突然ですが皆さん、AWS Japanさんの公式Youtubeチャンネルで配信されている「AWS Developer Live Show」はご存じでしょうか?
AWSの中の人がプログラミングや開発に特化したライブセッションを配信しており、比較的最近始まった配信のようです
インフラを生業にしている私が見てもわかりやすく、非常に勉強になります
そんな中今回は、「詳しい人に聞いてみよう ! Everything fails, all the time編」を見てみました
簡単にまとめると、「開発者にネットワークのことを知ってもらおう!」という内容です
開発者の方にとって勉強になることはもちろん、インフラ屋の方が見ても改めて考え直させられる内容だと思います
内容をまとめつつ、所感や補足を入れていこうと思います
アプリケーションとインフラ
-
Amazon.comのCTOであるWerner Vogelsが「Everything fails, all the time」と言っているように、物理的なものはいつか壊れると思って設計をすることが重要
- 「Everything fails, all the time」はいろいろな訳ができますが、「形あるものは壊れる」「いつだってモノは壊れる」「あらゆるものはいつ壊れてもおかしくない」といった感じの意味です
- https://dev.classmethod.jp/articles/service-health-status-history/
-
アプリケーションはインフラが無いと動かないので、アプリケーションはインフラの障害をリカバリすることを前提に設計しなくてはならない
- ここでいう「インフラ」はネットワークやストレージ、データベース、コンピュートを指します
-
本セッションでは「ネットワーク」にフォーカスする
分散コンピューティングの8つの嘘
-
Sun MicrosystemsのPeter Deutschが社内向けのメモとして公開した(諸説あり)
-
この中からいくつかピックアップして、本動画のテーマとしています
- 明らかなソースを見つけることができなかったのですが、このあたりがソースに近いと思います
- https://arnon.me/2013/04/fallacies-massively-distributed-computing/
- 記事の中の2つ目のリンク「fallacies of distributed computing 」をクリックすると8つの嘘が出てきます

- 明らかなソースを見つけることができなかったのですが、このあたりがソースに近いと思います
-
日本語訳(DeepL翻訳、および動画より引用)
- 基本的に誰もが、初めて分散アプリケーションを構築するとき、次の8つの前提条件を設定します。どれも長い目で見れば間違いであることがわかり、大きなトラブルやつらい学習経験の原因となります。
- ネットワークは信頼できる
- レイテンシはゼロである
- 帯域幅は無限である
- ネットワークはセキュアである
- トポロジは変化しない
- 管理者は1人である
- トランスポートコストはゼロ
- ネットワークは均質である
- 基本的に誰もが、初めて分散アプリケーションを構築するとき、次の8つの前提条件を設定します。どれも長い目で見れば間違いであることがわかり、大きなトラブルやつらい学習経験の原因となります。
-
公開は1994年ごろだが、現代にも生きる部分もある
-
初めて分散アプリケーションを開発するエンジニアが陥りがちな8つの間違いをまとめたもの
-
「マイクロサービスじゃないから分散システムじゃない」とは言えない、現代のシステムは基本的に分散システムである
- マイクロサービスでなくても、クライアント、ネットワーク、サーバーという分散がされている
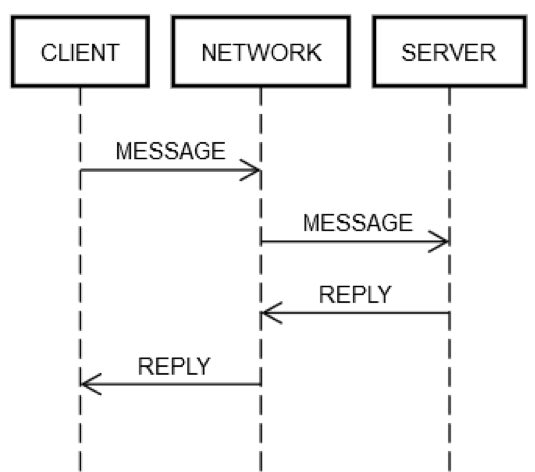
1. ネットワークは信頼できる
-
ネットワークの信頼性確保はISPの頑張りどころ、ISPが品質を担保してくれている
-
とはいえ、色々な要因によって通信障害は発生してしまう
- 地理的に遠いことによるレイテンシ
- 物理的トラブルによる通信障害
- 災害による通信障害
- 動物や虫によるケーブルの損傷
-
これらの影響を抑えるための信頼性向上がISPのお仕事
- 迂回経路を作っておく
- プロトコルによる再送処理を実装する
2.レイテンシはゼロである、3.帯域幅は無限である
-
クラウドで帯域幅は自由に使える感覚だが、もちろん上限はある
-
パケットには制御情報が含まれているため、制御情報を削ることでパケットのサイズを小さくすることが可能
- 例)HTTP2、WebSocketなどを使って実装する
-
レイテンシはある程度机上で計算できるが、具体的な数値を知りたい場合は検証すべき
- AZ間は約2msのレイテンシが生じうる
- 可用性の面ではマルチAZが推奨、2msのレイテンシを許容できない場合はシングルAZで実装する必要がある
5.トポロジは変化しない
-
トポロジ:ネットワークがどうつながっているのかを表す
-
実は、マクロな視点ではトポロジは変化している
- 例)障害時に経路変更が生じた場合には、マクロな視点ではトポロジが変わる
-
トポロジの変化が生じても影響がないようにするのも、ISPの頑張りどころ
総括
-
トポロジの変化が生じているとなると、ユーザー視点ではレイテンシが増えることがあるかもしれない
- ユーザー視点でのレイテンシ監視(Real User Monitoring)は重要なのかもしれない
-
アプリケーションにおける信頼性向上方法として、リトライ機構を作ることが推奨される
- AWSではエクスポネンシャルバックオフ、ジッターによって、リトライを実装している
-
アプリ開発者の視点でネットワーク障害を切り分けるのは難しい
- 一次切り分けだけでもできると、インフラ担当とのやり取りもスムーズになる
- 例)ping、tracertをしてみて、結果を共有する
- 一次切り分けだけでもできると、インフラ担当とのやり取りもスムーズになる
-
クラウドは便利な反面、インフラはブラックボックス化してしまう
- 裏側がどんな風になっているのか、興味を持って考えてみてることが重要
動画を見た感想
インフラ担当とアプリケーション担当、双方が幸せになる世界が早く来てほしいと思いました。動画の中でも言っていましたが、お互いが歩み寄ることが重要だと痛感しました。
最近は、AWS CDKのようなインフラとアプリの垣根を取っ払うようなサービスが増えてきていますし、私も積極的にアプリケーションの勉強をしていきたいです。
参考
-
- 動画の中のデモで使用していた、AWSのカオスエンジニアリングサービス
- 「実験テンプレート」を作成することで、意図した障害を発生させることができる
-
- ConnpassにAWSDevLiveShowのグループがあり、メンバーになるとGoogleカレンダーに予定を入れることができたりして便利です