クラスター分析をしている時に、最適なクラスター数を探すにはどうしたらいいのか?と考えるときありませんか?基本、シルエットスコアやクラスター毎のレコード数や特徴をみて、分析者が判断するものだと思っています。が、とりあえず何個くらいに分ければいいのか、ヒントが欲しいですよね。
SPSS Modeler にはクラスター分析をするために、K-meansやKohonen、TwoStepといったモデルが用意されていますが、分析者がモデル構築前に、クラスター数を指定する必要があります。
※.TwoStepは作成したいクラスター数の最大値、最小値を指定
※.Kohonenはオプションで幅と長さを指定可能
そこで、シルエットスコアやエルボー法という指標を用いて、最適なクラスター数を推定しようと思います。記事の題名がその1となっていますが、その2も作成する予定です。
その1 – SPSS Modeler 自動クラスタリングノードを利用
その2 – SPSS Modeler 拡張ノード(Python for Spark)を利用
※2025-03-11 本記事で使用した、ストリームとデータをGitHubにアップしました。
シルエットスコアとは
シルエットスコア(Silhouette Score)は、クラスタリングの効果を評価するために使用される指標の一つです。このスコアは、各データポイントがどの程度適切にクラスタリングされているかを数値で示します。具体的には、クラスタ内の凝集度とクラスタ間の分離度を用いて計算されます。
シルエットスコアは -1 から 1 の範囲で、1 に近いほどクラスタリングの品質が高いことを示します。スコアが 0 に近い場合は、クラスタの境界が曖昧であることを示し、負の値はクラスタリングが不適切である可能性があります。
引用
※.引用元のそのままの内容を記載させていただいております。
エルボー法
エルボー法は、それぞれのクラスター内の誤差平方和(SSE)を計算し、クラスター数とそれぞれの誤差平方和の和をプロットして適切なクラスター数を判断する手法です。エルボー(肘)のように曲線が折れ曲がる点が適切なクラスター数と考えます。

SPSS Modelerの自動クラスタリングノード
シルエットスコアを使って最適なクラスター数を推定しようと思いますが、何回もモデルを作成しシルエットスコアを確認するのは大変です。なので、Pythonを使ってクラスター数を変えながらシルエットスコアを計算しようと思ってプログラムまで書いてから、そんなことしなくてもSPSS Modelerには、自動クラスタリングノードでできることが分かりました。(‘Д’)
では実際やってみましょう。
SPSS Modelerの自動クラスタリングノードを利用したモデルの比較
使用するデータは、みんな大好きirisのデータです。もう最適なクラスター数も想像がつきますが
データダウンロード先
SPSS Modelerは v18.5を利用します。(本記事の内容はバージョン18.5でなくても問題なく実行できます。)
1. 作ったストリーム
シンプル。。入力データもirisなので特に加工などせずに自動クラスタリングノードへデータを渡しています。

2. 各種設定
①. 入力ノード

入力ノードはフィールド名を変更しているだけです。

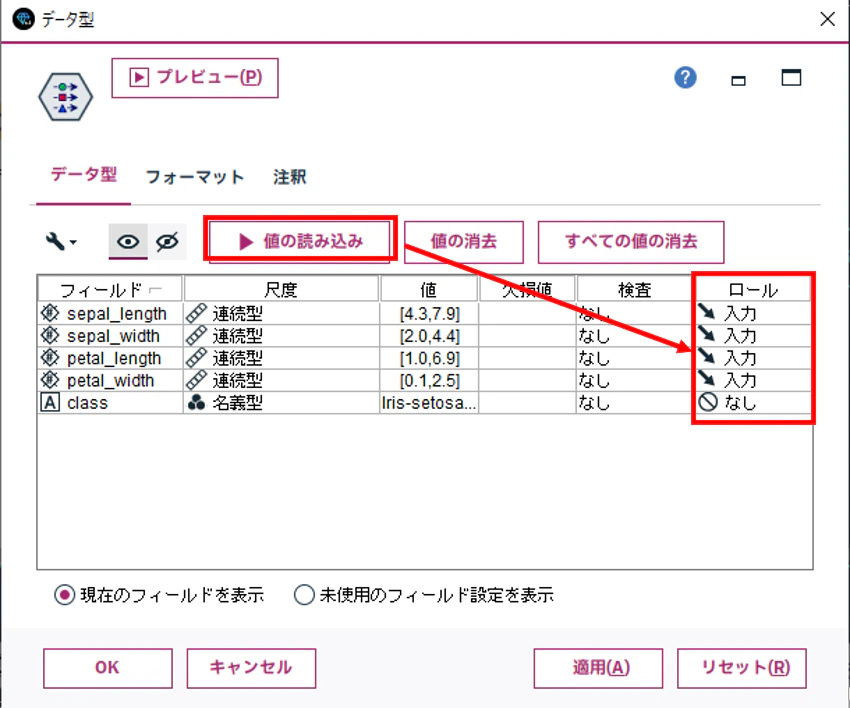
②. データ型ノード

データ型ノードでインスタンス化及びロールを設定しています。入力変数は、class以外のフィールドです。
③.自動クラスタリングノード
自動クラスタリングノードの設定をしていきます。
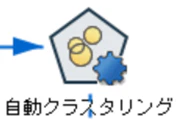
a. エキスパートタブ
K-meansノードのみを選択して、モデルパラメータを指定します。

b. モデルパラメータ
シンプルタブのクラスター数を設定します。今回は2から9までを指定します。
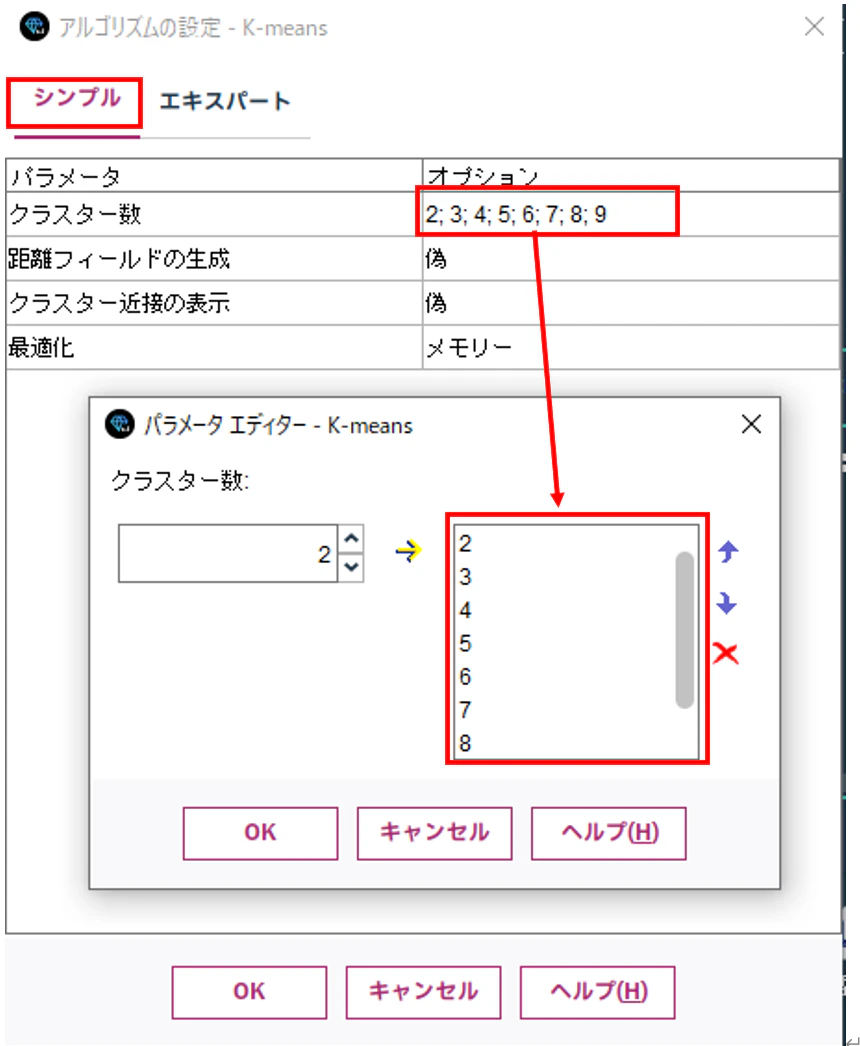
c. モデル作成
設定が完了すると、作成するモデル数が8となっていることが確認できます。2~9までクラスター数を変えたモデルを8個つくるということですね。
あとは、実行ボタンをクリックします。
3. 結果確認
自動クラスタリングナゲットをダブルクリックで開き結果を確認します。全体像の列がシルエットスコアになります。クラスター数別のシルエットスコアが一度に確認できます。また、最小・最大のクラスターのレコード数なども確認でき便利ですね。ちなみに、8個すべての結果ではなく、デフォルトでは上位5個のモデルが表示されるようになっています。

いやー、簡単ですね。
このように一度に複数の設定を試し指標も確認できるのでぜひ活用していきましょう。え?結局どのクラスター数にすればいいかって?個人的には、最小÷最大の値が一番大きく(最小クラスターと最大クラスターのレコード数の差が小さい)、シルエットスコアも高い”3”を選択するのがいいかなと思います。
次回は、SPSS Modelerの拡張ノードを利用してシルエットスコア・SSEを算出してみます。
自動クラスタリングノードで簡単に複数モデルのシルエットスコアを確認できました。が、せっかくプログラムも書いて準備したので、次回は、拡張ノードを利用したPython for Sparkバージョンも紹介したいと思います。本当はこっちのみ記事にするつもりでした。
参考情報
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS funさん記事