3つのOCRエンジンをサポートするIBMRPA
IBM RPAでは複数のOCRエンジンをサポートしており、ツール上から読み取り範囲の指定などをシームレスに行うことが可能です。OCR機能と連携することで、例えばPDFで送付されてきた注文書を読み取り、システムに入力するといった一連のシナリオをボットによって実装することが可能です。この記事ではIBMRPAでの具体的なOCR機能の使用方法について整理したいと思います。
サポートされるOCRエンジン
IBMRPAでは以下の3つのOCRエンジンをサポートします。
-
Tesseract
オープンソースのOCRエンジンです。 -
ABBYY
ABBYY社のOCRエンジンです。IBMRPAに組み込まれており、追加のライセンス費用無しで使用することが可能です。サーバー側にモジュールがインストールされ、サーバー側で動作します。 -
Google Cloud Vision
Googleが提供するOCRエンジンです。別途ライセンスが必要ですが、APIキーを取得してツールやコマンドに設定することで利用することが可能です。
コマンドでの使用例
様々なコマンドでOCRを使用することが可能ですが、代表的なものは以下の3つです。

- OCRによるクリック
画面上の領域をOCRにより取得し、該当座標をクリックします。 - OCRによるコントロール・テキストの取得
画面上のテキストをOCRによって取得します。 - OCRによるPDFテキストの取得
PDFファイルからOCRを使用してテキストを取得します。
実際に「OCRによるPDFテキストの取得」コマンドを使用してみました。このコマンドを使用するには以下の項目を指定する必要があります。
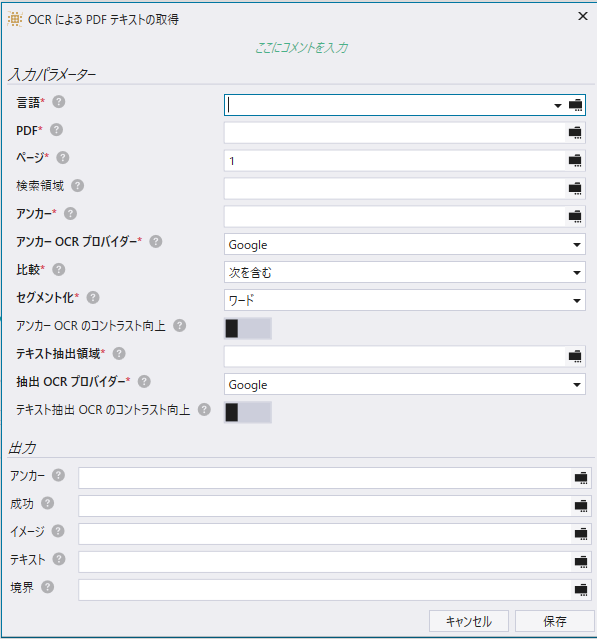
これらを一つずつ指定するのは少し面倒なのですが、「PDFテキストの抽出」ツールを用いることで、読み取り対象のPDFファイルを用いて、実際にOCRを動作させながら、読み取り領域を簡単に指定することが可能です。今回のケースでは、OCRエンジンとしてABBYYを選択し、「氏名」という文字をアンカーに指定し、そこからの相対的な位置で実際の氏名「田中太郎」を正しく認識することができました。(なお、このバージョン21.0.3ではTesseractでは英語のみ正しく動作し、日本語の認識は動作しませんでした。)
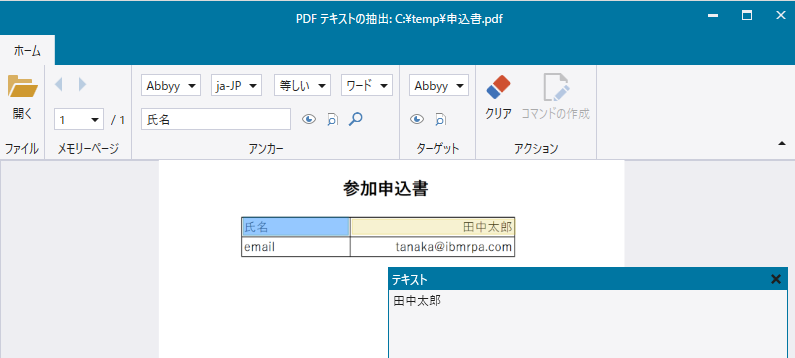
具体的な手順は以下の通りです。
- アンカー取得用OCRエンジンと言語を選択する(今回はAbbyy,ja-JP)
- アンカーとなる領域を選択する
- アンカーとなる文字を入力する
- プレビュー、もしくはアンカーの検索ボタンをクリックし、正しくアンカーが取得できていることを確認する
- ターゲット用OCRエンジンを選択する
- ターゲットの領域を選択する
- プレビューをクリックして結果を確認する
- コマンドの生成ボタンをクリックしてコマンドを生成する
まとめ
いかがでしたでしょうか?IBMRPAでは3つのOCRエンジンをサポートしており、ツール上から簡単にOCR機能を呼び出すことができました。OCR機能を使用することで、画面の上のボタンの位置を探してクリックしたり、PDFファイルからテキストを抽出し、後続のシステムに連携するといった業務シナリオを実装することが可能です。別途ライセンスを購入することなくABBYYを使用できるのは便利ですね。Google Cloud Visionを使う場合にはライセンスの指定が必要なのですが、そちらについても別途記事にしたいと思います。
※Japan Business Automation User Groupのご紹介
IBMのコミュニティーである、Japan Business Automation User Groupでは、IBMのBusiness Automation製品関連の様々な技術情報、イベント情報の参照や、フォーラムを介した技術的な質問を行うことが可能です。是非ご参加ください。 http://ibm.biz/JPBizAutomationUG