Summary
- 文字列の類似度分析をそれっぽく作ってみた。
- 便利なライブラリに溢れた日々のなかで、ふと自力で類似度分析してみたくなった。
- 自力で作る目的のもと、MSX-BASIC で作ってみた。
Motivation
普段は npm から便利なライブラリを引っ張ってきて、TypeScript でライブラリとライブラリをつなぎ合わせるようなことをしている。この前作ったアプリ では、Material-UI と textlint をつなぎ合わせる作業のように思えた。C 言語やアセンブラで 1 からプログラミングをする能力が、薄れてきているように感じた。
……よし、たまには自力でアルゴリズム組んでみるか!題材は以下の通り:
- 文字列の類似度をそれっぽく分析する。
- 使用言語は MSX-BASIC、理由はライブラリの概念が存在しないから。
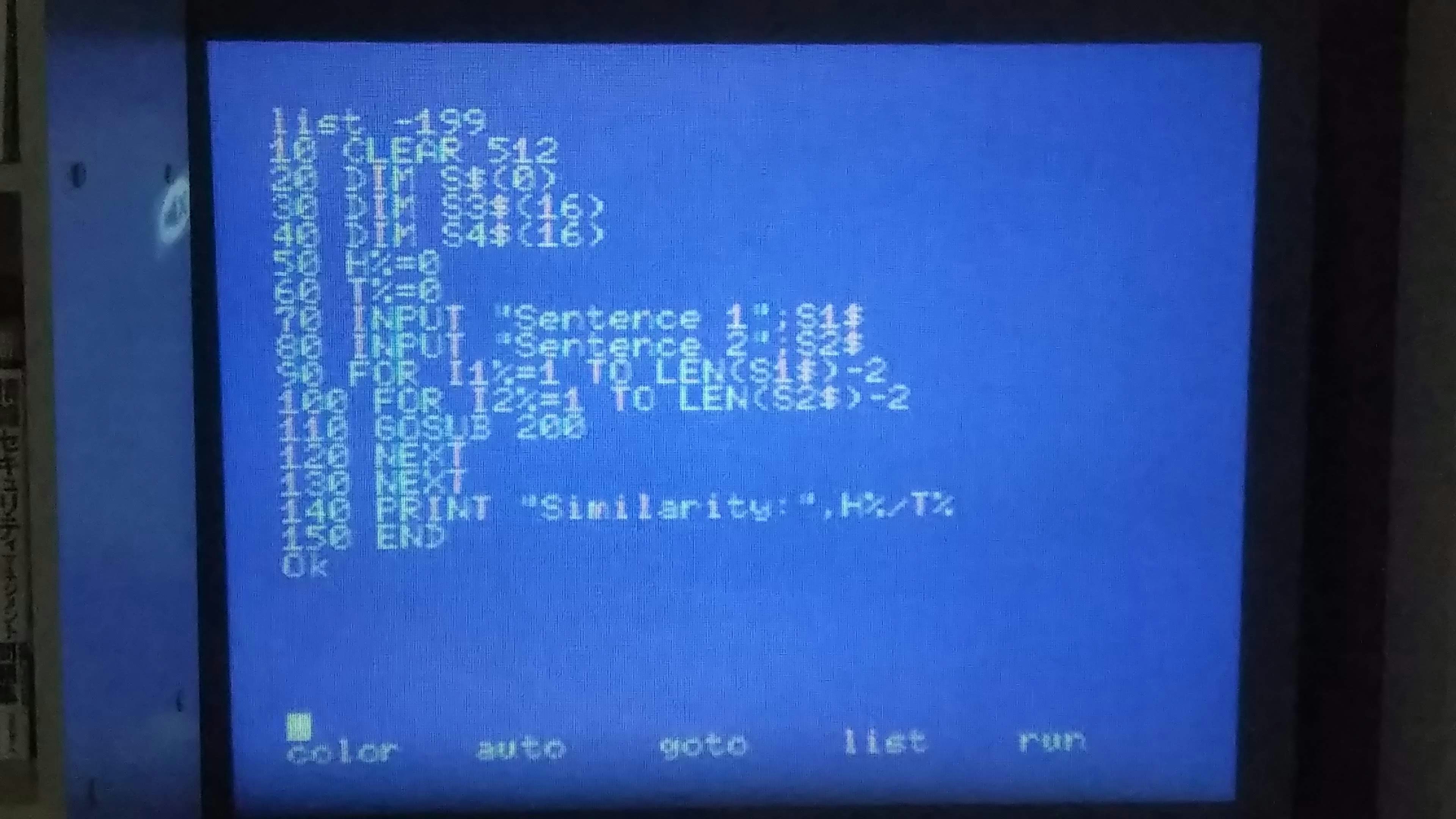
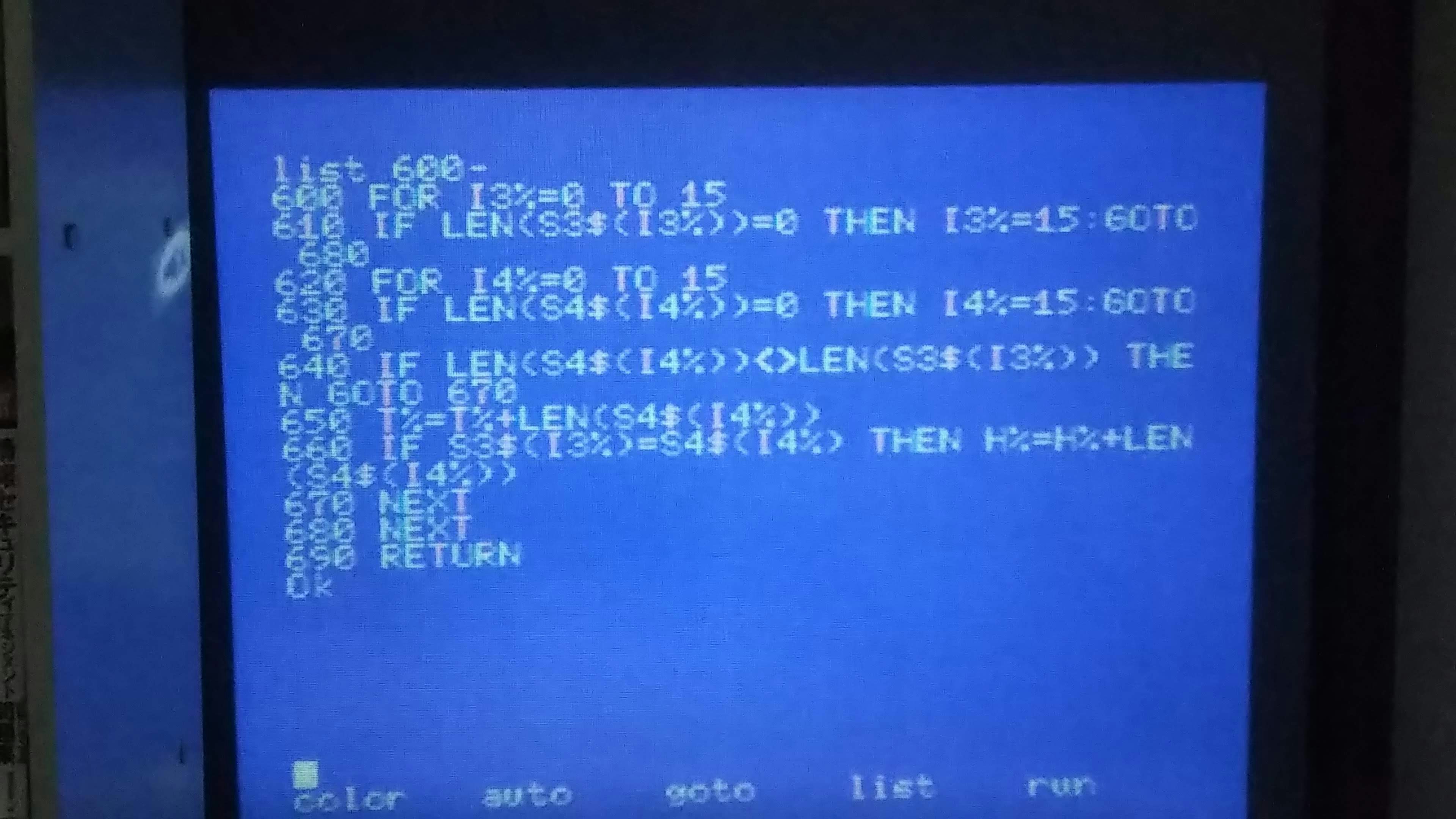
プログラム
類似度分析する 2 つの文字列を入力して、類似度を出力するメインプログラム。
入力文字列を 3-gram に分解するサブルーチン。
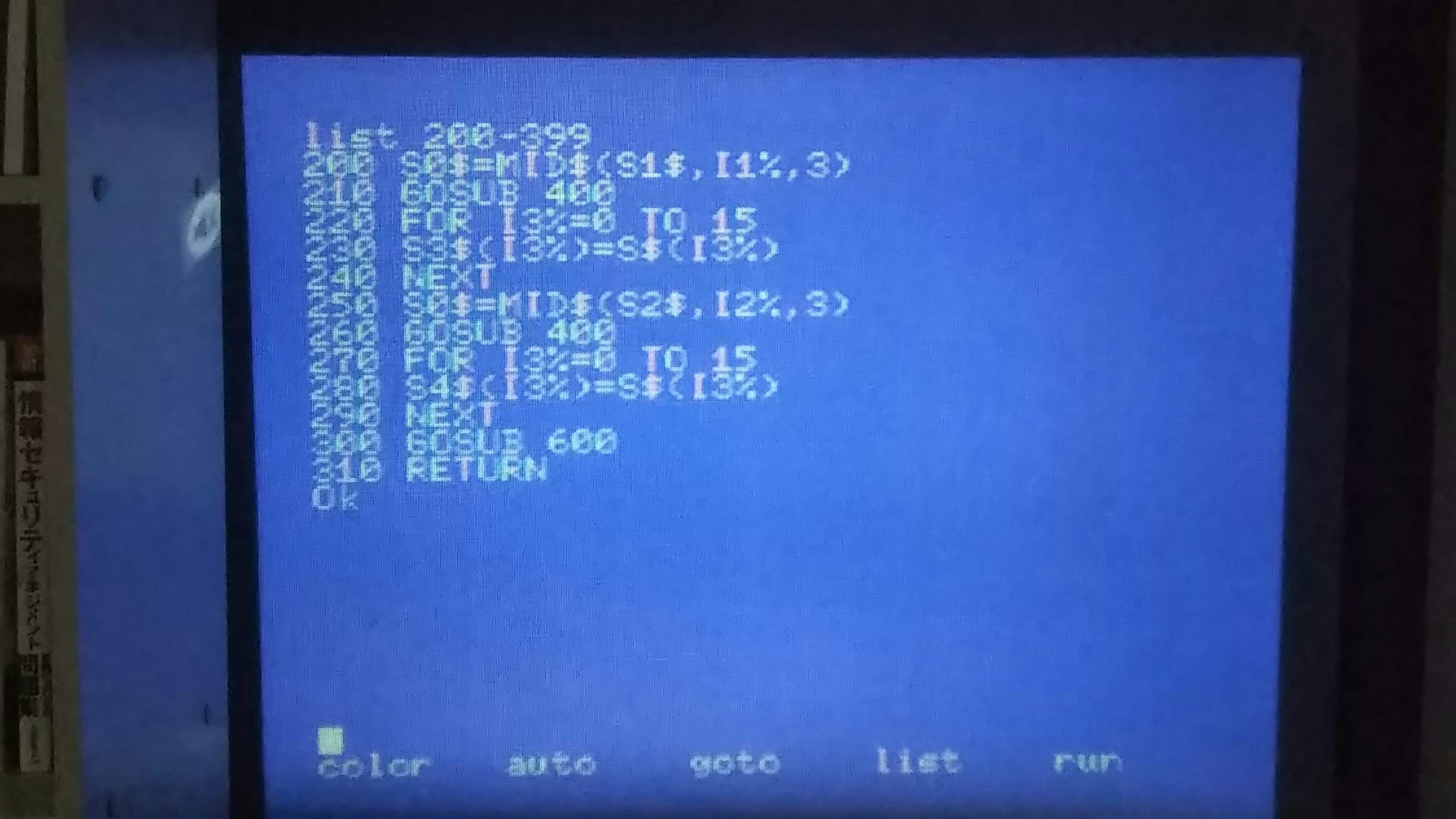
入力文字列を部分列に分解するサブルーチン。
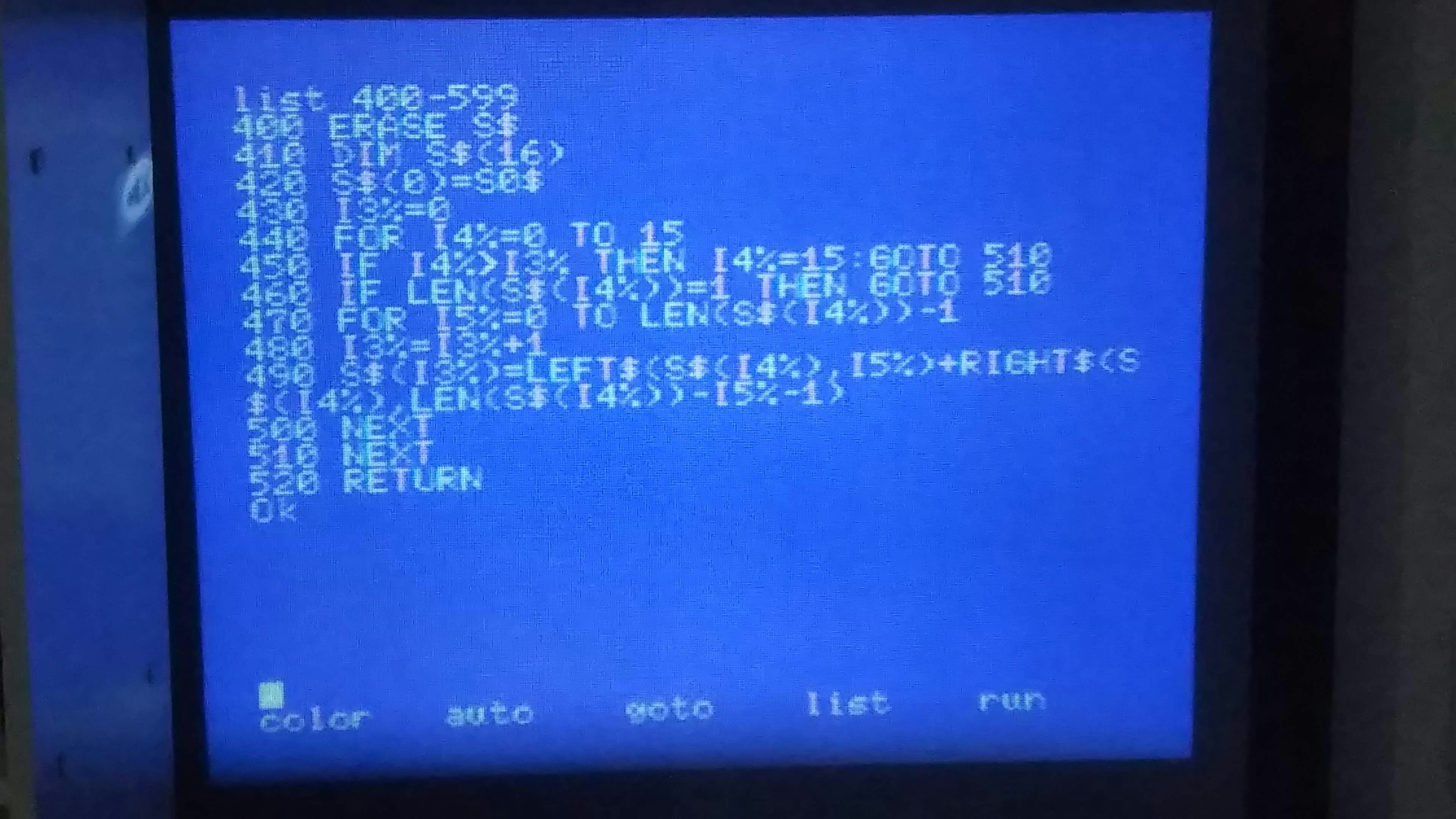
一致した部分列をカウントしていくサブルーチン。
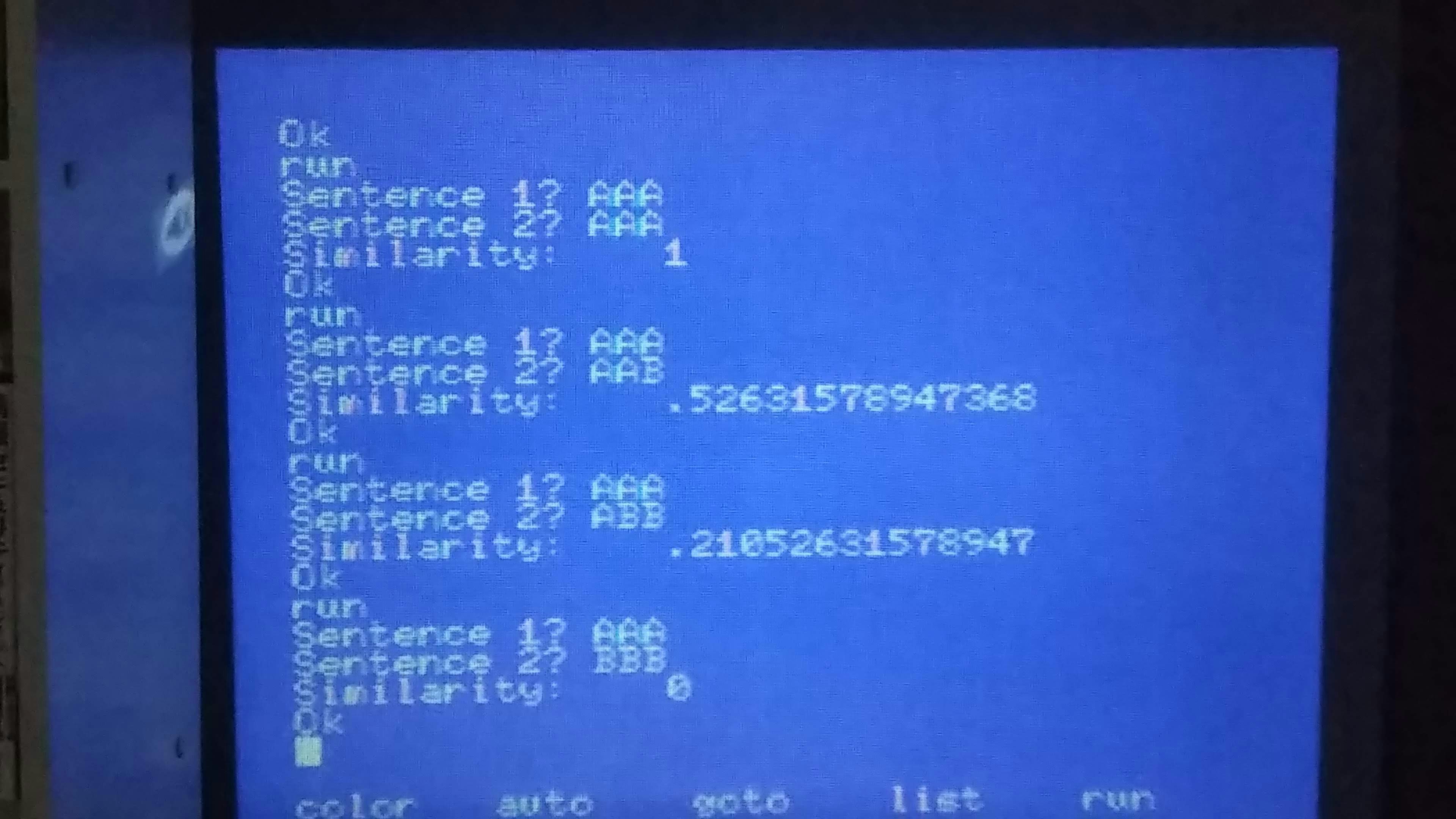
実際に分析してみる
"AAA" と "AAA" では類似度 100%
"AAA" と "AAB" では類似度 53%
"AAA" と "ABB" では類似度 21%
"AAA" と "BBB" では類似度 0%
……それっぽい!実行時間は 3 秒ほどと実用範囲内。
最近耳にしなくなった "pen apple applepen" と "pen pineapple pineapplepen" で分析した結果……
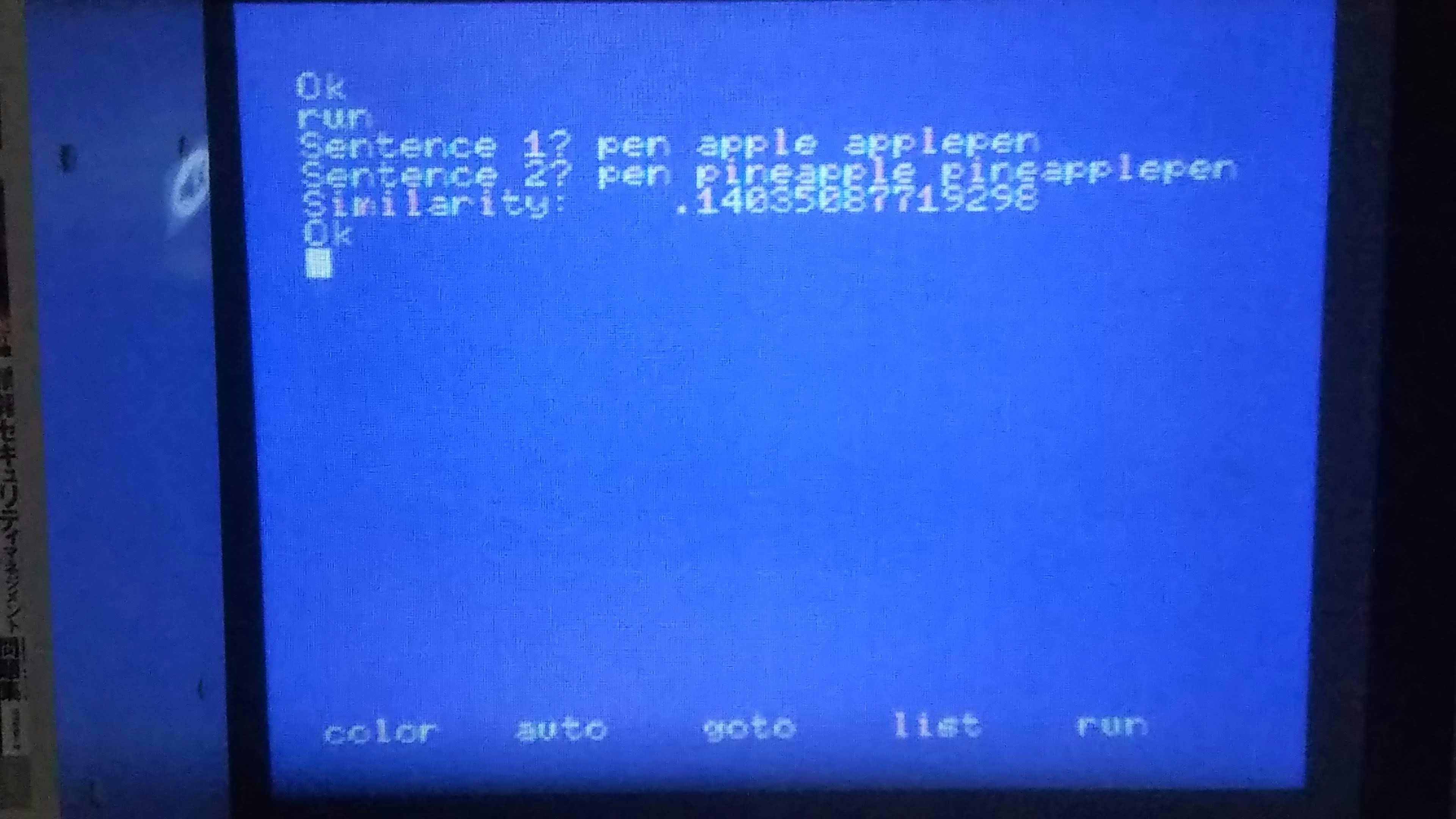
14%!!
もう少し高い類似度が出るべきだと思った。実行時間はおおよそ 13 分くらいでまあまあ現実的だったと思う。アルゴリズムを考え直す前にもう力尽きちゃったよ……
備考
部分列を使わなくても n-gram だけで類似度分析できるという、単純なことに気づいたのはこの記事を書き始めたときであった。
MicroSoft にも BASIC をビジネスにしていた時代があったんだなあ……しみじみ。
コロナ対策に160億円資金提供 「前例なき国際協力必要」―ゲイツ財団
(追記)
面接官「0からプログラムを書くことはできますか? というネタを知ったのは、この記事を投稿した直後であった。