ノベルワークスのとっしー(@tossy)です.
2024年 7月9日のAWS Immersion Dayに参加してきました🙌
今回の内容は 生成AIを体験してみようということで、awsで作成できる2種類の生成AIサービスを体験してきました。
こちらのイベントになります。
今回体験したAIサービスについて
以下の2つのサービスを体験しました。
Amazon Bedrock
Amazon Bedrockとは大手 AI 企業からの高性能な基盤モデル を選んで使用できる、フルマネージドサービスです。大手AI企業からの高性能な基盤モデルを手軽に使うことができます。
基盤モデルとは?:
基盤モデルは様々なデータを学習することで、より汎用的な使い方をすることを目指しているモデルです。これは、通常のモデルが特定の問題を解決するために、問題に関する限定されたデータを学習させて作成されるのとは対照的です。
生成 AI の活用における難しさ
生成AIを実際に活用していくには様々な課題があります。例えば以下のようなものです。
- 生成 AI の進化への追従
- 日々新しくなっていくAIに合わせて、そのサービス自体も新しくなっていき、次々と更新されていきます。生成AIを活用するには、現在のAIの動向や使っているAIサービスの変化などに常に気を配る必要があります。
- インフラストラクチャの管理
- 各モデルごとの環境構築と機械学習の知識に加えてカスタマイズのための大規模な計算リソース • インフラの維持管理など、様々なことに気を配る必要があります。
- プライバシーとセキュリティ
- モデル自身がデータを漏洩させてしまうリスクや、外部APIを使うことによってデータが漏洩してしまうリスクが出てきます。
そして、これらの課題を一気に解決してくれるのが、Amazon Bedrockなのです。
基盤モデルの提供企業
提供企業はAnthropic、Cohere、Meta、Mistral AI、Stability AI、および Amazonなどです。
セキュリティ面
各社によってそれぞれ特徴も異なっており、画像生成に強いものや、コストパフォーマンスや軽量さが重要視されているものや、知性が高く、最も正確な回答をするものだったりと様々です。
また、セキュリティに関しても
・ISO, SOC, CSA STAR レベル2 コンプライアンス基準の対象
・HIPPA の対象
・GDPR に準拠して利用可能
・基盤モデルの入出力がモデルプロバイダーに共有されたり、モデルの改善に利用されることはないと明記されいる
・データはお客様の VPC (仮想プライベートクラウド) を離れない
となっていてセキュリティ面にもかなり力が入っているのが伺えます。
個人的には、お客様の VPC (仮想プライベートクラウド) を離れないという点がセキュリティとして安心感がありました。
これは、ChatGPTなどのように外部のAPIを使ってサービスを構築するのではなく、自社内のサービスによって完結することを意味しています。これにより、外部APIのデータの取り扱いの変更の懸念や、APIを提供している企業でのデータ漏洩の心配が無くなります。
モデルの微調整
基盤モデルは用途に応じて微調整をすることが可能です。これにより、回答の精度や柔軟性を上げることができます。これにより話し方のカスタマイズや、必要ある情報にのみ回答を絞ったりと課題に対して、より有効的な使い方ができます。
Amazon Kendra
次にAmazon Kendraについてですが、このサービスはとてもシンプルです。
しかし、シンプル故に強力であり、ほとんど手を加える必要なく、そのまま使用しても十分使用できるサービスになっています。
簡単に説明すると、Kendraは機械学習を用いた企業向けの検索サービスです。企業内の大量のドキュメントの中から必要な情報を効率よく、簡単に取得することができます。検索は自然言語で行うことができ、例えばKendraに「システムAの、どこどこの仕様を教えて」と入力すると、Kendraがそれに関する情報と、その内容が書かれているファイルも一緒に出力してくれます。対話型AIのように、欲しい情報を自然言語で入力出来るのはとても使い勝手が良いです。
以下はKendraの役割に関する図です。
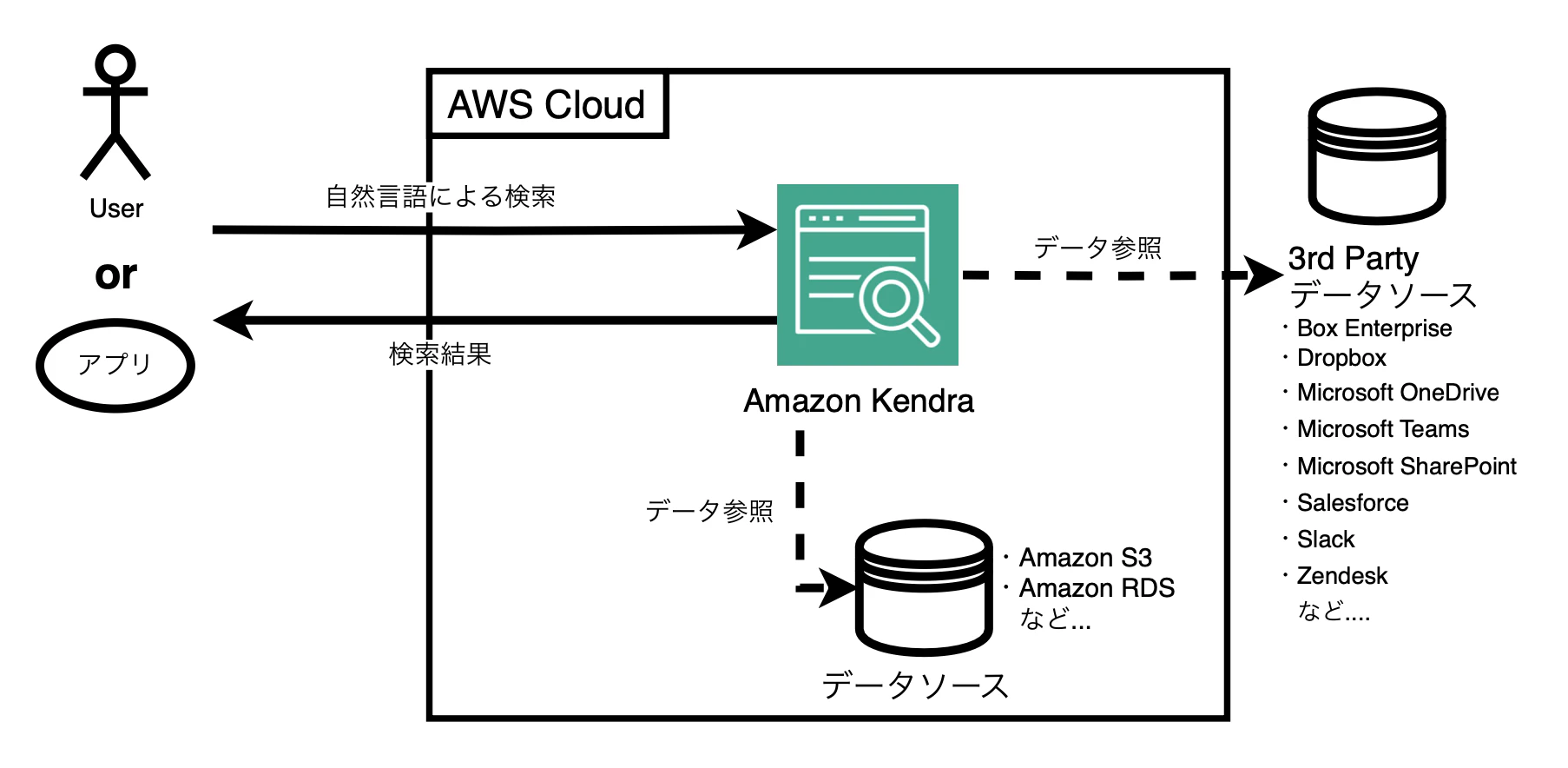
以下は簡単なRAGのアーキテクチャについての図です。Kendraの機能を使って、後ほど説明するRAGを構築するのが一般的なようです。この図のアプリの部分を丸々Kendraで置き換えることができます。
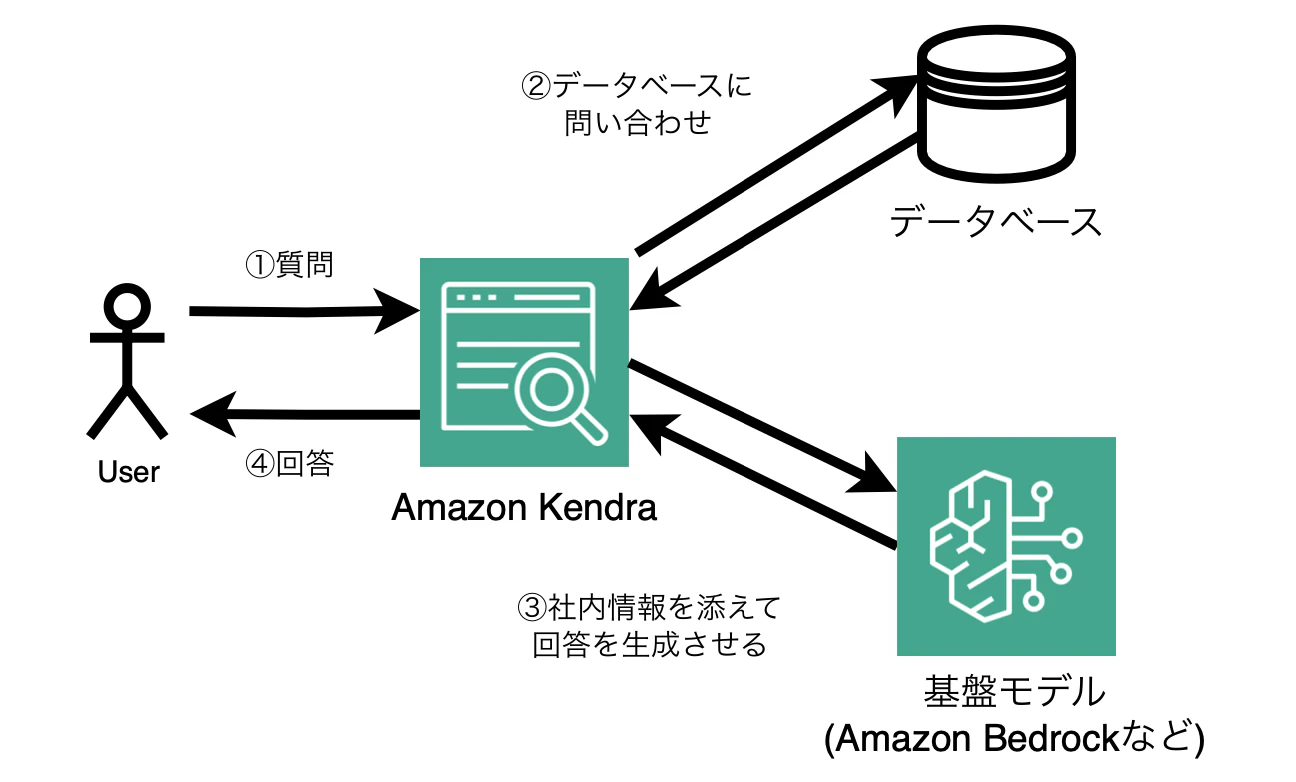
RAGについて
個人的に本イベントで一番印象に残った内容です。
RAGは、Retrieval Augmented Generationの略であり、生成AIモデル(例えば、GPT-3など)に情報を取り出す仕組みを組み合わせた技術です。
以下のような手順で情報を取り出します。
- 情報の取得:まず、質問に関連する情報を大規模なデータベースや知識ベースから取り出します。
- 回答の生成:取得した情報を元に、AIモデルが回答を生成します。
用途としては、社内の膨大な資料の中から、AIに適切な説明と資料を用意してもらうといった感じです。
個人用途として、これを仕様書の検索などに使いたいなと思いました。プログラムに関する仕様をあちこち散らばったドキュメントから取得してきて、その概要とドキュメントまで揃えて教えてくれるので、AIが間違っていそうなことを発言しているとすぐにドキュメントで確認することができます。
ハンズオン内容
最初は30分ほどスライドでの座学があり、その後は実際に手を動かしながらAWSのサービスを試しました。
Amazon Bedrock
まずAmazon Bedrockを試しました。デモ環境はAWS側で構築してくれていて、後はAmazon BedrockでどのAIサービスを使うかを選択するだけという状態でした。
コンソール内から手軽に使うAIを選択することができ、とても簡単に各AIを試すことが出来ました。
今回の環境は、AWSがオープンソースで提供している(2024/07/09時点)generative-ai-use-cases-jp(略称: GenU)を用いて構築されていました。GenU は生成 AI を安全に業務活用するための、ビジネスユースケース集を備えたアプリケーションです。
GenUでユースケースに応じた環境のインフラやUIなどを構築し、AIの中核を担う部分をAmazon BedrockやSageMakerなどのAI基盤で構築するといった感じです。
デモ環境のGenUはAI基盤にはAmazon Bedrockを採用していました。
対話型AI
初めに対話型AIを試しました。こちらの対話型AIもChatGPTと同じようなUIで、操作にすぐに慣れることが出来ました。試したのはAnthropic社のClaude3Haikuで、GPT3.5に比べて格段にレスポンスが速いのが印象的でした。他にもプロンプトによるモデルの微調整も試しました。モデル微調整の方法はとても簡単で、AIとチャットする画面の上部にプロンプトを設定するところがあり、自然言語で内容を指定します。幾つか質問を投げてみたのですが、回答の精度も申し分なく、GPT3.5以外にもこのような対話型AIがあることに驚きました。
画像生成AI
次に画像生成AIも試しました。使用したモデルは、stability.ai社のStable Diffusion XL1.0です。画像生成AIはほとんど使ったことが無かったのですが、こちらが意図した画像をある程度的確に作ることができました。しかし、戦闘機のドッグファイトシーンなどの激しい動きのある絵や、特定の動き(プログラミングする〜 など)を指定した時にうまく画像が生成されませんでした。いくつか、クスっとくる画像も生成していました。
Amazon Kendra
次にAmazon Kendraを試したのですが、これが優れもので、欲しい情報を自然言語で入力するだけで欲しい結果が返ってくるのが魅力的でした。本セミナー内ではKendraについて、「まだKendraに情報を類推する能力はあまり無く、新人社員のようなそれについてあまり知らない人が、ドキュメントを参考に回答を返してくれるイメージ」と述べられていました。しかし、ChatGPTのような優れた回答能力に加えて、信頼できる情報である、ドキュメント自体を持ってきてくれるというのは大変便利であり、これはあらゆる企業で重宝すると考えます。
活用例も幅広く、アイデア次第ではどんなものにでも応用できそうです。例えば、弁護士が法律について調査する場合を考えます。弁護士は最新の法律に加え、過去の裁判の判例を参照する必要があります。通常、膨大な判例データベースから関連する情報を手作業で探し出すのは時間と労力がかかります。そこでKendraを使用して自然言語で検索することで、このプロセスを大幅に効率化が期待できます。
具体的には、この事例では、以下のような場合においてKendraが活用すると推測します。
- 高度な検索機能を利用して、自然言語で特定の事例が判例に該当するかどうかを調べる場合
- 判例に対し、根拠を確かめるために該当する情報が欲しい場合
Amazon Kendraであればこの2つを迅速に提供することができます。
Amazon Kendraは例に上げた法律分野に限らず、医療、金融、教育など、さまざまな分野での情報検索やデータ解析を支援するツールとして活用できます。例えば、医療分野では、医師が患者の病歴や最新の研究成果を迅速に検索する際に役立ちますし、教育分野では、学生や研究者が学術論文や参考文献を効率よく探し出すことが可能です。
所感
公演中に「AIは人間にとってどのような部分を自動化してくれるのか」というお話しがあり、とても印象的であったので最後に紹介したいと思います。簡潔に説明すると、次のようなことが述べられていました。
AIによって、普段手作業で行なっていた非構造化データ(テキストや画像、動画や音声など)を構造化データ(JSONやCSVなどのプログラムで扱いやすいデータ)に変換するという作業を、自動的に効率良くこなすことができるようになった。
世の中の90%以上のデータが非構造化データで保管されていると言われています。かつては人手で非構造化データを構造化データに変換していましたが、現在ではAIがこの作業を驚異的なスピードで行えるようになっています。これにより、世界中のデータが意味を持つものに変わり、それを活用して新たな創造に繋げることが、最近のAIビジネスの一つとなっています。
今やデータは「新しい石油である」と言われるほどの価値があります。それでは、AIによる構造化データの生成は石油採掘に類するものでしょうか?AIがデータの価値を向上させるのに大きな役割を果たしていることは間違いありません。今後、構造化データを扱う機会が格段に増えると予測します。今回のセミナーを通して、それらのデータを正しく効率的に扱えるようになるために、アルゴリズムやデータサイエンスなどの学びを深めていきたいと感じました。