最近、ChatGPTの盛り上がりから、私が関わっている会社でもChatGPTの導入の話が進みました。
この会社では、以下のような環境を利用しています。
| 環境 | バージョン |
|---|---|
| React.js | 18.2.0 |
| TypeScript | 5.0 |
| npm openai | 3.2.1 |
開発するにあたってリポジトリから実際にコードを見て、
どんな型かを確認しながら開発していたこともあり、
その調べたことを記事にして置いておこうと思い書きました。
作ったサイトのイメージは以下です。
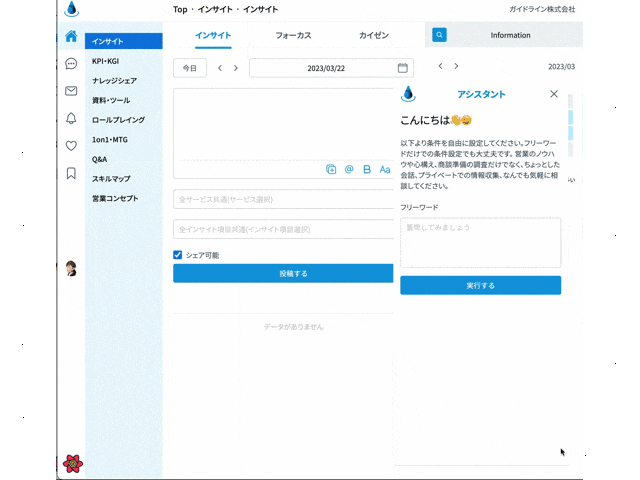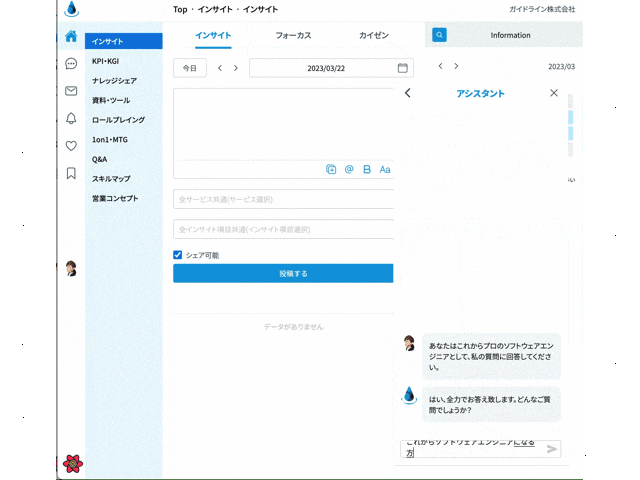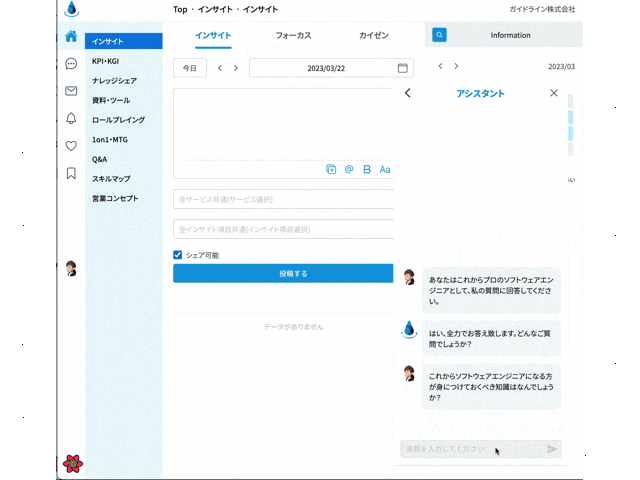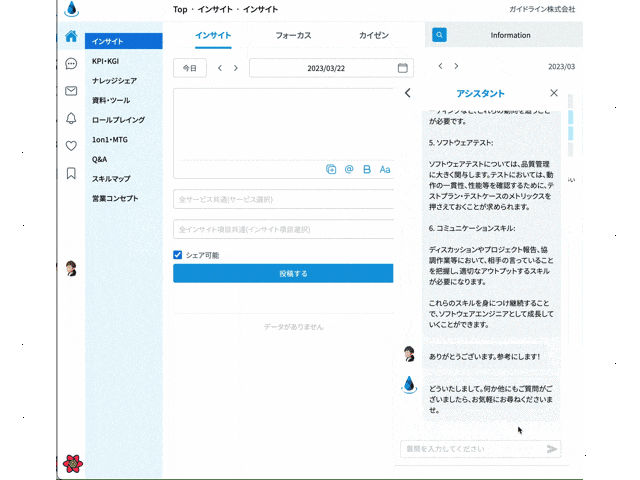
この記事では、ChatGPTのAPIを叩けるnpm openaiライブラリの使い方について解説してきます。
事前準備
まずは、以下のOpenAIのサイトから、API KEYを取得しましょう。
初期に18ドル分のクレジットをいただけます。
大量のリクエストを叩かなければ18ドルはすぐには行かない数字でした。今のところ私は0.1ドル未満です。
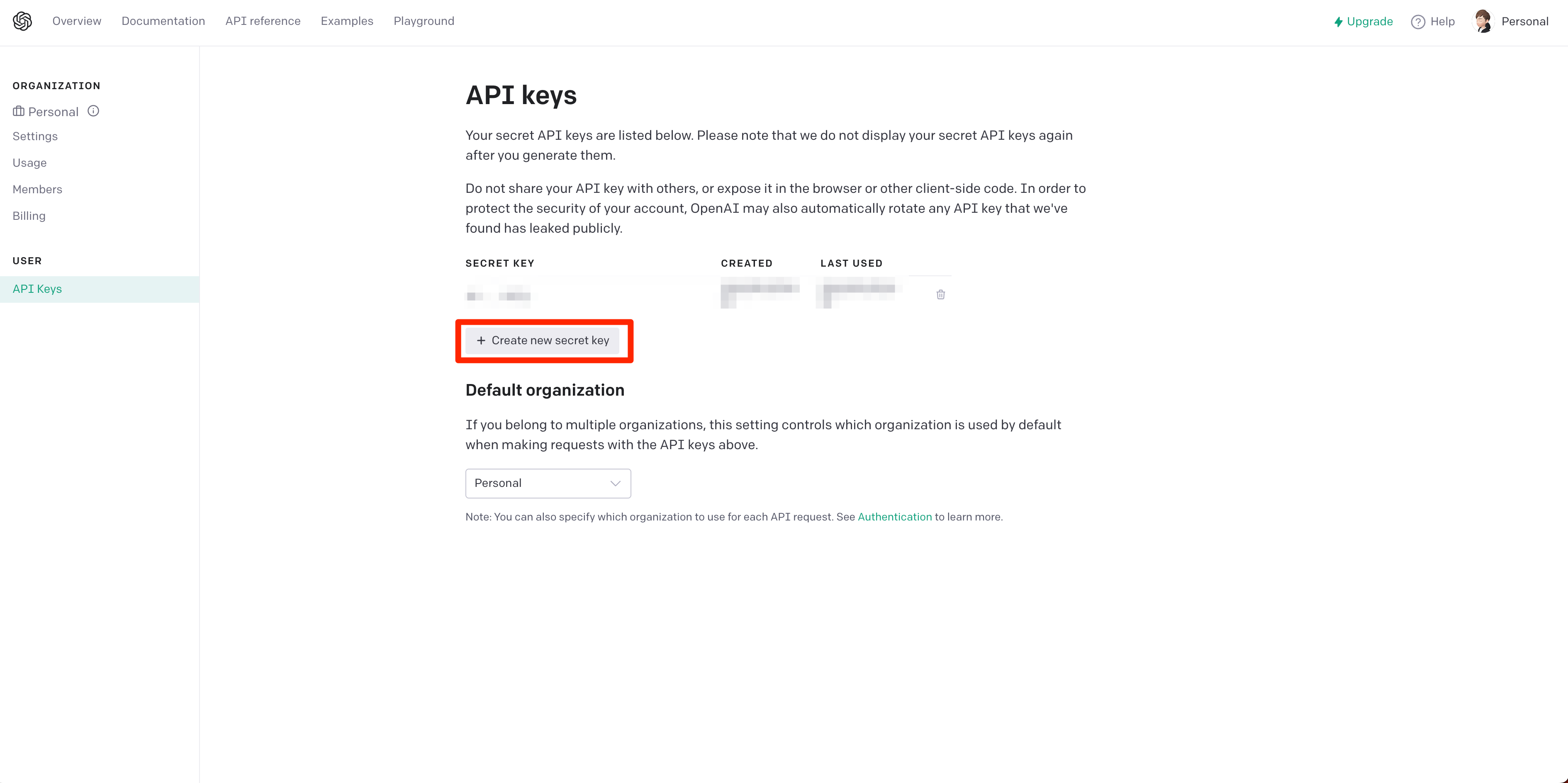
SECRET_KEYを取得したら、.envなどに以下のように指定しておきます。
OPENAI_API_KEY=sk-********
会話するためのopenaiライブラリの使い方
まずはリクエストのコード例です。
会話のAPIに関するドキュメントは こちら にあります。
叩くAPIは POST https://api.openai.com/v1/chat/completions です。
これを openaiライブラリから呼ぶコードの例は、以下です。以下は最小のコード例です。
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
export const openAiRequest = async () => {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo", // string;
messages: [
{
role: "user", // "user" | "assistant" | "system"
content: "こんにちは!", // string
},
],
});
return completion.data;
};
こちらのコードを参考に、各オプションについて詳しく見ていきます。
リクエストに含めるオプションについて
model
型: string
ChatGPTに使用するモデルを記載します。必須項目になっています。
先に示したコード例でいうと、こちらの部分です。
~省略~
export const openAiRequest = async () => {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo", // string;
~省略~
2023年3月22日時点で、利用できるモデルは下記です。gpt-4あたりは、まだ登録しないと利用できないのでgpt-3.5-turboあたりを使うといいかもしれません。
- gpt-4
- gpt-4-0314
- gpt-4-32k
- gpt-4-32k-0314
- gpt-3.5-turbo
- gpt-3.5-turbo-0301
利用できるモデル最新の情報は、公式サイトから確認できます。
messages
messagesは配列です。
リクエストボディーに含められた、このmessagesに配列データを元にChatGPTはレスポンスしてくれます。
~省略~
export const openAiRequest = async () => {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo", // string;
messages: [
{
role: "user", // "user" | "assistant" | "system"
content: "こんにちは!", // string
},
],
~省略~
messagesには、3種類の会話があります。
- 「ユーザー」: ユーザー側が送信するデータ
- 「アシスタント」: ChatGPTから返ってくるデータ
- 「システム」: ChatGPTにどんな役割を与えるかを送信するデータ
です。
messagesの型は、下記です。
export interface ChatCompletionRequestMessage {
'role': ChatCompletionRequestMessageRoleEnum; // "user" | "assistant" | "system"
'content': string;
'name'?: string;
}
'messages': Array<ChatCompletionRequestMessage>;
ここで新たに出てきたnameは、ChatGPTの名前を表します。例えば..
messages: [
{
role: "user", // "user" | "assistant" | "system"
content: "こんにちは!", // string
name: "Pikachu", // string
},
],
上記のように、nameにPikachuと設定したら、以下のように返って来るようになりました。
"こんにちは!私はPikachuというAIです。"
nameには以下のような制約があります。
- 1~64文字以内
- 英数字のみ(ひらがな、カタカナ、漢字などは利用できない)
上記まではmessagesのroleがuserの例でした。
次に、systemを使った例も示します。
systemは、AIのキャラクターなどを決めるものです。
例えば、キャラクターを「猫」としてみます。
~~省略~~
const botSystem = `
あなたは今から猫として生きることになりました。
話す言葉は猫語です。
どんな質問にも、猫語で答えてください。
`;
export const openAiRequest = async () => {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo", // string;
messages: [
{
role: "system", // "user" | "assistant" | "system"
content: botSystem, // string
},
{
role: "user", // "user" | "assistant" | "system"
content: "こんにちは!あなたの人生でした一番の後悔はなんでしょうか?また、その後悔で得られた教訓はなんですか?", // string
},
],
~~省略~~
キャラクターを猫に設定した上で
質問を
「こんにちは!あなたの人生でした一番の後悔はなんでしょうか?また、その後悔で得られた教訓はなんですか?」としてみました。
すると以下のような回答が得られました。
ニャー、こんにちは。
私は猫であるので、人生を持っていないので、後悔することができません。
しかし、私たちは今を生きて、毎日を大切に過ごすことが大切だと思います。
私の人生から得られる教訓は、今を楽しみ、自分の幸福に注力することが大切ということです。
リクエストに必須の項目は上記の、modelとmessagesで以上です。
必須項目以外のオプション
以降で説明するオプションについては、必須項目ではありません。
max_tokens
型: number | undefind
ChatGPTから生成される回答のトークンの最大数を表します。
デフォルトでは制限がありません。
2048とかくらいの制限はつけておくといいかもしません。
トークン数はこちらから確認することができます。
https://platform.openai.com/tokenizer

user
型: string | undefind
エンドユーザーを表す一意の識別子を渡すことができます。
OpenAIの不正利用の検知などに役立ちます。
ログインユーザーのIDなどを設定しておくといいと思います。
n
型: number | null | undefind
ChatGPTからの回答の数を表します。
デフォルトは1です。
例えば3にすると以下のように3つの回答が得られました。
"choices": [
{
"message": {
"role": "assistant",
"content": "こんにちは!私はPikachuと呼ばれています。"
},
"finish_reason": "stop",
"index": 0
},
{
"message": {
"role": "assistant",
"content": "こんにちは! 私はPIKACHUです。"
},
"finish_reason": "stop",
"index": 1
},
{
"message": {
"role": "assistant",
"content": "私はピカチュウです!"
},
"finish_reason": "stop",
"index": 2
}
]
stop
型: Array | string | undefind
こちらに含めた文字列が回答に出て来たタイミングで、回答の生成を停止できます。
最大4つの文字列を渡すことができます。
temperature
型: number | null | undefind
0~2の間で設定できます。
デフォルトは1になっています。
この値は、回答のランダム性を調整するために使われます。
2に近いほど、多様な回答が得られます。
top_p
型: number | null | undefind
こちらもデフォルトは1です。
temperature同様、この値が低いほど、多様な回答が得られます。
stream
型: boolean | null | undefind
デフォルトはFalseであり、、回答が全て生成されてから、レスポンスされます。
Trueにすると回答生成中でも、1文字ずつ回答を得られるようになります。
が、現在はまだ対応されていません。
presence_penalty
型: number | null | undefined
デフォルトは0で、-2.0から2.0までの値をとります。
2.0に近いほど、今まで出てきたテキストにペナルティを与え、
そのテキストを使わないようになり、新しい話題を話す可能性が高くなります。
frequency_penalty
型: number | null | undefined
デフォルトは0で、-2.0から2.0までの値をとります。
2.0に近いほど、今まで出てきたテキストの頻度に応じて、ペナルティを与え、
そのテキストを使わないようになり、新しい話題を話す可能性が高くなります。
logit_bias
型: object | null | undefined;
指定したトークンが、回答に現れる可能性を調整できます。
上記で、リクエストのボディーに含められるオプションは以上です。
レスポンスされる型
続いてレスポンスされるデータについて見ていきます。
returnされている completion.dataは Promise<CreateChatCompletionResponse>型です。
~省略~
export const openAiRequest = async () => {
const completion: AxiosPromise<CreateChatCompletionResponse> = await openai.createChatCompletion({
model: "gpt-3.5-turbo", // string;
messages: [
{
role: "user", // "user" | "assistant" | "system"
content: "こんにちは!", // string
},
],
});
return completion.data; // CreateChatCompletionResponse
};
次に、CreateChatCompletionResponseがどんな型について見てみます。
CreateChatCompletionResponse型の詳細
まずは、ユーザーが「こんにちは」と送った際に、レスポンスされたデータを見てみます。
レスポンスに型を含めて記載しています。
{
"data": {
"id": "***********************", // string
"object": "chat.completion", // string
"created": 1679458143, // number
"model": "gpt-3.5-turbo-0301", // string
"usage": { // CreateCompletionResponseUsage型
"prompt_tokens": 9, // number リクエストしたトークン数
"completion_tokens": 56, // number 回答のトークン数
"total_tokens": 65 // リクエストと回答の合計トークン数
},
"choices": [ // Array<CreateCompletionResponseChoicesInner>型
{
"message": { // ChatCompletionResponseMessage
"role": "assistant", // "user" | "assistant" | "system"
"content": "こんにちは!しばらくぶりにお会いできて嬉しいです。何かお力になれることがありましたら、何でも遠慮なくお申し付けください。" // string
},
"finish_reason": "stop", // string
"index": 0 // number 回答のindex
}
]
}
}
上記のうち、主に使うのは、choicesの中のmessageの中のcontentかと思います。
よって下記のように、choicesからcontentだけを抜き取るようなコードも書いておくことが多いかもしれません。
const fetch = async (): Promise<string | undefined> => {
const data = await openAiRequest();
const answer = data.choices.at(-1)?.message?.content;
return answer;
};
解説はこれで終わりです。
終わり
型情報などを参考にしたのは(ドキュメントにもありますが)こちらのリポジトリです。
まだ情報がどんどん更新されることもあると思いますが、
これからこのライブラリを使用する方の参考になればと思います。