はじめに
クレジットカードをはじめとする金融サービスの不正利用検出は、サービスを提供する企業にとって重要な課題の一つであり、不正なトランザクションやアカウント活動を正確に検出することが求められます。
一般的な機械学習アルゴリズムはデフォルトでは学習時に以下のような条件を考慮せず、それぞれのトランザクションを等しく扱う傾向があります。
- 正常利用に比べて不正利用ははるかに少ない(クラスの不均衡)。
- 不正利用を見逃してしまった場合のコストは、正常なトランザクションを不正と誤検知するコストよりもはるかに高い。
上記のような条件を加味し、金融サービスを提供する企業における不正利用による損失の最小化等、ビジネス観点でより実用的な機械学習モデルの構築を目指すのが、 「コスト考慮型学習(Cost-Sensitive Learning, CSL)」 によるアプローチになります。
本記事では、二値分類タスクにおけるコスト考慮型学習に焦点を当てています。
コンペ等で実施される通常の機械学習における"良いモデル"と、コスト考慮型学習における"良いモデル"の考え方には以下のような違いがあります。
- 通常の機械学習:
- 誤分類数がより少ないモデルを良いモデルとする(つまり、正しいクラスを予測できた数が多いモデルが良いモデルとされます)。
- コスト考慮型学習:
- 誤分類によって生じるコストがより小さいモデルを良いモデルとする。
ユースケース例
ユースケースとしては金融サービス以外には以下が挙げられます。
- 通信会社における顧客の解約予測:
- 偽陽性(解約しない顧客を解約すると予測)に比べ、偽陰性(解約する顧客を解約しないと予測)に高いコストを割り当てることで、通信会社は潜在的な解約者をより正確に特定できる。
- 重症化しやすい病気への罹患予測:
- 偽陽性(罹患していないが罹患していると予測)に比べ、偽陰性(罹患しているが罹患していないと予測)に高いコストを割り当てることでより早期発見につながり、治療コストを削減することができる。
- 製造業における製品の不良品予測:
- 偽陽性(不良品でない製品を不良品と予測)に比べ、偽陰性(不良品である製品を不良品でないと予測)に高いコストを割り当てることで、製造業者は不良品による事故等を減らすことができる。
コスト考慮型学習の基本
コスト考慮型学習の重要なコンセプトは以下のようなコスト行列を導入することです。
以下はクレジットカードの不正利用検知を対象としたコスト行列の一例です。
※不正利用とモデルが判断した場合は決済を中断し、ユーザーの再認証を実施すると仮定
| 実際に不正利用 | 実際に正常利用 | |
|---|---|---|
| 不正利用と予測 | - | ユーザビリティ低下に伴う将来的な損失 |
| 正常利用と予測 | 不正利用による損失 | -(購入による利益) |
このコスト行列を学習アルゴリズムや予測フローに組み込むことで全体的なコストを最小化するように予測を最適化することができます。
なお、実際のビジネス現場では対象のドメインやビジネス構造に基づくより緻密なコスト設計が必要となるのでご注意ください。
コスト考慮型学習は主に以下の2つにカテゴライズできます。[1]
-
Direct Cost-sensitive Learning :
- 誤分類コストを学習アルゴリズムに直接導入し学習時に利用する手法。
- 例えば、CSTree(Ling et al., 2004) は、誤分類コストを直接決定木の学習アルゴリズムに導入しており、通常の決定木アルゴリズムは情報利得やジニ不純度などの基準を使用してデータを分割しますが、CSTreeでは誤分類コストを最小化する分割を選択することで誤分類のコストが高いクラスの誤分類率の低減を図っている。
-
Cost-Sensitive Meta-Learning:
- 学習データに対する前処理あるいはモデルの出力値に対して処理を行うことで間接的に誤分類コストを考慮する手法。任意の学習アルゴリズムに適用可能。
- 例えば、コスト行列に基づいて予測確率に対してクラスラベルを割り当てる際のしきい値を調整する手法(thresholding)がある。
コスト行列について
コスト考慮型学習に欠かせないコスト行列ですが、作成にあたり注意すべき点が2つあります。
| 実際に不正利用(1) | 実際に正常利用(0) | |
|---|---|---|
| 不正利用と予測(1) | c11 | c10 |
| 正常利用と予測(0) | c01 | c00 |
- c10 > c00 および c01 > c11を満たす。(分類を誤った際のコストの方が大きくなる条件)
- c00 ≧ c10 かつ c01 ≧ c11(不正利用と予測すると常にコストが最小化される条件) あるいは、c10 ≧ c00 と c11 ≧ c01(正常利用と予測すると常にコストが最小化される条件)を満たしてはいけない。
誤分類コストの設定方法によってコスト行列は以下の2パターンに分けられます。[2]
-
Class-dependent cost-matrix :
- 予測結果のそれぞれのクラス(TP/FP/TN/FN)のコストを、データによらず同じ値で一律に設定できる場合はこちらを採用する。
- 例えば全データに対して一律にc11 = 0、c10 = 50、c01 = 200、c00 = 0を適用する場合。
-
Instance-dependent cost-matrix :
- 予測結果のそれぞれのクラス(TP/FP/TN/FN)のコストが、データによって変動する場合はこちらを採用する。(決済金額に応じて誤分類のコストが変動するような場合など)
- 例えば以下のようにサンプル毎にコスト構造が異なる場合。
- サンプル1はc11 = 0、c10 = 50、c01 = 200、c00 = 0を適用。
- サンプル2はc11 = 0、c10 = 80、c01 = 900、c00 = 0を適用。
- サンプル3はc11 = 0、c10 = 10、c01 = 100、c00 = 0を適用。
- ・・・・
thresholdingの実装
Cost-Sensitive Meta-Learningの一つであるthresholdingの導入方法について紹介します。
最適な閾値は以下の通り計算します。[3]
\text{Threshold} = \frac{c_{10} - c_{00}}{c_{10} - c_{00} + c_{01} - c_{11}}
thresholdingは以下のようによりコストが低くなるように分類(予測)を行います。
- 正例と分類したときのコスト > 負例と分類したときのコスト → 負例と予測
- 正例と分類したときのコスト < 負例と分類したときのコスト → 正例と予測
scikit-learn の乳がんデータセットを用いた実装例を以下に示します。
コストの観点から、FNすなわち良性と分類されたが実は悪性だったという誤分類が、FPの5倍のペナルティがあるというシチュエーションを想定して以下のようにコスト行列を作成しました。
| 実際に悪性(1) | 実際に良性(0) | |
|---|---|---|
| 悪性と予測(1) | c11=0 | c10=1 |
| 良性と予測(0) | c01=5 | c00=0 |
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
from sklearn.model_selection import train_test_split
def calculate_threshold(cost_fp: int, cost_fn: int, cost_tp: int, cost_tn: int) -> float:
"""
Given the cost values, calculate the threshold for cost-sensitive learning.
The function checks if the given cost values meet the required conditions,
calculates the threshold, and returns it. If the conditions are not met,
the function raises a ValueError.
Parameters:
cost_fp (int): Cost of False Positive.
cost_fn (int): Cost of False Negative.
cost_tp (int): Cost of True Positive.
cost_tn (int): Cost of True Negative.
Returns:
float: The calculated threshold value.
Raises:
ValueError: If the provided cost values do not meet the required conditions.
"""
# Check conditions: cost_fp > cost_tn and cost_fn > cost_tp
if not (cost_fp > cost_tn and cost_fn > cost_tp):
raise ValueError("Conditions not met: cost_fp > cost_tn and cost_fn > cost_tp are required")
# Check conditions: cost_tn >= cost_fp and cost_fn >= cost_tp or cost_fp >= cost_tn and cost_tp >= cost_fn
if (cost_tn >= cost_fp and cost_fn >= cost_tp) or (cost_fp >= cost_tn and cost_tp >= cost_fn):
raise ValueError("Conditions not met: Inappropriate cost condition combination exists")
# Calculate the threshold
threshold = (cost_fp - cost_tn) / (cost_fp - cost_tn + cost_fn - cost_tp)
return threshold
# データセットのロード
data = load_breast_cancer()
X, y = data.data, data.target
# データセットをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
# Logistic Regressionモデルのインスタンス化と訓練(通常の学習)
clf_normal = LogisticRegression(random_state=42, solver='liblinear')
clf_normal.fit(X_train, y_train)
# 通常の予測とConfusion Matrix
y_pred_normal = clf_normal.predict(X_test)
conf_matrix_normal = confusion_matrix(y_test, y_pred_normal)
# コストマトリックスの定義(偽陽性と偽陰性のコスト)
cost_fp = 1 # c10
cost_fn = 5 # c01
cost_tp = 0 # c11
cost_tn = 0 # c00
# しきい値の計算
threshold = calculate_threshold(cost_fp, cost_fn, cost_tp, cost_tn)
# しきい値を使用して予測とConfusion Matrix
y_pred_proba = clf_normal.predict_proba(X_test)[:, 1] # クラス1の確率を取得
y_pred_thresholding = (y_pred_proba >= threshold).astype(int) # しきい値で二値化
conf_matrix_thresholding = confusion_matrix(y_test, y_pred_thresholding)
# Confusion Matrixの描画
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
# 通常のConfusion Matrixの表示
ConfusionMatrixDisplay(conf_matrix_normal, display_labels=['Negative', 'Positive']).plot(ax=ax[0])
ax[0].set_title('Normal Prediction')
# しきい値を使用したConfusion Matrixの表示
ConfusionMatrixDisplay(conf_matrix_thresholding, display_labels=['Negative', 'Positive']).plot(ax=ax[1])
ax[1].set_title('Thresholding Prediction')
# サブプロット間の間隔を調整
plt.subplots_adjust(wspace=0.5)
plt.show()
出力結果:
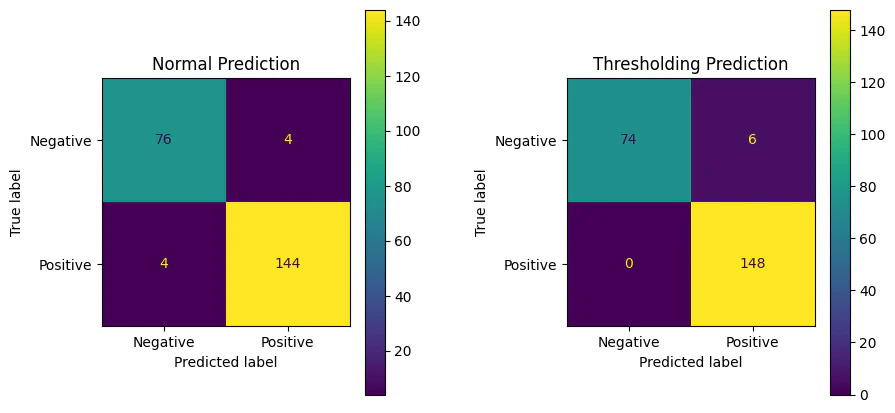
左が通常通りモデルの出力を反映、右がモデルの出力した予測確率に対してthresholdingを反映した結果になります。
thresholdingでFNに対するコストを高く設定することで、FNが通常通りのモデルだと4に対して、thresholdingを適用したモデルだと0となり期待通りの結果が得られました。
おわりに
今回はClass-dependent cost-matrixを用いた例で、Cost-Sensitive Meta-Learningの一つであるthresholdingについて実装してみました。
追々Instance-dependent cost-matrixに関する既存の研究や実装方法についてまとめて記事にしたいと思います。