Linux版SQLServerのPublic Previewが出たよ!
2016年11月16日に、待ちに待った(?)Linux版SQLServerのPublic Previewがリリースされました。
【gloops Advent Calendar 12/1】gloopsで検知しているDBアンチパターンまとめで、m_ono_desuyoが述べている通り、弊社ではRDBMSとして大部分でSQLServerを採用しています。
個人的にWindowsServerを触ってきた期間よりLinuxに触れてきた期間が長く、機会があったら迅速にLinux版SQLServerを使えるようにする為、検証しました。
インストール方法については、個人ブログのSQLSERVER ON LINUXを触ってみるを参照してください。
AlwaysONは使えない!?
現時点で、SSMSからAlwaysON High Availabilityを選択するとエラーになります。
yumを探すと、
mssql-server-ha.x86_64 : Microsoft(R) SQL Server(R) Relational Database Engine
と、それらしいパッケージがあるので、こちらをインストールします。
インストールすると、/usr/lib/ocf/resource.d/sql/fciという、pacemaker用のresource-agentが入りどうやらこれでクラスタを組めという事なのでしょう。
では、さっそく作っていきます。
構成は以下の通り。
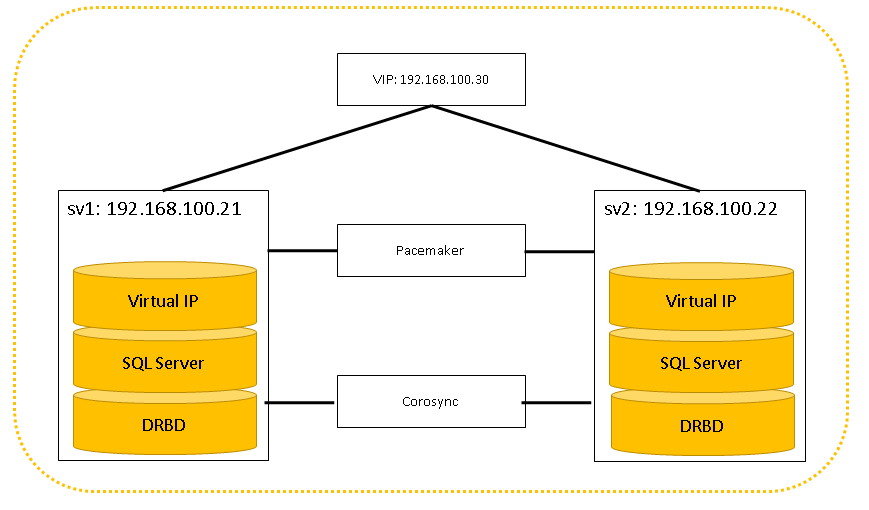
DRBDを組む
ELrepoにCentOS7用のパッケージが置いてあります。
mkdir -p /root/work
cd /root/work
# kernel-develをインストール
yum -y install kernel-devel
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
yum -y install kmod-drbd84-8.4.7-1_1.el7.elrepo.x86_64 --enablerepo=elrepo
※執筆時点の最新版DRBDは、kenel 3.10.0-514.el7 を求めてきます。
※普通にCentOS7を入れてアップデートすると、3.10.0-327.36.3.el7 になり、古いのでVersionを指定して入れています。
インストールが終わると、DRBDで利用するパーティション作成に進みます。
パーティションが同じブロック数であれば、DISKサイズは関係ありません。
検証環境では、8GBの仮想ディスクを使っています。
# fdisk /dev/sdb
コマンド (m でヘルプ): n
Select (default p): p
パーティション番号 (1-4, default 1): エンター入力
Partition 1 of type Linux and of size 8 GiB is set
コマンド (m でヘルプ): w
パーティションテーブルは変更されました!
次に、DRDBのリソースを作ります。
resource r0 {
protocol C;
device /dev/drbd0;
disk /dev/sdb1;
meta-disk internal;
on sv1 {
address 192.168.100.21:7801;
}
on sv2 {
address 192.168.100.22:7801;
}
}
drvdadmコマンドを実行し、DRBDのメタデータを作成します。
# drbdadm create-md r0
md_offset 8588881920
al_offset 8588849152
bm_offset 8588587008
Found some data
==> This might destroy existing data! <==
Do you want to proceed?
[need to type 'yes' to confirm] yes
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.
success
次に、2台のパーティションの整合性を取ります。
このコマンドは、パーティションサイズによって時間が掛かります。
systemctl start drbd.service
# sv1にて、
drbdadm -- --overwrite-data-of-peer primary all
# sv1にて、
cat /proc/drbd
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by phil@Build64R7, 2016-01-12 14:29:40
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:2833408 nr:0 dw:0 dr:2834320 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:5553884
[=====>..............] sync'ed: 33.9% (5420/8188)M
finish: 0:02:14 speed: 41,336 (30,140) K/sec
primary側でDRBDデバイス(/dev/drbd0)にext4のファイルシステムを作成します。
以後の作業は、primary側でのみ実施になります。
mkfs.ext4 /dev/drbd0
(中略)
done
mount -t ext4 /dev/drbd0 /data
DRBDパーティションのマウントはpacemakerで行うので、ここではfstabの記述は行いませんが、サーバー起動時にDRBDが立ち上がるようにしておきます。
systemctl enable drbd
corosyncを組む
細かい設定は割愛します。
totem {
version: 2
crypto_cipher: none
crypto_hash: none
interface {
member {
memberaddr: 192.168.100.21
}
member {
memberaddr: 192.168.100.22
}
ringnumber: 0
bindnetaddr: 192.168.100.0
mcastaddr: 239.255.1.1
mcastport: 5405
ttl: 1
}
}
pacemakerを組む
pacemakerの設定には、pscコマンドを使います。
IPアドレスでもクラスタノードの登録は出来ますが、/etc/hostsを設定することで、status確認等を行いやすくします。
vim /etc/hosts
192.168.100.21 sv1
192.168.100.22 sv2
# pacemakerを起動
systemctl start pacemaker
次に、クラスタノードを追加します。
haclusterユーザーが使われますので、任意のパスワードをつけて下さい。
password hacluster
[任意のパスワード]
# ノード追加
pcs cluster auth sv1 sv2 -u hacluster -p [パスワード]
sv2: Authorized
sv1: Authorized
# 初期セットアップ
pcs cluster setup --name sqlserver-cluster sv1 sv2 --force
# cluster起動
pcs cluster start --all
ここまで来ると、一部警告は出ますが2台でクラスタが組まれ、互いの死活監視がされている状態になります。
# pcs status
Cluster name: sqlserver-cluster
WARNING: no stonith devices and stonith-enabled is not false
Last updated: Sun Dec 11 16:37:47 2016 Last change: Sun Dec 11 16:37:46 2016 by hacluster via crmd on sv2
Stack: unknown
Current DC: NONE
2 nodes and 0 resources configured
Node sv1: UNCLEAN (offline)
Node sv2: UNCLEAN (offline)
Full list of resources:
PCSD Status:
sv1: Online
sv2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
リソースを登録する
SQLServerのHAに必要な構成は以下になります。
- Lisnerに該当するVirtual-IP
- Active/Standbyの確立
- スプリットブレインにならない。
- Master機のデータに書き込めない場合はエラーとみなしてF/Oさせる。
- Vitrual-IPアドレス、DRDBのPrimary、SQLServerは同じノードで稼働する。
- DRBDをマウントした後niSQLServerを起動させ、最後にVirtual-IPを付ける。
Virtual-IPは、Linux-HAではお馴染みのresource-agents内のIPADDR2モジュールを使います。
SQLServerの状態確認は、冒頭に上げた/usr/lib/ocf/resource.d/sql/fciモジュールを使ってみます。
リソースの登録前に、pacemakerのmonitorで使うSQLアカウントの設定を行います。
/var/opt/mssql/secrets/passwdにログインで使うアカウントを記載するようです。
# vim /var/opt/mssql/secrets/passwd
sa
saのパスワード
# 保存したら、パーミッションを600に設定
chmod 600 /var/opt/mssql/secrets/passwd
これはどうかと思いますが、今は仕方ありません。
そしてresourceの追加を行います。
# stonith機能の無効化
pcs property set stonith-enabled=false
# 仮想IPの定義
pcs resource create RES_VIP ocf:heartbeat:IPaddr2 ip=192.168.100.30 cidr_netmask=24 op monitor interval=3s
# SQLServerの定義
pcs resource create RES_SQLServer ocf:sql:fci op monitor interval=3s
# DRBDの定義
pcs resource create RES_DRBD ocf:linbit:drbd params drbd_resource="r0" op monitor interval="5s" role="Master"
# ファイルシステムの定義
pcs resource create RES_DRBD_FS ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/data" fstype="ext4"
# DRBDのMaster/Slave昇降格の定義
pcs resource master MS_DRBD RES_DRBD master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
# 同居設定
pcs resource group add RES_DRBD RES_SQLServer RES_VIP
pcs constraint colocation RES_COLOCATION-1 INFINITY: MS_DRBD:Master RES_SQLServer RES_VIP
# 起動順番の定義
pcs constraint order promote MS_DRBD then start RES_DRBD_FS
pcs constraint order start RES_DRBD_FS then start RES_SQLServer
pcs constraint order start RES_SQLServer then start RES_VIP
これで最終的には以下のようになります。
# pcs status
Last updated: Sun Dec 18 02:19:01 2016 Last change: Sun Dec 18 02:18:47 2016 by hacluster via crmd on sv1
Stack: corosync
Current DC: sv1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
2 nodes and 5 resources configured
Online: [ sv1 sv2 ]
Master/Slave Set: MS_DRBD [RES_DRBD]
Masters: [ sv1 ]
Resource Group: GR_SQLServer
RES_DRBD_FS (ocf::heartbeat:Filesystem): Started sv1
RES_SQLServer (ocf::sql:fci): Started sv1
RES_VIP (ocf::heartbeat:IPaddr2): Started sv1
Node Attributes:
* Node sv1:
+ master-RES_DRBD : 10000
* Node sv2:
Migration Summary:
* Node sv2:
* Node sv1:
SQLServerへの接続は、仮想IPである192.168.100.30にアクセスを行います。
データディレクトリの変更
デフォルトの/var/op/mssql/dataを、DRBDのパーティションである/data/mssql/dataに移動する必要がありますが、どこを探してもSQLServerのデフォルトフォルダを変更する箇所が見当たりません。
SSMSでファイルPATHを変える手もありますが、今回は/var/op/mssql/dataを/data/mssql/dataに移動し、シンボリックリンクを張りました。
※シンボリックリンクを張る処理は、sv1とsv2で行ってください。
mkdir /data/mssql/
mv /var/opt/mssql/data /data/mssql/data
mv /var/opt/mssql/log /data/mssql/log
ln -s /data/mssql/data /var/opt/mssql/data
ln -s /data/mssql/log /var/opt/mssql/log
FailOver時の切り替え時間
sv2がMasterとして稼働している状態で、バスっと停止しFailOverを発生させました。
その際に、sv1でcrm_mon -A1を1秒間隔で実行し、各リソースの切り替えがどのように行われるのか確認したところ、以下のようになりました。
| 時間 | 障害検知から経過した秒数 | 状態 |
|---|---|---|
| Sun Dec 18 03:36:41 | 0秒 | 障害検知 |
| Sun Dec 18 03:36:42 | 1秒 | VIPリソースの停止 |
| Sun Dec 18 03:36:43 | 2秒 | 全てのリソース停止 ノードはOnlineのまま DRBDがsv1に切り替わる |
| Sun Dec 18 03:36:44 | 3秒 | sv2がOFLINEに移行 sv1側で、/dev/drbd0を/dataにマウント |
| Sun Dec 18 03:36:45 ~03:36:54 |
4秒~13秒 | 変化なし |
| Sun Dec 18 03:36:54 | 14秒 | sv1側で全てのリソースが稼働 |
以前検証したAlwaysONのFailOverの時間が約16秒だったので、Linux版のSQLServerでも同等の時間でFailOverが行える事が確認出来ました。
製品版のLinux版SQLServerに求める事
弊社で行っている運用として、以下の点が未実装なので製品版では実装される事を望みます。
・ JOB Agent
sqlcmdが同梱されていますが、これを使ってジョブを書いてcronで回すのはSSMSユーザーは敷居が高い気がします。
・ 拡張イベント
無くてもいいですがデッドロックやSlowQueryなどの記録が、xelの形式だと加工し辛いので吐くならテキストで出力欲しいです。
製品版がリリースされたら、改めて検証したいと思います。