目的
この記事では、ランダムフォレストの流れを図解して説明をしていきます。
(手書きで汚いですが、ご了承ください![]() )
)
ランダムフォレストとは?
ランダムフォレストとは、複数の種類の決定木を組み合わせて分類や回帰(=数字の予測)を行う機械学習のモデルです。
この説明だとなかなかわからないので、具体例で考えていきます。
具体例:病院
「患者のAさんが来て、おそらく1年以内には糖尿病になりそう。でも、確証がない。。。
あ、機械学習でも本当に糖尿病になりそうかどうかを調べてみよう」

このケースの場合は、Aさんが「1年以内に糖尿病なる」か「1年以内には糖尿病にならない」かの2択の分類になります。
この例で、ランダムフォレストを用いてみましょう。
機械学習を行うためには、まずデータが必要です。今回は下記のような多くの患者さんのデータがあるとします。
(すでに1501人の患者が糖尿病になったのか、ならなかったのかのデータを集めたものです)

ランダムフォレストの手順
ランダムフォレストの手順は下記になります。
- それぞれ異なるデータを元に複数の決定木を作る。
- 今回の患者 Aさんのデータを元に、それぞれの決定木で、「1年以内に糖尿病なる」か「1年以内には糖尿病にならない」を予測してもらう
- それぞれ出てきた結果から、多数決で予測値を決める
上記の流れを解説します。
1. それぞれ異なるデータを元に複数の決定木を作る。
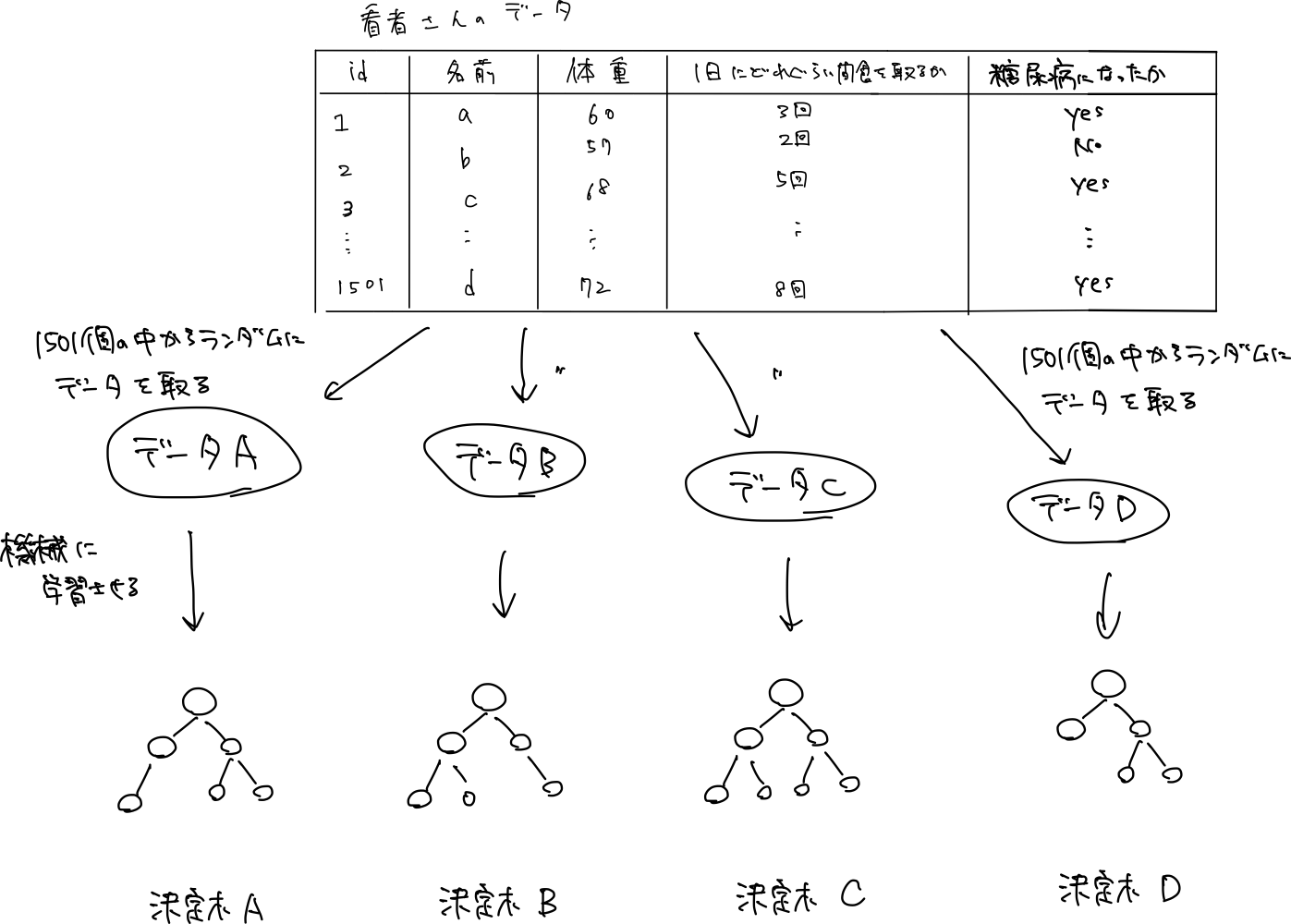
2. 今回の患者 Aさんのデータを元に、それぞれの決定木で、「1年以内に糖尿病なる」か「1年以内には糖尿病にならない」を予測してもらう

3. それぞれ出てきた結果から、多数決で予測値を決める
今回は、「糖尿病になる」が多数を占めているので、ランダムフォレストのAさんの予測結果は「糖尿病になる」になります。
まとめ
コードを書いていてもよくわからなくなることが多いので、ランダムフォレストの流れを可視化してみました。
もし誰かの理解の助けになれば幸いです。
もし気になる点などあれば、ご指摘いただけるとありがたいです。