何をするか
- tweepyでツイートを伝染的に取得
- 二つの観点から集計
- matplotlibでグラフ化
ツイートの取得方法
- 取得対象者の人数を決定する
- 予め用意していた複数のユーザIDからランダムに1人選出(Aとする)
- Aからツイートを200件取得
- Aのフォロワーの中からランダムに1人選出(Bとする)
- Bからツイートを200件取得
…
という感じに取得していきます.
個人的に伝染するような動作をしているように見えたのでスパムくんと呼んでいます.
集計方法
- ツイートを取得する際に平仮名の個数をカウントし, CSVファイルに逐次追加
- CSVファイルから平仮名の個数をそれぞれ合計し, 全取得ツイート中の出現した回数を得る
- 同時に各ツイートに出ているか出ていないかを算出, 出現したツイートの数を求める
そのため, 総出現回数と出現したツイート数を今回はグラフ化していきたいと思います.
また, それぞれを全ツイート数で割った1ツイートあたりの平均出現個数とどの割合でその平仮名を含むツイートが出現するかも一覧として出しておきたいと思います.
結果の予測
やっぱり母音あたりが強いんじゃないかと思います.
「あ」~「お」が上位を占めるかも??
結果
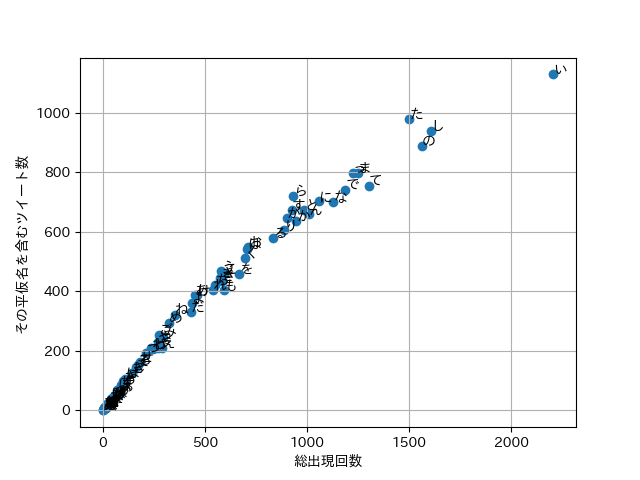
ちなみに一部をソートして抜粋すると
| 平仮名 | 総出現回数 | 個/ツイート | 平仮名 | 総出現回数 | 個/ツイート | |
|---|---|---|---|---|---|---|
| い | 2207 | 0.8719 | - | ゐ | 0 | 0 |
| し | 1606 | 0.6345 | - | ゑ | 0 | 0 |
| の | 1562 | 0.6171 | - | ゎ | 7 | 0.0027 |
| た | 1501 | 0.5930 | - | ぬ | 7 | 0.0027 |
| て | 1304 | 0.5152 | - | ぢ | 7 | 0.0027 |
| ま | 1251 | 0.4942 | - | ぺ | 8 | 0.0031 |
| っ | 1225 | 0.4839 | - | ぽ | 9 | 0.0035 |
| で | 1189 | 0.4697 | - | づ | 10 | 0.0039 |
| 平仮名 | 出現したツイート数 | 出現ツイート/全ツイート | 平仮名 | 出現したツイート数 | 出現ツイート/全ツイート | |
|---|---|---|---|---|---|---|
| い | 1128 | 0.4456 | - | ゐ | 0 | 0 |
| た | 978 | 0.3864 | - | ゑ | 0 | 0 |
| し | 938 | 0.3706 | - | ぬ | 4 | 0.0015 |
| の | 889 | 0.3512 | - | ぺ | 6 | 0.0023 |
| っ | 797 | 0.3148 | - | ゎ | 7 | 0.0027 |
| ま | 796 | 0.3145 | - | ぢ | 7 | 0.0027 |
| て | 754 | 0.2979 | - | ぴ | 7 | 0.0027 |
| で | 740 | 0.2923 | - | ぷ | 7 | 0.0027 |
コメント
「い」がぶっちぎりトップみたいですね.
この他にも色々わかったら追記していこうと思います.
ソースコード
テキトーですが一応置いておきます.
ツイートの伝染的取得.py
import tweepy
from twitter import *
import csv
import random
CONSUMER_KEY = '*****'
CONSUMER_SECRET_KEY = '*****'
ACCESS_TOKEN = '******'
ACCESS_TOKEN_SECRET = '*******'
def count_char(api, user_id, f, get_status_num):
# ひらがなのリスト
char_list = [chr(char_codepoint)
for char_codepoint in range(ord('ぁ'), ord('ん') + 1, 1)]
writer = csv.writer(f)
try:
# 自分のタイムラインの最新200件を取得
for status in tweepy.Cursor(api.user_timeline, user_id).items(get_status_num):
# 平仮名の個数の計算
char_num_list = []
for char in char_list:
char_num = status.text.count(char)
char_num_list.append(char_num)
writer.writerow(char_num_list)
except tweepy.error.TweepError:
print('認証がうまくできないアカウントにぶつかったので飛ばします.')
return False
return True
def choice_id_random(api, user_id, get_status_num):
id_list = tweepy.Cursor(api.followers_ids, user_id).items(30)
id_list = list(id_list)
id = random.choice(id_list)
user = api.get_user(id)
while(user.lang != 'ja' or user.statuses_count <= get_status_num or user.protected == True):
id = random.choice(id_list)
user = api.get_user(id)
return random.choice(id_list)
def count_char_infection(user_id, infection_num, f, get_status_num):
# 認証
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET_KEY)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth, wait_on_rate_limit=True)
while(infection_num > 0):
try_user_id = choice_id_random(api, user_id, get_status_num)
if(count_char(api, try_user_id, f, get_status_num)):
print('=== 対象 -> id:{}'.format(try_user_id))
infection_num -= 1
print('=== 残り{}人'.format(infection_num))
user_id = try_user_id
if __name__ == '__main__':
# 感染元アカウントのリスト. ここからランダムに選ばれる.
id_list = ['*****', '*****', '*****']
f = open("file_name", "a", encoding="utf-8")
print('=== 感染する人数を入力してください.')
infection_num = int(input('> '))
count_char_infection(random.choice(id_list),
infection_num, f, get_status_num=200)
集計結果の表示とグラフ化.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plot
import matplotlib as mpl
if __name__ == "__main__":
char_list = [chr(char_num)
for char_num in range(ord('ぁ'), ord('ん') + 1, 1)]
org_df = pd.read_csv('file_name',
engine='python', names=char_list)
print(org_df)
# 各ひらがなの出現回数
sum_org_df = np.sum(org_df, axis=0)
sorted_sum_org_df = sum_org_df.sort_values(ascending=False)
print(sorted_sum_org_df)
print(sorted_sum_org_df / len(org_df))
# 各ひらがなの使用されていたツイート数
appear = np.array(org_df)
appear[appear > 0] = 1
appear_df = pd.DataFrame(appear, columns=char_list)
sum_appear_df = np.sum(appear_df, axis=0)
sorted_sum_appear_df = sum_appear_df.sort_values(ascending=False)
print(sorted_sum_appear_df)
print(sorted_sum_appear_df / len(org_df))
# 描画
font = {"family": "IPAexGothic"}
mpl.rc('font', **font)
fig = plot.figure()
ax = fig.add_subplot(111)
ax.scatter(sum_org_df, sum_appear_df)
for x, y, char in zip(sum_org_df, sum_appear_df, char_list):
ax.annotate(char, (x, y))
ax.set_xlabel('総出現回数')
ax.set_ylabel('その平仮名を含むツイート数')
ax.grid()
plot.show()