はじめに
ノートの投稿記事からリンクされているAmazonの商品を集計してランキングサイトを作りました。技術書のランキングはQiitaを元にしたテック・ブック・ランクがありますが、私はビジネス書や実用書を読みたいため、ノートにだったらそういう情報ありそうだなと思ったので。
Note Station | 人気のビジネス書や実用書、技術書をランキング形式で毎日更新
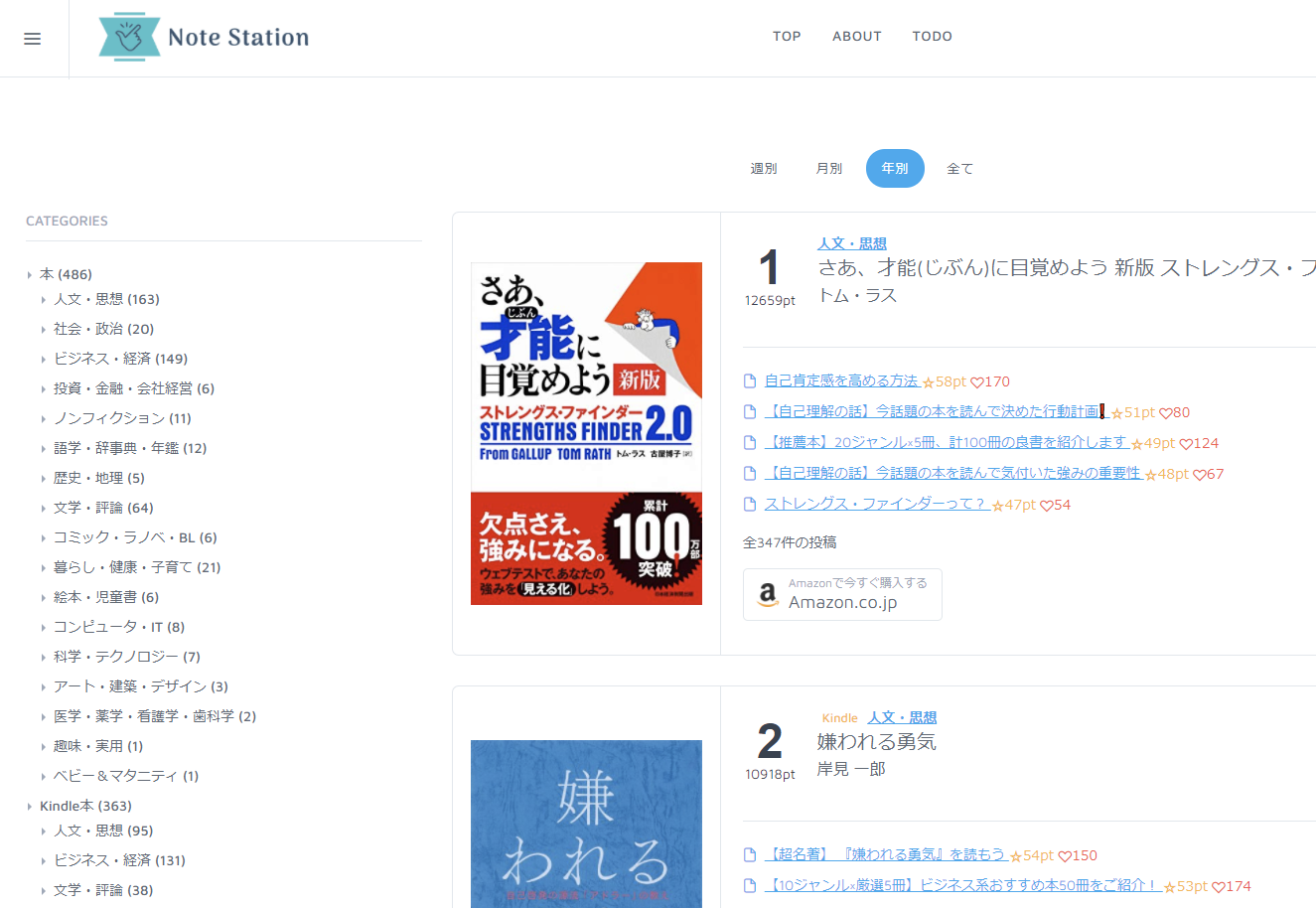
元々個人用に作って、書籍購入の参考にしたり、ランキング処理の勉強として作ったのですが、思ったよりも便利なのではと思い公開する事にしました。
書籍のカテゴリはたくさんあるので、2階層目までのカテゴリ情報でフィルタできるようになっています。Amazonのカテゴリを最後まで表示すると凄い細かいので解像度を荒くしています。
また、書籍以外の情報も出てくるので、それはフィルタリングしないでそのまま表示するようにしています。
できていないこと
TODOとしてまとめてはいるのですが、主にランキング周りを改善したいと思っています。
特に、Kindleと物理本が別々に扱われているのをなんとかしようと思っています。名寄せのための情報は既に持っているのですが、スコアの計算をMySQLで行っていいるため、名寄せ処理を入れると、凄くクエリが重くなってしまい悩んでいます。
また、月や年のランキングの上位が似ているため、発見の幅が狭まっているのをなんとかしたいです。
あとは、1つの記事には他の書籍も紹介されているので、ランキング表示のところに関連書籍を合わせて表示したいと思っています。Amazonでも関連商品は1つ1つのページを辿るしかないので、リスト表示のところに関連商品も小さく表示したら、書店で本棚を見るかのような体験が出来そうかなと。
ランキングについて
専門家ではないため難しい理論や処理は実装できないのですが、以下のことに気を配りました。
- 基本は言及している記事の数、記事のイイネの数と記事の投稿日を元に計算する
- 投稿してから時間が経過したものは減衰するようにする
- 減衰は集計期間によって変更する
- 同一ユーザーが毎投稿に自分の(?)書籍のリンクを貼っているものがあるので、そういうものはスコアを抑えるようにする
- 例: 10個の記事がある場合、1人が書いているよりも10人が書いている方がスコアが高い
- ユーザー自体のスコア(ユーザーのフォロワー数など)は利用しない。重みも考慮しない。
- SNS上の情報(TwitterやHatenaBookmarkなど)もある程度考慮する
こんな感じの本が見れます。

利用した技術一覧
使っている技術は特に目新しいものはありません。SPAで作ろうと思ったのですが、ページが1枚しかないので、クラシックな作りました。勉強も兼ねているので、SPA化は近いうちにやろうと思っています。
お金をなるべく使いたくなかったのでAWSやGCPではなく、ConohaのVPSを使っています。
- Crawler
- Ruby 2.7
- MySQL 8
- RabbitMQ
- Web site
- Bootstrap 4
- SQLite
- Nginx + Puma + Sinatra
- Cloudflare
- Datadog
ただ、クロールや集計をするサーバとランキング情報を配信するサーバは分けています。ランキング情報の生成はWriteが1日に1回かつ、WebサイトはWrite処理がありません。なので生成したランキング情報をMySQL上に生成した後に、SQLiteファイルとしてDumpして、Webサイト用のVPSに転送しています。(集計前のデータはMySQL上で大量のレコードと大きなデータサイズなので、これを参照させたくない)
ランキング情報をSQLiteにDumpするのはレコード数が少ないからこそやっているのですが、これによってメモリ使用量もDisk使用量も小さくなり、小さいVPSで運用できています。いまのところ、それなりにサクサク(応答時間が50ミリ秒未満)と動いていると思っています。
一度使ってみて欲しいです。