はじめに
Databricks社様は、Apache Sparkの共同創設者であるマテイ・ザハリア氏とアリ・ゴディシ氏が2013年に立ち上げた企業です。この企業は、AIや機械学習を含むビッグデータの分析を、Databricksだけで完結させることのできる統合環境を提供しています。つまり、データ抽出・加工・分析・可視化の様々なワークロードを一つのサービスでカバーしているのです。
昨日、DatabricksJapanでサポートしているユーザーコミュニティ「JEDAI」がオフラインイベントを開催されたので、参加してきました。

各種講演について
1.楽天証券×DatabricksのデータとAIの物語 ~Databricksを利用してて思うこと~
データ分析の統合部署を新たに設立し、先進的な技術への取り組みを強化しているとのことです。企業が求める分析環境において、ユーザーの変動に伴うデータ量の急増するケースは多くなっています。スケーラビリティが不可欠であり、さらに、データエンジニアからアナリストまでの幅広い職種の人々が利用できる統合データ環境の需要も高まっています。これらの課題に対応するため、Databricksの導入を選択したとのことでした。
Databricksの採用により、分散処理を利用した高負荷処理が可能となり、AzureMLやPowerBIへの接続も容易になったとのことです。

2.日経におけるAI・データサイエンスに関する取り組みとDatabricks
こちらでは、実際にDatabricksを使用した記事推薦などの事例を多く紹介しています。PoCでなく、実際の案件へと進展させた事例も多数ありました。

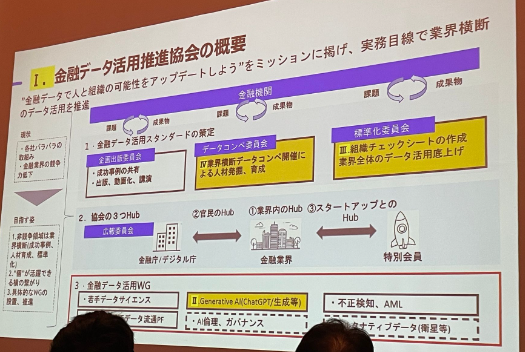
3.金融データ・生成AI活用に必要となる金融機関の組織設計と業界横断取組について
金融データの有効活用を目的に、業界全体でのデータ活用を実務の視点から推進することを意図して、コンペティションが開催したとのことでした。このイベントは多くの関心を集めたとのことでした。
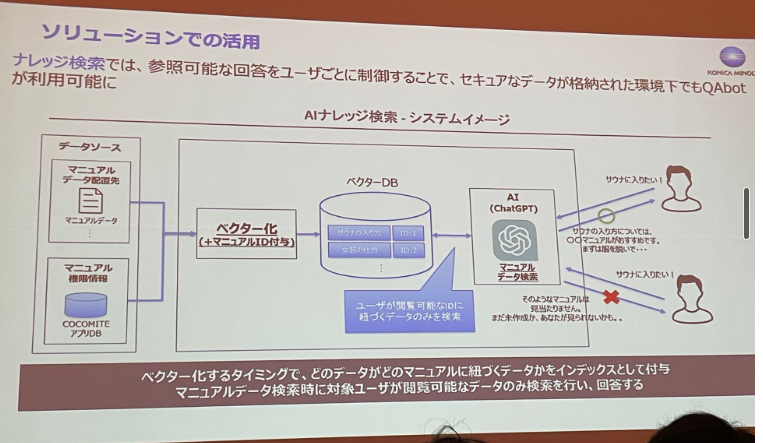
4.新規事業立ち上げ時におけるデータブリックスの価値とLLMによるソリューション/運用プロセスの高度化
Databricksを使用して、生成型AIのQAbotを開発したとのことでした。このbotはベクトル検索に加えて、データの権限管理も可能とのことです。データの権限管理にはUnityCatalogを使用しているのでしょうか。興味深いです。
最後に
登壇者の皆様からの一貫したメッセージは、データの取得、分析、および可視化を複数のサービス間で移動することなく、統合プラットフォームで効率的に実施できる利点があるとのことでした。さらに、Sparkの採用により、高いパフォーマンスとコスト効果が実現できるとの共通の意見がありました。また、従量課金制のため、大きな初期投資なしに小規模からのスタートが可能との声も聞かれました。
私自身、Databricksに関するプロジェクトにはまだ携わる機会がありませんが、この先進的な技術に積極的に取り組みたいと感じています。