はじめに
皆さんこんにちは。今回は前回作った自殺ツイートデータセットを用いてBERTモデルを作成する前に、
EDAと自殺ツイートに特徴的なワードからルールベースでも検出できるのか試してみたいと思います。
▼前回記事はこちら
自殺ツイートのEDA
EDAの流れとしては
データの分布、文字数の確認
↓
ginzaで形態素解析
↓
自殺ツイート・無関係ツイートに頻出する名詞、動詞、形容詞の確認していきます。
環境はgoogle colabです。
①まずは必要なライブラリをインポートします。
# 必要なライブラリのインストール
!pip install -q ginza ja_ginza datasets transformers[ja]
import spacy
import pandas as pd
import numpy as np
from tqdm.auto import tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
②続いてデータを読み込みます。
train_df = pd.read_csv("/content/drive/MyDrive/suicide_detection/input/train.csv")
test_df = pd.read_csv("/content/drive/MyDrive/suicide_detection/input/test.csv")
データを眺めてみましょう。
▼自殺ツイート(suicide=1)

▼無関係なツイート(suicide=0)

③次にラベルの割合を見ていきます。
label_distribution = (train_df["suicide"].value_counts() /len(train_df))*100
label_distribution
0 90.943808
1 9.056192
Name: suicide, dtype: float64
自殺(=1)ラベルは約9%でかなり不均衡です。
④文字数はどれくらいでしょうか?
suicide = train_df[train_df["suicide"]==1]
not_suicide=train_df[train_df["suicide"]==0]
plt.title("suicide")
suicide["tweet"].str.len().plot(kind="hist", color="orange")
plt.title("not_suicide")
not_suicide["tweet"].str.len().plot(kind="hist")
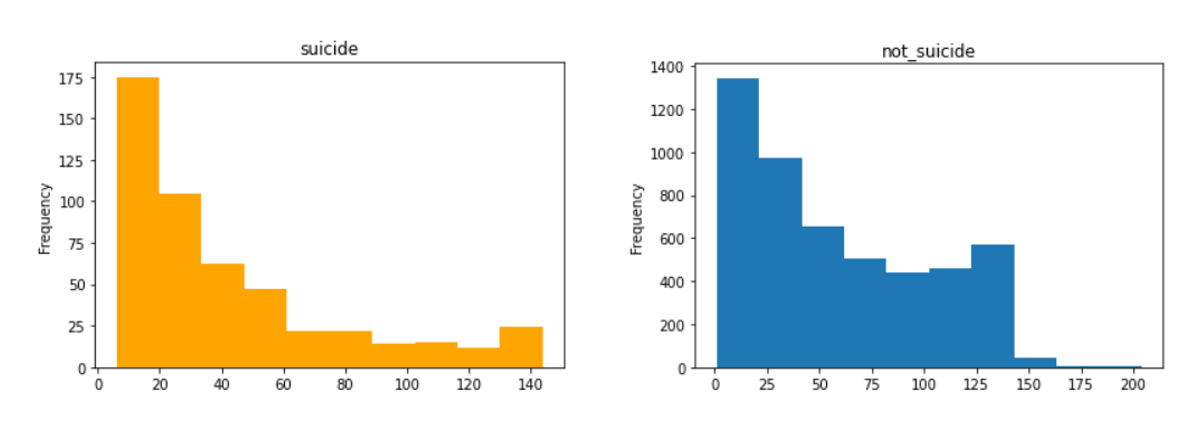
40~50字以下の短文がどちらも多いようです。
⑤train_test_splitでvalidationセットを作成しておきます。
trn_df, val_df = train_test_split(train_df, test_size=0.1, stratify=train_df["suicide"], random_state=SEED)
⑥自殺ツイートと無関係ツイートの品詞の出現頻度を確認します。
ginza_nlp = spacy.load("ja_ginza")
counter = Counter()
for text in tqdm(train_df[train_df["suicide"]==1]["tweet"]):
# 名詞かつ文字数が2以上の単語のみカウント
counter.update([str(t) for t in ginza_nlp(text) if (t.pos_ == "NOUN") & (len(t) > 1)])
for text in tqdm(train_df[train_df["suicide"]==0]["tweet"]):
# 名詞かつ文字数が2以上の単語のみカウント
counter.update([str(t) for t in ginza_nlp(text) if (t.pos_ == "NOUN") & (len(t) > 1)])
動詞は"VERB", 形容詞は"ADJ"にします。
結果は下記のとおりとなりました。自殺ツイートのみに出現しているワードがあるようです。
自殺ツイートの名詞は自分や仕事に対する言葉が多く、動詞は「消え、疲れ」などネガティブなワードが目立ちます。形容詞も「苦しい、無理、しんどい」など悲痛の声が読み取れます。
無関係なツイートでは「今日」が頻出しているのに対し、自殺ツイートは「明日」が頻出しており、否応なしにやってくる明日や未来に対しての不安が大きいことが読み取れますね。

ルールベースでの検出
自殺ツイートに頻出しているワードをピックアップしてSuicide_wordとし、ツイート中にこのワードが入っていたら自殺ツイートとする予測を行います。
SUICIDE_WORDS = ["自分", "仕事","ごめん","消え","疲れ","辛い","苦しい","しんどい"]
def has_suicide_words(text):
for suicide_word in SUICIDE_WORDS:
if suicide_word in text:
return True
return False
val_rule_preds = val_df["tweet"].map(has_suicide_words).astype(int)
F1スコアを確認します。
f1_score(val_df["suicide"], val_rule_preds)
0.2058823529411765
うーん、よくないですね。。
これを超えられるようなモデル作成を頑張ります。いきなりBERTの前にナイーブベイズもやってみようかなと思っています。
まとめ
自分が作ったデータセットのラベリングに一貫性があるのか確かめる上でもEDAって大事だなと思いました。品詞の頻出語チェックでしっかり分かれていて良かったです。そして、自殺ツイートに出てくる頻出語をみるだけでも、苦しみが伝わってきて胸が締め付けられました。ルールベースでの検出はうまくいきませんでしたが、ナイーブベイズやBERTの力を比較するうえでも試してみて良かったです。
参考
Nishika hate-speech detectionにて公開されているチュートリアルを参考にしました。
https://competition.nishika.com/hate/topics/386