概要
正規表現について調べると、
-
^は行の先頭にマッチする -
.は改行以外の任意の1文字にマッチする -
*は直前の表現の0回以上の連続 -
+は直前の表現の1回以上の連続 -
$は行の末尾にマッチする -
[]は角括弧内の任意の1文字にマッチする -
\[バックスラッシュは直後の1文字のメタ文字をエスケープして、ただの文字として扱う -
[0-9]0から9までの数字
このような基本的なことは調べればすぐに出てくる。
サルにもわかる正規表現
が、そういうことを知っていても
# 4byte文字絵文字や一部の常用でない漢字 を表す
/[\xF0-\xF7][\x80-\xBF][\x80-\xBF][\x80-\xBF]/
# 数字と特定の記号のみ マッチする
/^[0-9 -\/:-@\[-\`\{-\~]+$/
なんだこの暗号は!!とおもったのでいろいろ調べた。
調べたきっかけ
MySQLとLaravelで仕事をしていて、こういうお題が出された。
「4byte文字が含まれていたらバリデーションにひっかかるようにしてほしい」
ヒント:/[\xF0-\xF7][\x80-\xBF][\x80-\xBF][\x80-\xBF]/
https://www.softel.co.jp/blogs/tech/archives/5269
4byteを制御する理由
ユーザが氏名や住所などの入力欄に絵文字を入力すると、MySQL側が4byte文字を受け付けないためにエラーが発生する。
4byte文字の制御はMySQL側でも可能だが、MySQLの設定を変えるとなると(恐らく)既に存在しているデータを入れ直さなければならない。
なので、ユーザが絵文字を入力しようするとバリデーションエラーを返す、という対策をとることになった。
やったこと①
まず初めに、
「4byte文字が含まれていないことをバリデートする」ことが必要なので、
「〇〇が含まれていないこと」を表す正規表現について調べた。
# PATTERNを含まない文字列
^(?!.*PATTERN).*$
// 「こんにちは」を含まない文字列
^(?!.*こんにちは).*$
# 4byte文字を含まない文字列
^(?!.*/[\xF0-\xF7][\x80-\xBF][\x80-\xBF][\x80-\xBF]/).*$
PATTERN には文字列や正規表現が入り、「PATTERNが含まれていないこと」を表すことができる。(否定先読み)
参考:WWWクリエイターズ
x〇〇は何?
\xは、直後に続く16進数で文字コードを指定する(例 \x41なら大文字のAを表す)
https://www.seiai.ed.jp/sys/text/java/utf8table.html
このサイトによると、
xF0-xF7は、4バイト文字の開始バイト
8x,9x,Ax,Bx つまり x80-xBFは、多バイト文字の2バイト目以降 を示す。
他参考:
https://seiai.ed.jp/sys/text/csd/cf14/c14a070.html
やったこと②
電話番号にもバリデーションチェックを入れる必要がある。
氏名等と同様に正規表現で指定しようとしたが、カスタムのバリデーション tel を使えばOKなのでは?
と思い、どんな内容なのかLaravelのソースを見てみると、前述のこれが現れた。
/^[0-9 -\/:-@\[-\`\{-\~]+$/
さっぱりわからない。
バックスラッシュは直後の1文字をエスケープしているだろうけど、この不規則に現れているようにみえるハイフンはなんだ?
「-/:-@[-`{-~」「電話番号 正規表現」などで検索してみても、
ハイフンあり/ハイフンなしの電話番号のバリデーションが出てくる。
そこでふと、数字以外でも、 [A-Z] というように文字を範囲指定したい場合はハイフンを使うことを思い出した。
# 特定の文字のみを含む文字列
[ぁ-んァ-ン0-9a-zA-Z0-9\-]+
ということは、不規則にみえるハイフンも文字コード上での範囲を指定しているかも、と考えて 文字コード を確認してみると、
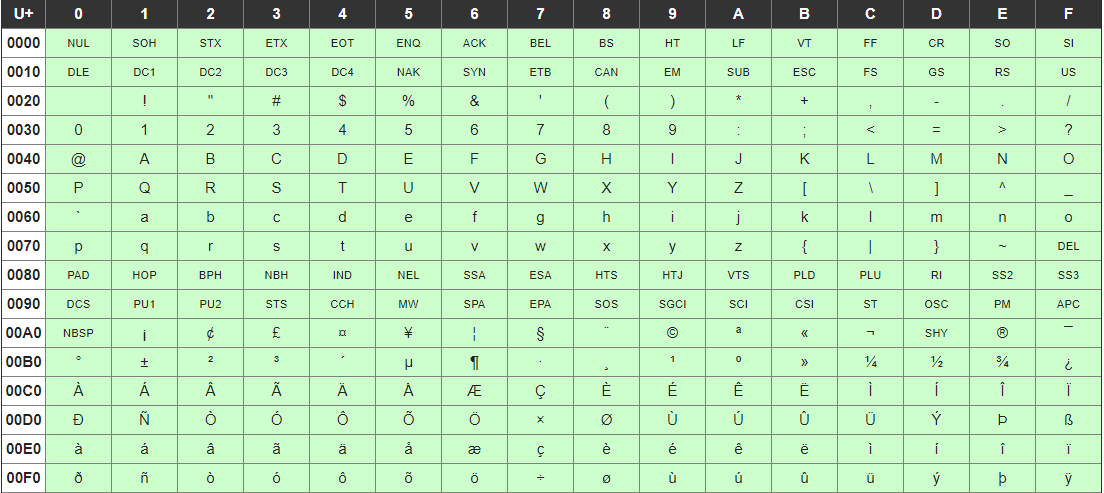
これだ!
分かりやすくするため、エスケープのためのバックスラッシュを除いて-/:-@[-`{-~ を分解してみると、
-/ :-@ [-` {-~
① / までの文字
② : から @ までの文字
③ [ から ` までの文字
④ { から ~ まで の文字
を表していることがわかる。
よって、
# tel のバリデーション
/^[0-9 -\/:-@\[-\`\{-\~]+$/
これは、0から9までの数字と、①~④までの特定の記号のみ、マッチすることになる。
電話番号には このバリデーションを指定すれば、絵文字などの4byte文字も弾くことができる。
UTF-8 と Unicode
UTF-8
UTF-8は1~4バイト(初期の定義では6バイトまで)の可変長コードのこと。
UTF-8は、Unicodeで定義された符号化文字集合をバイト列に変換する方式の一つです。ASCIIコードと互換性をもたせた規格となっているので、多くのソフトウェアで使われています。
UTF-8の仕組み
UTF-8の最初の128文字は、ASCIIとまったく同じです。ASCII文字は1バイトで表現されますが、漢字や仮名文字は3バイト、もしくは4で表現されるので、データサイズはUTF-16(2バイト表現)より大きくなります。
文字コードについては1日では理解しきれなかった・・・。
0x
16進数がでてくると0xという文字をよくみるが、
プログラミングの世界では、16進法であることを示すために先頭に 0x (ゼロエックス)を付ける習慣があるらしい。
16進数っぽいのに0xがついているせいで、初めはよくわからなかった。
そのほか
正規表現によるバリデーションでは ^ と $ ではなく \A と \z を使おう
記事を書くために調べていたら、「体系的に学ぶ 安全なWebアプリケーションの作り方」で有名な徳丸さんがこんなことを書いていた。
PerlやPHPの場合は、文字列の途中に改行があった場合でも、文字列全体を1行と見なします。一方、Rubyの場合や、PerlやPHPで正規表現の m修飾子を指定した場合は、改行を行の区切りと見なし、複数行として処理します。このため、/^xxx$/ (PerlやPHPの場合は/^xxx$/m )という正規表現は、「xxxに一致する行がある場合にマッチ」となります。
大垣さんに限らず大半の方が、正規表現でのバリデーションに ^ と $ を使って完全一致マッチングを指定していますが、これは間違いということになります。それでは、過去のPHP(やPerl等)のスクリプトが、これが原因で脆弱性だらけになるかというと、そうではありません。
なぜなら、PHPやPerlの正規表現のデフォルトは単一行モードであり、文字列の途中の改行の前後で ^ や $ がマッチすることはないからです。
^ や $ を使った場合、完全一致のバリデーションをかけたつもりでも、末尾に改行が含まれる場合はバリデーションにひっかからない・・・ということらしい。
今回の目的である「4byte文字の制御」は、完全一致ではなく、「含まれる場合に弾きたい」ので、問題ないはず。
文字列の先頭・末尾は \A \z で指定できることは知らなかった。Aで始まりzで終わるところにセンスを感じる・・・。