動作環境
google colaboratory
keras 2.2.5
python
実験の内容
0から9の文字をフォントから切り取ったりして画像を集めてKerasで学習しました。
各画像は88枚ずつ。validation用に2割としました。100epoch回転。Data Augmentationを利用した結果が以下の通りです。

感想)
・Data Augmentationした分最初のaccracyが低いですね。しかし、後から上昇してきます。
・学習データがまだ少ないので、正解率に波があります。
反省)
・文字なのに上下反転・左右反転させていました、やらなくていいですね。
分類するクラスを29個に増やして再実験
29個の文字をフォントから切り取って画像として保存し、train.csvにまとめた上で、Kerasで機械学習しました。29個の文字は「1234567890①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲」です。
各画像は約88枚ずつ。validation用に2割としました。150epoch回転。100epoch以降に学習率低減テクニックを使っています。そして、Data Augmentationを利用した結果が以下の通りです。

・改善点
フォントの画像を切り取ったときにフォントが豆腐(=画像がなくてい四角い画像が出ること)になっているものを使って学習していたので削除すべきでした。
感想
・1文字あたり画像が80枚そこらしかないので、1文字に付き60枚くらいしか訓練画像がまだありませんが、95%の正解率を達成しています。(これに他の文字を追加していったらどうなるのか・・・)
・課題として、画像認識における機械学習の一連のコードは完成したのですが、学習する以上にtrainingデータをまとめるのが時間がかかるのがわかりました。まとめのデータを、文字の画像を追加するたびに毎回1から作成していたら、時間がいくらあっても足りないので、処理の改良が必要ということです。つまり、datasetが始めからあるサンプルは楽でありがたいですね。
似ている文字について考える
「十」と「+」、「ロ」と「口」と「◻」、「あ」と「ぁ」など、これらの文字を認識するためには、文脈と周りの文字の大きさから判断するしかないように思えます。一般的な画像の機械学習では大きさの違う犬でも同じクラスと考えますが、文字の場合は違う文字だったりするので、違う処理で分類する方法を考えてやる必要がありそうです。
「土」「±」、「I」「1」、「Z」「2」、「G」「4」、「t」「+」「十」、「h」「ん」、「ノ」「/」、「I」「エ」「工」、「ⓞ」「◎」、「ト」「卜」、「千」「チ」、「λ」「入」
手書き文字認識の精度について
手書き文字を含めた文字を前提とする場合、精度というものはとても恣意的で、お手盛りなどの操作ができることが、作業をしていると良くわかります。そもそも、文字を集めるところから自分の自由に選択が出来るので、精度を上げたかったら綺麗な文字の画像ばかりを集めれば検証状況での精度は当然上ります。しかし、実用的な読み取りを考えると、汚い文字も入れたいですが、あまりに汚い文字や個性的な文字は読めなくとも「常識的にこれは仕方がない」と説明できます。しかし、精度という点では下がるので、精度が少し低い結果のものはそれだけ手書きに近い文字を学習しようと頑張っている結果であるとも考えることができます。
分類するクラスを50個に増やして再実験
 感想)
・29から50に文字を増やした結果、95%から97%に認識度が上がりました。しかし、豆腐になっている文字とかを削除したことが原因かと思われます。
・また、同じ画像がいくつもあるようであり(重複しているので無駄)、同じ画像はデータセットとしてはまとめないように編集したいと思いました。このため後日、同じ画像を削除するようなツールを作りました。
・画像をデータセット(train.csv)としてまとめる処理が結構時間がかかります。
感想)
・29から50に文字を増やした結果、95%から97%に認識度が上がりました。しかし、豆腐になっている文字とかを削除したことが原因かと思われます。
・また、同じ画像がいくつもあるようであり(重複しているので無駄)、同じ画像はデータセットとしてはまとめないように編集したいと思いました。このため後日、同じ画像を削除するようなツールを作りました。
・画像をデータセット(train.csv)としてまとめる処理が結構時間がかかります。
分類するクラスを100文字に増やして再実験
google colaboratoryを使っているのですが、画像を100クラス置くために100個のフォルダを作成しそれぞれに画像を置くようにしているのですが、既に管理が大変です。更新した画像のみをアップロードしたいのですが、どのファイルなのか見つけるのさえ面倒です。50フォルダを1つのミドルフォルダの中に入れるようにして、これが動くようにコードを修正したりしました。このミドルフォルダをアップロードするのですが、現状でも一回に4000ファイルのアップロードになり、2時間くらい時間がかかるという状況です。
ミドルフォルダを作ったことにより、フォルダを入れるlistが1次元から2次元配列に変更しました。listをappendして、さらにappendすれば2次元配列の作成ができました。
97%達成してますが、波があるときがあるようです。

分類するクラスを200文字に増やして再実験
精度が97%から92%台に下がってしまった。うーん。

精度が下がっている原因としては、漢字が追加したために、行書やヘンテコ文字まで学習データにあるので、それがvalidationとしてテスト時に出現し始めたため、精度が下がったと考えられます。つまり、行書やヘンテコ文字は学習させないほうが、サンプル段階では良い報告ができるので外すべきだったかと思いました。それから、画像を縮小する処理をいれていたのですが、そのとき、一部の細いフォントの線が消えているということに気づいたので、これも削除する方向にしたいです。
分類するクラスを500文字に増やして再実験
92%から93%に精度が上昇しました。
理由は、行書やヘンテコ文字やサイズ縮小で線が消えるようなところを削除したためだと思います。学習にかかった時間は56分です。ここまでやるには、ボタンを1つ押せば、自動で同じフォントや文字化け(豆腐化)している画像を一回で処理することなどを、効率的に実行していないとできません。

分類するクラスを1000文字に増やして再実験
精度・・・500文字のとき93%だったのに、1000文字に増やした場合95%まで上昇しました。やっている処理は一切変わりません。
かかった時間・・・GPUを使用しましたが、ちょうど4時間かかりました。500文字のとき1時間だったのに、その倍の1000文字で4時間でした。
気になること・・・epochが少ないときの方が顕著であるが、200のときも500のときも、訓練データの精度よりも検証データの精度の方が髙いのはなぜだろう。

交差検証について
ここまで来て、あまり考えていませんでしたが、交差検証をどういう風に組み込むのがいいだろうかと思うようになりました。
結局、自分が出した結論として、150epochを一回で実行するのではなく、50epochを3回やるようにすれば、その都度scikit-learnのtrain_test_split関数を使えば、自然とランダムな交差検証が出来ると考えられるので、このように学習を実行することにしました。つまり、交差検証法を組み込むというよりは、交差検証になるように、jupyterLab上の実行方法を考えれば良いと考えました。ここら辺の考え方は、教科書どおりではないと言えます、現場の作業者が発見するノウハウかと思います。とりあえず、このようにすればランダムに4次元テンソルを並び替えてくれるので、一応これでランダムな交差検証をしたことになります。このようなやり方を考えた理由として、今の時点でも、50epochで2時間かかるためであり、これ以上長時間colabを稼働させると、強制停止が行われてしまうこともあって、一度処理を停止したいと思うことも理由の1つです。(グラフが分割されてしまうというデメリットはあります)
分類するクラスを2700文字にして再実験
1~50epoch (1~50周目)
上述のように時間的制約、メモリ的制約があるため、50epochで一旦学習を終える戦略です。
学習率は0.001でやって、正解率は95.48%。
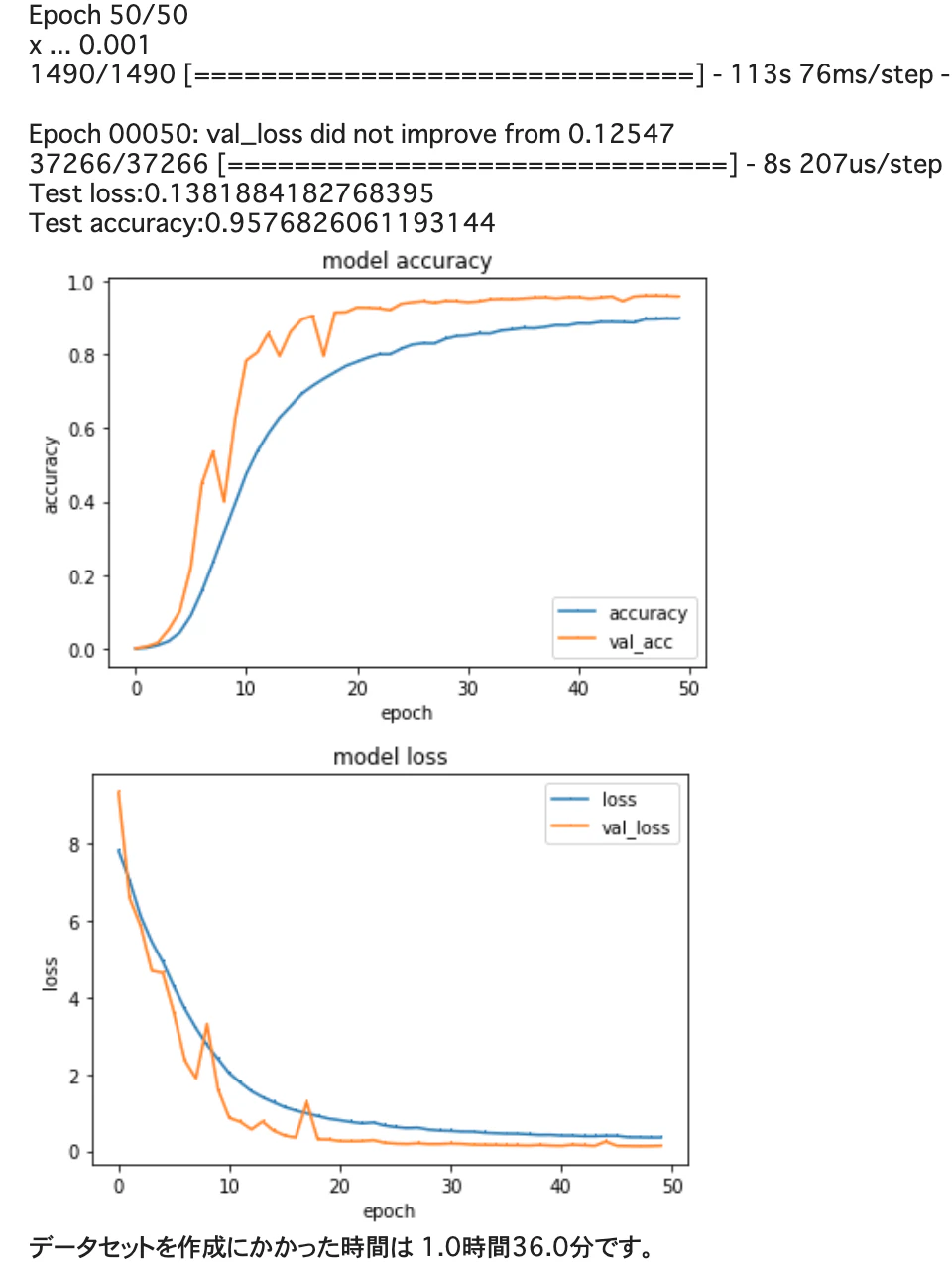
学習率低減などのテクニックを使わなくても、95%の正解率を達成しています。Test Time Augmentationもアンサンブル学習もやっていません。つまり、難しい文字の方が見分けが付きやすいということがわかります。画像認識を使った機械学習については、Kerasを組み込む技術さえあれば、知能は必要ないということですね。
50~100epoch目 (50~100周目)
90epochでRAM不足とかで停止してしまったので、グラフは出ませんでした。以降より、50epochではなく、30epochずつに周回数を変更します。
90~120epoch目 (90~120周目)
30epochに減らして再チャレンジ。
学習率を0.001から0.0002に下げています。正解率97.48%。

2時間かかりましたが、これは夜やったので、サーバ上で他の負荷が多い時間だから時間がかかったと思います。
120~150epoch (120~150周目)
学習率を0.0002から0.0001に下げています。正解率97.57%。
 43分で終わりました。実行する時間帯によって、43分から2時間のように実行時間に差が出ることがわかります。
43分で終わりました。実行する時間帯によって、43分から2時間のように実行時間に差が出ることがわかります。
感想
2700文字となると、20万行の4次元テンソルデータになります。つまり、20万枚の画像データをアップロードしたり、フォルダを入れ間違えたり、手順を間違えたりします。
画像のノイズについて、どの画像で学習すべきか
 cv2.thresholdと検索するとサンプルコードが出てきます。世の中には薄い線を書く人や、予想外のことをしてくる人もいるので、2値化するときなどでも、どの濃さで2値化するとか問題が発生します。この6つの画像の例ではoriginal Imageのままでよいと今は思います。綺麗なサンプル画像ばかり用意すると、汚い字を認識してくれ無い点のあります。しかしノイズを意図的に追加するとしてもガウシアンノイズとか、ゴマ塩ノイズとかのノイズを追加しても違って、スキャンしたときの自然なノイズや圧縮したときのノイズを含んだ画像データを使うのが良いかと思っています。
cv2.thresholdと検索するとサンプルコードが出てきます。世の中には薄い線を書く人や、予想外のことをしてくる人もいるので、2値化するときなどでも、どの濃さで2値化するとか問題が発生します。この6つの画像の例ではoriginal Imageのままでよいと今は思います。綺麗なサンプル画像ばかり用意すると、汚い字を認識してくれ無い点のあります。しかしノイズを意図的に追加するとしてもガウシアンノイズとか、ゴマ塩ノイズとかのノイズを追加しても違って、スキャンしたときの自然なノイズや圧縮したときのノイズを含んだ画像データを使うのが良いかと思っています。
続く・・・。