OCR?
光学式文字読取装置。手書き文字や印字された文字を光学的に読み取り、 前もって記憶されたパターンとの照合により文字を特定し、文字データを入力すること。
装置やソフトがありますね
tesseract-ocrとは?
Tesseract-OCRはHPが開発し現在はGoogleが公開しているオープンソースのOCRエンジン
有名ですね。
試してみる!
-
インストール環境
CentOS release 6.7 (Final)
gccのバージョンが4.8以上 -
インストールしたバージョン
leptonica-1.72
tesseract 3.05.00dev
必要なライブラリをインストール
yum install autoconf automake libtool
yum install libpng-devel libjpeg-devel libtiff-devel zlib-devel
yum install libicu-devel
yum install pango-devel
Training toolsのmakeでICU(文字コード変換ライブラリ)が必要になるので
makeが通ることが確認できたバージョン56rcを
ソースからインストールする。
cd /usr/local/src/
sudo wget http://download.icu-project.org/files/icu4c/56rc/icu4c-56_rc-src.tgz
tar zxf icu4c-56_rc-src.tgz
cd icu/source/
./configure
make
make install
必要ならsudoをつけましょう
Leptonica という画像解析ライブラリも必要
最新をインストール
cd /usr/local/src/
wget http://www.leptonica.com/source/leptonica-1.72.tar.gz
tar -xzvf leptonica-1.72.tar.gz
cd leptonica-1.72
./configure
make
make install
tesseract-ocrと辞書のインストール
最新をインストール
yum install libicu-devel
cd /usr/local/src
git clone https://github.com/tesseract-ocr/tesseract.git
cd tesseract
./autogen.sh
./configure
make
sudo make install
sudo ldconfig
make training
sudo make training-install
export TESSDATA_PREFIX=/usr/local/src/tesseract/
tesseract-ocrの最新版はLeptonicaが1.72以上でないとconfigureで失敗します
またtraining toolsを用意するには
icuとlibicu-develとpango-develをインストールしている必要があります。(最初に入れましたね)
またgccがC++11をサポートしてないと
configure: WARNING: Training tools WILL NOT be built because of missing c++11 support.
というWARNINGがでてtrainingをmakeできません。
ですのでgccはC++11をサポートしている4.8以上のバージョンが必要になります
http://cpprefjp.github.io/implementation-status.html
traineddataのコピー
せっかくtraining toolsを入れたので、
https://github.com/tesseract-ocr/langdata
からtraineddataを作りたいところですが、
なぜか私の環境ではファイル生成に失敗したので仕方なく
https://github.com/tesseract-ocr/tessdata
からほしいtraineddataもってきます
eng.traineddata
jpn.traineddata
を下記のフォルダにコピーしました
/usr/local/tesseract/tessdata/
バージョン確認
$ tesseract -v
tesseract 3.05.00dev
leptonica-1.72
libjpeg 6b (libjpeg-turbo 1.2.1) : libpng 1.2.49 : libtiff 3.9.4 : zlib 1.2.3
簡単な使い方
tesseract 画像ファイル名 出力ファイル名 -l 言語
画像はここで作成しました
http://www.nin-fan.net/tool/string_image.html
【漢】ゴシック体
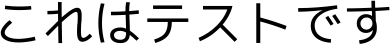
結果
$ tesseract test.png out -l jpn
これはテス卜です
おお
卜..
英字
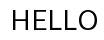
結果
$ tesseract hello.jpg out -l eng
HELLO
good
解析のしやすさ
日本語は、パラメータの調整や画像処理の工夫で
解析しやすい方法をとる必要があると思います。
英字や数字限定にすれば、もっと解析の質は上がりますが、
斜め文字だと誤認識が多いです。
他のライブラリ
nhocr
日本製で、日本語の読み取り精度は上の tesseract-ocr より良いらしい
参考
今はgithubにソースがある
https://github.com/tesseract-ocr/tesseract
学習させられる
http://hadashi-gensan.hatenablog.com/entry/2014/01/15/135316
http://tips.recatnap.info/wiki/Tesseract-OCR%E3%81%AE%E5%AD%A6%E7%BF%92%EF%BC%88%E8%AD%98%E5%AD%97%E7%8E%87%E3%82%92%E3%81%82%E3%81%92%E3%82%8B%EF%BC%89#combine_tessdata.E3.81.AE.E5.AE.9F.E8.A1.8C
ios
https://getpocket.com/a/read/356673238
関連スライド
http://www.slideshare.net/takmin/tesseract-ocr
http://www.slideshare.net/youheiyamaguchi/ss-12902286