求められる項目を消す
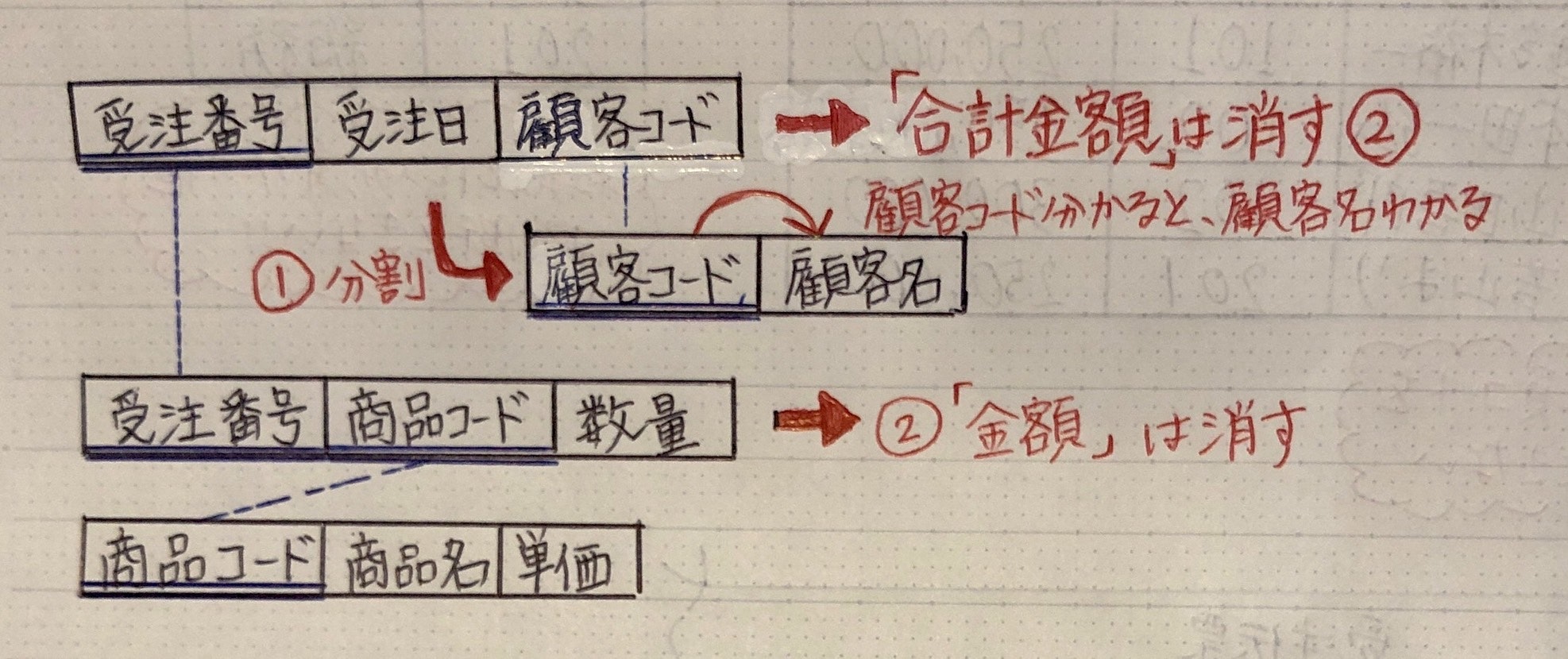
※ 完全関係従属:主キーによって、項目が決まる
※ 推移的関係従属: 主キー以外の項目によって、項目が決まる
トランザクション処理
データベースの処理のかたまり
→ データの更新処理:トランザクション単位で行う
ACID特性 : トランザクションに求められる4つのこと
| 原子性(Atomicity) | トランザクション処理:「全て実行」or「全く実行せず」で終了 |
| 一貫性(Consistency) | データベースの内容に矛盾がないこと |
| 独立性(Isolation) | トランザクション「複数」or「一つ」で実行→処理結果は同じ |
| 耐久性(Durability) | トランザクション正常終了→更新結果は消えない |
排他制御
データ更新中:他のトランザクションから更新されないようにする=アクセスをロック(排除)
→ 目的:データの不整合を防ぐ
(ロックしない状態)
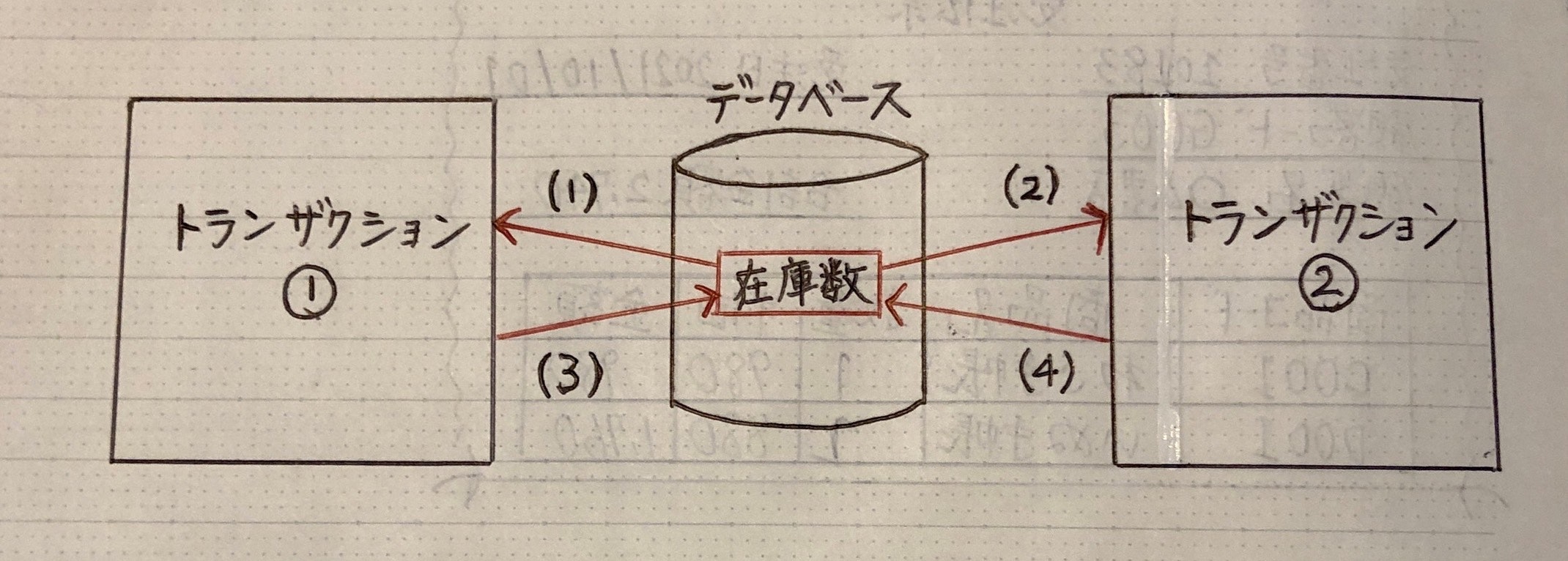
⑴ トランザクション①:在庫数アクセス(在庫数:100個)
⑵ トランザクション②:在庫数アクセス(在庫数:100個)
⑶ トランザクション①:データ更新処理(在庫数:100 - 20 = 80個)
⑷ トランザクション②:データ更新処理(在庫数:100 - 30 = 70個)
* 在庫数 70個(本来50個でないといけない)
→ 不整合が生じている
(ロックした状態)
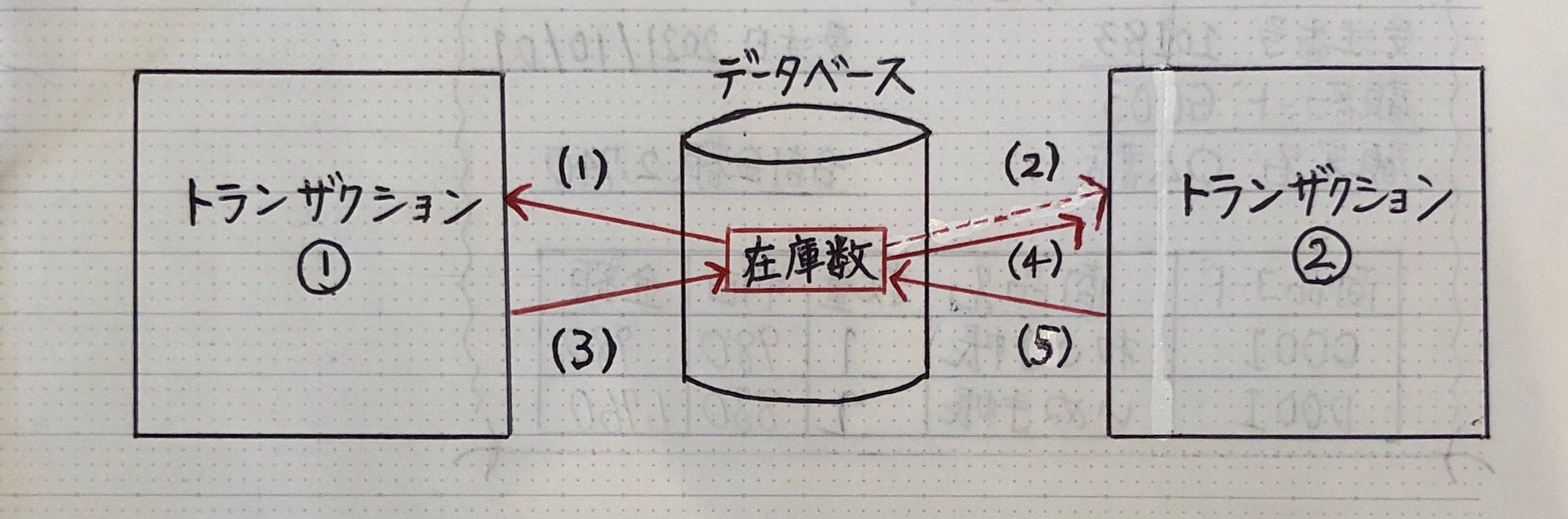
⑴ トランザクション①:在庫数アクセス(在庫数:100個)→ 他トランザクションからのアクセスをロック
⑵ トランザクション②:在庫数アクセス→ ロック状態なので待ち状態になる
⑶ トランザクション①:データ更新処理(在庫数:100 - 20 = 80個)→ ロックを解除する
⑷ トランザクション②:在庫数アクセス(在庫数:80個)→ アクセスをロック
⑸ トランザクション②:データ更新処理(在庫数:80 - 30 = 50個) → ロックを解除する
共有ロック & 専有ロック
共有ロック
データを読み取る時に使う
→ 他のトランザクション:データを読み取れる・更新できない
専有ロック
データを更新する時に使う
→ 他のトランザクション:データを読み込めない・更新できない
ロックの粒度(範囲)
・ ロックの粒度を大きくする(ロック範囲大):他トランザクションの待ち状態が多くなる
→ 全体のスループット低下
・ ロックの粒度を小さくする(行単位でロック):待ち状態が少なくなる↔︎管理するロック数が増える
→ DBMSのメモリ使用:増加
デットロック
複数のトランザクション : お互いに相手が使いたいデータをロック
→ お互いがロック待ち状態
→ (デットロックを解消する方法)片方のトランザクションをロールバック
2相コミットメント
分散型データベース:物理的に別れている複数のデータベース→見かけ上1つのデータベースとして扱えるシステム
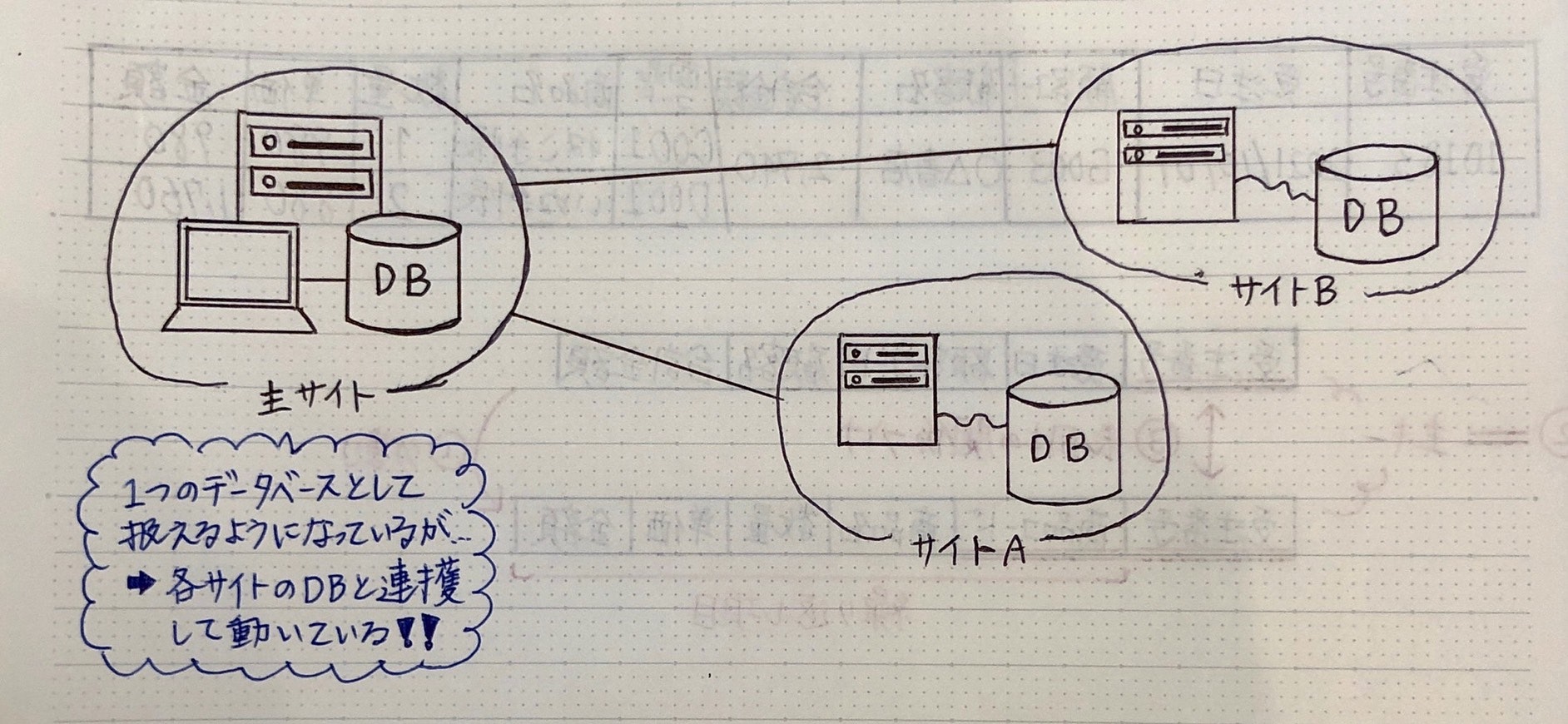
(2相コミットメントの仕組み)
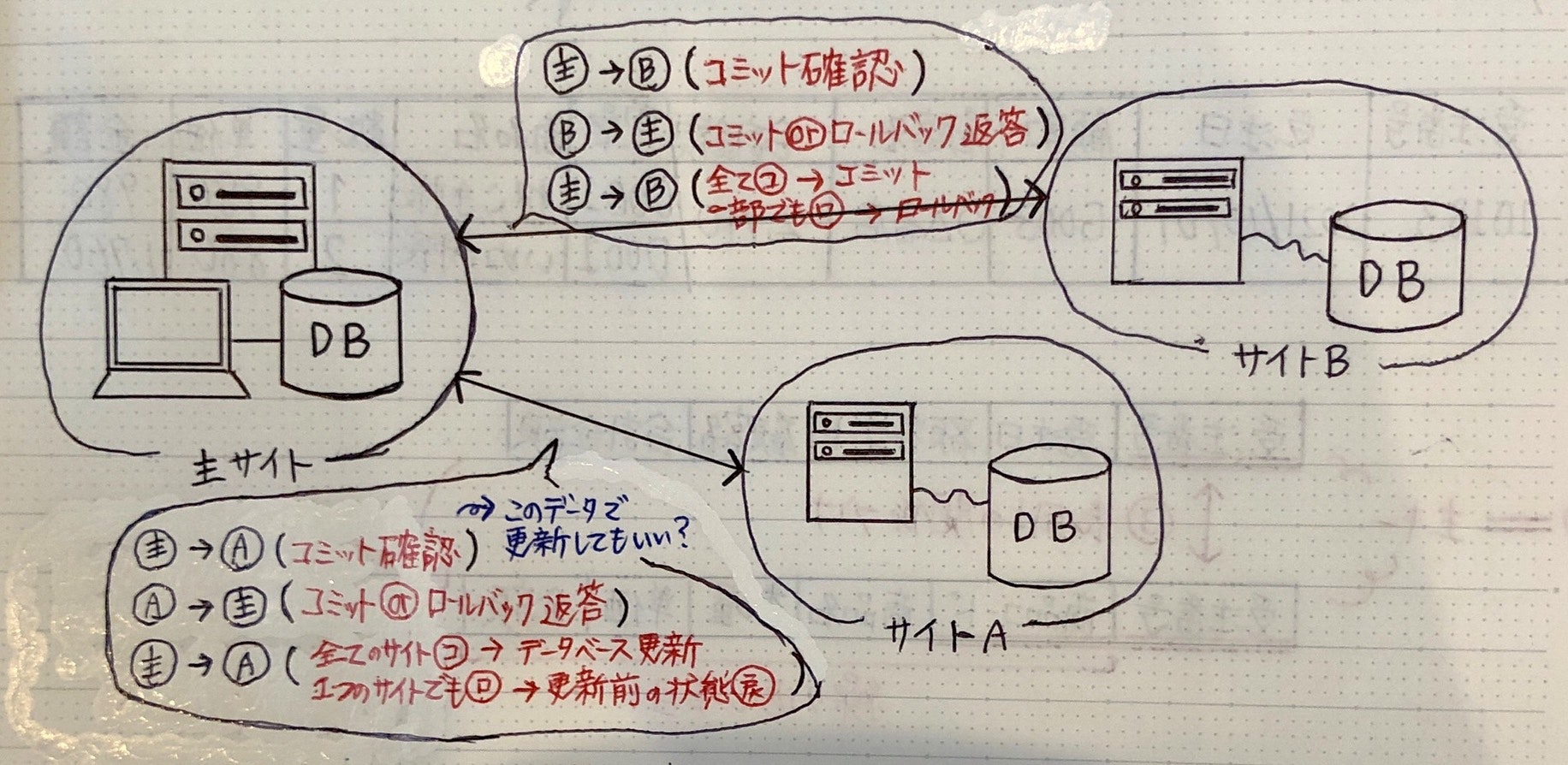
* 2相コミットメント
→ コミット or ロールバックの確認
※ アクセスの透過性: 使う資源が遠い or 近い どちらでも、利用者は気にせずアクセスできること
データベースの障害回復
障害回復で使うファイル
・ フルバックアップファイル:DBの全データをバックアップ
・ ログファイル(ジャーナルファイル):DBの更新記録
→ 更新前ジャーナル:更新前の状態を記録
→ 更新後ジャーナル:更新後の状態を記録
障害回復する処理
ロールフォワード
(データベースのハードウェアなどの障害時)
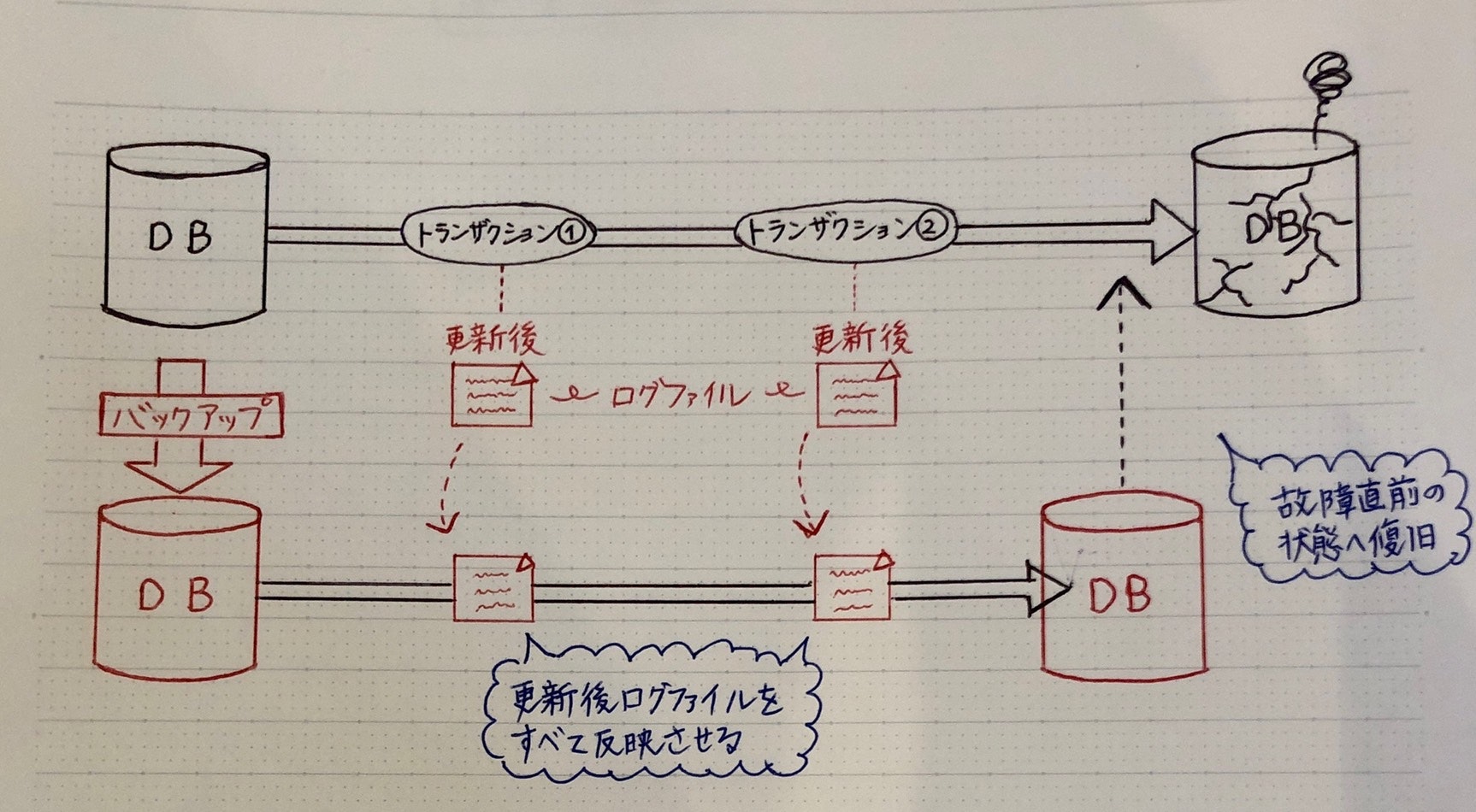
* フルバックアップファイル + 更新後ログファイル
→ DB復旧
ロールバック
(トランザクション処理中 → 障害発生)
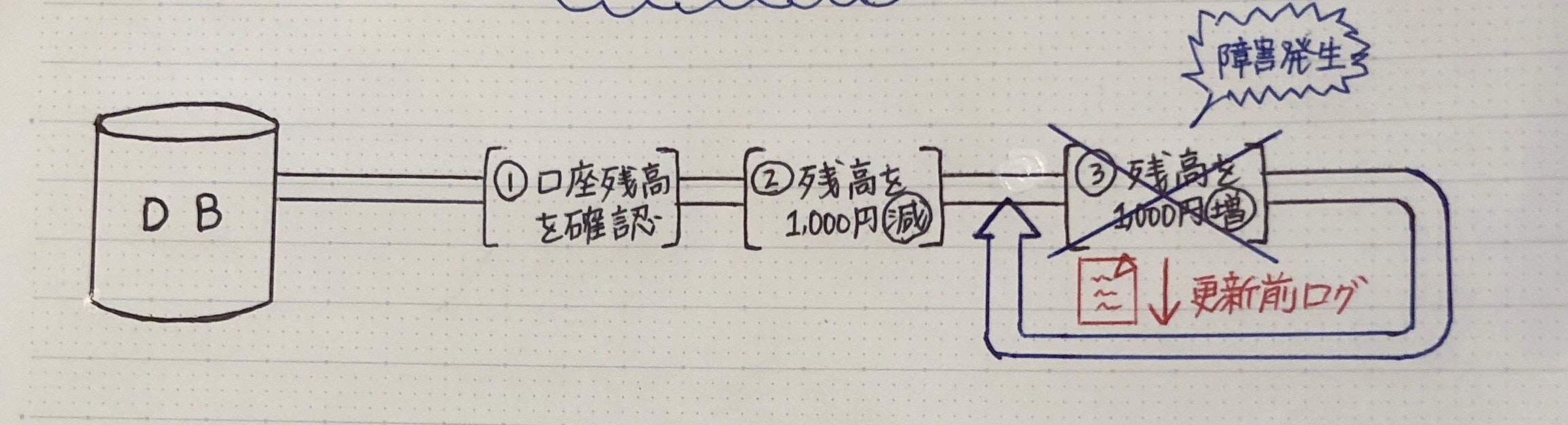
* 更新前ログファイル → DB復旧(トランザクションを無効にする)
チェックポイント
(DBMS:トランザクション → DB反映までの流れ)
- トランザクションがコミット
- 更新情報 → メモリ上の「バッファ」「ログファイル」に書き出す
- 「チェックポイント」のタイミング:「バッファ」 → 「DB」 まとめて更新
* システム障害:「バッファ」上のデータ消失
→ 「チェックポイント時のデータ」 & 「ログファイル」→ データ復旧
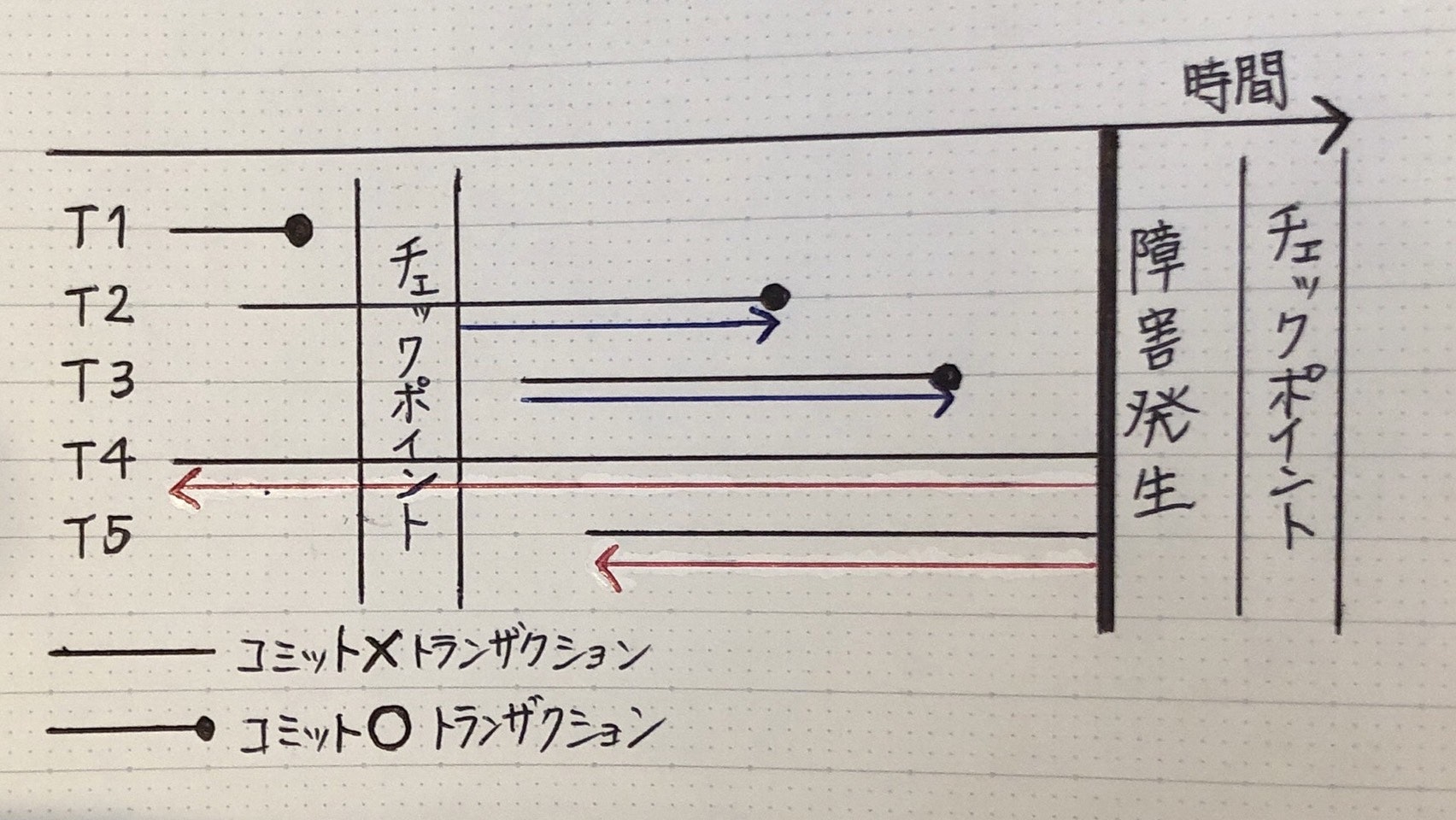
- T2・T3:「更新後ログファイル」→ 障害発生直前まで回復(ロールフォワード)
- T4・T5:「更新前ログファイル」→ トランザクション開始時点まで回復(ロールバック)
- T1:「チェックポイント」時にコミット終了 → バッファに何もないため、回復対象ではない
※ システム障害時の対応
| 名前 | システムの電源 | 対応 |
|---|---|---|
| ウォームスタート | 切らない | ログの更新情報で処理再開 |
| コールドスタート | 切る | システムを初期状態にして処理再開 |
データの操作(SQL)
SQL
DBの表を定義、データを操作する言語
→ データ定義言語・データ操作言語の2種類
データ定義言語(DDL:Data Definition Language)
データベース・表を定義する言語
表の定義
- 3層スキーマ:概念スキーマ
- 記憶媒体:実表(基底表)
| 構文 | 意味 |
|---|---|
| CREATE TABLE 表名(列名 データ型) | 表を作成 |
| PRIMARY KEY | 主キー設定 |
| FOREIGN KEY(列名) REFERENCES 表(列名) | 外部キー設定 |
| UNIQUE(列名) | 一意制約つける |
| CHECK(列名 条件) | 値に条件つける |
| NOT NULL | NULL禁止 |
| CREATE VIEW 表名 | ビュー作成 |

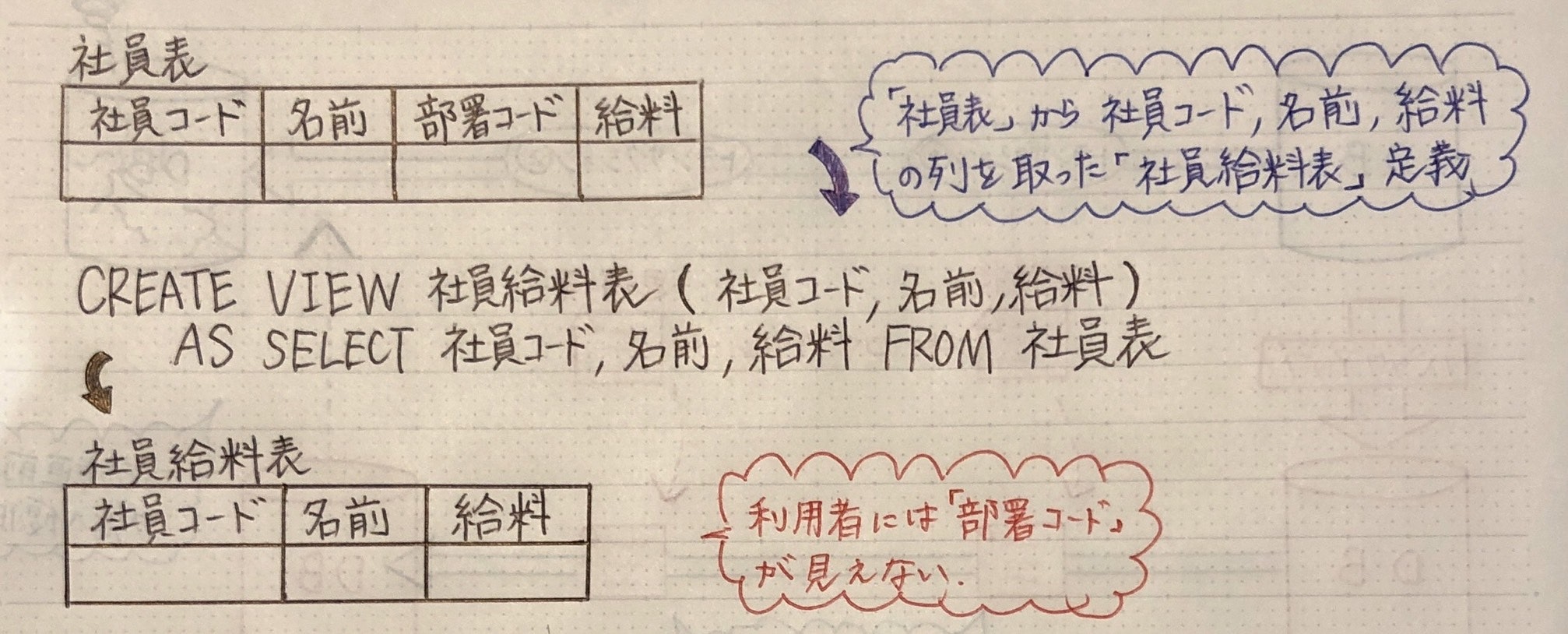
ビューの定義
ビュー : 実表から必要な部分を取り出す → 一時的に作成した表
→ 利用者にビューを提示できる
→ 3層スキーマ:「外部スキーマ」にあたる
→ 仮想表 : ハードディスには存在しない
データ操作言語(DML:Data Manipulation Language)
データ抽出・挿入・更新・削除をする言語
SELECT文
SELECT文:データを抽出する
→ データを抽出:問合せ (クエリ)
(基本文型)
| SELECT 列名1, 列名2 | 抽出する列 |
| FROM 表名1, 表名2 | どの表からか |
| WHERE 条件式 | 抽出する条件 |
射影
列を抽出
SELECT 品名 FROM 商品表;
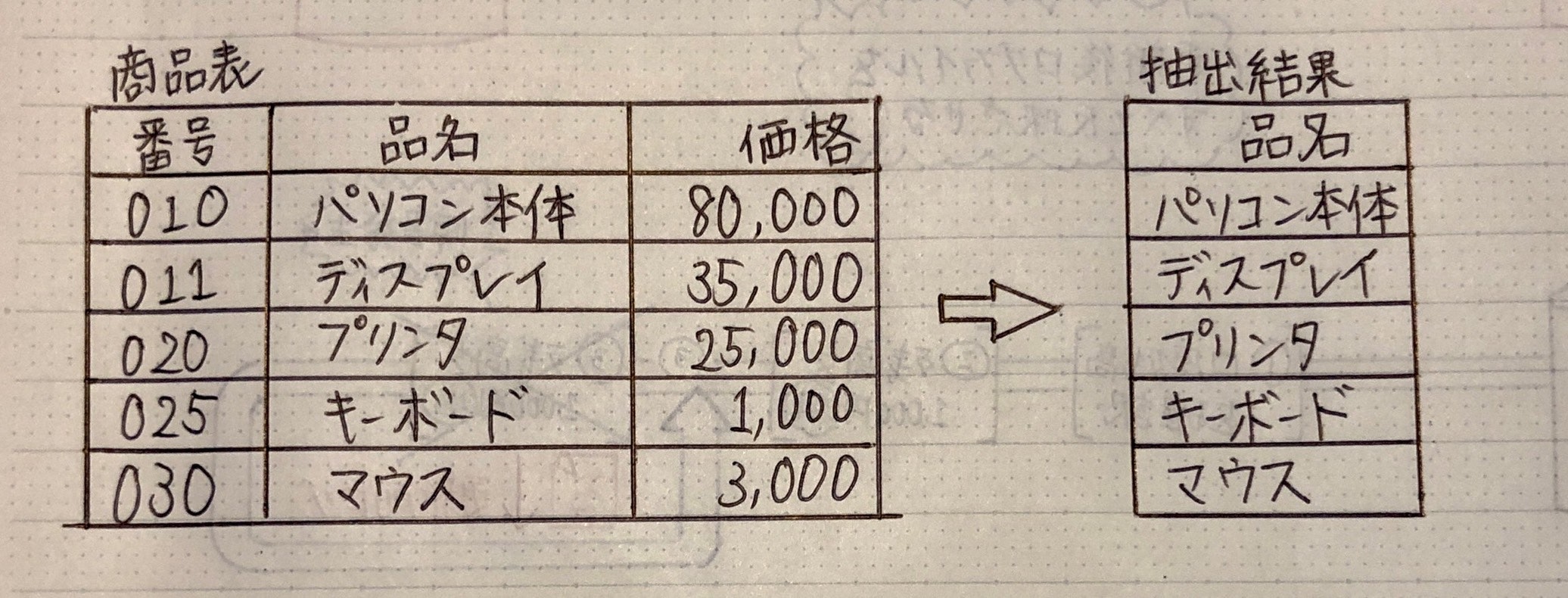
選択
条件にあう行を抽出
(条件式で使う演算子)
| 注意構文 | 意味 |
|---|---|
| A <> B | AとBは等しくない |
| A AND B | AかつB |
| A OR B(IN (A, B)) | AまたはB |
| NOT A | Aではない |
*優先順位:NOT → AND → OR
→ ()で変更できる
例)商品表から番号が、010,020,020の商品情報(全ての列)を抽出
SELECT *(番号,品名,価格) FROM 商品表
WHERE 番号='010' OR 番号='020' OR 番号='030';
(WHERE 番号 IN('010','020','030')) → 「OR」の代わりに「IN」
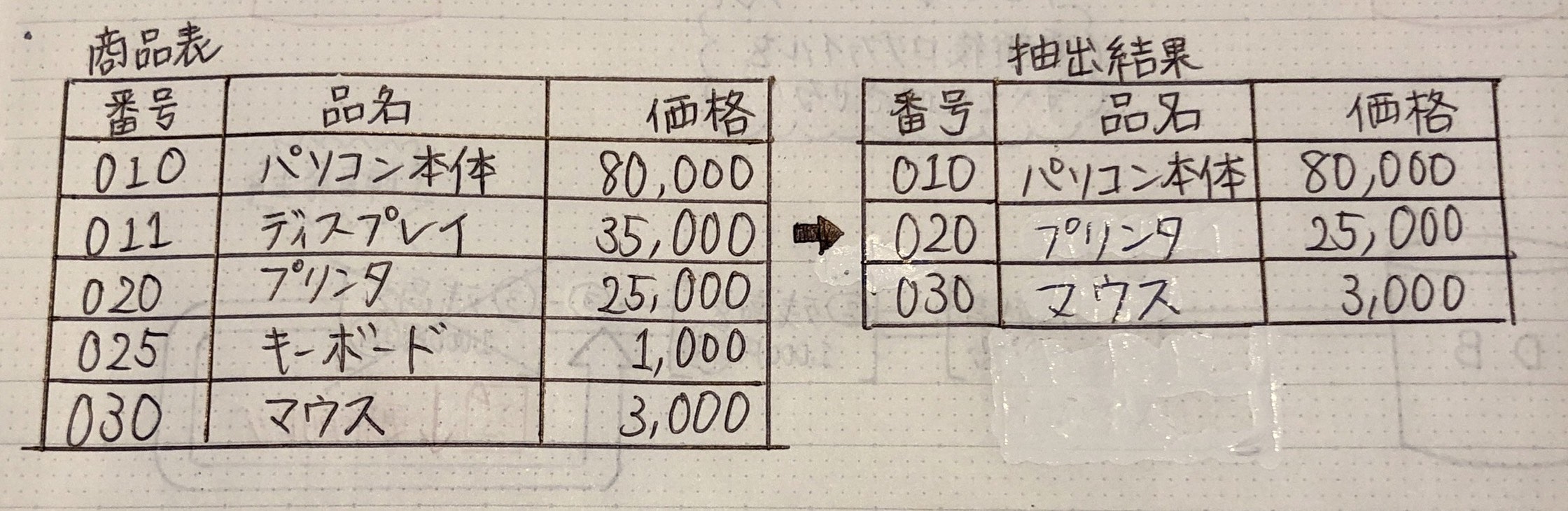
例) 商品表から、価格が1万円以上5万円以下の商品情報を抽出
SELECT * FROM 商品表
WHERE 価格>=10000 AND 価格<=50000;
(WHERE 価格 BETWEEN 10000 AND 50000;) → 「AND」の代わりに「BETWEEN」
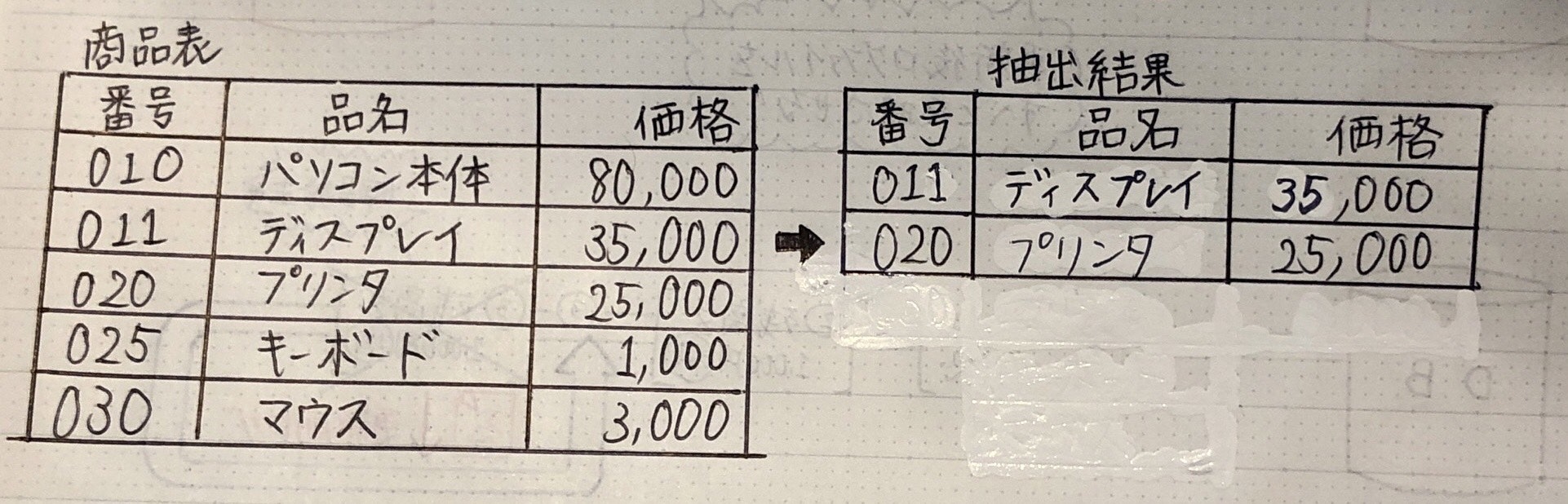
結合
二つ以上の表をくっつける → 一つの表にする
FROM:抽出する表を指定
WHERE:表間をどの列で結合するか指定
* 複数の表に同じ列名がある場合の区別
→ 「表名.列名」
例)受注表と商品表を結合・顧客名、商品名、単価を抽出
SELECT(DISTINCT) 顧客名, 商品名, 単価 FROM 受注表, 商品表
WHERE 受注表.商品番号 = 商品表.商品番号;
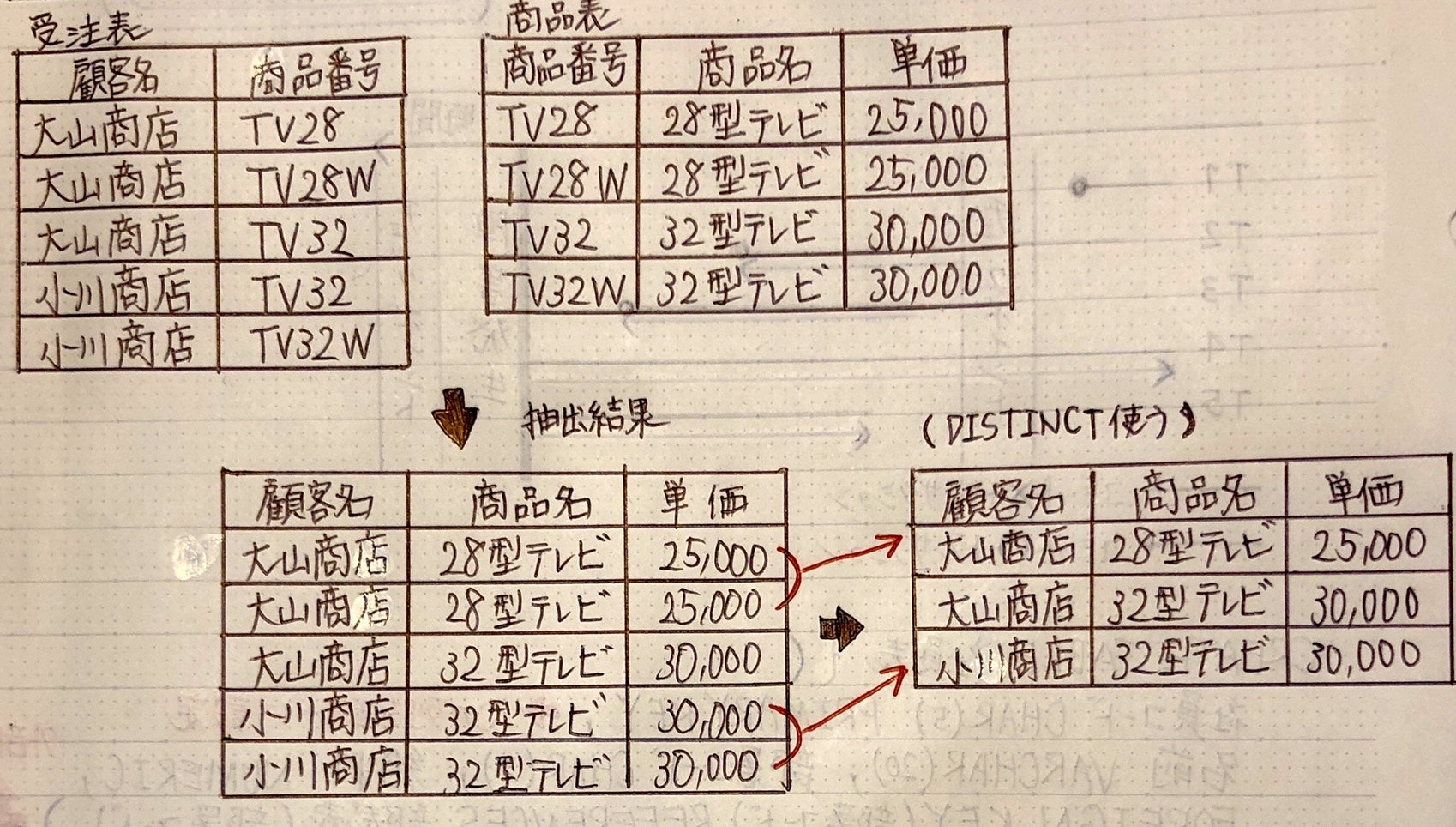
* DISTINCT : 重複行を一つにまとめる
* WHERE句 : LIKE → 文字列の一部が一致する行を抽出(ワイルドカード)
- % : 0文字以上の文字列
- ー : 1文字の文字列
SELECT * FROM 社員表
WHERE 氏名 LIKE '% 三 %'; → 社員表の氏名に「三」を含む社員情報を抽出
(氏名 LIKE '三%') → 氏名の最初が「三」で始まる
(氏名 LIKE '% 三') → 氏名の最後が「三」で終わる
SQL〜並べ替え・グループ化〜
並べ替え
ORDER BY 列名 ASC(DESC) : 列を昇順(降順)に並べ替える
例)日付:昇順、同じ日付の中:数量の降順 並べ替え
SELECT * FROM 出庫記録
ORDER BY 日付 (ASC), 数量 DESC; → ASC省略可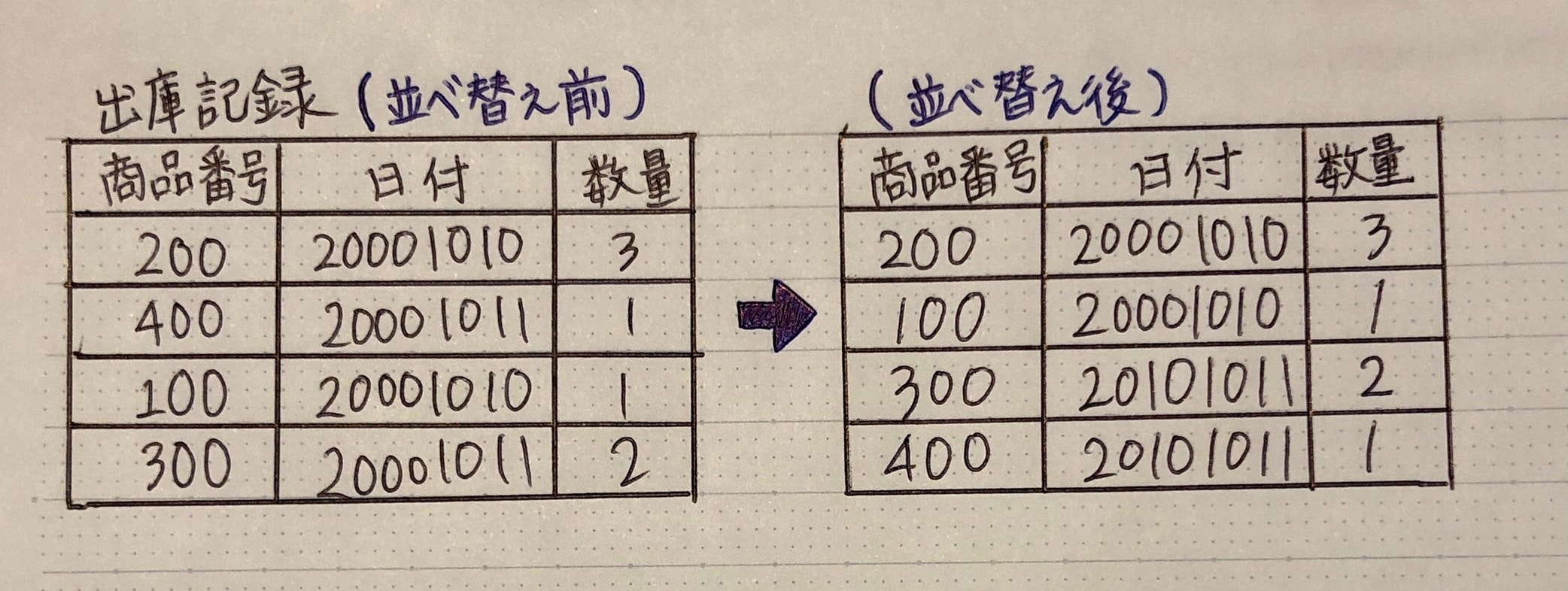
集合関数(集計関数)
指定した列の値を集計
| 関数 | 機能 |
|---|---|
| SUM (列名) | 合計 |
| AVG (列名) | 平均 |
| MAX (列名) | 最大値 |
| MIN (列名) | 最小値 |
| COUNT * | 指定した行数求める |
グループ化
GROUP BY 列名 : 列の値が同じ行をグループ化
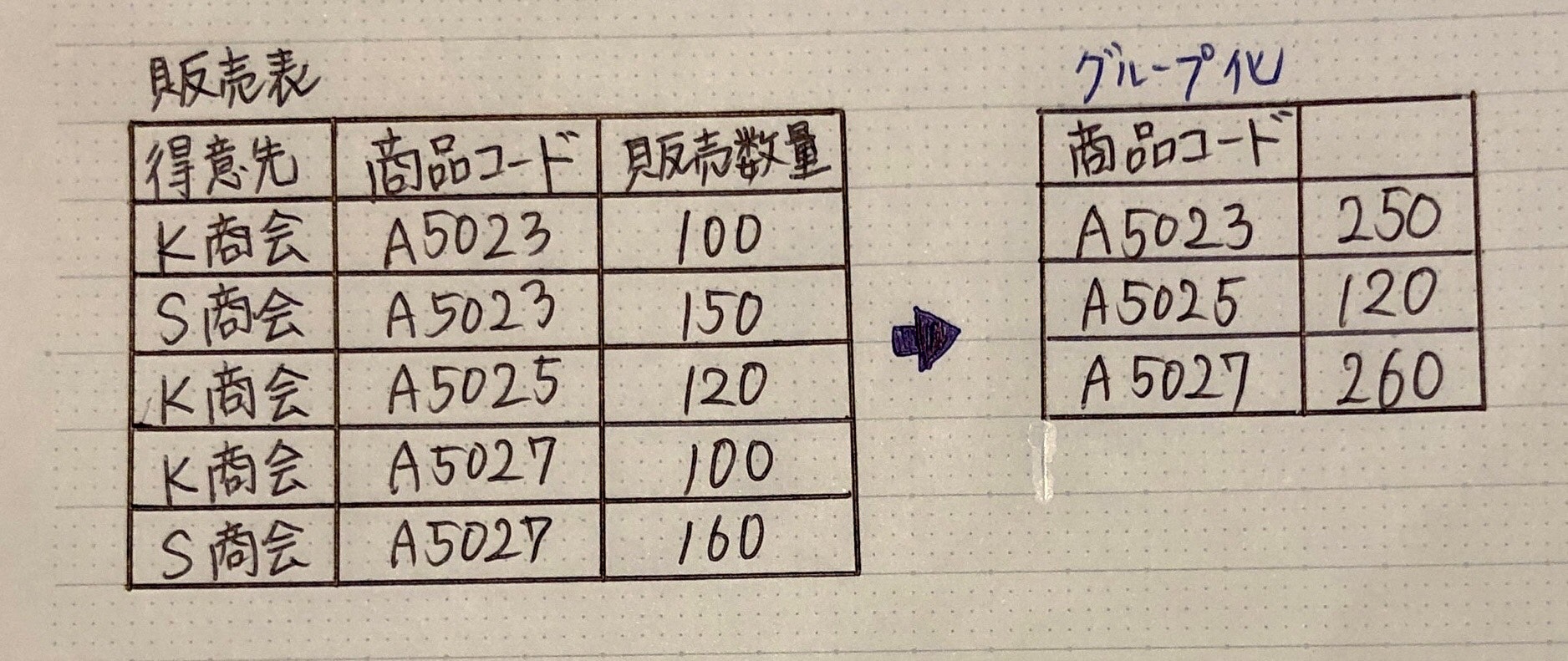
例) 販売表:商品コードごとの販売数量の合計、商品コード・販売数量の合計を抽出
SELECT 商品コード, SUM(販売数量) FROM 販売表
GROUP BY 商品コード;
* SELECT 直後の列名
→ 集合関数を除き、GROUP BYで指定した列名を入れる。
AS
集合関数で求めた列 → 別名つける
例) 上記で求めたSUM(販売数量)の列:別名つける
SELECT 商品コード, SUM(販売数量) AS 合計数量 FROM 販売表
GROUP BY 商品コード;

HAVING
グループ → 条件をつける
例) 販売表:商品コードごとの販売数量合計→250超える商品コード、販売数量の合計を抽出
SELECT 商品コード, SUM(販売数量) AS 合計数量
FROM 販売表
GROUP BY 商品コード HAVING SUM(販売数量) > 250;
| 商品コード | 合計数量 |
|---|---|
| A5027 | 260 |
SQL〜副問い合わせ〜
「SELECT文 WHERE」に「SELECT文」を組み込むこと
→ ①いったん抽出 ②結果を条件に再抽出
IN(NOT IN)
IN():()内に含まれる行を抽出
例) 社員表:IPスキル持つ社員情報を抽出
SELECT * FROM 社員表 ← 主問合せ
WHERE 社員番号 (NOT)IN(SELECT 社員番号 FROM 社員スキル表
WHERE スキルコード='IP'); ← 副問い合わせ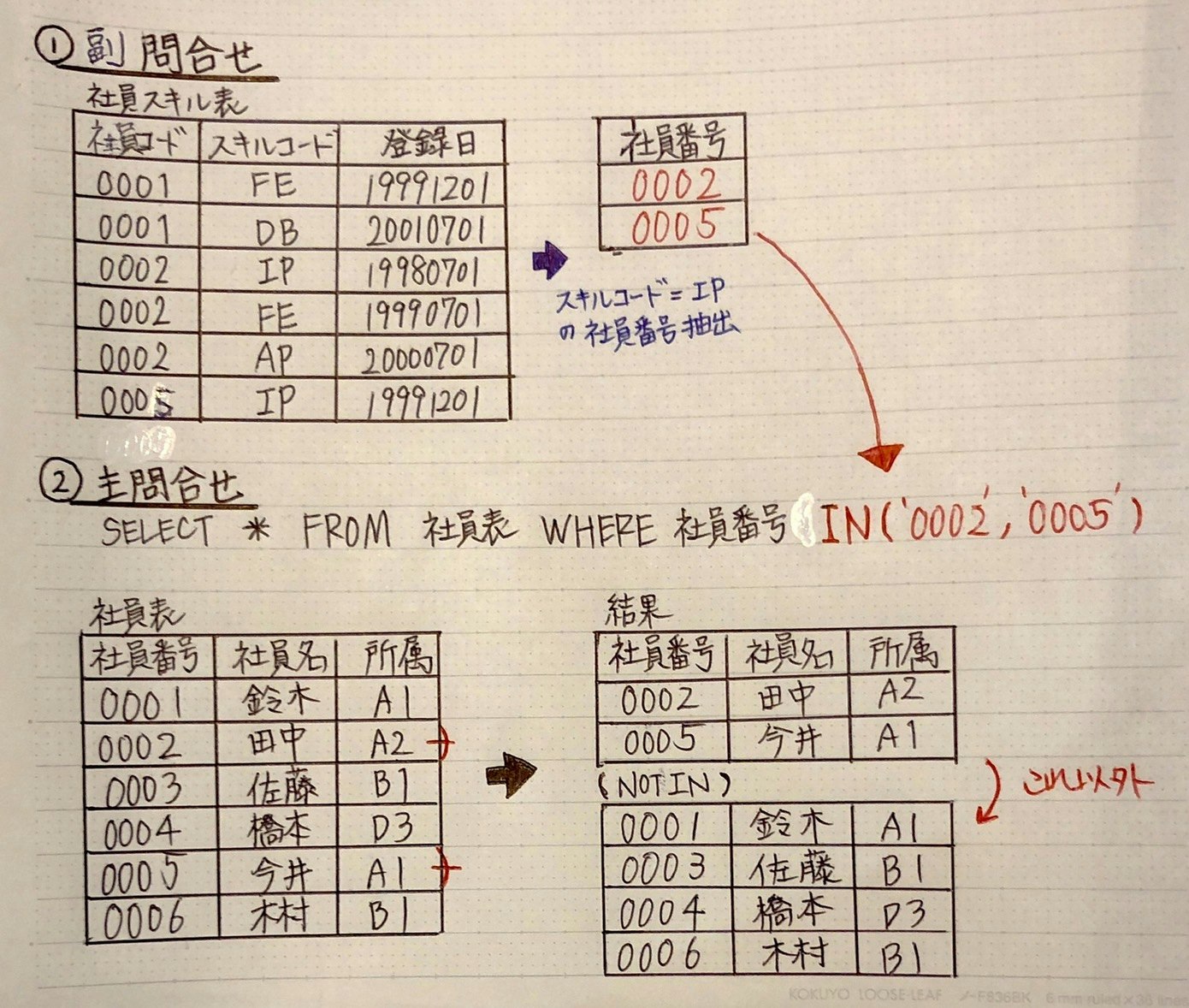
(NOT)EXISTS
- EXISTS():()内の行が存在=「真」、存在しない=「偽」
- NOT EXISTS():()内の行が存在しない=「真」、存在=「偽」
例) 上と同じ
SELECT * FROM 社員表 ←主問合せ
WHERE EXISTS(SELECT * FROM 社員スキル表 ←副問合せ
WHERE スキルコード='IP'
AND 社員表.社員番号=社員スキル表.社員番号);
(流れ)
- 主問合せ:社員表から1行目取り出す
- 副問合せ:社員スキル表「スキルコード=IP」かつ「社員番号が同じ」行が存在?? →「真」なら行を抽出
- ① ②の繰り返す
* 組込みSQL: プログラムの中にSQLを書く → プログラムからDB操作
データベースの応用
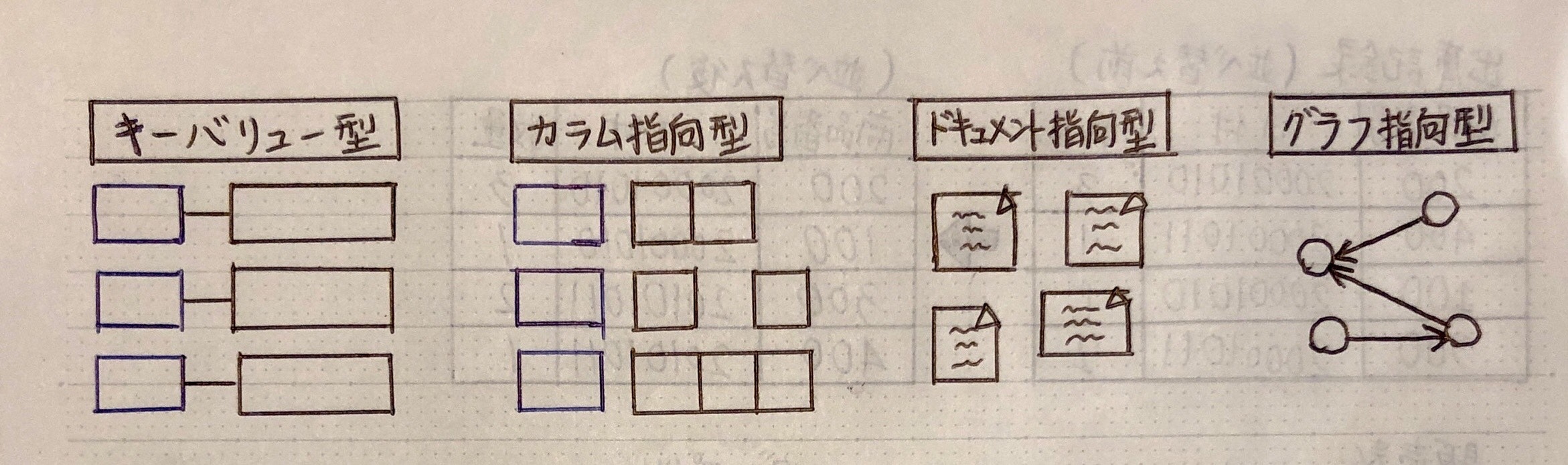
NoSQL(Not Only SQL)
SQLを使わず操作するデータベース全般
目的:ビックデータの保存・解析
| 種類 | 特徴 |
|---|---|
| キーバリュー型 | キー(一意に識別できる)& バリュー(データ) で管理 |
| カラム指向型 | キー → カラム(項目)を自由に追加できる |
| ドキュメント指向型 | ドキュメント1件(データ構造自由)=1データになる |
| グラフ指向型 | ノード間:リレーションでつなぎ構造化する |
データベースの応用
企業によるデータベースの有効活用
| データウェアハウス(wearhouse) | 企業の活動で得たデータ → 蓄積したDB |
| データレイク | データウェアハウスの一種。未処理・リアルタイムで蓄積 |
| データマート(mart) | データウェアハウスから抽出した目的別DB(利用者のため) |
| データマイニング(mining) | 大量のデータ→法則・因果関係を発掘 |
| BI(Business Intelligence)ツール | ビジネスで使える情報を取り出すツール |
ビックデータ
多様・高頻度に更新される大量データのこと
-
オープンデータ : 原則無償・二次利用可→公共・企業が公開するデータ
→ ビックデータ + オープンデータ = 色々な問題解決に寄与できる!
データ資源の管理
DBを活用 → 他のデータ資源管理も大切
- リポジトリ : ソフトウェア開発で使う、プログラム情報を管理するDB
- データディクショナリ : データ項目の名称・意味を登録してるデータ辞書