はじめに
pandasを使ってインデックスとカラムが整理されていないexcelファイルの処理をする機会があったので、その方法をまとめます。
excelを処理する方法としてopenpyxlなんてのもありますが、.xlsファイルを読み込めなかったり、結局DataFrameの方が処理しやすいのでpandasを使用しています。
ファイル読み込み
import pandas as pd
file = pd.ExcelFile(filename, encoding='utf8')
encodingの指定はよしなに
シート読み込み
sheet_df = file.parse(sheet_name, header=None)
header=Noneは、最初の一行目をカラムとして読み込まないという意味です。カラムが整理されているデータならこちらのオプションはいらないかもしれません。
シート名の取得
全てのシートを利用したい場合は、file.sheet_namesでsheetの名前の配列が取得できるので、以下のように全てのシートをdfに格納することもできます。
sheet_names = file.sheet_names
for i, name in enumerate(sheet_names):
sheet_df[i] = file.parse(name, header=None)
結合されたセルの扱い
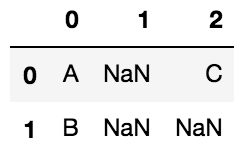
また、結合されたセルでは、結合セル中の左上のセルのみデータが入っており、他はNaNとして扱われます。
例えば、以下のようなセルをpandasで読み込むと、
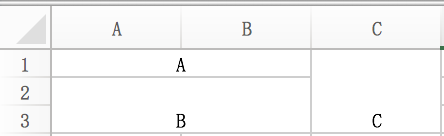
全て結合セル中の最も左上のセルにのみデータが入っているとみなされ、次のようなDataFrameになります。
シートのデータ取得
# 以下の返り値はseries
# n行目取得
sheet_def.iloc[n]
# n列目取得
sheet_def.iloc[:, n]
# m行n列のデータ取得
sheet_df.iloc[m, n]
この他、ilocを使えばスライスのように行と列を指定できます。
シートのデータ処理
# 行ごとに処理
for i, row in sheet_def.iterrows():
print(i, row)
# 列ごとに処理
for i, col in sheet_def.iteritems():
print(i, col)
おわりに
pandasで読み込みさえすればあとはDataFrameとして扱えるので便利です。