はじめに(本記事の概要)
本記事は、ゲームアプリ(Google Play)のレビュースクレイピングを行い、スコア推移の可視化とテキストマイニング(単語頻度分析、共起ネットワーク)を行うことを目的に作成した。この手法はゲームアプリ以外にも応用可能である。また、私自身のプログラミング学習の成果物の記録を残すという意味でも作成している。
今回の分析対象としてGoogle Play版『ウマ娘 プリティーダービー』(Cygames、2021年)を選択した。当該アプリを選んだ理由は以下の通りである。
- 情報誌「日経トレンディ」の「2021年ヒット商品ベスト30」の第2位にランクインするなど、今年度注目されたゲームアプリのため。
- レビュー数が、 7万件と分析データとしては申し分ない数のため。
- スコア平均が「評価:3.5」(本記事執筆時点)と低く、なにかしらゲームにおいて問題があるように思われるため。(※2022/11/16時点では「評価:4.6」となっており、妥当な評価に落ち着いている。リリース当時にネガティブなレビューが集中したのは、期待度が高いタイトルであるがゆえに、遊んだプレイヤーがなにかしらの改善を期待したからこその結果であると推測される。少なくとも、こうしたプレイヤーが意見をくれることは、ゲーム開発・運用においては健全な証拠である。大切なのは、プレイヤーが真に求めているニーズ(本質的な問題)を探り、開発・運用していくことである。)
分析結果については、本記事執筆時点のものである。また、言うまでもなく「userName」などの情報は個人情報保護の観点から本記事には掲載しない。
なお、本記事の作成者はプログラミング学習を始めて間もない初学者のため、ソースコードが拙い点については何卒ご容赦いただきたい。「もっとこうしたほうがいいよ!」みたいなご意見があれば、コメントいただければ幸いである。
使用ツール・Pythonライブラリ
ツール
- Google Colaboratory ※Jupyter Notebookでも代用可。
ライブラリ
- google_play_scraper(Google Playのアプリレビューからスクレイピングを行うライブラリ。)
- nlplot(自然言語処理の基本的な可視化を行うライブラリ。)
- MeCab(定番の形態素解析のライブラリ。)
- mecab-ipadic-neologd(辞書ライブラリ。「ウマ娘」などの固有名詞で解析ができる。)
- pandas, numpy, matplotlib(データサイエンス御用達ライブラリ。)
手順
00.事前準備
- ライブラリのインストール&読み込み
- google_play_scraperでレビュー取得
- データフレームとして格納
01.スコア推移の集計・可視化、月別スコアの集計・可視化
- 運用開始日から現在までのスコア推移を棒グラフで表示
- 100%積み上げ棒グラフで月別スコアを集計
- 直近1ヶ月のスコア推移とレビューを抜き出す
02.テキストマイニング(形態素解析)
- レビューのデータフレームとして格納
- MeCabで形態素分析を行う
- mecab-ipadic-neologdをインストール
- nlplotで直近1ヶ月のレビューを可視化・分析
- 頻出単語
- 単語数の分布
- ワードクラウド
- 共起ネットワーク
- サンバーストチャート
00.事前準備
ライブラリのインストール&読み込み
まず Google Play アプリのレビュースクレイピング用のライブラリである「google_play_scraper」をpipでインストールする。
# google_play_scraperのインストール
!pip install google_play_scraper
次にデータ分析用の各ライブラリを読み込む。
# ライブラリの読み込み
from google_play_scraper import app
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime as dt
google_play_scraperでレビュー取得して、データフレームに格納
google_play_scraperをインポートして「ウマ娘 プリティーダービー - Google Play」のレビューを取得していく。
# google_play_scraperでレビュー取得
from google_play_scraper import Sort, reviews_all
# 「ウマ娘 プリティーダービー - Google Play」からレビューを取得する
jp_reviews = reviews_all(
'jp.co.cygames.umamusume',
sleep_milliseconds=0, # defaults to 0
lang='ja', # defaults to 'en'
country='jp', # defaults to 'us'
sort=Sort.NEWEST, # defaults to Sort.MOST_RELEVANT
)
取得したレビューをデータフレームに格納したら下準備は完了。
# 取得したレビューをデータフレームに格納
df_bush = pd.DataFrame(np.array(jp_reviews), columns=['review'])
df_bush = df_bush.join(pd.DataFrame(df_bush.pop('review').tolist()))
df_bush
01.月別スコアの集計
運用開始日から現在までのスコア推移を棒グラフで表示
スコア推移を可視化するための前準備を行う。まず['at'](レビュー投稿日時)['score'](スコア)['content'](レビューコメント)など必要な列のみ抜き出す。
df = df_bush[['at', 'score', 'content']]
df.head()
at score content
0 2021-10-26 07:27:14 4 継承でかなり左右されるのをもうちょいどうにかして欲しい。せめて青因子は上昇量固定でもいいんじ...
1 2021-10-26 07:12:12 1 るしあのガチャが一番の楽しみ。
2 2021-10-26 07:08:47 5 ウマ娘の首がマミるバグが多いので改善して欲しいです。 それ以外は花丸です☆
3 2021-10-26 06:55:01 5 マジでいい
4 2021-10-26 06:30:42 3 ガチャが引けません、それ以外は良い感じです。
抜き出した['score']列の総数をカウントする。
df['score'].value_counts() # ユニーク値(score)のカウント
5 7601
1 7213
2 2909
3 2782
4 2729
Name: score, dtype: int64
日別で['score']列の集計を行う。
# 日別でスコア数を表示
df_score = df[['at', 'score']]
# crosstableでscoreを横軸に変換
df_score = pd.crosstab(df['at'], df['score'], dropna=False)
# resampleで日付毎に
df_score = df_score.resample('D').sum()
# 日別スコア データフレームを作成
df_score
score 1 2 3 4 5
at
2021-02-22 0 0 4 5 36
2021-02-23 2 0 2 0 14
2021-02-24 80 10 14 27 53
2021-02-25 36 13 11 19 76
2021-02-26 26 10 20 25 51
... ... ... ... ... ...
2021-10-25 47 10 1 8 6
2021-10-26 18 8 5 5 11
2021-10-27 36 7 6 4 10
2021-10-28 46 15 6 5 13
2021-10-29 25 6 5 2 1
このデータを棒グラフ(時系列データ)として可視化した結果、以下のようなグラフが得られた。
# plotで折れ線グラフを表示
plt.figure()
df_score.plot(figsize=(18,8))
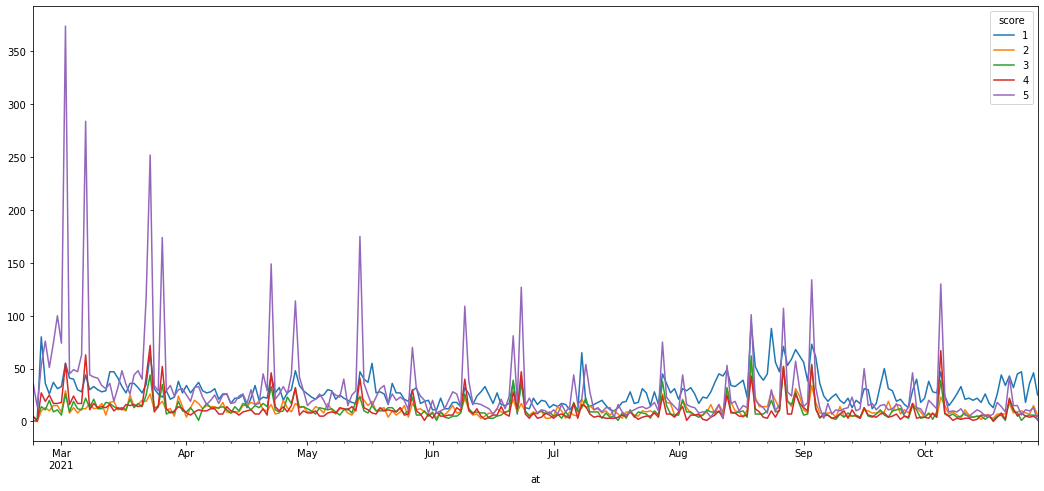
ここから当該アプリ運用開始時の評価から現在の評価までが、高評価から低評価に逆転している様子がうかがえる。
100%積み上げ棒グラフで月別スコアを集計
次に100%積み上げ棒グラフにすることにより月別のスコア推移を可視化する。その前準備としてまず月別でスコアを集計する。
# 100%積み上げグラフで表示
# 月別で集計
df_score_month = df_score.resample('M').sum()
df_score_month
score 1 2 3 4 5
at
2021-02-28 212 63 71 110 404
2021-03-31 1064 457 497 649 2210
2021-04-30 829 396 419 349 984
2021-05-31 824 353 343 335 907
2021-06-30 592 271 290 301 750
2021-07-31 656 308 273 202 545
2021-08-31 1346 527 437 331 744
2021-09-30 855 308 255 243 599
2021-10-31 835 226 197 209 458
月別のスコア数を100%積み上げ棒グラフとして可視化した結果、以下のようなグラフが得られた。
# 100%積み上げグラフ
# 正規化する
df_score_month2 = df_score_month.div(df_score_month.sum(axis=1), axis=0)
n_rows, n_cols = df_score_month2.shape
positions = np.arange(n_rows)
offsets = np.zeros(n_rows, dtype=df_score_month2.values.dtype)
colors = plt.get_cmap("tab20c")(np.linspace(0, 1, n_cols))
fig, ax = plt.subplots()
ax.set_xticks(positions)
for i in range(len(df_score_month2.columns)):
# 棒グラフを描画する。
bar = ax.bar(positions, df_score_month2.iloc[:, i], bottom=offsets, color=colors[i])
offsets += df_score_month2.iloc[:, i]
# 棒グラフのラベルを描画する。
for rect in bar:
cx = rect.get_x() + rect.get_width() / 2
cy = rect.get_y() + rect.get_height() / 2
ax.text(cx, cy, df_score_month2.columns[i], color="k", ha="center", va="center")
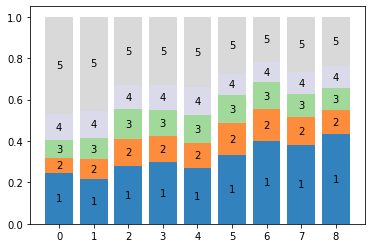
以上、折れ線グラフ・棒グラフの可視化から、当該アプリは運用開始後から評価が減少傾向にあることが認められた。
直近1カ月間のスコア推移とレビューの表示
直近1ヶ月間のスコア推移を可視化し、その期間のレビューを抜き出す。これは当該アプリにおける現状の問題点をレビュー内容から明らかにするためである。
# 直近1ヶ月間のスコア推移とレビューの表示
date_start = "2021-10-01"
date_end = "2021-10-31"
df_score_ex = df_score[date_start:date_end]
df_score_ex
score 1 2 3 4 5
at
2021-10-01 22 4 4 4 6
2021-10-02 38 7 8 3 20
2021-10-03 28 7 2 8 16
2021-10-04 27 4 9 4 12
2021-10-05 47 23 39 67 130
... ... ... ... ... ...
2021-10-24 45 9 8 5 15
2021-10-25 47 10 1 8 6
2021-10-26 18 8 5 5 11
2021-10-27 36 7 6 4 10
2021-10-28 46 15 6 5 13
2021-10-29 25 6 5 2 1
直近1ヶ月のスコア推移を折れ線グラフ(時系列データ)として可視化した結果、以下のグラフが得られた。
# グラフの表示
df_score_ex.plot(figsize=(18,8))
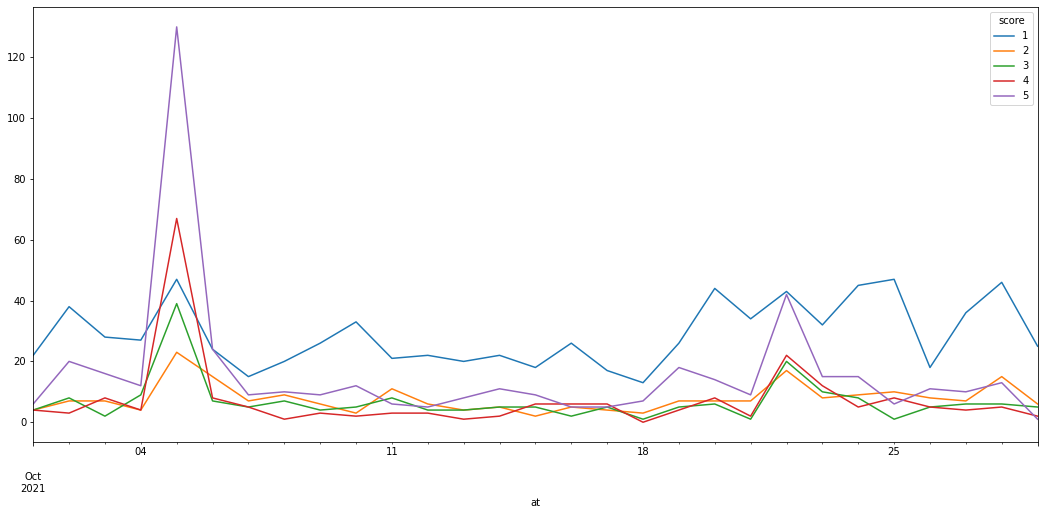
直近1ヶ月のグラフの結果から、5日前後を除き、高評価よりも低評価が上回る結果となっていることがうかがえる。では、どのような理由で低評価なのかを実際のレビューを抜き出して検証する。
# 期間中のレビューを抜き出す
df_reviews = df[(df['at'] > dt.datetime(2021,10,1)) & (df['at'] < dt.datetime(2021,11,4))]
pd.set_option('display.max_rows', None)
df_reviews
at score content
0 2021-10-29 07:23:25 2 とりあえず、このゲームがサービス終了するまでレビュー欄確認することにした。...
1 2021-10-29 07:12:41 1 Galaxyの端末だけガチャが引けないバクが一向に修正されないやるな
2 2021-10-29 06:53:50 3 新規参入する余地が皆無の因子仕様の改善がされない限り、星4以上の評価はありえないですかね。思...
3 2021-10-29 06:25:35 2 ガチャだけ引いてます😁👊👊👊👊🤜💥🤛
4 2021-10-29 06:23:58 1 レビュー消すの大変そうっすね^^
... ... ... ... ... ...
低評価レビューに目を通す限り「課金・ガチャに関する問題」、次いで「ゲームシステム・イベントに関する」レビューについての記述が見られるため、この辺りが問題点であることが認められる。
02.テキストマイニング(形態素解析)
次に直近1ヶ月間のレビューを形態素解析を行う。形態素解析とは、自然言語処理(NLP)分野において、文法的な情報の注記の無い自然言語のテキストデータから、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素の列に分割し、それぞれの形態素の品詞等を判別する作業である。今回はレビューのテキストデータを分割し、頻出単語数並びに単語間の繋がりについて解析していく。形態素解析を行うことにより、レビューにおけるトピックワードの可視化が可能となり、問題点の可視化に役立つ。
レビューをデータフレームに格納する
形態素解析を行う前準備のため、直近1ヶ月のレビュー(['at', 'content']列)のみを抽出する。
# 直近1カ月のレビューをデータフレーム化
df1 = df_bush[['at','content']]
df1 = df[(df['at'] > dt.datetime(2021,10,1)) & (df['at'] < dt.datetime(2021,10,31))]
df1
1893 2021-10-01 14:34:17 2 ほぼ微課金(デイリーパックのみ)ですがリセマラと強運で人権育成キャラとSRサポート完凸を持っ...
1894 2021-10-01 14:33:18 1 育成はやる気を絶好調に上げても、一度でもやる気が下がると面白いくらいガンガン下がる。 アオハ...
1895 2021-10-01 14:14:08 5 バグの修正早すぎて芝
1896 2021-10-01 14:08:44 5 最高
1897 2021-10-01 14:02:08 1 水着·ウェディングドレス·ハロウィンなどのコスプレ衣装はオリジナルのキャラでやってほしい。名...
... ... ... ... ... ...
テキストのみ抽出
次に形態素解析にかける理由から、テキスト('content'列)のみ抽出する。
df1 = df1[['content']]
df1 = df1.rename(columns={'content': 'text'})
df1
1893 ほぼ微課金(デイリーパックのみ)ですがリセマラと強運で人権育成キャラとSRサポート完凸を持っ...
1894 育成はやる気を絶好調に上げても、一度でもやる気が下がると面白いくらいガンガン下がる。 アオハ...
1895 バグの修正早すぎて芝
1896 最高
1897 水着·ウェディングドレス·ハロウィンなどのコスプレ衣装はオリジナルのキャラでやってほしい。名...
... ... ... ... ... ...
レビュー(テキスト)のみのデータフレームが得られたら、形態素解析の準備は完了である。
MeCabで形態素解析を行う
形態素解析を行うためのライブラリである「MeCab」をインストールする。
# MeCabをインストール
!pip install mecab-python3 > /dev/null
# mecab-ipadic-neologdをインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# 辞書のパスの確認
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd
念のため、問題なく形態素解析が行えるか例文でテストを行う。
# 形態素解析テスト
import MeCab
m = MeCab.Tagger()
sample_txt = "『ウマ娘 プリティーダービー』は、Cygamesによるスマートフォン向けゲームアプリ。"
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
m = MeCab.Tagger(path)
print("Mecab ipadic NEologd:\n",m.parse(sample_txt))
Mecab ipadic NEologd:
『 記号,括弧開,*,*,*,*,『,『,『
ウマ娘 プリティーダービー 名詞,固有名詞,一般,*,*,*,ウマ娘プリティーダービー,ウマムスメプリティーダービー,ウマムスメプリティーダービー
』 記号,括弧閉,*,*,*,*,』,』,』
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
Cygames 名詞,固有名詞,一般,*,*,*,Cygames,サイゲームス,サイゲームス
による 助詞,格助詞,連語,*,*,*,による,ニヨル,ニヨル
スマートフォン 名詞,固有名詞,一般,*,*,*,smartphone,スマートフォン,スマートフォン
向け 名詞,接尾,一般,*,*,*,向け,ムケ,ムケ
ゲームアプリ 名詞,一般,*,*,*,*,*
。 記号,句点,*,*,*,*,。,。,。
EOS
「ウマ娘 プリティーダービー」が固有名詞として解析が行えていることから、問題なく「mecab-ipadic-neologd」が辞書として分析が行えたことがわかる。
形態素解析を行う
実際に「MeCab」と辞書「mecab-ipadic-neologd」ライブラリを用いて、先ほどデータフレーム化したレビューの形態素解析を行う。
# MeCabで形態素解析を行う
import MeCab
def mecab_text(text):
#MeCabのインスタンスを作成(辞書はmecab-ipadic-neologdを使用)
mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
#形態素解析
node = mecab.parseToNode(text)
#形態素解析した結果を格納するリスト
wordlist = []
while node:
#名詞のみリストに格納する
if node.feature.split(',')[0] == '名詞':
wordlist.append(node.surface)
#形容詞を取得、elifで追加する
elif node.feature.split(',')[0] == '形容詞':
wordlist.append(node.surface)
#動詞を取得、elifで追加する
#elif node.feature.split(',')[0] == '動詞':
# wordlist.append(node.surface)
node = node.next
return wordlist
# 形態素結果をリスト化し、データフレームdf1に結果を列追加する
df1['words'] = df1['text'].apply(mecab_text)
# 表示
df1
text words
1893 ほぼ微課金(デイリーパックのみ)ですがリセマラと強運で人権育成キャラとSRサポート完凸を持っ... [課金, デイリー, パック, リセマラ, 強, 運, 人権, 育成, キャラ, SR, サ...
1894 育成はやる気を絶好調に上げても、一度でもやる気が下がると面白いくらいガンガン下がる。 アオハ... [育成, やる気, 絶好調, 一, 度, やる気, 面白い, アオハル, 特訓, アオハル,...
1895 バグの修正早すぎて芝 [バグ, 修正, 早, 芝]
1896 最高 [最高]
1897 水着·ウェディングドレス·ハロウィンなどのコスプレ衣装はオリジナルのキャラでやってほしい。名... [水着, ウェディングドレス, ハロウィン, コスプレ, 衣装, オリジナル, キャラ, ほ...
... ... ... ... ... ...
以上のように形態素ごとの解析結果が得られた。
nlplotで直近1カ月のレビューを可視化・分析
「nlplot」という形態素解析した単語を可視化するライブラリにて分析を行う。このライブラリを使用することにより、簡単に形態素解析を行ったデータの可視化を行うことが可能となる。
# nlplotのインストール
!pip install nlplot
頻出単語
頻出単語の可視化を行った結果、以下のグラフが得られた。
# nlplotで直近1カ月のレビューを可視化・分析
# 頻出単語
import nlplot
npt = nlplot.NLPlot(df1, target_col='words')
# top_nで頻出上位単語, min_freqで頻出下位単語を指定
stopwords = npt.get_stopword(top_n=0, min_freq=0)
npt.bar_ngram(
title='uni-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=1,
top_n=50,
stopwords=stopwords,
)
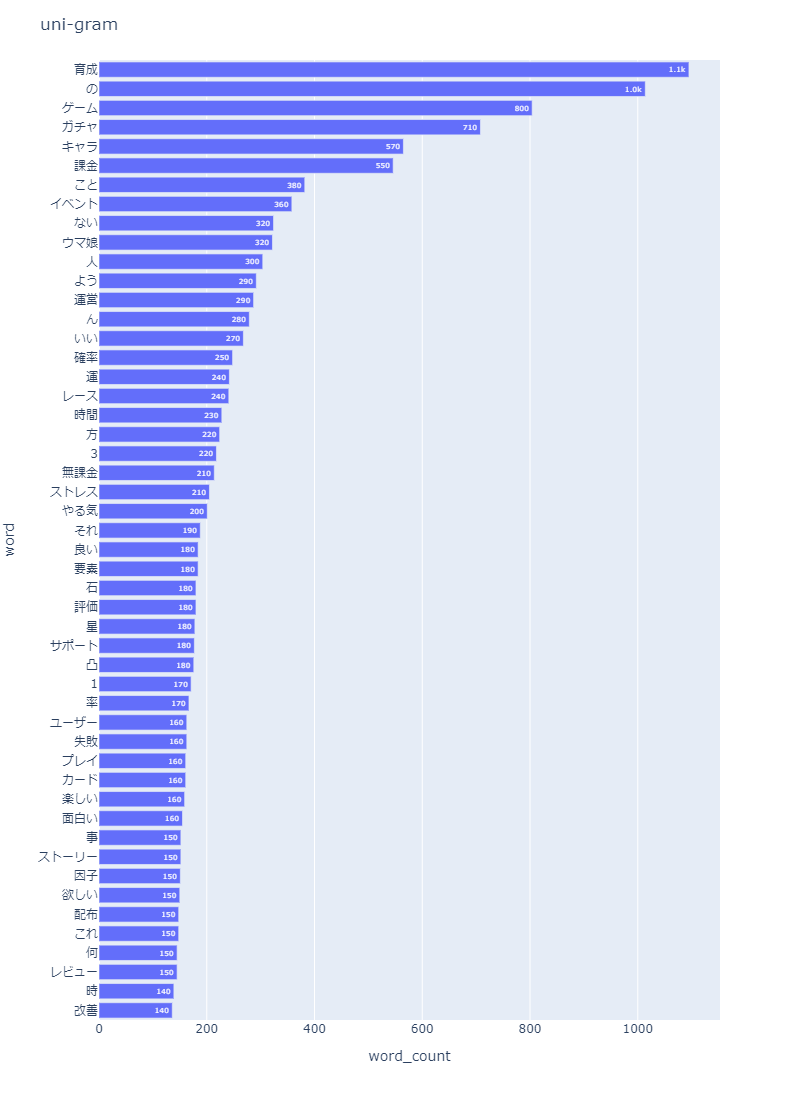
頻出単語は「育成」「ゲーム」「ガチャ」「キャラ」「課金」「イベント」となっていることから、この辺りのワードがレビューで取り上げられていることがわかる。
単語数の分布
単語数の分布の可視化を行った結果、以下のグラフが得られた。
# 単語数の分布
npt.treemap(
title='Tree of Most Common Words',
ngram=1,
top_n=30,
stopwords=stopwords,
)
単語数の分布は頻出単語と同様の結果「育成」「ゲーム」「ガチャ」「キャラ」「課金」「イベント」となっていることから、この辺りのワードがレビューで取り上げられていることがわかる。

ワードクラウド
ワードクラウド(文章中で出現頻度が高い単語を複数選び出し、その頻度に応じた大きさで図示する手法)での可視化を行った結果、以下のグラフが得られた。
# ワードクラウド
npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
)

グラフでは「ストレス」「運ゲー」「渋い」「課金」といった単語が散見されることがわかる。
共起ネットワーク
# 共起ネットワーク
# ビルド(データ件数によっては処理に時間を要します)
npt.build_graph(stopwords=stopwords, min_edge_frequency=70)
display(
npt.node_df.head(), npt.node_df.shape,
npt.edge_df.head(), npt.edge_df.shape
)
npt.co_network(
title='Co-occurrence network',
)
単語ごとの共起ネットワーク(単語が共通に出現する関係(共起関係)を円と線で表示した図)として可視化した結果、以下のグラフが得られた。

共起ネットワークから「育成」「課金」「ガチャ」「キャラ」「ストレス」といった単語間に共起関係が見られることから、ゲームにおける育成や課金、キャラになにかしらのストレス要因があるように思われる。
サンバーストチャート
サンバーストチャート(階層化されたデータをドーナッツ状のグラフで表したもの)として可視化した結果、以下のグラフが得られた。
# サンバースト
npt.sunburst(
title='All sentiment sunburst chart',
colorscale=True,
color_continuous_scale='Oryel',
width=800,
height=600,
save=True
)

このグラフから、共起ネットワークの結果と同様に、第1階層に「育成」「確率」「ストレス」といった項目が見られることから、ゲームにおける育成になにかしらのストレス要因があるように思われる。
また、第1階層に 「キャラ」「課金」「無課金」「運営」があることから、課金周りが運営批判に直結していることが示唆されるだろう。
まとめ(分析結果について)
-
レビュー分析の結果、課金に関する問題、そこからのゲームバランスの問題があることがうかがえる。
-
ガチャが渋い(排出されない)といったルートボックスの問題と課金額によって無課金プレイヤーと課金プレイヤーとの間とのレベルに乖離が見られるといったレビューも散見している。このことから、課金・ゲームバランスの問題が拝金主義的な印象をプレイヤーに与えており、結果として低評価レビューを加速させている可能性がある。
-
今後の対応策については、無課金プレイヤーと課金プレイヤーとのレベル差を改めて分析した上で、適切なバランスになるようにゲームバランスの調整を行うことが必要だろう。ただし、こうした調整については極端な対応を行った場合、ゲームバランスの崩壊はおろか企業として利益を出すことができず、結果として現状のクオリティのコンテンツをプレイヤーに提供できなくなるという問題もある。
-
バランス調整については、A/Bテスト(元はWebマーケティングの手法で、施策の良否を判断するために、2つの施策同士を比較検討しながら改善を図る。)的にゲームを改善する手法が望ましいのではないだろうか。
-
ゲームデザイン・インゲームの仕様については、根本を見直すほど問題があるとは思えない。むしろグラフィックやインゲームなどについてはレビューでも高評価が多い。
-
ここからは私見であるが、こうした課金・ゲームバランスの問題がうかがえるものの、近年のスマートフォンゲームとしては高クオリティのゲームであると評価できる。また、ゲームデザインについてもよくできたゲームであると評価することができるだろう。ゲームデザイン評価についてはここでは割愛する。
-
また、実際に当該ゲームをプレイした個人(プレイ当初の頃に数回課金した程度)としては、課金仕様について「渋いか」と言われると、そこまで渋くないんじゃないか、と言える。一応、私自身が狙ってみた☆3のキャラクターも問題なく排出されている。ただし、これについては当人のプレイスタイルにもよるだろう。こうした印象の乖離が起きる原因については、改めて客観的に調査していく必要がある。
あとがき(私的課題点)
-
ライブラリありき(google_play_scrape, nlplotなど)でプログラミングを組んだため、今後は使用したライブラリそのもののプログラムを読み解くなど、ローレベルで理解できるようにしていきたい。
-
「グラフに月を追加する」「グラフのサイズ調整」など思うように調整ができていない部分が多い。そうした描画ライブラリ(pyplot)の理解を深めるようにしていきたい。
-
「Excel(データ分析・グラフ)」「KH Coder(形態素解析)」レベルでの実装をPythonまたはRで行えるようにしていきたい。また今後は機械学習を用いたデータ分析基盤をある程度組めるように勉強していきたい。
-
ライブラリのドキュメント(英語)をスラスラ読めるようにしていきたい。
-
今回の分析は、あくまでも表面的なレビュー分析のため、更なる分析には、インゲームにおける、DAU/MAUやPU(Paid User)、RR(Retention Rate)やFQ7(Frequency 7)、あるいは遷移や離脱といったデータが必要となるだろう(こうしたデータは実際にゲームの運用に関わっている人ではないと取得できない代物だが・・・)。機会があれば、こうした側面からデータ分析を行えるように勉強していきたい。
参考
-
How to Scrape Google Play Reviews in 4 simple steps using Python
https://www.linkedin.com/pulse/how-scrape-google-play-reviews-4-simple-steps-using-python-kundi -
Pandas DataFrameを徹底解説!(作成、行・列の追加と削除、indexなど)
https://ai-inter1.com/pandas-dataframe_basic/ -
pandasでユニークな要素の個数、頻度(出現回数)をカウント
https://note.nkmk.me/python-pandas-value-counts/ -
Matplotlib で図のサイズとその形式を変更する方法
https://www.delftstack.com/ja/howto/matplotlib/how-to-change-the-size-and-format-of-a-figure-in-matplotlib/ -
matplotlib – 積み上げ棒グラフを作成する方法
https://pystyle.info/matplotlib-stacked-bar-chart/ -
Pythonで文章中の頻出単語を抽出する方法
https://analysis-navi.com/?p=2167 -
PYTHONで感情分析(形態素解析準備編)- MECAB
https://boxcode.jp/python%E3%81%A7%E6%84%9F%E6%83%85%E5%88%86%E6%9E%90%EF%BC%88%E5%BD%A2%E6%85%8B%E7%B4%A0%E8%A7%A3%E6%9E%90%E6%BA%96%E5%82%99%E7%B7%A8%EF%BC%89-mecab -
[文章生成]MeCabをインストールして分かち書きを試してみよう
https://atmarkit.itmedia.co.jp/ait/articles/2102/05/news027_2.html -
Google ColabにMeCabとipadic-NEologdをインストールする
https://qiita.com/jun40vn/items/78e33e29dce3d50c2df1 -
NLPLOTが凄い!自然言語を可視化・分析できるPYTHONライブラリ
https://boxcode.jp/nlplot%e3%81%8c%e5%87%84%e3%81%84%ef%bc%81%e8%87%aa%e7%84%b6%e8%a8%80%e8%aa%9e%e3%82%92%e5%8f%af%e8%a6%96%e5%8c%96%e3%83%bb%e5%88%86%e6%9e%90%e3%81%a7%e3%81%8d%e3%82%8bpython%e3%83%a9%e3%82%a4