はじめに
最近、論文を読んでいたところ、Gated Linear Unit(GLU)がちらほら利用されていました。
具体的には以下の論文になります。
Do Transformer Modifications Transfer Across Implementations and Applications?
Simple Baselines for Image Restoration
そのため、広く一般に使われるようになるような気がしてきたため、CIFAR-100 の識別で実験を行ってみました。
Gated Linear Unit(GLU) とは?
Gated Linear Unit は以下の式で表せる構造になります。
$$
\begin{eqnarray}
GLU(x) = (x W_1 + b_1) \otimes \sigma (x W_2 + b_2)
\end{eqnarray}
$$
$\sigma$ はシグモイド関数になります。
単純に入力をアフィン変換した結果を2分割して、片方にシグモイド関数を適用した後、アダマール積を取る形になります。
なお、pytorch の実装ではアフィン変換を除いた部分が GLU として用意されています。
上記の「Do Transformer Modifications Transfer Across Implementations and Applications?」では、シグモイド関数の代わりに、ReLU、GELU、Swish、恒等関数を利用した実験例が記載されています。
また、それぞれに名前をつけています。
| 名称 | 片側に適用する関数 |
|---|---|
| GLU | Sigmoid |
| ReGLU | ReLU |
| GeGLU | GeLU |
| SwiGLU | Swish |
| LiGLU | 恒等関数 |
この名前が今後広く使われるかは不明ですが
実験
CIFAR100 を利用して実験を行いました。
比較対象として、GeLU と GeGLU を利用しました。
実験条件
実験の際のパラメータを以下に示す。
| パラメータ名 | 値 |
|---|---|
| 学習回数 | 200 epochs |
| バッチサイズ | 128x8 |
| Optimizer | AdamW |
| 学習率 | 1e-3 |
| 学習率のスケジューリング | Cosine Annealing |
| 学習率のウォームアップ | 線形で 5 epochs |
| weight decay | 0.05 |
| mixup alpha | 0.1 |
| cutmix alpha | 1.0 |
| label smoothing | 0.1 |
| 損失関数 | Binary Cross Entropy |
| Data Augmentation | Trivial Augmentation(wide_standard, 31) |
| Stochastic Depth | 0.05 |
Mixup と Cutmix はミニバッチ毎に 50% の確率でどちらを利用するか選択しています。
また、Trivial Augmentation については公式の実装をしています。
モデル
モデルは ConvNeXt を参考に適当に作りました。
データセットが CIFAR100 なので、そのまま ConvNeXt を利用できないため、STEM として 4x4 stride=4 の畳み込みではなく、3x3 stride=2 の畳み込みを利用しています。
また、個人的な趣味で LayerNormalization の代わりに RMS Normalization を利用しました。
各解像度でのブロック数とチャンネル数は以下のようにしました。
| 解像度 | チャンネル数 | ブロック数 |
|---|---|---|
| 32x32 | 96 | 2 |
| 16x16 | 192 | 8 |
| 8x8 | 384 | 2 |
1ブロックの中では、GeLU の場合4倍にチャンネルを増やし、その後元に戻しています。
GeGLU の場合は、6倍に増やしたあと、GeGLU で 3倍に減らし、そこから元のチャンネル数に戻しています。
計算時間
| モデル | FLOPS | パラメータ数 | 学習時間 |
|---|---|---|---|
| GELU | 981,554,688 | 5,413,060 | 142分 |
| GeGLU | 1,096,078,848 | 6,026,308 | 167分 |
なお、学習は Google Colab の TPU で行いました。
学習結果
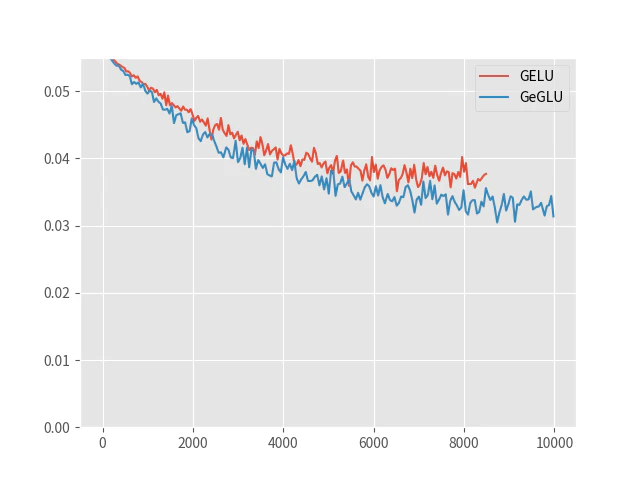
学習損失を以下に示します。X軸は学習時間(秒)です。
検証時正答率を以下に示します。X軸は学習時間(秒)です。
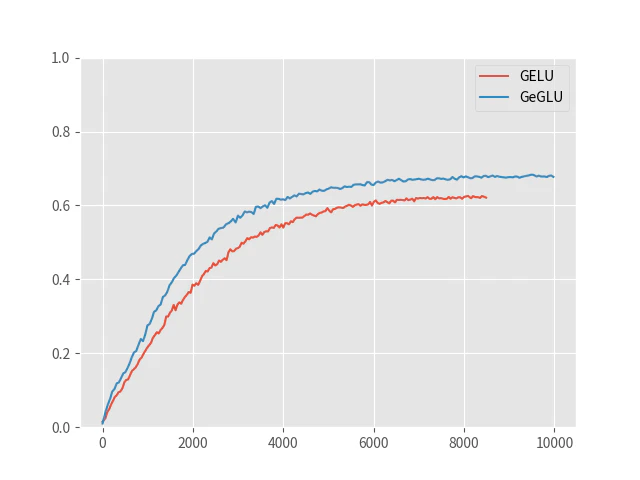
なお、最終的な検証データの正答率は以下の通りです。
| モデル | 正答率 |
|---|---|
| GELU | 62.12% |
| GeGLU | 67.73% |
| WRN-28-10(参考) | 81.75% |
参考に WRN-28-10 で学習した結果も記載しました。モデルの作り方が悪かったのか WRN-28-10 より性能が悪いです。
おわりに
若干モデルの計算量が増えていますが、同じ学習時間で比べても GELU に比べて GeGLU の方が性能が良くなっています。
そのため、GLU の有用性を示せたと考えています。
以上