はじめに
今回の記事は下記の記事の続編になります。
グラフ分析のためには構成を問わない手法のため、分析や可視化の方法だけ知りたいという方は前回の記事はスキップしても問題ありません。
構築とクエリまでのステップは#1、グラフの分析や可視化の例は#2でご確認ください。
前提条件
前回の記事に沿って環境を作成した場合には、そのまま続きから進めることが可能です。それ以外では、インメモリでクエリを実行できるデプロイ方式で今回紹介するクエリは実行可能です。
(グラフサーバーは二種類あり、3-Tierと呼ばれるインメモリにグラフを読み込むデプロイ方式で実行します。もう一方はオラクルデータベース内でグラフをロードする2-Tierの方式があります)
グラフをメモリにロードする
前回の記事で作成したグラフを今回のセッションに読み込んでいきましょう。
永続化してあるグラフは、セッションが切断されても利用可能です。
graph = session.get_graph("customer_360")
これ以前のグラフを作成する手順を確認したい場合はこちらの前回の記事をご確認ください。
パターンマッチング
PGQLクエリは、特定のパターンを発見する場合に便利です。今回のデータから、同じ日付に送金と受け取りで500以上のやり取りをしている口座をが無いか確認してみましょう。(サンプルデータのため金額の単位はありません)
graph.query_pgql("""
SELECT a.account_no
, a.balance
, t1.amount AS t1_amount
, t2.amount AS t2_amount
, t1.transfer_date
FROM MATCH (a)<-[t1:transfer]-(a1)
, MATCH (a)-[t2:transfer]->(a2)
WHERE t1.transfer_date = t2.transfer_date
AND t1.amount > 500
AND t2.amount > 500
""").print()
+---------------------------------------------------------------+
| account_no | balance | t1_amount | t2_amount | transfer_date |
+---------------------------------------------------------------+
| xxx-yyy-202 | 200.0 | 900.0 | 850.0 | 2018-10-06 |
+---------------------------------------------------------------+
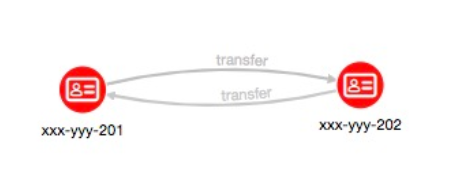
循環しているパスの検知
AからB、そしてAに戻ってくる場合や、AからB,Cを通ってAに戻ってくるような始点から終点までが同じ口座で終わっている取引を発見します。
graph.query_pgql("""
SELECT a1.account_no AS a1_account
, t1.transfer_date AS t1_date
, t1.amount AS t1_amount
, a2.account_no AS a2_account
, t2.transfer_date AS t2_date
, t2.amount AS t2_amount
FROM MATCH (a1)-[t1:transfer]->(a2)-[t2:transfer]->(a1)
WHERE t1.transfer_date < t2.transfer_date
""").print()
+-----------------------------------------------------------------------------+
| a1_account | t1_date | t1_amount | a2_account | t2_date | t2_amount |
+-----------------------------------------------------------------------------+
| xxx-yyy-201 | 2018-10-05 | 200.0 | xxx-yyy-202 | 2018-10-10 | 300.0 |
+-----------------------------------------------------------------------------+
この結果は可視化した場合、下記のようになります。
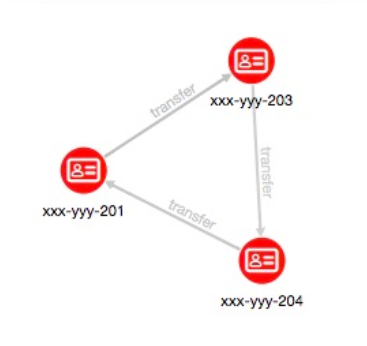
次のクエリは、前のものよりももう一つ多い取引がある場合をクエリしています。
graph.query_pgql("""
SELECT a1.account_no AS a1_account
, t1.amount AS t1_amount
, a2.account_no AS a2_account
, t2.amount AS t2_amount
, a3.account_no AS a3_account
, t3.amount AS t3_amount
FROM MATCH (a1)-[t1:transfer]->(a2)-[t2:transfer]->(a3)-[t3:transfer]->(a1)
WHERE t1.transfer_date < t2.transfer_date
AND t2.transfer_date < t3.transfer_date
""").print()
+-----------------------------------------------------------------------------+
| a1_account | t1_amount | a2_account | t2_amount | a3_account | t3_amount |
+-----------------------------------------------------------------------------+
| xxx-yyy-201 | 500.0 | xxx-yyy-203 | 450.0 | xxx-yyy-204 | 400.0 |
+-----------------------------------------------------------------------------+
ビジュアライズした場合は下記のようになります。
影響力のある口座の発見
ネットワークに対して影響力の大きい口座を発見していきましょう。ノードの中心性や重要度をスコアリングするためのアルゴリズムはいろいろあります。今回は例として、ビルトインのページランクアルゴリズムを利用します。
- フィルターをする
graph2 = graph.filter(pgx.EdgeFilter("edge.label()='TRANSFER'")); graph2
PgxGraph(name: sub-graph_16, v: 6, e: 8, directed: True, memory(Mb): 0)
-
ページランクアルゴリズムを実行する。
ページランクアルゴリズムは各ノードに数値の重みを割り当て、グラフ内での相対的な重要度を測定します。
analyst.pagerank(graph2);
VertexProperty(name: pagerank, type: double, graph: sub-graph_16)
- 結果を出す
graph2.query_pgql("""
SELECT a.account_no, a.pagerank
FROM MATCH (a)
ORDER BY a.pagerank DESC
""").print()
+-------------------------------------+
| a.account_no | a.pagerank |
+-------------------------------------+
| xxx-yyy-201 | 0.18012007557258927 |
| xxx-yyy-204 | 0.1412461615467829 |
| xxx-yyy-203 | 0.1365633635065475 |
| xxx-yyy-202 | 0.12293884324085073 |
| xxx-zzz-212 | 0.05987452026569676 |
| xxx-zzz-211 | 0.025000000000000005 |
+-------------------------------------+
コミュニティ検知
アカウントのどの部分集合がコミュニティを形成しているかを調べてみましょう。
ここでは同じサブセット内のアカウント間の移動が、他のサブセット内のアカウント間の移動より多いということです。ここでは、組み込みの弱/強連結成分アルゴリズムを使用する。
最初のステップは、アカウントとその間の転送だけを持つ部分グラフを作成することです。
これは、グラフにエッジフィルター("transfer "というラベルを持つエッジ)を作成し、適用することによって行われます。
顧客ノードを含まないグラフを作成します
graph2 = graph.filter(pgx.EdgeFilter("edge.label()='TRANSFER'")); graph2
#結果
PgxGraph(name: sub-graph_16, v: 6, e: 8, directed: True, memory(Mb): 0)
顧客が除外されたグラフをアルゴリズムにかけます。
Weakly Connected Component (WCC) は1つのパーティションのみを検出します。
analyst.wcc(graph2)
#結果
PgxPartition(graph: sub-graph_16, components: 1)
コンポーネント値は、wccという名前のプロパティに格納されます。
graph2.query_pgql("""
SELECT a.wcc AS component_id
, COUNT(*) AS count
FROM MATCH (a)
GROUP BY a.wcc
ORDER BY a.wcc
""").print()
#結果
+----------------------+
| component_id | count |
+----------------------+
| 0 | 6 |
+----------------------+
この場合、WCCアルゴリズムにより、6つのアカウントすべてが1つのコンポーネントを形成していることが分かりました。
Strongly Connected Components (SCC Kosaraju)アルゴリズムを実行します。ここでは3つのコンポーネントを検知しました。
analyst.scc_kosaraju(graph2)
#結果
PgxPartition(graph: sub-graph_16, components: 3)
コンポーネントの ID とそれぞれに含まれるノードの数をそれぞれ列挙します。
graph2.query_pgql("""
SELECT a.scc_kosaraju AS component_id
, COUNT(*) AS count
FROM MATCH (a)
GROUP BY a.scc_kosaraju
ORDER BY a.scc_kosaraju
""").print()
#結果
+----------------------+
| component_id | count |
+----------------------+
| 0 | 1 |
| 1 | 4 |
| 2 | 1 |
+----------------------+
Johnのアカウントと同じ接続コンポーネントの他のアカウントをリストアップします(= xxx-yyy-201)。コンポーネントIDは、PGQLクエリで使用するためにSCC_KOSARAJというプロパティとして追加されます。
graph2.query_pgql("""
SELECT a.account_no
FROM MATCH (a)
, MATCH (a1)
WHERE a1.account_no = 'xxx-yyy-201'
AND a.scc_kosaraju = a1.scc_kosaraju
ORDER BY a.account_no
""").print()
#結果
+-------------+
| account_no |
+-------------+
| xxx-yyy-201 |
| xxx-yyy-202 |
| xxx-yyy-203 |
| xxx-yyy-204 |
+-------------+
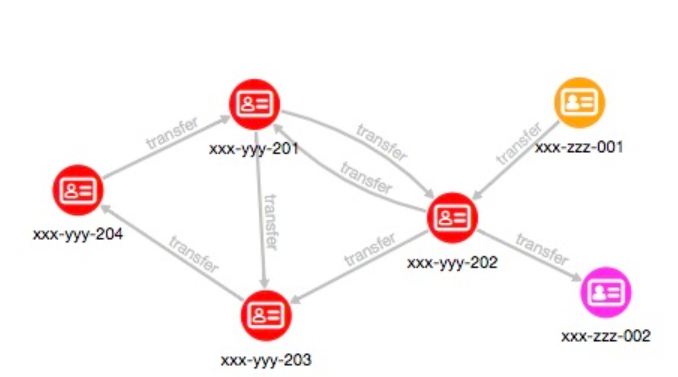
このケースでは、SCC Kosarajuアルゴリズムにより、xxx-yyy-201 (John's account)とxxx-yyy-202, xxx-yyy-203, and xxx-yyy-204は一つのパーティションで、xxx-zzz-211は一つのパーティション、xxx-zzz-212も一つのパーティションと確認できました。
グラフの可視化
前のステップで行った解析結果は、グラフ可視化機能で簡単に可視化することができます。GraphVizというコンポーネントで可視化を行っていきます。
GraphVizにログインする
下記のURLからGraphVizにWebブラウザ上でアクセスします。は利用中のグラフサーバーのIPアドレスを入力してください。
https://<public_ip_for_compute>:7007/ui
マーケットプレイスのイメージは自己署名のSSL証明書とともに配布されているため、実運用では独自の証明書に変更する必要があります。
一方、ウェブブラウザでは、安全であることを理解しつつ、警告を表示する必要があります。
Chromeの場合は、警告ウィンドウにthisisunsafeと入力すると、GraphVizの画面に遷移します。
Firefoxでは、Advancedというボタンを押して、危険性を承知で続行を選択します。
接続すると、以下のスクリーンショットのような画面が表示されるはずです。ユーザー名(customer_360)とパスワードを入力し、送信をクリックします。詳細オプションのグラフサーバーという選択肢はデフォルトなので、変更する必要はありません。

クエリの変更
最初の5行を取得するようにクエリを修正し、LIMIT 100をLIMIT 5に変更し、実行をクリックします。
以下のスクリーンショットのようなグラフが表示されるはずです。
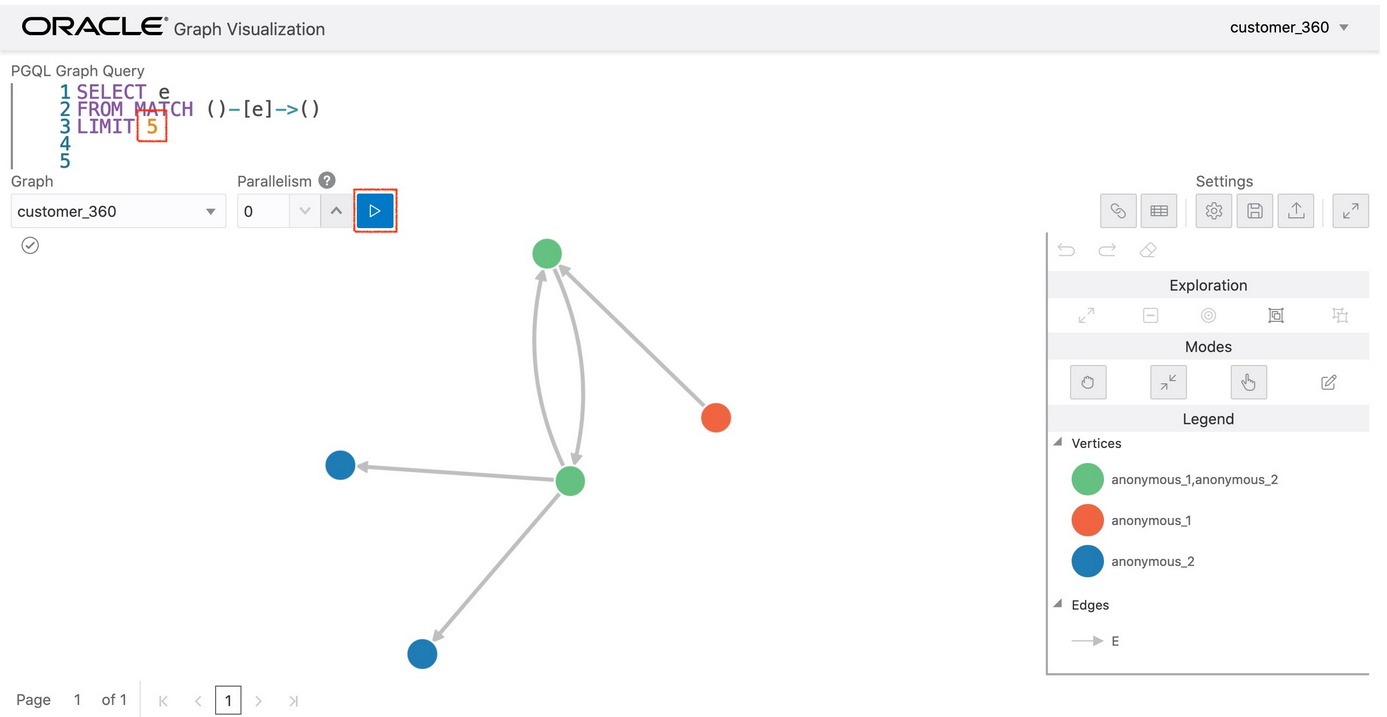
ハイライトの追加
次に、ハイライトと呼ばれるラベルやその他の視覚的なコンテキストを追加してみましょう。
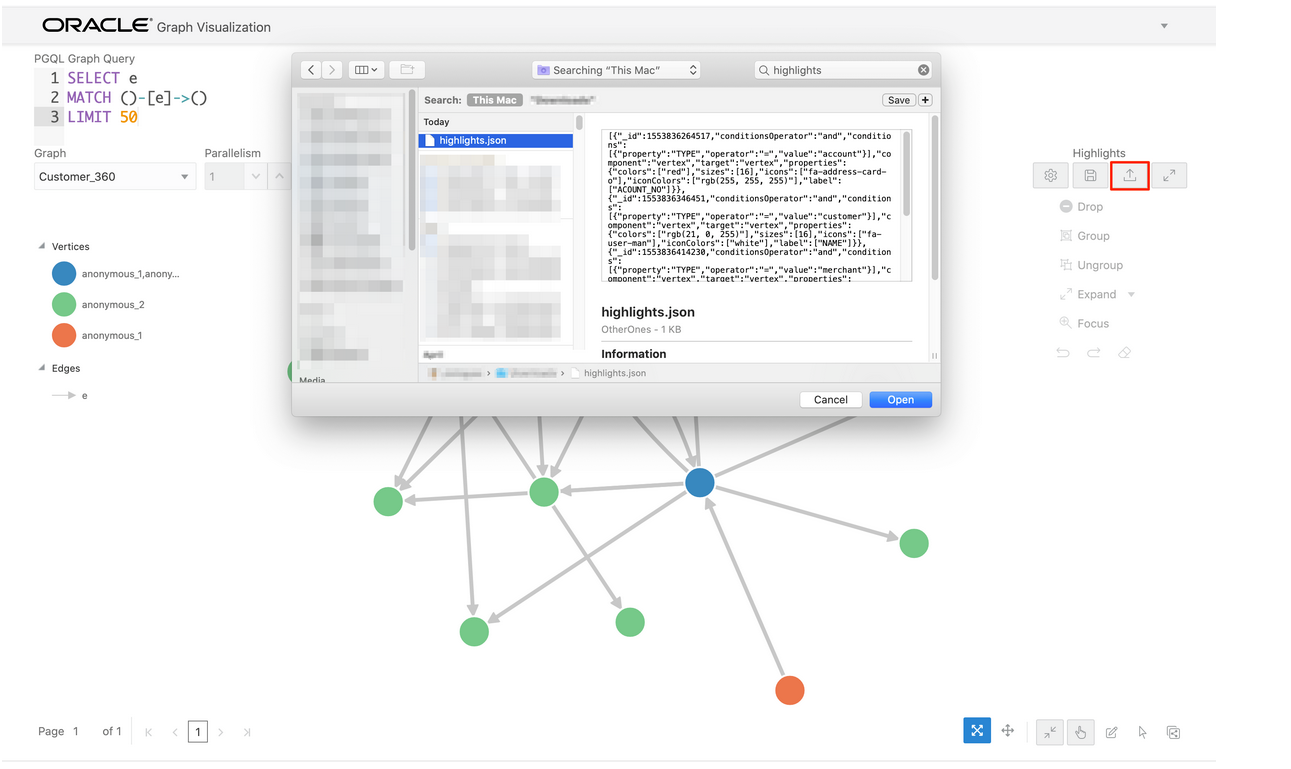
highlights.json.zipが見本として利用可能です。
ダウンロードしたハイライトのファイルは、下記画像にあるように、GraphVizのファイルアップロードボタンから、適用させることが可能です。ダウンロードしたハイライトが無い場合は、自分で作成したものをこの画面から適用させることもできます。
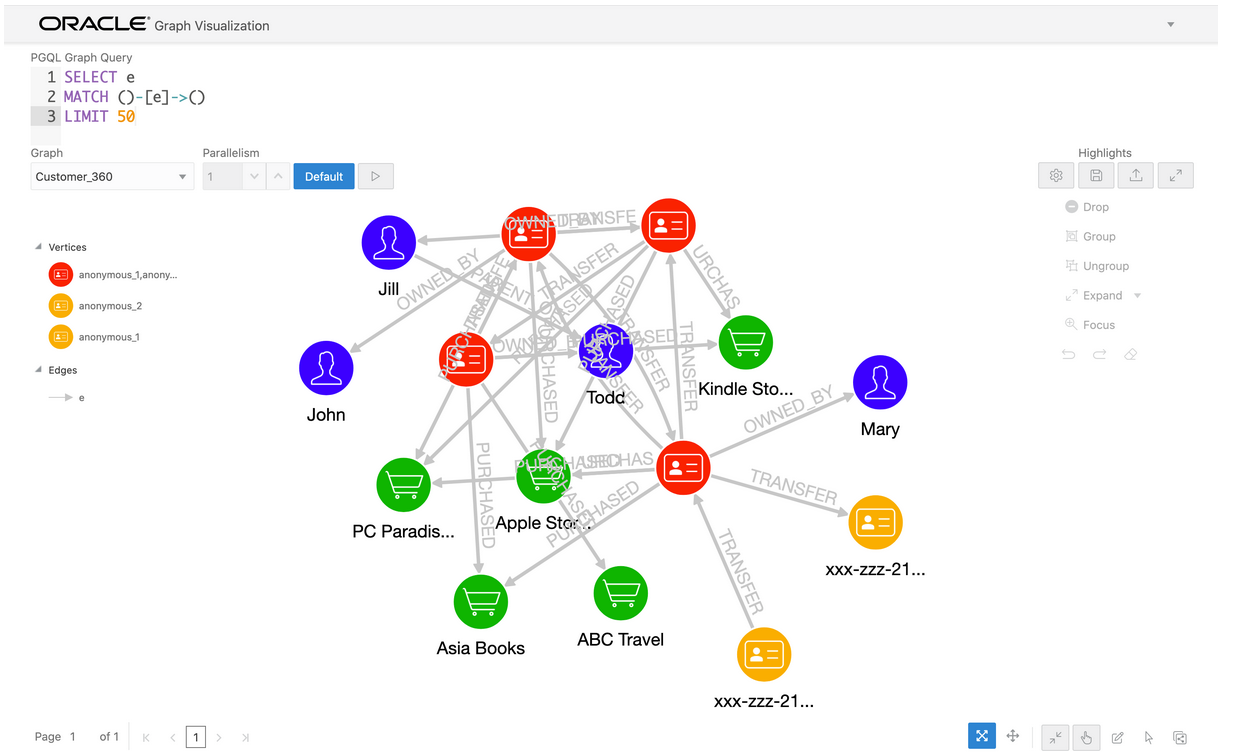
今回のハイライトファイルを適用させると、下記のようなグラフの描画になります。
PGQLのパターンマッチング
次はいくつかのパターンマッチングクエリを実行してみましょう。
pgql-lang.orgサイトと、仕様のサイトは詳細と使用例の確認に良いサイトになっています。今回の記事では、基本的なクエリを実行していきます。
PGQLクエリの基本的な構造は下記の要になっています。
SELECT <select_list>
FROM MATCH <graph_pattern> ON <graph_name>
WHERE <condition>
PGQLはグラフパターンをマッチングするためのMATCH句として知られる特定の構文を提供します。グラフパターンは与えられた条件と制約を満たす頂点と辺にマッチします。
(v) は頂点の変数vを表します
- は,(source)-(dest)のように無向の辺を示す
-> はソースから宛先への外へ出ていくエッジを示す
<-は宛先からソースへ入ってくるエッジを示す
[e]はエッジ変数のeを表す
また、graph_nameはGraphVizのUIから選択されるため、ここでは省略してください。
同じ日にアウトバウンドとインバウンドで500以上の転送があったアカウントを探しましょう。
PGQLクエリは下記のようになります。
SELECT *
FROM MATCH (a)-[t1:transfer]->(a1)
, MATCH (a2)-[t2:transfer]->(a)
WHERE t1.transfer_date = t2.transfer_date
AND t1.amount > 500
AND t2.amount > 500
上記の最初のMATCH句において、(a)は送信元の頂点、(a1)は送信先を示し、[t1:transfer]はそれらを結ぶエッジを示します。transferは、t1のエッジがTRANSFERというラベルを持つことを指定しています。2つのパターンの間にあるカンマ(,)はAND条件です。
GraphVizアプリケーションのPGQL Graph Queryテキスト入力ボックスに、クエリをコピー&ペーストして、実行を押します。結果は下図のように表示されるはずです。ハイライト設定で、xxx-yyy-で始まる口座は赤色(=該当の口座)で表示され、xxx-zzz-はオレンジ色(=他の口座)で表示されています。
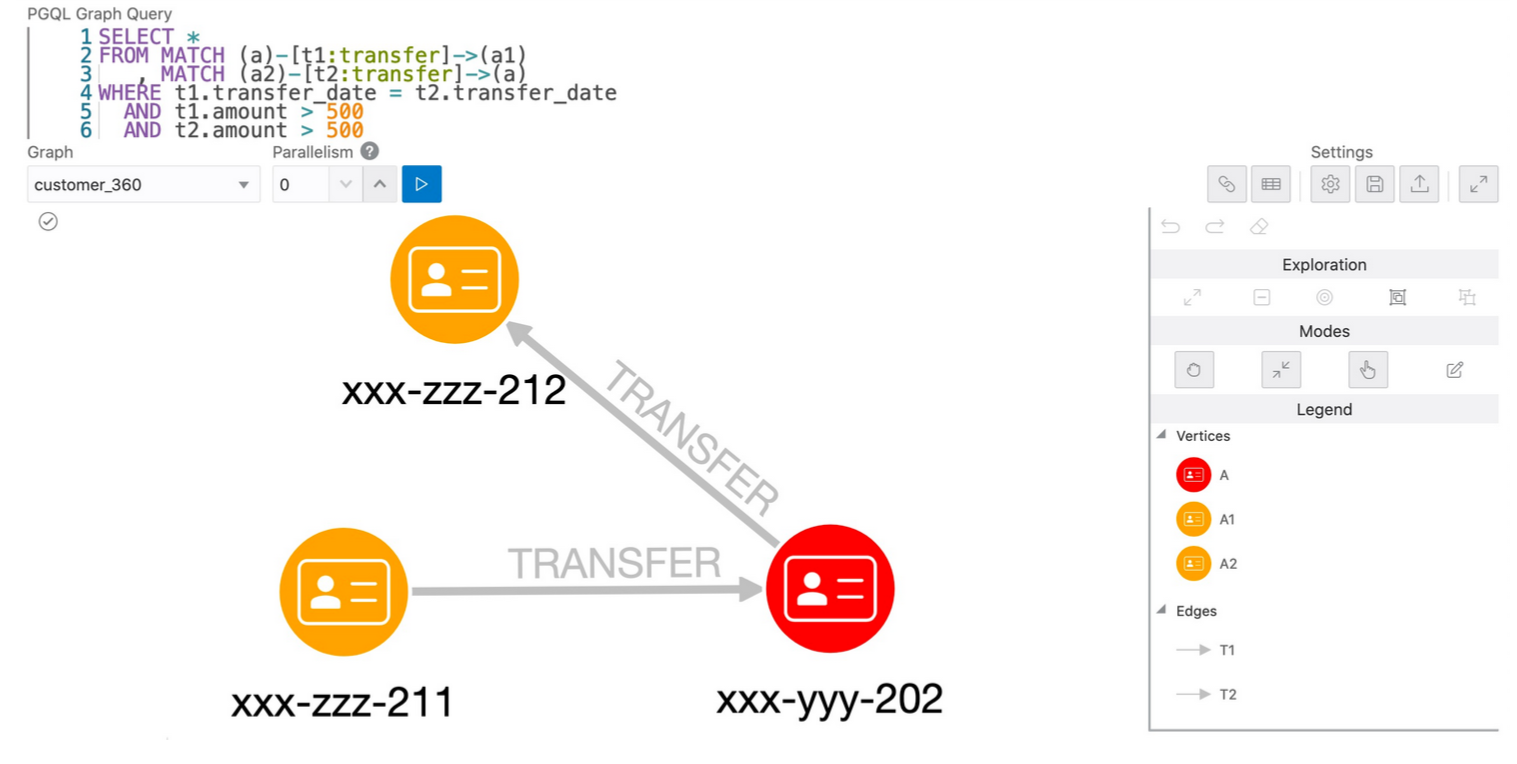
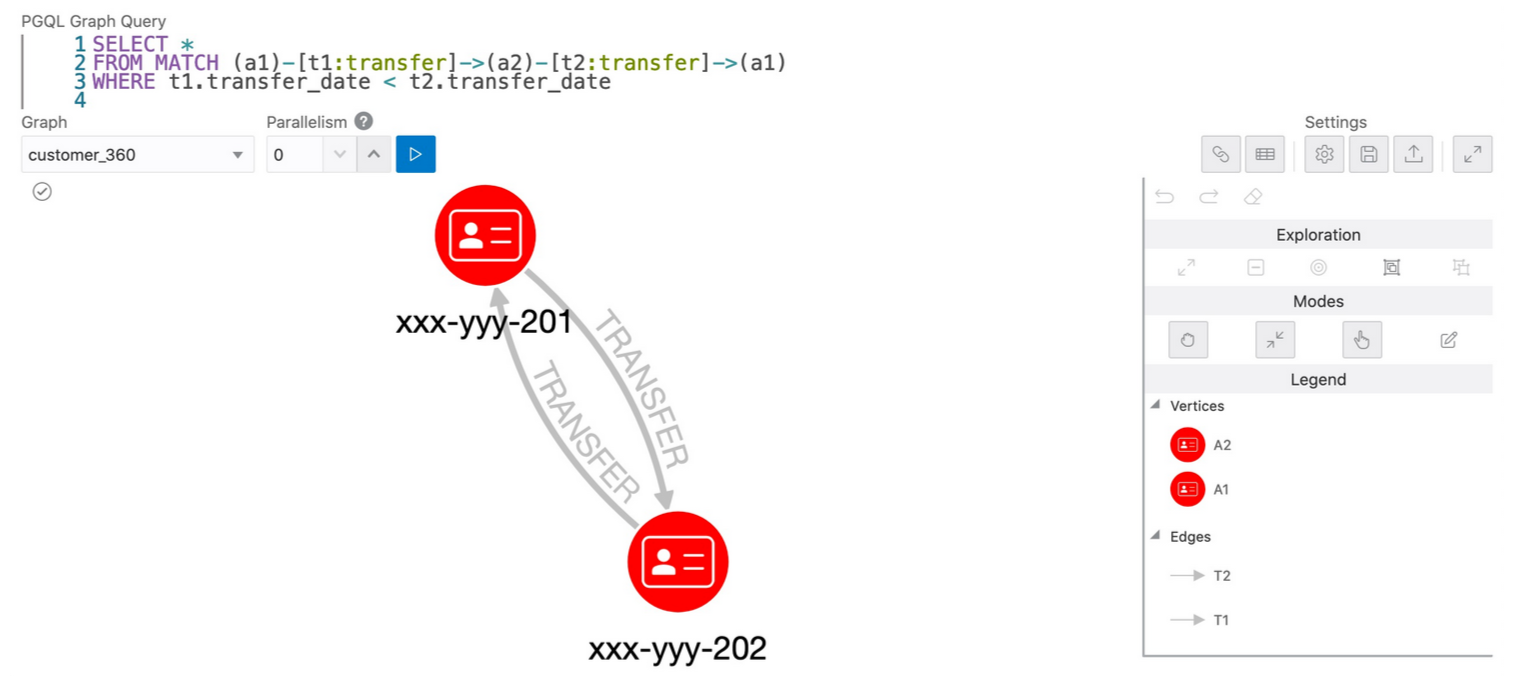
次のクエリは、同じ2つの口座への送金と口座からの送金、つまりa1->a2、a2->a1というパターンを見つけるものです。クエリは次のようになります。
SELECT *
FROM MATCH (a1)-[t1:transfer]->(a2)-[t2:transfer]->(a1)
WHERE t1.transfer_date < t2.transfer_date
GraphVizアプリケーションのPGQL Graph Queryテキスト入力ボックスに、クエリーをコピー&ペーストし、実行すると、下記のようになります。
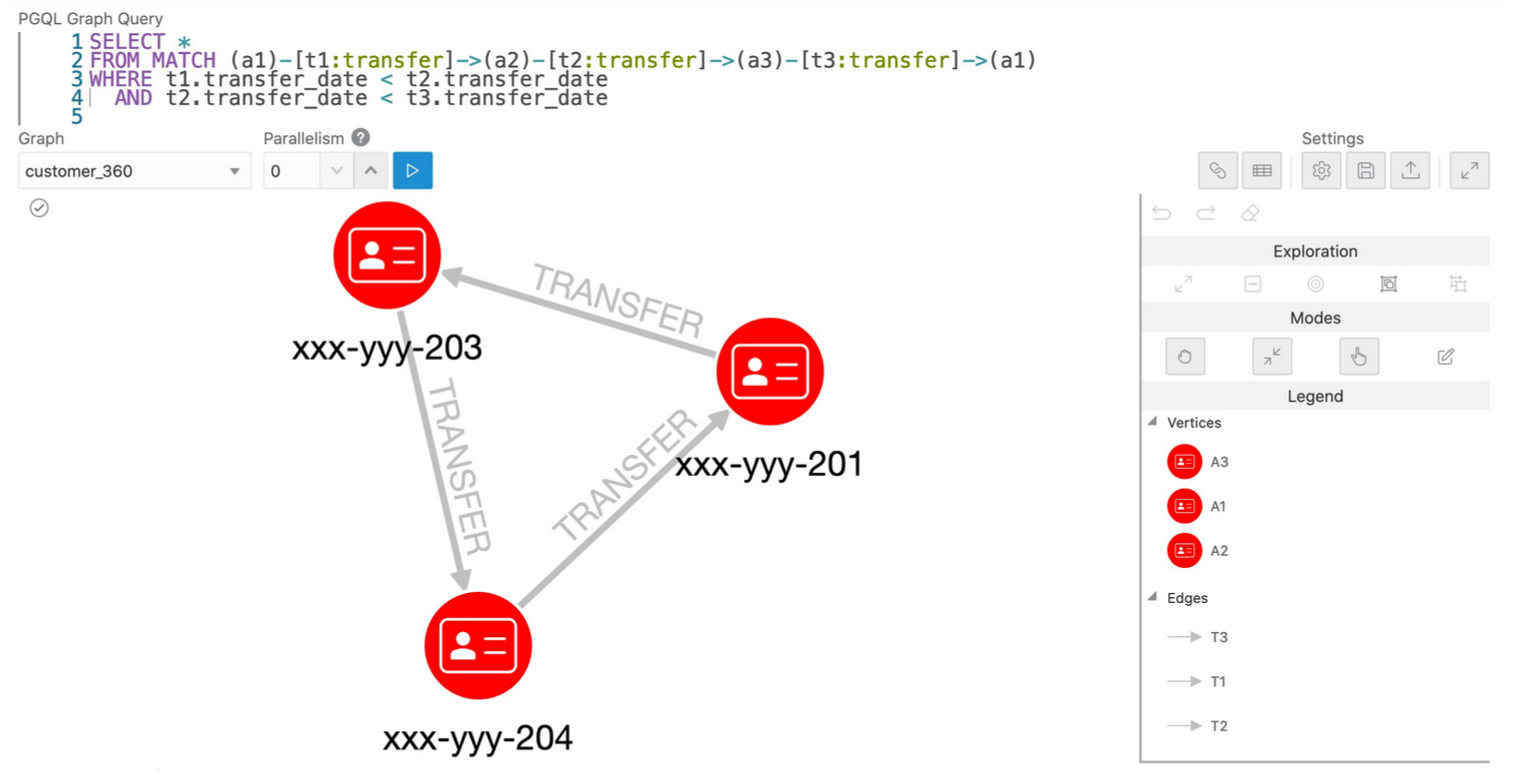
次は、そのクエリにもう1つアカウントを追加して、3つのアカウント間の循環的な転送パターンを探してみましょう。
SELECT *
FROM MATCH (a1)-[t1:transfer]->(a2)-[t2:transfer]->(a3)-[t3:transfer]->(a1)
WHERE t1.transfer_date < t2.transfer_date
AND t2.transfer_date < t3.transfer_date
GraphVizアプリケーションのPGQL Graph Queryテキスト入力ボックスに、クエリーをコピー&ペーストし、実行すると、下記のようになります。
これで基本的な分析クエリや可視化の手順を行うことができました!
参考資料
少し前のv21.4ですが日本語のマニュアルはこちら