1.はじめに
前回は、IBM Granite Time Series ModelをZero-Shot(モデルをチューニングせず事前学習されたモデルをそのまま利用)モデルで予測してみました。
今回は、モデルをFine-Tuningして予測をしてみようと思います。
参考にしたものは、以下のURLにあるNotebookのサンプルです。
今回は、まずは精度が出る設定を確認するパートとなります。
どのくらいパラメータ設定にすれば精度が高くなるか確認します。
さて、今回使用したストリームは下記Git Hubにアップロードしています。
ご自由にダウンロードしてください。
データはこちらからダウンロードしてください。
①. 前回と同じスペインのエネルギーデータ
energy_dataset.csv
②. コントロール変数として追加で、スペインの気象データを使用します。
weather_features.csv
※. 注意点
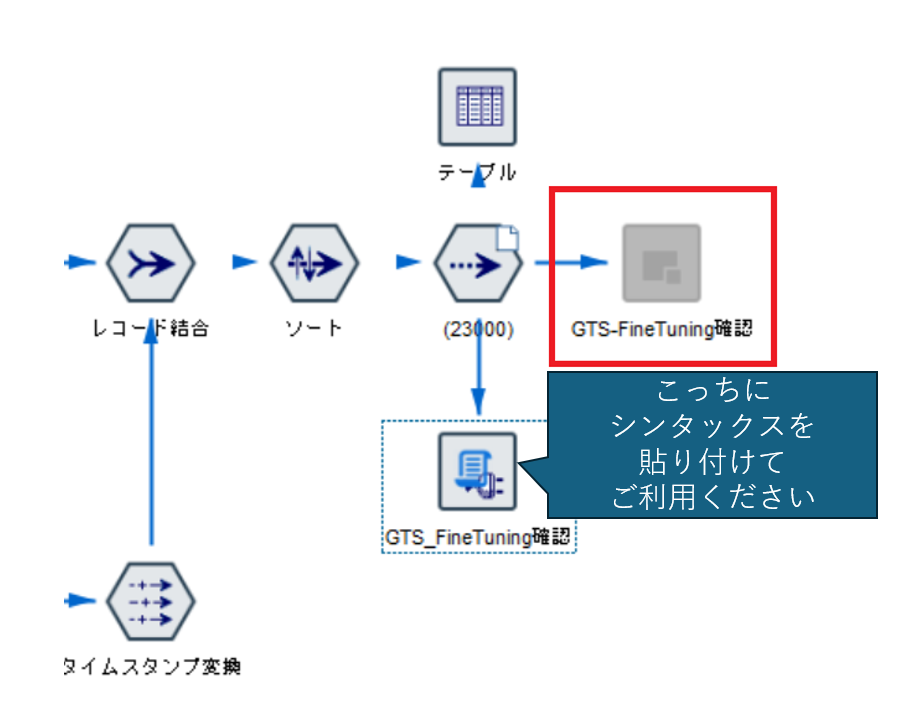
上記のストリームを開くとなぜかPythonシンタックスを記述した拡張の出力ノードが使用不可になります。
赤枠のように灰色に。。なぜかはわかっていません。
そのため、一緒に保存してある「Granite_FineTurning_ModelTrain.py」の中身を、ストリーム内に準備してある拡張の出力ノードにコピー・貼り付けしてご使用ください。
また、シンタックスにある下記のフォルダ設定の部分については、適宜みなさんの環境に合わせてパスを変更してください。
# Finetuning時のログ、モデルなどの保存フォルダ
OUT_DIR = "C:\\Qiita\\202505\\ttm_results"
2.準備
必要な準備は以下の記事で記載しております。必要なライブラリを導入してください。
3. 使用データ
以下のURLより2つのCSVデータをダウンロードしてください。
①. 前回と同じスペインのエネルギーデータ
energy_dataset.csv
②. コントロール変数として追加で、スペインの気象データを使用します。
weather_features.csv
4. Few-shot Fine-Tuningについて
まず、私の動作環境は以下の通りです。
| 項目 | 内容 |
|---|---|
| OS | Windows 11 Pro |
| CPU | 11th Gen Intel(R) Core(TM) i5-1130G7 |
| GPU | Intel(R) Iris(R) Xe Graphics |
| Memory | 16GB |
| Disk | SSD 512GB |
| Modeler | 18.6 |
| Python | 3.10.7(Modeler同梱) |
かなり非力な環境のため、Fine-Tuningをする時、パラメータに気を付けないと、
処理がいつ終わるかわからないという事態が発生します。
ということで、今回は、Few-shot Fine-tuning で実装しようと思います。
特徴は以下の通りです。
| 項目 | 内容 |
|---|---|
| 目的 | 大量のデータを使わずに、モデルを素早く特定のタスクに適応させる。 |
| データ量 | 「ほんの少し」=全体の数%だけ(例:5%、10%)だけを使う。 |
| 効果 | 時間・計算コストを抑えつつ、性能を大きく向上できる場合がある。 |
| 適用範囲 | ラベル付きデータが少ないタスク、素早く試したい場面、モデルの初期テストなど。 |
| モデルの特徴 | すでに「かなり一般知識を持った大きな事前学習モデル」が前提(ゼロからの学習ではない)。 |
| 学習方法 | - 少量データを特別な順番で渡す(例えばデータの「最初から」「ランダムに」など) |
| - 学習率を少し下げたり、エポックを短くしたりすることが多い。 | |
| リスク | データが少なすぎると「過学習(overfitting)」しやすい。汎用性が下がる可能性もある。 |
・通常のFine-tuning
→ たっぷりデータを与えて、モデルの重みをしっかり更新する。
・Few-shot Fine-tuning
→ ごくわずかのデータだけで微調整(重みの小さなアップデートだけ行う)。
→ 元の知識(事前学習時の知識)を壊さないように、ちょっとだけ方向を変える感じ。
といったところでしょうか。
まぁ、普通のFine-Tuningをやってみましたが、いつまでたっても処理が終わりませんでした。
とほほ。
5. Modelerでの実装(精度確認)
さて、実際に実装していきます。
ストリーム全体は以下の通りです。
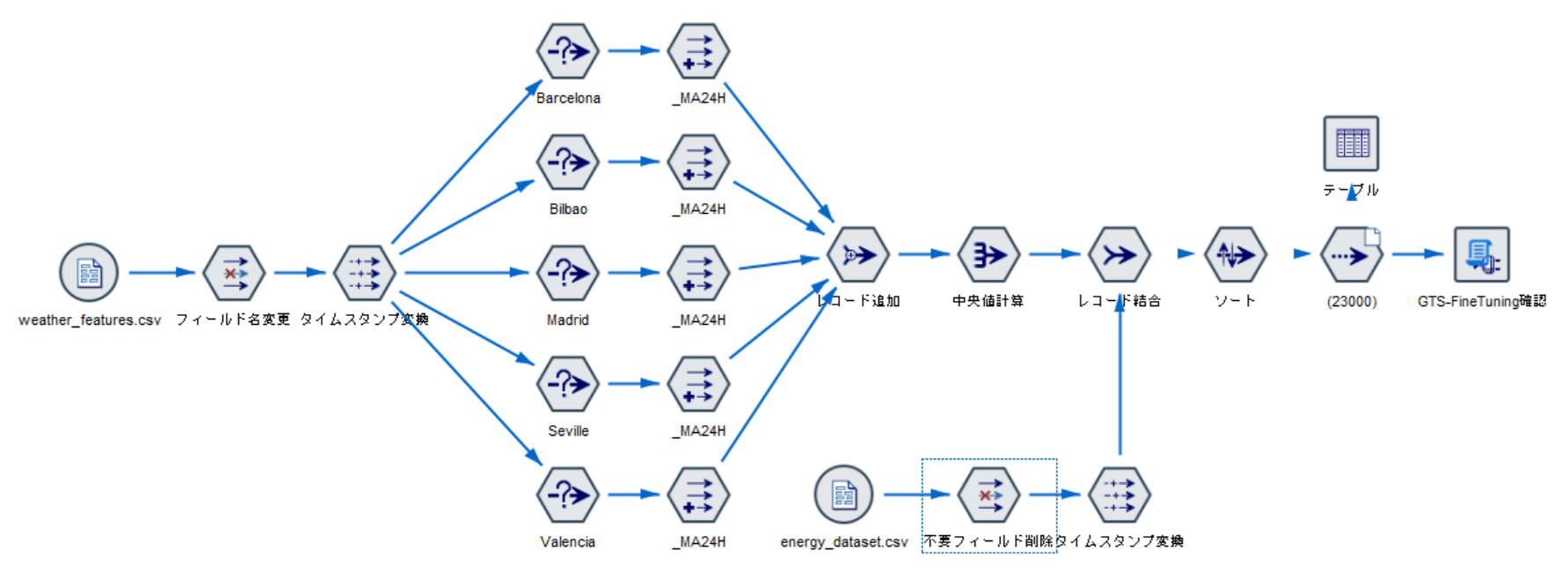
一番右の拡張の出力ノードでFine-tuningを実装しています。
その手前までは
①. 気象データからコントロール変数の作成
②. エネルギーデータと気象データの結合
③. データの絞り込み(データの削減)
といった処理をしています。
参考にしたサンプルではPythonでやっていますが、ここではModelerでデータ加工をやってみます。
①. 気象データからコントロール変数の作成
まずは、Fine-Tuningで使用するコントロール変数を作成します。
今回は、気象データを使っています。
この気象データには、1時間ごとの気温や、湿度、風速、雨量などの各種データが代表的な都市別に記録されています。
その気象データについて、以下のような処理をして変数を作成します。
①. 各都市毎にデータを分ける。
②. 各気象データの24時間移動平均値を作成する。
③. 再度結合して各都市毎の24時間移動平均値から、同一時刻の中央値を作成する。
エネルギーデータ(total load actual)は、スペイン全体で1時間ごとに1つしかないが、
気象データは1時間ごとに5都市分あるため、各都市の移動平均値を求め、さらにその中での中央値をスペインの気象データとするのです。
こんなイメージ。XXより右側にも、同じように他の気象データも中央値を計算して格納します。
| 時間 | total load actual | 気温_中央値(5都市の移動平均から算出) | XX |
|---|---|---|---|
| 2018/1/1 11:00 | 25000 | 25.6 | -- |
| 2018/1/1 12:00 | 27000 | 23.6 | -- |
さて、見てみましょう。
a. データ入力からタイムスタンプ変換まで
可変長ファイルノードで、 weather_features.csv を読み込みます。特に設定は変更しません。
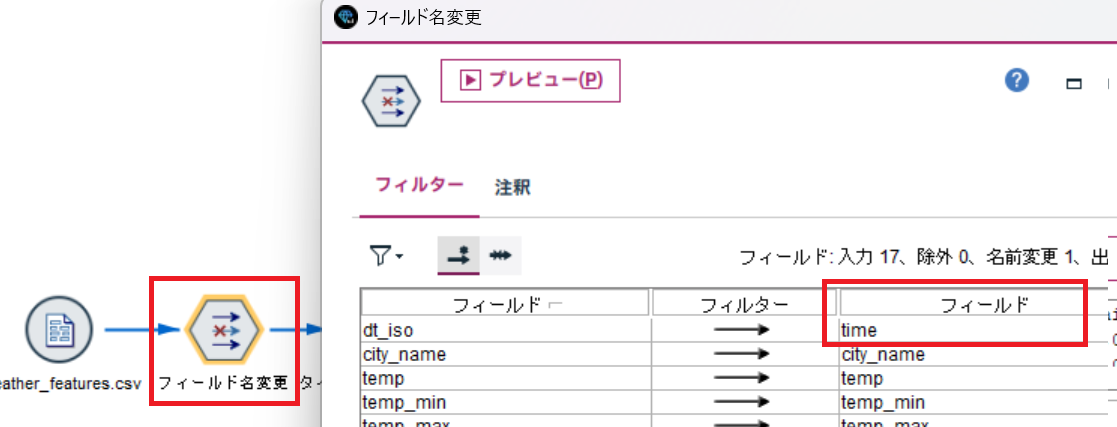
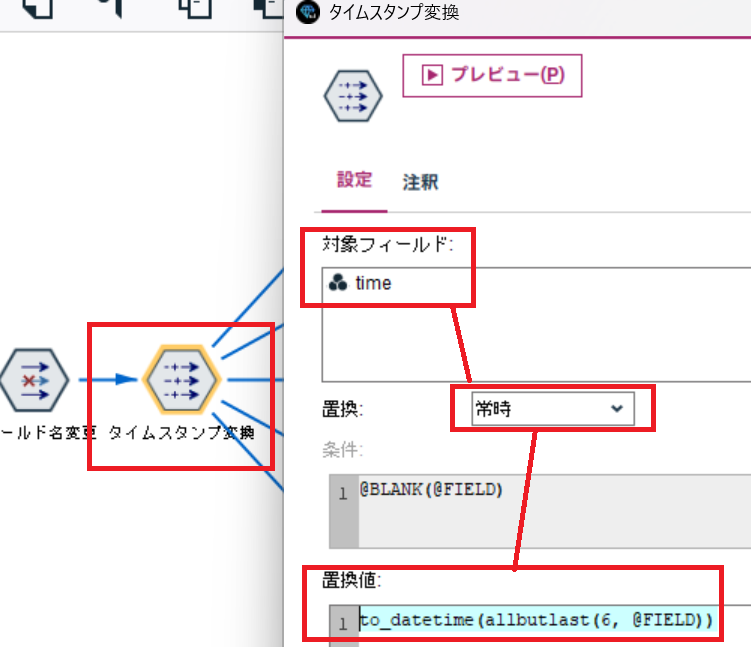
続いて、フィルターノードで時刻データのフィールド名を変更します。ここでは、後から結合するスペインのエネルギーデータである energy_dataset.csv のフィールド名の time に合わせています。
最後に、時刻データをタイムスタンプ型に変換しています。
ここは、前回と同様に +01:00 などの時差表記を削除してから変換しています。
to_datetime(allbutlast(6, @FIELD))
b. 各都市毎の気象データの移動平均を計算する。
次に気象データの24時間移動平均を計算していきます。
5都市分実装していますが、都市を抽出する部分以外は全て同じ処理です。
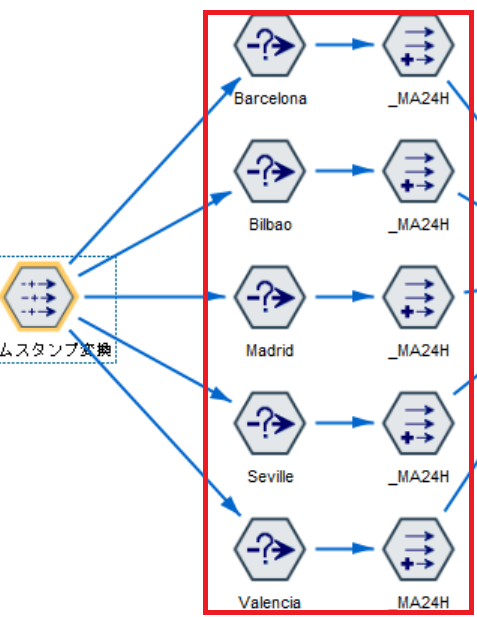
さて、見ていきましょう。
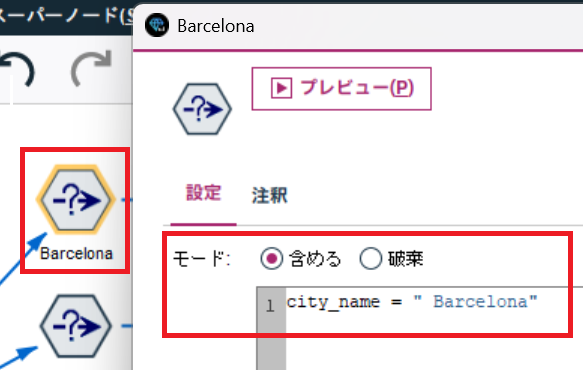
まずは、条件抽出ノードで都市を絞り込みます。(例は" Barcelona"!! 行ってみたい。。。)
気を付けてほしいのは、" Barcelona"と半角スペースが前方に含まれています。
データの中身をよく確認しましょう。"Madrid"は半角スペースがないなど違いがあります。
続いて、24時間移動平均を計算します。
フィールド作成ノードを使って、複数の気象データの移動平均値を一気に計算します。
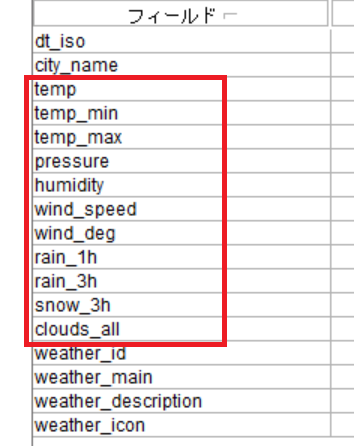
①. モードを 複数 とする。
②. 対象フィールドを複数選択します。今回は、以下の12個の気象データフィールドです。。
③. 24時間移動平均を計算するClem式を記述します。@MEAN関数を使用すれば簡単。
@MEAN(@FIELD,24)
昔の記事になりますが、シーケンス関数についてはこちらで紹介しています。
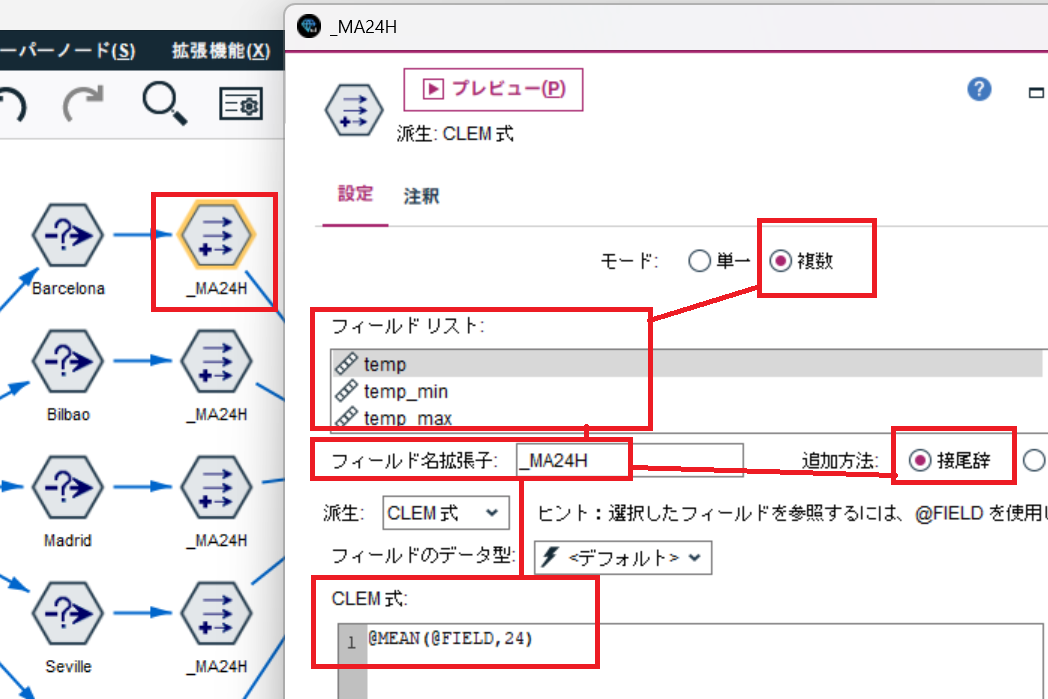
結果は以下の通り、複数フィールドを一気に作成できます。
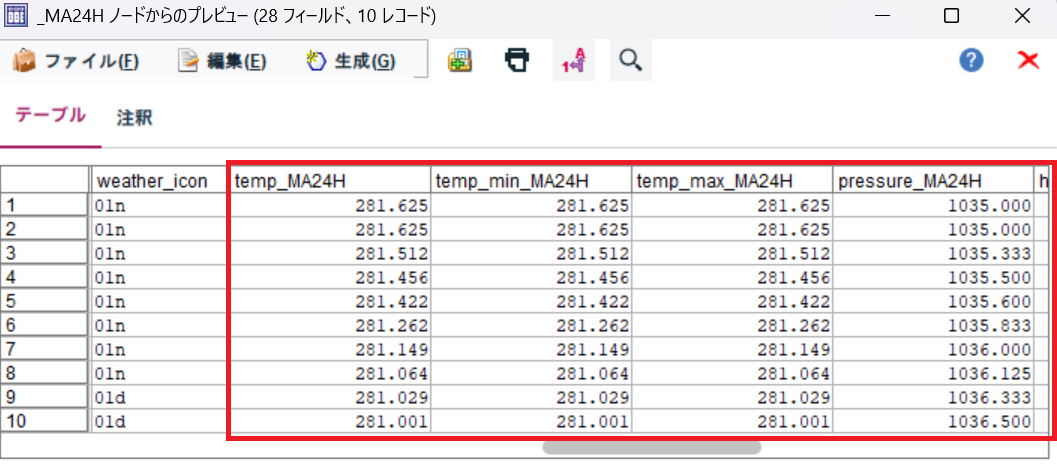
最後は、都市毎に計算した結果をレコード追加ノードで統合します。特に設定は変更せずに統合できます。
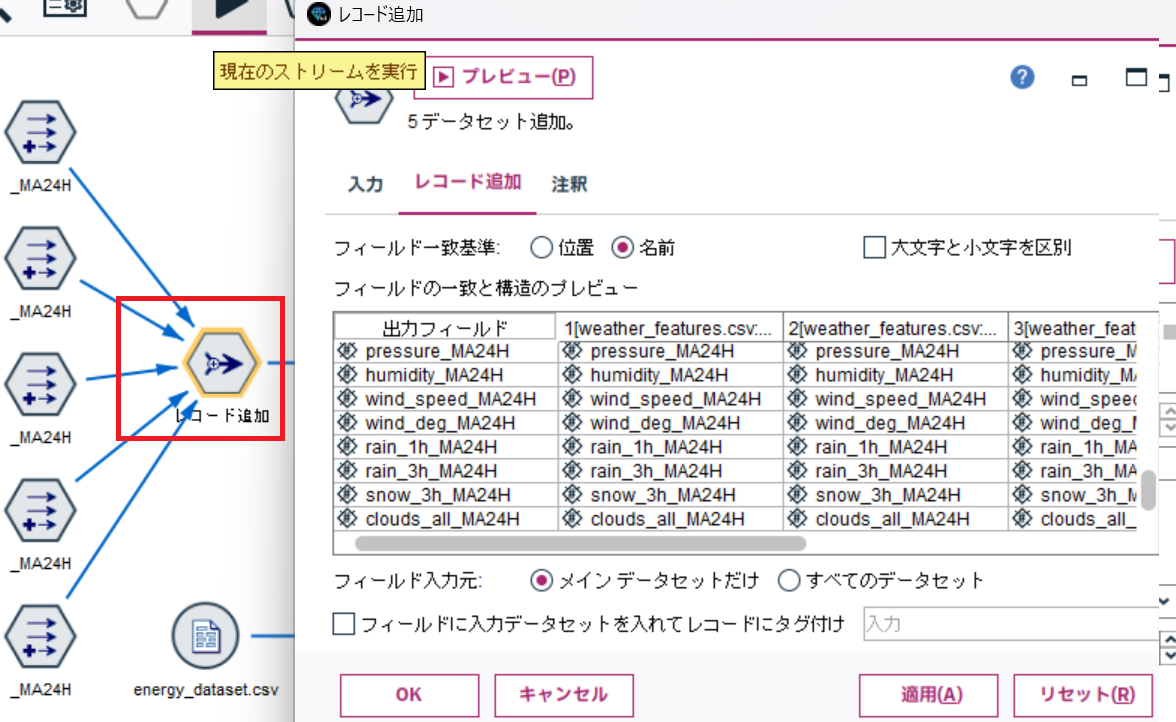
c. 集計して中央値を計算する
統合されたデータからレコード集計ノードを使って各気象データの中央値を計算します。
各時刻の中央値を求めますのでキーは time になります。
あとは、先ほど作成した気象データの24時間移動平均を対象に中央値を計算するだけです。
RecordCountは必要ないので、チェックは外しましょう。
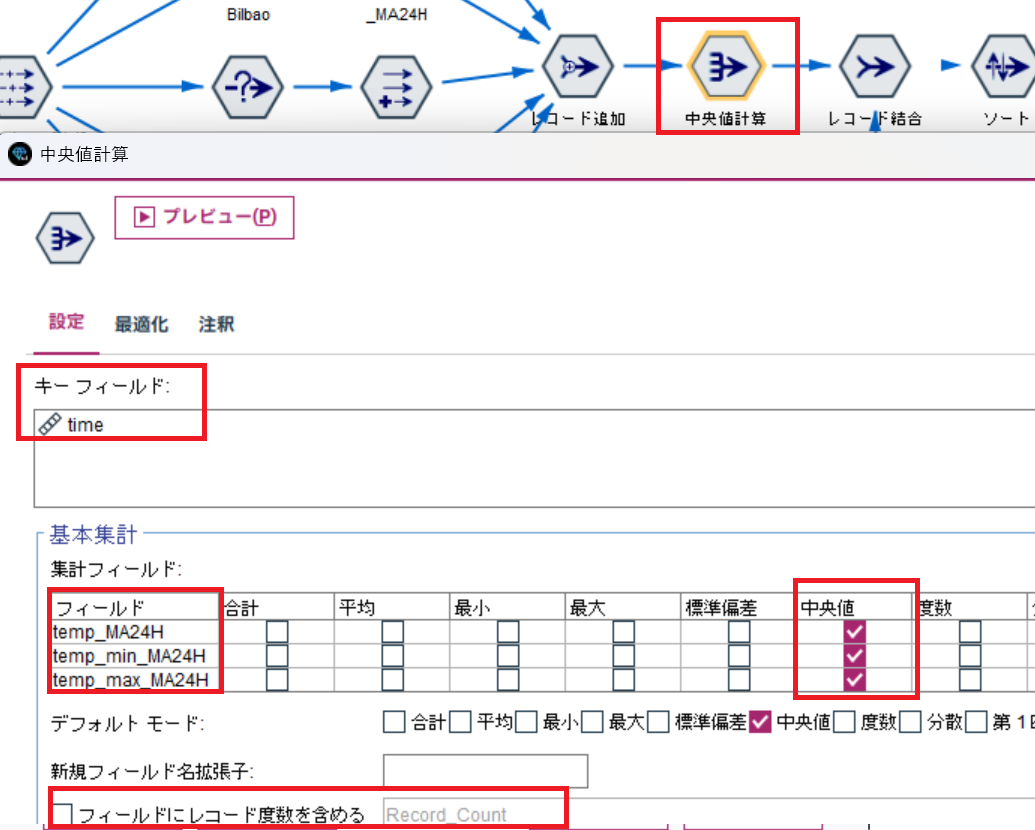
結果は以下の通り、時刻毎の中央値が計算されています。
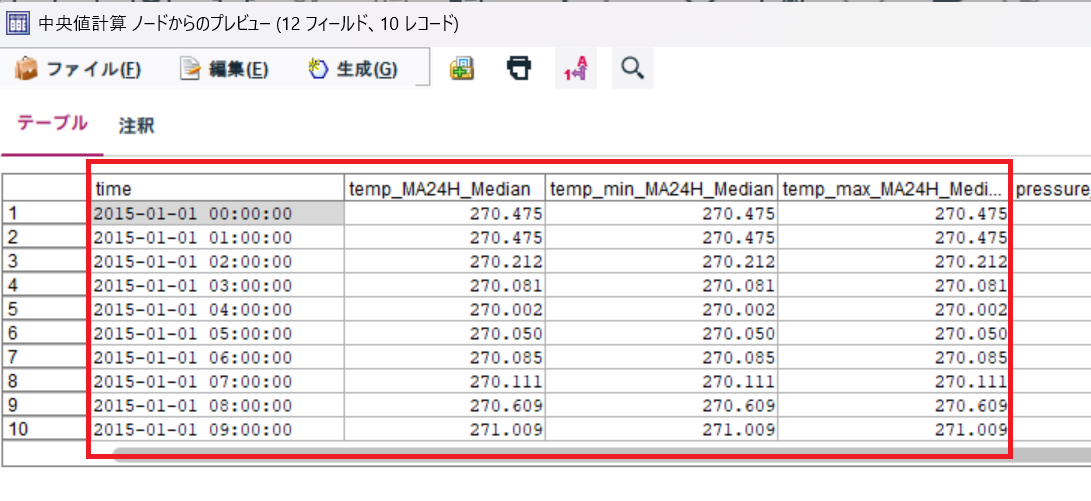
②. エネルギーデータとコントロール変数の結合及びデータの絞り込み
次は、コントロール変数とエネルギーデータを結合します。
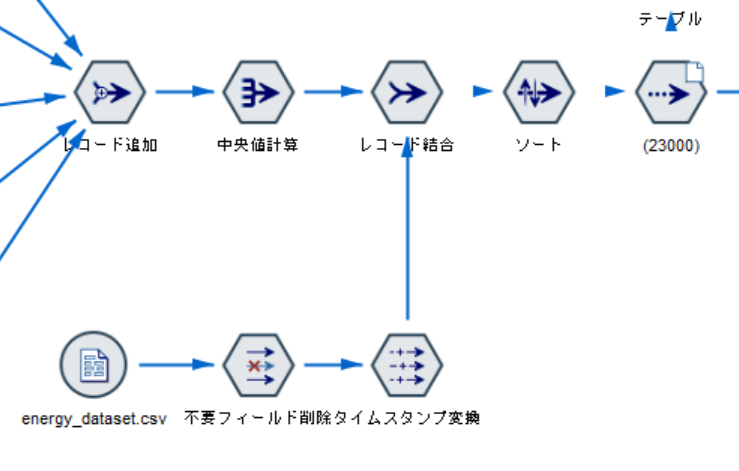
a. エネルギーデータの入力とタイムスタンプ変換
可変長ファイルノードで、energy_dataset.csv を読み込みます。特に設定はしません。
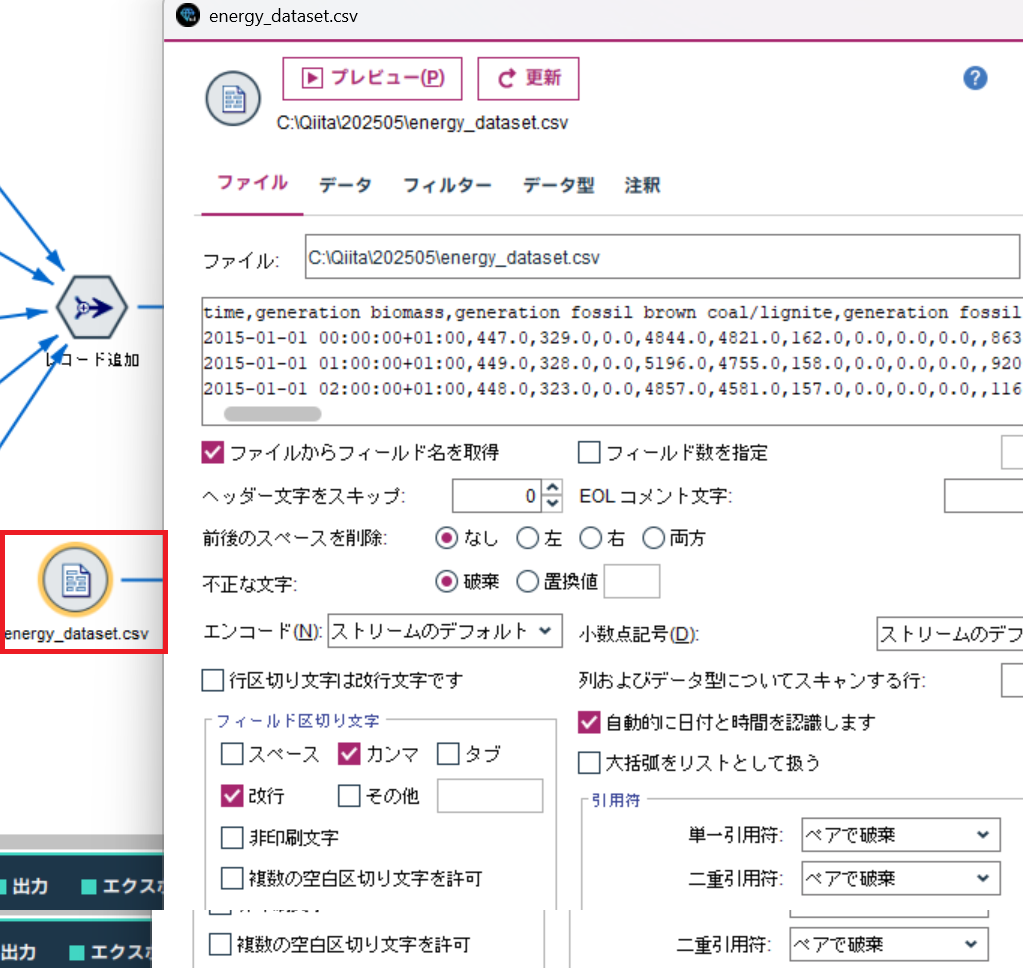
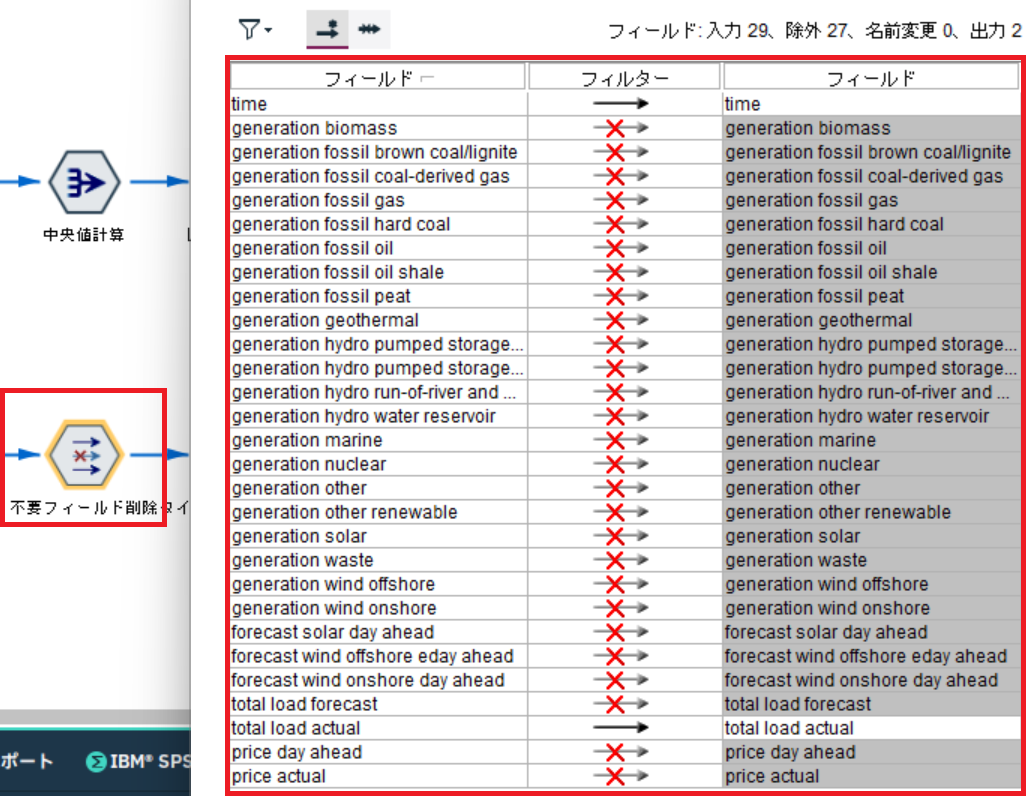
続いて、time と total load actual 以外はフィルターノードで除外します。
weather_features.csvと同じように置換ノードで time フィールドを タイムスタンプ型 に変換します。
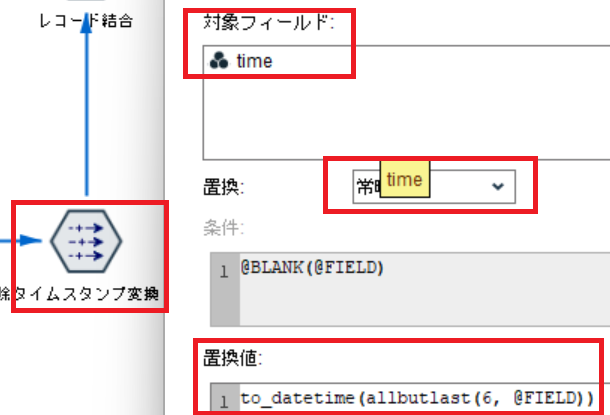
b. エネルギーデータとコントロール変数を結合
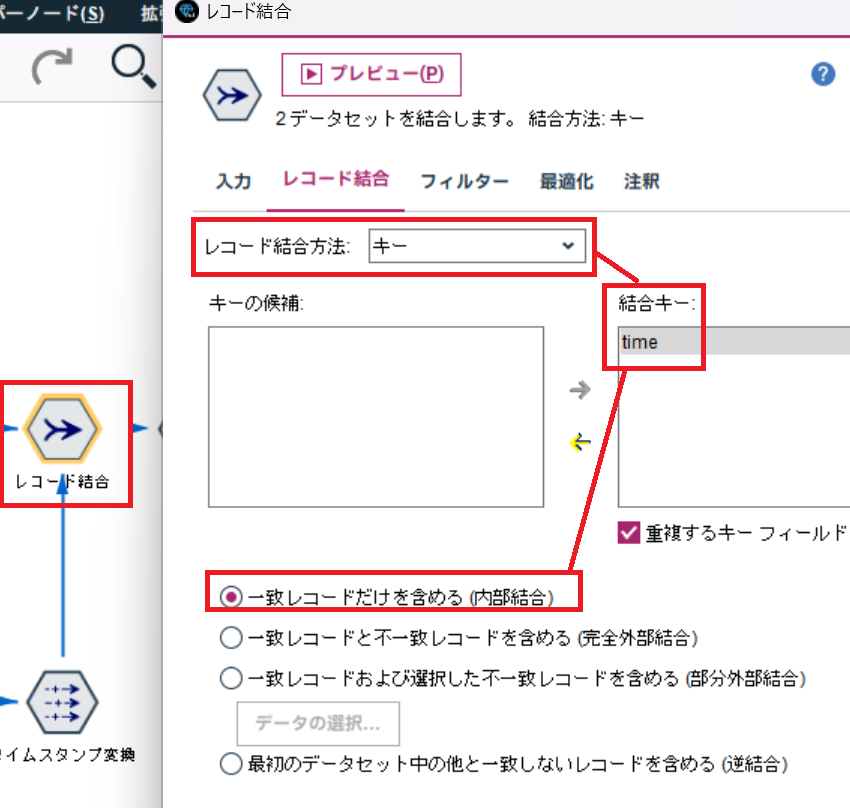
レコード結合ノードで、データを結合します。
結合キーは time となります。
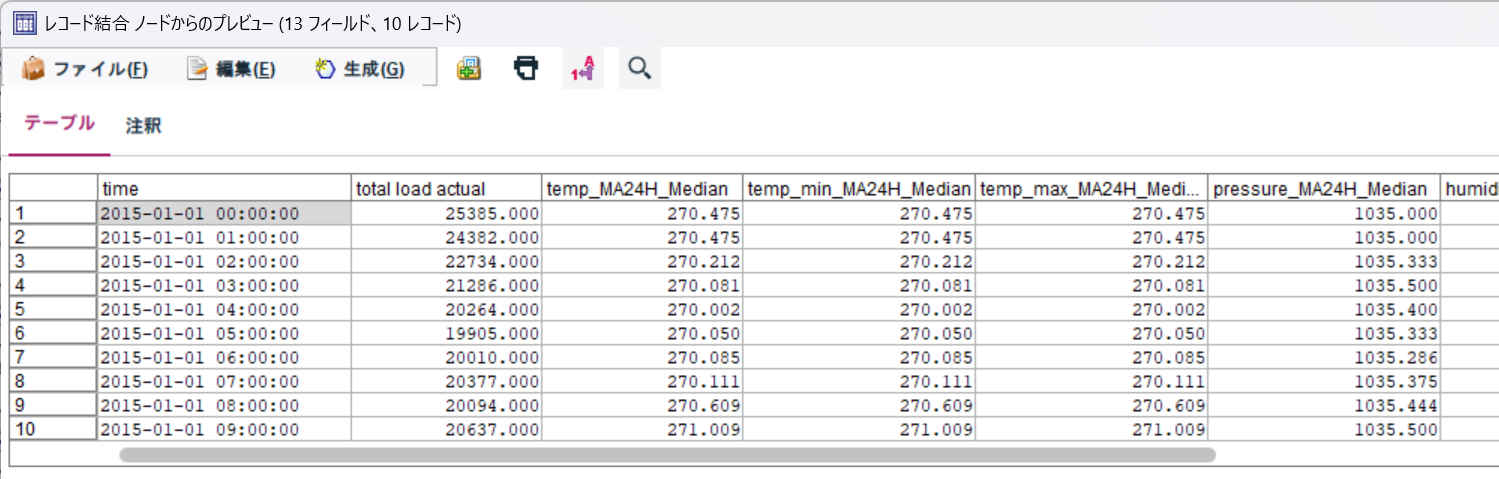
結合結果は以下の通りです。
時刻毎の total load actualと各種気象データの中央値が結合されています。
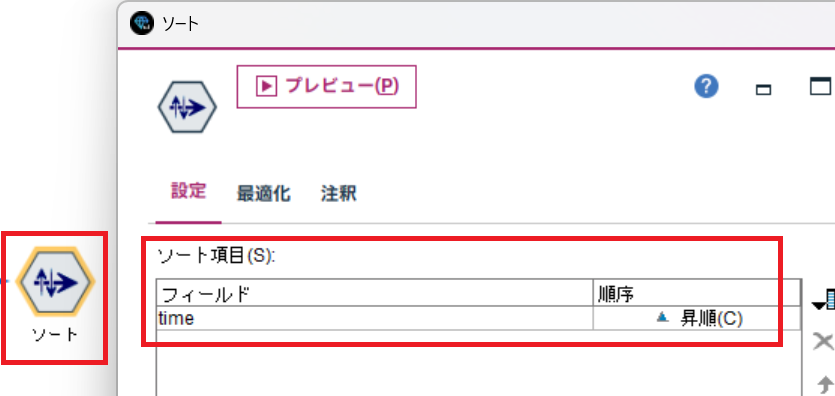
c. ソート及びデータの絞り込み
データをtime の昇順でソートします。(念のためです。)
続いて、私のPCが非力なのでデータを絞り込みます。
今回は、23,000件を除外しました。→ 今回も35000件ほどデータがあるので約12,000件のデータを使ってFine-Tuningするということです。
また、ノードにキャッシュを設定しています。この後に何度もトライ&エラーを繰り返すので。
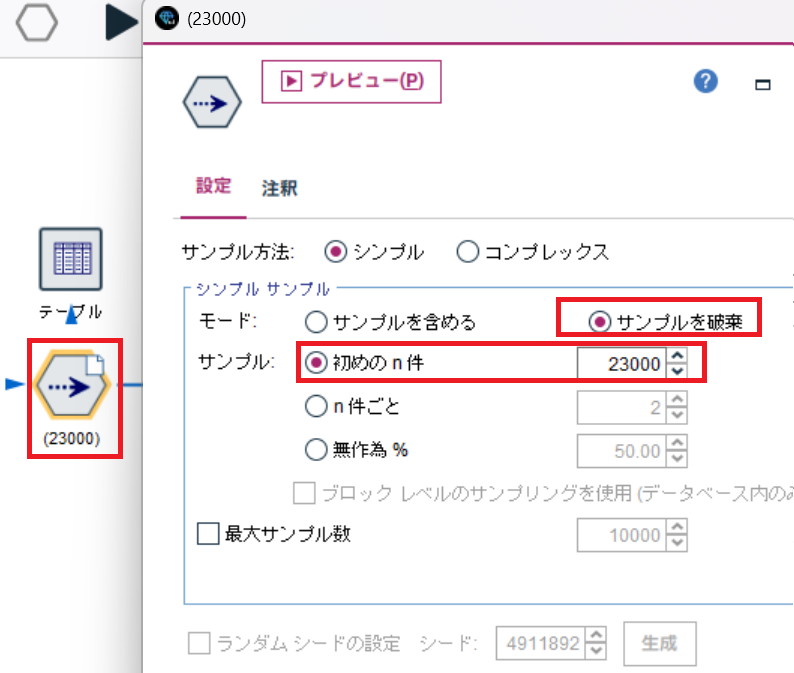
レコード件数については、精度を上げるためにレコード件数を増やしたり、実行時間を削減するために減らしたりと試行錯誤を繰り返しました。
みなさんも最適なものを探してみてください。
もちろん環境が整っているであれば、全件使用する方がいいと思います。(うらやましい。)
③. IBM Granite TimeSeries Fine-Tuning
はい、やっと 拡張の出力ノード + Pythonの出番です。
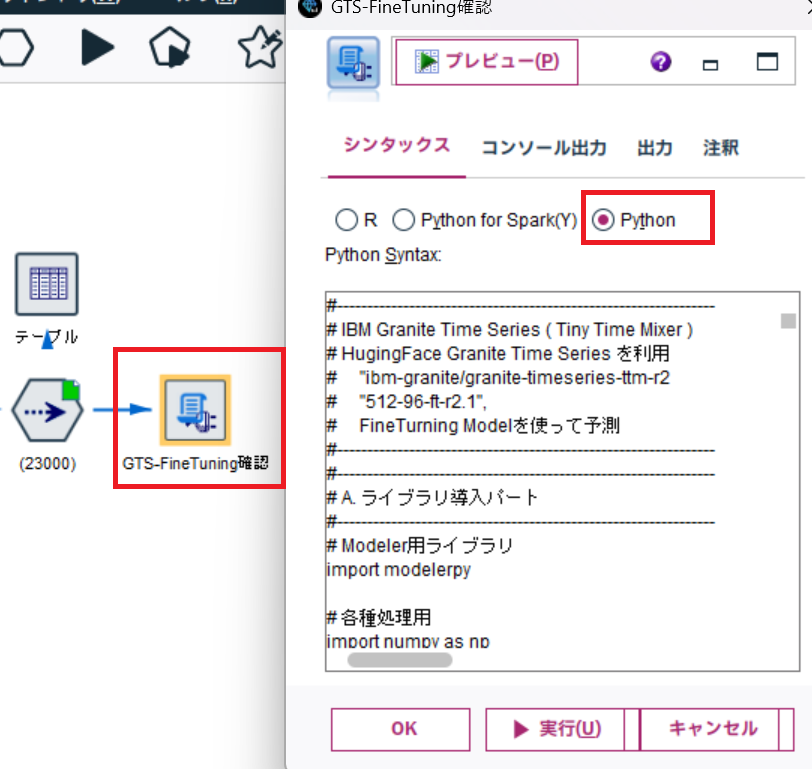
以下がシンタックスの全体になります。
今回は、精度の確認を実施しているので、予測値などは取得していません。
#---------------------------------------------------------------
# IBM Granite Time Series ( Tiny Time Mixer )
# HugingFace Granite Time Series を利用
# "ibm-granite/granite-timeseries-ttm-r2
# "512-96-ft-r2.1",
# FineTurning Modelを使って予測
#---------------------------------------------------------------
#---------------------------------------------------------------
# A. ライブラリ導入パート
#---------------------------------------------------------------
# Modeler用ライブラリ
import modelerpy
# 各種処理用
import numpy as np
import pandas as pd
# Finetuningモデル保存用
import math
import os
# モデル作成用 - Finetuning
# pytorch
import torch
# 最適化手法の一つで、Adam に weight decay(重みの減衰) を加えたもの
# 補足: 通常のAdamだとL2正則化がうまく効かないことがある → それを修正したのがAdamW
from torch.optim import AdamW
# スケジューラ
# 学習率(Learning Rate)を 1サイクルの形で調整するスケジューラ
from torch.optim.lr_scheduler import OneCycleLR # 最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整
# 早期終了(Early Stopping) 用のコールバック
# トレーニング統合クラス
# Trainer に渡す設定(学習率、バッチサイズ、出力先など)を保持するクラス
from transformers import EarlyStoppingCallback, Trainer, TrainingArguments, set_seed
# IBM Granite TTM
from tsfm_public import (
TimeSeriesForecastingPipeline, # 時系列予測のパイプライン
TimeSeriesPreprocessor, # 入力データの整形・スケーリング
TinyTimeMixerForPrediction, # 時系列予測モデル
TrackingCallback, # 学習中にログを取ったり、追加で何かを記録するための カスタムCallback
count_parameters, # モデルの総パラメータ数を数えて出力してくれる関数
get_datasets, # 前処理済みのDataFrameを、モデルが扱える Dataset形式(学習/検証/テスト) に変換する関数
)
# 入力データをtrain/valid/test に自動で分割してくれる関数
from tsfm_public.toolkit.time_series_preprocessor import prepare_data_splits
#---------------------------------------------------------------
# B. カラム定義
#---------------------------------------------------------------
# タイムスタンプカラム
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
#---------------------------------------------------------------
# C. データ入力パート
#---------------------------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
# 時系列カラム"time"をタイムスタンプ型に変更
input_df[ timestamp_column ] = pd.to_datetime(input_df[ timestamp_column ])
#---------------------------------------------------------------
# D. モデル用データ準備パート
#---------------------------------------------------------------
#-----------------------------------------------
# カラムロール設定
#-----------------------------------------------
# 予測対象カラム定義
target_columns = [ target_column ] #リストにする
# カラムロール設定
# 説明変数には、各日時の気象データの中央値を指定
column_specifiers = {
"timestamp_column": timestamp_column, # タイムスタンプカラム
"id_columns": [], # 複数系列を識別するためのID(今回は1系列なので空)
"target_columns": target_columns, # 予測対象カラム
"control_columns": [ # コントロール変数(気象データなど)
"temp_MA24H_Median",
"temp_min_MA24H_Median",
"temp_max_MA24H_Median",
"pressure_MA24H_Median",
"wind_speed_MA24H_Median",
"wind_deg_MA24H_Median",
"humidity_MA24H_Median",
"rain_1h_MA24H_Median",
"rain_3h_MA24H_Median",
"clouds_all_MA24H_Median",
],
}
#-----------------------------------------------
# 使用モデル用パラメータ設定
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# モデルが「未来何ステップ先まで予測」するか(ここでは96時間先=4日分)
prediction_length = 96 # the max forecast length for the 512-96 model
# 使用モデルバージョン
TTM_MODEL_REVISION = "512-96-ft-r2.1"
#-----------------------------------------------
# 使用データ設定
#-----------------------------------------------
# データセットのうち、10%だけを使ってトレーニング・評価を行う設定
fewshot_fraction = 0.1
# データ分割の設定 - 学習用 60% , テスト用 20% , 残り 20%
split_config = {"train": 0.6, "test": 0.2}
# Finetuning時のログ、モデルなどの保存フォルダ
OUT_DIR = "C:\\Qiita\\202505\\ttm_results"
# GPU(CUDA)が使えれば使う、無ければCPU。
device = "cuda" if torch.cuda.is_available() else "cpu"
#-----------------------------------------------
# データ分割「訓練・検証・テスト」
#-----------------------------------------------
# input_df を context_length を考慮しながら「訓練・検証・テスト」に分割
train_df, valid_df, test_df = prepare_data_splits(input_df, context_length=context_length, split_config=split_config)
#---------------------------------------------------------------
# E. モデル実行パート
#---------------------------------------------------------------
#-----------------------------------------------
# モデル用 Preprocessor の初期化と学習
#-----------------------------------------------
tsp = TimeSeriesPreprocessor(
**column_specifiers, # カラム定義
context_length=context_length, # 学習に使用するレコード数(ここでは512)
prediction_length=prediction_length, # 予測するレコード数(96)
scaling=True, # スケーリング(標準化や正規化)
encode_categorical=False, # カテゴリ変数(文字列など)を数値にエンコードするかどうか。数値データのみのためFalse
scaler_type="standard", # 平均0・標準偏差1に標準化(StandardScalerを使うイメージ)
)
#-----------------------------------------------
# モデルパラメータ設定
#-----------------------------------------------
# ランダムSeeDの設定 - 42はおまじない
set_seed(42)
# Granite Time Seriesモデル設定
finetune_forecast_model = TinyTimeMixerForPrediction.from_pretrained(
"ibm-granite/granite-timeseries-ttm-r2", # Hugging Face 上の IBMのGraniteシリーズ 時系列モデル(TinyTimeMixer)
num_input_channels=tsp.num_input_channels, # 入力のチャンネル数(= モデルに渡す特徴量の数) tspで自動で計算されてる。
prediction_channel_indices=tsp.prediction_channel_indices, # 予測対象の指定 tspで計算されている。
exogenous_channel_indices=tsp.exogenous_channel_indices, # 外部変数(エクソジェニアス変数)」の位置を指定。tspで計算されている。
fcm_use_mixer=True, # FCM = Forecast Channel Mixing 複数の特徴量(チャネル)を混ぜながら時系列の未来を予測するしくみを有効化する。
fcm_context_length=10, # FCMに渡す「過去の参照ウィンドウ」の長さ。10ステップ分のデータを見て未来を考える、という設定。
enable_forecast_channel_mixing=True, # チャネル間の Mixing を Decoder 側でも使うかどうか。有効にすると、予測を出すときにも特徴量同士を混ぜて、より複雑なパターンを捉えることができる。
decoder_mode="mix_channel", # Decoder(予測を生成する側)での挙動設定。"mix_channel" にすると、チャンネル間のミキシングを有効化した構造になる
)
#-----------------------------------------------
# 事前学習を更新せず利用する (backborne)設定
#-----------------------------------------------
# **「backbone」部分の重みは、事前学習されたまま固定して、学習時には更新しない(凍結する)**という意味
print(
"Number of params before freezing backbone",
count_parameters(finetune_forecast_model),
)
for param in finetune_forecast_model.backbone.parameters():
param.requires_grad = False
# Count params
print(
"Number of params after freezing the backbone",
count_parameters(finetune_forecast_model),
)
#-----------------------------------------------
# データセット作成(Preprocessorの内容を反映)
#-----------------------------------------------
# データセットの作成 (split_config 60:20:20)
# 学習・検証・テスト用のPyTorch Dataset に変換
train_dataset, valid_dataset, test_dataset = get_datasets(
tsp, # 事前定義したPreprocessor
input_df,
split_config, # 60:20:20
fewshot_fraction=fewshot_fraction, # 0.1
fewshot_location="first", # few-shotに使うデータの取り方。「first」なら、データの最初からfew-shotサンプルを取る。("random"もある)
use_frequency_token=finetune_forecast_model.config.resolution_prefix_tuning, # 周波数情報(時間の粒度情報、'1H'や'1D'を埋め込むか?)。ここではモデルの事前設定をそのまま使う設定
)
#-----------------------------------------------
# ハイパーパラメータ設定
#-----------------------------------------------
learning_rate: float = 0.001 # learning_rate: 学習の速さ
num_epochs: int = 20 # num_epochs: 最大 20 エポックまで学習
patience: int = 5 # patience: 精度が改善しない状態が 5 エポック続いたら早期終了
batch_size: int = 32 # batch_size: 一度に何個の時系列スライスを学習するか(32個)
#-----------------------------------------------
# Fine-Tuningのパラメータ設定
#-----------------------------------------------
# Trainer の学習設定(TrainingArguments)
finetune_forecast_args = TrainingArguments(
output_dir=os.path.join(OUT_DIR, "output"), # モデル出力先ディレクトリ
overwrite_output_dir=True, # 上書
learning_rate=learning_rate,
num_train_epochs=num_epochs,
do_eval=True, # 各エポックごとに検証を行う
eval_strategy="epoch", # 1エポックごとに評価
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=0, # CPUなら 0 推奨 (マルチスレッドより安定)
report_to=None,
save_strategy="epoch", # 1エポックごとにモデル保存(ただし save_total_limit=1 なので最新だけ残す)
logging_strategy="epoch",
save_total_limit=1,
logging_dir=os.path.join(OUT_DIR, "logs"), # Make sure to specify a logging directory
load_best_model_at_end=True, # 最も良かったエポックのモデルを保存
metric_for_best_model="eval_loss", # 評価指標は損失関数(小さい方が良い)
greater_is_better=False, # For loss
use_cpu=device != "cuda", # GPU が使えないときは CPU で実行
)
#-----------------------------------------------
# 早期終了の設定
#-----------------------------------------------
# EarlyStopping(早期終了の設定)
# 評価損失 (eval_loss) の改善が 0.001 未満で 5 エポック 続くと自動終了
# → 無駄な学習を防いでオーバーフィッティングも回避!
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=patience, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.001, # Minimum improvement required to consider as improvement
)
# ログなどのカスタム設定
tracking_callback = TrackingCallback()
#-----------------------------------------------
# Optimizer / スケジューラ設定
#-----------------------------------------------
# Optimizer(最適化手法)と Scheduler(学習率スケジューラー)の設定
# AdamW:定番の最適化手法(重み減衰に強い)
optimizer = AdamW(finetune_forecast_model.parameters(), lr=learning_rate)
# OneCycleLR:最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整
scheduler = OneCycleLR(
optimizer,
learning_rate,
epochs=num_epochs,
steps_per_epoch=math.ceil(len(train_dataset) / (batch_size)),
)
#-----------------------------------------------
# FineTurningの実行
#-----------------------------------------------
# Trainer インスタンス作成
finetune_forecast_trainer = Trainer(
model=finetune_forecast_model, # FineTuneモデル
args=finetune_forecast_args, # Trainer の学習設定
train_dataset=train_dataset, # 学習用データセット
eval_dataset=valid_dataset, # 検証用データセット
callbacks=[early_stopping_callback, tracking_callback], # EarlyStopping(早期終了の設定)
optimizers=(optimizer, scheduler), # Optimizer(最適化手法)と Scheduler(学習率スケジューラー)
)
# 学習スタート
finetune_forecast_trainer.train()
#-----------------------------------------------
# モデルPipelineの作成・実行
#-----------------------------------------------
# 予測パイプラインの作成と実行
pipeline = TimeSeriesForecastingPipeline(
finetune_forecast_model, # fewshot - finetuneモデル
device=device, # GPU or CPU.
feature_extractor=tsp, # Preprocessor
batch_size=batch_size,
)
# Make a forecast on the target column given the input data.
finetune_forecast = pipeline(test_df)
print(finetune_forecast.head())
#-----------------------------------------------
# モデル精度の確認
#-----------------------------------------------
print("epoch = " , num_epochs)
print("patience = " , patience)
print("learning_rate = " , learning_rate)
print("batch_size = " , batch_size)
# Define some standard metrics.
def custom_metric(actual, prediction, column_header="results"):
"""Compute MSE, RMSE, MAE, and MAPE"""
a = np.asarray(actual.tolist())
p = np.asarray(prediction.tolist())
mask = ~np.any(np.isnan(a), axis=1)
# MSE
mse = np.mean(np.square(a[mask, :] - p[mask, :]))
# MAE
mae = np.mean(np.abs(a[mask, :] - p[mask, :]))
# MAPE
# 0除算を避けるため、小さすぎる値は無視する(1e-8など)
safe_a = np.where(np.abs(a[mask, :]) < 1e-8, np.nan, a[mask, :])
mape = np.nanmean(np.abs((safe_a - p[mask, :]) / safe_a)) * 100
return pd.DataFrame(
{
column_header: {
"mean_squared_error": mse,
"root_mean_squared_error": np.sqrt(mse),
"mean_absolute_error": mae,
"mean_absolute_percentage_error": mape,
}
}
)
# モデル精度の表示
print(custom_metric(
finetune_forecast["total load actual"],
finetune_forecast["total load actual_prediction"],
"fine-tune forecast (total load)",
))
では詳細をみていきましょう。
a. ライブラリ導入パート
各種必要なライブラリをインポートしています。
math や os はFine-tuningする際にモデルを保存するために使っています。
Fine-tuningのために各種ライブラリも必要なので、Zero-shotモデル時より多くインポートしています。
#---------------------------------------------------------------
# A. ライブラリ導入パート
#---------------------------------------------------------------
# Modeler用ライブラリ
import modelerpy
# 各種処理用
import numpy as np
import pandas as pd
# Finetuningモデル保存用
import math
import os
# モデル作成用 - FineTuning
# pytorch
import torch
# 最適化手法の一つで、Adam に weight decay(重みの減衰) を加えたもの
# 補足: 通常のAdamだとL2正則化がうまく効かないことがある → それを修正したのがAdamW
from torch.optim import AdamW
# スケジューラ
# 学習率(Learning Rate)を 1サイクルの形で調整するスケジューラ
from torch.optim.lr_scheduler import OneCycleLR # 最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整
# 早期終了(Early Stopping) 用のコールバック
# トレーニング統合クラス
# Trainer に渡す設定(学習率、バッチサイズ、出力先など)を保持するクラス
from transformers import EarlyStoppingCallback, Trainer, TrainingArguments, set_seed
# IBM Granite TTM
from tsfm_public import (
TimeSeriesForecastingPipeline, # 時系列予測のパイプライン
TimeSeriesPreprocessor, # 入力データの整形・スケーリング
TinyTimeMixerForPrediction, # 時系列予測モデル
TrackingCallback, # 学習中にログを取ったり、追加で何かを記録するための カスタムCallback
count_parameters, # モデルの総パラメータ数を数えて出力してくれる関数
get_datasets, # 前処理済みのDataFrameを、モデルが扱える Dataset形式(学習/検証/テスト) に変換する関数
)
# 入力データをtrain/valid/test に自動で分割してくれる関数
from tsfm_public.toolkit.time_series_preprocessor import prepare_data_splits
b. カラム定義とデータの入力パート
ここは、モデルで使用するカラムの定義と
SPSS Modelerからデータを取得しています。
前回同様に、time をタイムスタンプ型に変換しています。
特に難しくはありませんね。
#---------------------------------------------------------------
# B. カラム定義
#---------------------------------------------------------------
# タイムスタンプカラム
timestamp_column = "time"
# 予測対象カラム名
target_column = "total load actual"
#---------------------------------------------------------------
# C. データ入力パート
#---------------------------------------------------------------
#ModelerからPandasでデータを入力
modelerData = modelerpy.readPandasDataframe()
input_df = modelerData
# 時系列カラム"time"をタイムスタンプ型に変更
input_df[ timestamp_column ] = pd.to_datetime(input_df[ timestamp_column ])
c. モデル用各種設定・ロール定義パート
ここではモデルで使用するカラムのロール設定やモデルのパラメータを定義しています。
Zero-Shotモデルとの違いは、コントロール変数を定義しているところですね。
Modelerで作成した中央値の気象データを column_specifiers の control_columns で指定しています。
また、精度検証のために、学習用、テスト用にデータを分割しています。
使用するモデルは、Zero-Shotの時と同じものを使用しています。
★ Point
このパートでのポイントはFew-Shotの設定部分です。
データセットのうち、10%だけを使ってトレーニング・評価を行う設定
フルデータではなく、少量のデータ(few-shot) だけでモデルを fine-tune して、それでも良い精度が出るか?少ないデータにモデルがどれだけ強いか?
実際のビジネス環境では「大量のデータがない」ケースもあるため、「少量のデータでも学習可能」なことを確認するのは大事。
今回は、0.1 = 10% で設定しています。
fewshot_fraction = 0.1
※.最初は、0.05 = 5%でやっていましたが、データ量や実行環境の非力さから0.1に変更しました。
#---------------------------------------------------------------
# D. モデル用データ準備パート
#---------------------------------------------------------------
#-----------------------------------------------
# カラムロール設定
#-----------------------------------------------
# 予測対象カラム定義
target_columns = [ target_columns ] #リストにする
# カラムロール設定
# 説明変数には、各日時の気象データの中央値を指定
column_specifiers = {
"timestamp_column": timestamp_column, # タイムスタンプカラム
"id_columns": [], # 複数系列を識別するためのID(今回は1系列なので空)
"target_columns": target_columns, # 予測対象カラム
"control_columns": [ # コントロール変数(気象データなど)
"temp_MA24H_Median",
"temp_min_MA24H_Median",
"temp_max_MA24H_Median",
"pressure_MA24H_Median",
"wind_speed_MA24H_Median",
"wind_deg_MA24H_Median",
"humidity_MA24H_Median",
"rain_1h_MA24H_Median",
"rain_3h_MA24H_Median",
"clouds_all_MA24H_Median",
],
}
#-----------------------------------------------
# 使用モデル用パラメータ設定
#-----------------------------------------------
# モデルが「過去何ステップ分のデータを見て」学習・予測するか(ここでは過去512時間分)
context_length = 512 # the max context length for the 512-96 model
# モデルが「未来何ステップ先まで予測」するか(ここでは96時間先=4日分)
prediction_length = 96 # the max forecast length for the 512-96 model
# 使用モデルバージョン
TTM_MODEL_REVISION = "512-96-ft-r2.1"
#-----------------------------------------------
# 使用データ設定
#-----------------------------------------------
# データセットのうち、10%だけを使ってトレーニング・評価を行う設定
fewshot_fraction = 0.1
# データ分割の設定 - 学習用 60% , テスト用 20% , 残り 20%
split_config = {"train": 0.6, "test": 0.2}
# Finetuning時のログ、モデルなどの保存フォルダ
OUT_DIR = "C:\\Qiita\\202505\\ttm_results"
# GPU(CUDA)が使えれば使う、無ければCPU。
device = "cuda" if torch.cuda.is_available() else "cpu"
#-----------------------------------------------
# データ分割「訓練・検証・テスト」
#-----------------------------------------------
# input_df を context_length を考慮しながら「訓練・検証・テスト」に分割
train_df, valid_df, test_df = prepare_data_splits(input_df, context_length=context_length, split_config=split_config)
d. モデル実行パート
さて、本丸ですよ。ちょっと長いですが。
流れは、
- Preprocessorの設定
- Granite Time Seriesのパラメータ設定
- backbornの設定
- データセット作成
- ハイパーパラメータ設定
- Finetuningパラメータ設定
- 早期終了設定
- Optimizer / スケジューラ設定
- FineTurningの実行
- モデルPipelineの作成・実行
と、10ステップもあります。
d-1. Preprocessorの設定
まずは、Zero-Shotモデルの時もあった、Preprocessorの設定です。
ここは、モデル用のデータの扱い方などの定義をします。正規化などやカラムの定義をここで設定。
#-----------------------------------------------
# モデル用 Preprocessor の初期化と学習
#-----------------------------------------------
tsp = TimeSeriesPreprocessor(
**column_specifiers, # カラム定義
context_length=context_length, # 学習に使用するレコード数(ここでは512)
prediction_length=prediction_length, # 予測するレコード数(96)
scaling=True, # スケーリング(標準化や正規化)
encode_categorical=False, # カテゴリ変数(文字列など)を数値にエンコードするかどうか。数値データのみのためFalse
scaler_type="standard", # 平均0・標準偏差1に標準化(StandardScalerを使うイメージ)
)
d-2. Granite Time Seriesのパラメータ設定
ここも、Zero-Shotモデルの時もあった、Granite Time Seriesモデルのパラメータ設定です。
Preprocessorで定義したものをモデルに渡しているのと、FCM (Forecast Channel Mixing)を使い。特徴量を混ぜ合わせながら未来を予測する機能を有効にしています。
また、何度実行しても同じデータセットになるように、ランダムシードも設定しています。
#-----------------------------------------------
# モデルパラメータ設定
#-----------------------------------------------
# ランダムSeeDの設定 - 42はおまじない
set_seed(42)
# Granite Time Seriesモデル設定
finetune_forecast_model = TinyTimeMixerForPrediction.from_pretrained(
"ibm-granite/granite-timeseries-ttm-r2", # Hugging Face 上の IBMのGraniteシリーズ 時系列モデル(TinyTimeMixer)
num_input_channels=tsp.num_input_channels, # 入力のチャンネル数(= モデルに渡す特徴量の数) tspで自動で計算されてる。
prediction_channel_indices=tsp.prediction_channel_indices, # 予測対象の指定 tspで計算されている。
exogenous_channel_indices=tsp.exogenous_channel_indices, # 外部変数(エクソジェニアス変数)」の位置を指定。tspで計算されている。
fcm_use_mixer=True, # FCM = Forecast Channel Mixing 複数の特徴量(チャネル)を混ぜながら時系列の未来を予測するしくみを有効化する。
fcm_context_length=10, # FCMに渡す「過去の参照ウィンドウ」の長さ。10ステップ分のデータを見て未来を考える、という設定。
enable_forecast_channel_mixing=True, # チャネル間の Mixing を Decoder 側でも使うかどうか。有効にすると、予測を出すときにも特徴量同士を混ぜて、より複雑なパターンを捉えることができる。
decoder_mode="mix_channel", # Decoder(予測を生成する側)での挙動設定。"mix_channel" にすると、チャンネル間のミキシングを有効化した構造になる
)
d-3. backbornの設定
IBM Granite Time Seriesは、すでに一般的なパターン(例えば時系列の動きやトレンド)を学習しています(backborn部分)。そのため backbone を固定し、上に載せる「出力層(ヘッド)」だけ学習することで、少ないデータでも精度よく学習できるようにしています。
訓練時間も短縮され、過学習も防げます。
要するに Granite Time Seriesの事前学習部分は残しながら学習させる設定。
print文は、パラメータ数を確認しているだけです。
#-----------------------------------------------
# 事前学習を更新せず利用する (backborne)設定
#-----------------------------------------------
# **「backbone」部分の重みは、事前学習されたまま固定して、学習時には更新しない(凍結する)**という意味
print(
"Number of params before freezing backbone",
count_parameters(finetune_forecast_model),
)
for param in finetune_forecast_model.backbone.parameters():
param.requires_grad = False
# Count params
print(
"Number of params after freezing the backbone",
count_parameters(finetune_forecast_model),
)
d-4. データセット作成
先ほどデータは分割していますが、
学習 (train) では、モデルに最適な形(PyTorch Dataset形式)に加工したデータ(train_dataset, valid_dataset)を使う必要があるので、ここで加工します。
#-----------------------------------------------
# データセット作成(Preprocessorの内容を反映)
#-----------------------------------------------
# データセットの作成 (split_config 60:20:20)
# 学習・検証・テスト用のPyTorch Dataset に変換
train_dataset, valid_dataset, test_dataset = get_datasets(
tsp, # 事前定義したPreprocessor
input_df,
split_config, # 60:20:20
fewshot_fraction=fewshot_fraction, # 0.1
fewshot_location="first", # few-shotに使うデータの取り方。「first」なら、データの最初からfew-shotサンプルを取る。("random"もある)
use_frequency_token=finetune_forecast_model.config.resolution_prefix_tuning, # 周波数情報(時間の粒度情報、'1H'や'1D'を埋め込むか?)。ここではモデルの事前設定をそのまま使う設定
)
d-5. ハイパーパラメータ設定
★ point
ここが、ポイントになります。学習の速さや、エポック数などが学習時間や精度に関わってきます。
あまりにも時間がかかる!や精度が悪いなどあれば、これらの値を変更して試行錯誤してください。
※.サンプルでは、エポック数 = 200、学習率 0.0004等の値で実行しています。
#-----------------------------------------------
# ハイパーパラメータ設定
#-----------------------------------------------
learning_rate: float = 0.001 # learning_rate: 学習の速さ
num_epochs: int = 20 # num_epochs: 最大 20 エポックまで学習
patience: int = 5 # patience: 精度が改善しない状態が 5 エポック続いたら早期終了
batch_size: int = 32 # batch_size: 一度に何個の時系列スライスを学習するか(32個)
d-6. Fine-Tuningのパラメータ設定
★ point
dataloader_num_workers=0 と並列実行しない設定となっています。
CPUの場合は、0がよいみたいです。筆者の環境では2以上などマルチにすると実行時間が伸びる感じでした。
GPUなら並列処理が得意なので4などの値がいいみたいです。
#-----------------------------------------------
# FineTuningのパラメータ設定
#-----------------------------------------------
# Trainer の学習設定(TrainingArguments)
finetune_forecast_args = TrainingArguments(
output_dir=os.path.join(OUT_DIR, "output"), # モデル出力先ディレクトリ
overwrite_output_dir=True, # 上書
learning_rate=learning_rate,
num_train_epochs=num_epochs,
do_eval=True, # 各エポックごとに検証を行う
eval_strategy="epoch", # 1エポックごとに評価
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=0, # CPUなら 0 推奨 (マルチスレッドより安定)
report_to=None,
save_strategy="epoch", # 1エポックごとにモデル保存(ただし save_total_limit=1 なので最新だけ残す)
logging_strategy="epoch",
save_total_limit=1,
logging_dir=os.path.join(OUT_DIR, "logs"), # Make sure to specify a logging directory
load_best_model_at_end=True, # 最も良かったエポックのモデルを保存
metric_for_best_model="eval_loss", # 評価指標は損失関数(小さい方が良い)
greater_is_better=False, # For loss
use_cpu=device != "cuda", # GPU が使えないときは CPU で実行
)
d-7. 早期終了設定
改善が見込めなければ、モデルの学習を終了して次に進ませる設定です。
ログの出力も設定しておきます。
#-----------------------------------------------
# 早期終了の設定
#-----------------------------------------------
# EarlyStopping(早期終了の設定)
# 評価損失 (eval_loss) の改善が 0.001 未満で 5 エポック 続くと自動終了
# → 無駄な学習を防いでオーバーフィッティングも回避!
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=patience, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.001, # Minimum improvement required to consider as improvement
)
# ログなどのカスタム設定
tracking_callback = TrackingCallback()
d-8. Optimizerとスケジューラ設定
モデルのパラメータ(重み)の更新方法に AdamW を指定しています。
finetune_forecast_model.parameters() で、モデルのすべての学習対象パラメータを取ってきて、
指定した学習率(learning_rate = 0.001)で、AdamWで最適化するようにセットしています。
スケジューラは、学習率を固定にしないで、小さくしたり大きくしたりすることで、より良い結果が出やすくなります。
OneCycleLR : 最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整。
#-----------------------------------------------
# Optimizer / スケジューラ設定
#-----------------------------------------------
# Optimizer(最適化手法)と Scheduler(学習率スケジューラー)の設定
# AdamW:定番の最適化手法(重み減衰に強い)
optimizer = AdamW(finetune_forecast_model.parameters(), lr=learning_rate)
# OneCycleLR:最初ゆっくり→中盤速く→最後ゆっくり…と学習率を動的に調整
scheduler = OneCycleLR(
optimizer,
learning_rate,
epochs=num_epochs,
steps_per_epoch=math.ceil(len(train_dataset) / (batch_size)),
)
d-9. Fine-Tuningの実行
ここまでの設定を元にFine-Tuningを実行します。
#-----------------------------------------------
# FineTuningの実行
#-----------------------------------------------
# Trainer インスタンス作成
finetune_forecast_trainer = Trainer(
model=finetune_forecast_model, # FineTuneモデル
args=finetune_forecast_args, # Trainer の学習設定
train_dataset=train_dataset, # 学習用データセット
eval_dataset=valid_dataset, # 検証用データセット
callbacks=[early_stopping_callback, tracking_callback], # EarlyStopping(早期終了の設定)
optimizers=(optimizer, scheduler), # Optimizer(最適化手法)と Scheduler(学習率スケジューラー)
)
# 学習スタート
finetune_forecast_trainer.train()
d-10. Pipelineの実行
Fine-Tuningしたモデルを使ってPipelineを実行し予測結果を取得します。
渡すデータは、テスト用データですね。
#-----------------------------------------------
# モデルPipelineの作成・実行
#-----------------------------------------------
# 予測パイプラインの作成と実行
pipeline = TimeSeriesForecastingPipeline(
finetune_forecast_model, # fewshot - finetuneモデル
device=device, # GPU or CPU.
feature_extractor=tsp, # Preprocessor
batch_size=batch_size,
)
# Make a forecast on the target column given the input data.
finetune_forecast = pipeline(test_df)
print(finetune_forecast.head())
e. モデルの精度確認
最後に精度を確認しています。
MAPE(絶対平均パーセント誤差)を基準にしたかったので、確認できるようにしています。
epoch数などのハイパーパラメータと共に表示させながら
よい精度になるまで、試行錯誤しながら何回も実行します。
#-----------------------------------------------
# モデル精度の確認
#-----------------------------------------------
print("epoch = " , num_epochs)
print("patience = " , patience)
print("learning_rate = " , learning_rate)
print("batch_size = " , batch_size)
# Define some standard metrics.
def custom_metric(actual, prediction, column_header="results"):
"""Compute MSE, RMSE, MAE, and MAPE"""
a = np.asarray(actual.tolist())
p = np.asarray(prediction.tolist())
mask = ~np.any(np.isnan(a), axis=1)
# MSE
mse = np.mean(np.square(a[mask, :] - p[mask, :]))
# MAE
mae = np.mean(np.abs(a[mask, :] - p[mask, :]))
# MAPE
# 0除算を避けるため、小さすぎる値は無視する(1e-8など)
safe_a = np.where(np.abs(a[mask, :]) < 1e-8, np.nan, a[mask, :])
mape = np.nanmean(np.abs((safe_a - p[mask, :]) / safe_a)) * 100
return pd.DataFrame(
{
column_header: {
"mean_squared_error": mse,
"root_mean_squared_error": np.sqrt(mse),
"mean_absolute_error": mae,
"mean_absolute_percentage_error": mape,
}
}
)
# モデル精度の表示
print(custom_metric(
finetune_forecast["total load actual"],
finetune_forecast["total load actual_prediction"],
"fine-tune forecast (total load)",
))
④. 精度の確認
さて、ここまでのものを実行すると、精度が確認できます。
赤枠で囲った部分が、精度分析の部分です。
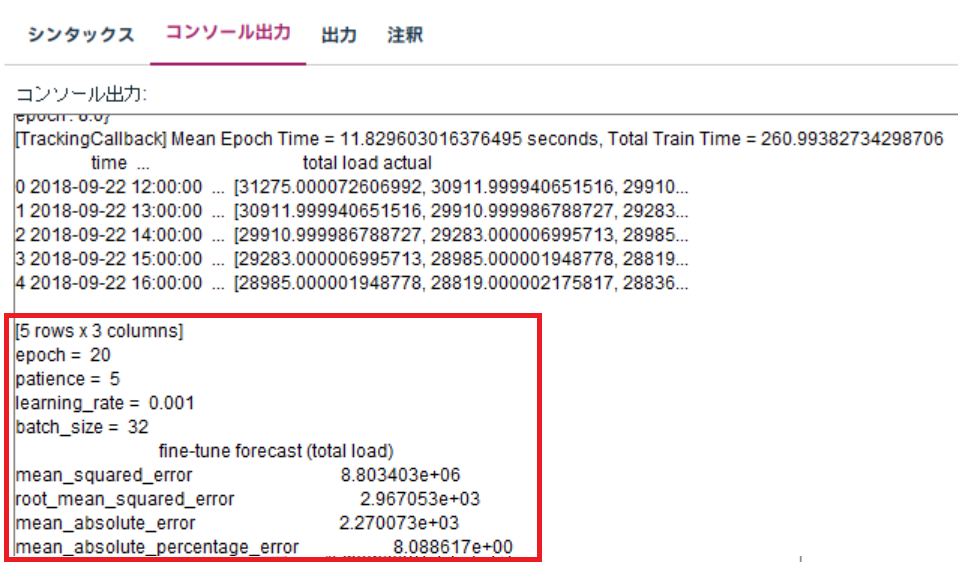
エポック数を増やしたり、学習率を小さくしたり、何回も試行錯誤した結果
エポック数 20
patience 5
learning_rate 0.001
batch_size 32
の時に、約260秒くらいの実行時間で、
MAPE(絶対平均パーセント誤差)が、8% 程度になりました。
非力な環境ですとここらへんが限界かな?と思いました。とほほ。
ご了承ください。
6. まとめ
さて、いかがでしたでしょうか。
今回は、IBM Granite Time Serires ModelをFine-Tuningし、精度を確認しました。
今後このようなモデルをFine-Tuningして使う場合は、GPUが必須ですね。痛感しました。
オンプレで無理ならクラウドを利用するなど考えていきたいと思います。
次回は、Zero-Shotモデルの場合と同じように予測結果をModelerに戻す処理に、チャレンジしたいと思います。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログなどは以下のTechXchangeのコミュニティに統合されました。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan