ソフトクラスタリングに挑戦!
みなさん。こんにちは。今回はソフトクラスタリングを題材にしてみようと思います。こちらもユーザー様から問い合わせがあり挑戦してみたものになります。
※ 2025/03/14 記事で使用したストリームとデータをGitHubにアップロードしました。
1. ソフトクラスタリングとは?
クラスタリングにはハードとソフトの2種類があります。
それぞれのデータが単一のグループに所属するようにグルーピングするものをハードクラスタリング、複数のグループに所属できることを許してグルーピングするものをソフトクラスタリングといいます。
ハードクラスタリングでは、K-Meansなどが有名ですね。私の記事でも扱いました。
SPSS Modelerの標準機能で利用できます。
ソフトクラスタリングは、SPSS Modelerの標準機能では利用できないので、今回もPython + 拡張ノードでチャレンジしてみました。
ソフトクラスタリングは、Fuzzy C-means(FCM)を利用してみようと思います。scikit-learnでは実行できず、scikit-fuzzyを入れると実行できます。
以下のサイトを参考にさせていただきました。
2. まずは準備から
①. scikit-fuzzyを導入
ライブラリとして、scikit-fuzzyを使用するためこれを導入します。
以下の例は、Modeler v18.5をデフォルトパスでインストールした場合に、ライブラリイを導入する際の例です。
C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts>python.exe -m pip install scikit-fuzzy
②. その他のライブラリ
NumpyやPandasも導入しておきましょう。
③. fuzzy c-meansについて
クラスタリングをする際の使い方は以下の通り
cntr, u, u0, d, jm, p, fpc = skfuzzy.cluster.cmeans(data, c, m, error=None, maxiter=None, init=None, seed=None)
ここでもつたない説明はしますが、詳細は以下を参照してください。
a. 引数
まずは、引数から。
data : 2d array, size (S, N)
クラスタリングするデータ。Nはデータセットの数、Sは各サンプルベクトル内の特徴の数です。
注意点
みなさんもよく使うIris等のデータは、形状が (N_samples,S_features)、つまり (150, 4) といった形で表現されるデータ形式です。
C-Meansでは投入するデータは、形状: (S_features,N_samples)、つまり (4,150) という形で表されます。行と列が逆ですね。場合によっては転置が必要なので注意してください。今回も転置をして実行しています。
c : int
クラスター数。
m : float
c-meansのパラメータです。変えると結果も変わってきます。
error : float
停止基準: エラーの基準を下回った場合に停止させます。
反復して処理を繰り返すものなので停止基準が必要なのです。
maxiter : int
反復の最大回数。
init : 2d array, size (S, N)
初期のfuzzy c-meansの値。何も指定されていない場合は、アルゴリズムはランダムに初期化された値を使います。
まぁ、初期値をどこにするのかなんて分からないので省略でいいと思います。
seed : int
ランダムシード値です。上記のinitパラメータが指定されている場合、効果はありません。
主にデバッグ/テストの目的です。
b.戻り値
つづいて戻り値です。
ちなみに、cntrとu以外は使わないと思います。
cntr : 2d array, size (S, c)
各クラスターの中心の値。
u : 2d array, (S, N)
最終的なfuzzy c-meansの配列データ。
要するにc-meansの結果です。各データがどのクラスタに割り当てられたかを割合で示されます。
S,Nとなっていますが、c,Nでしょうね。クラスタ番号が入るので。
u0 : 2d array, (S, N)
用途が分からない値です。以下が説明。
fuzzy c-meansの行列の初期推定値 (init が指定されているか、または init が指定されていない場合はランダムな推定値が使用されます)。
d : 2d array, (S, N)
最終的なユークリッド距離行列。とのこと。使うかな?
Final Euclidian distance matrix.
jm : 1d array, length P
目的関数の履歴?使わないでしょう。おそらく。
Objective function history.
p : int
実行された反復回数。
fpc : float
Final fuzzy partition coefficient.
はい。何かの係数ですね。わかりません。
c.その他
予測をする際に使い方
u, u0, d, jm, p, fpc = skfuzzy.cluster.cmeans_predict( test_data, cntr_trainedm, error, maxiter, init=None, seed=None )
引数に、cntr_trainedという、モデル作成時の戻り値である各クラスタ中心値を渡す必要があります。
scikit-learnのk-meansモデルのように、モデルを保存しておき、利用する時は呼び出してテストデータだけ渡せばいいだけといった使い方ができないので、ちょっと使い勝手が悪いですね。fuzzy c-meansはモデルというより関数のような感じです。
今回は、こちらは使用していません。
3. Modelerでソフトクラスタリングをやってみる。
準備と、fuzzy c-meansについての簡単な理解ができたら、実装していきましょう。
①.使用データ
使用するデータは、いつものirisのデータです。
データダウンロード先
SPSS Modelerは v18.5を利用します。
②.拡張ノード
Modelerの標準機能では実現できないので、拡張ノードを使います。
今回は、拡張の変換ノードです。

fuzzy c-meansはモデルを作るというより関数を呼び出して使うような感覚なので、拡張のモデルノードではなく、こちらを使用しました。
③. ストリーム全体

シンプルですね。これだけです。
④. ストリーム詳細
詳細をみていきましょう。
a. データ入力
まずは、データ入力。irisのデータをcsvで読み込んでいるだけです。

フィールド名がないので、フィルタータブで付与しています。

b. 拡張ノード - シンタックス全体
拡張ノードのシンタックスをみていきましょう。
#--------------------------------------------------------------
#ライブラリインポート
#--------------------------------------------------------------
#SPSS Modeler ライブラリ
import modelerpy
#numpyインポート
import numpy as np
import pandas as pd
#クラスタモデルインポート
#scikit-fuzzy library
import skfuzzy as fuzz
#--------------------------------------------------------------
# C-Meansモデルに渡すためのパラメータ設定
# 今回はクラスタ数は3つで作成。
# Fuzzy C-meansのパラメータは2。
# 繰り返し回数は1000
# エラー率は0.001
# Seedは12345678
#--------------------------------------------------------------
# Define parameters
c = 3 # Number of clusters
m = 2 # Fuzziness parameter
max_iter = 1000 # Maximum number of iterations allowed.
errp = 0.001 # Stopping criterion
seed_value = 12345678 # Seed
#--------------------------------------------------------------
#データモデル定義処理
#--------------------------------------------------------------
if modelerpy.isComputeDataModelOnly():
#--------------------------------------------------------------
#データモデル取得
#--------------------------------------------------------------
modelerDataModel = modelerpy.getDataModel()
#--------------------------------------------------------------
#モデル用変数フィールドを追加
#--------------------------------------------------------------
#クラスタ数でループ
for n_clt in range(0, c) :
#データモデルにクラスタフィールドを追加
field_name = f"Cluster{n_clt}"
modelerDataModel.addField(modelerpy.Field(field_name, "real", measure="continuous"))
#所属クラスタ用フィールドを追加
modelerDataModel.addField(modelerpy.Field("$CM-Cluster", "integer", measure="continuous"))
#修正したデータモデルをModelerへ戻します。
modelerpy.setOutputDataModel(modelerDataModel)
#--------------------------------------------------------------
#Fuzzy C-Meansモデル処理
#--------------------------------------------------------------
else:
#データをPandasで取得
modelerData = modelerpy.readPandasDataframe()
outputData = None
#学習データを作成
#モデル作成に不要なClassの列を削除します。
input_df = modelerData.drop("Class", axis=1)
#--------------------------------------------------------------
#C-Meansモデル作成開始
# 1. クラスタモデル作成
# 2. データフレームを修正
# 3. 所属クラスタ取得
# 4. データフレームを修正
#--------------------------------------------------------------
#--------------------------------------------------------------
#1. C-Meansモデル作成
# 学習データの形に注意。irisのデータを転置しています。
# initはなし。
#--------------------------------------------------------------
cntr, u, _, _, _, _, _ = fuzz.cluster.cmeans(input_df.T, c, m, error=errp, maxiter=max_iter, init=None, seed=seed_value)
#--------------------------------------------------------------
#2. データフレーム修正
#Modelerに戻すためにデータフレームを修正
#--------------------------------------------------------------
#戻り値の配列は転置してPandasに変換
U_DF = pd.DataFrame(u.T)
#カラム名をデータモデルで定義したものに合わせます。
#クラスタ数でループ カラム名を変更
for cnt in range(0,c):
#データモデルにクラスタフィールドを追加
field_name = f"Cluster{cnt}"
U_DF = U_DF.rename(columns={cnt: field_name})
#C-Means戻り値を入力データ(学習データではない)に追加。
outputData = pd.concat([modelerData,U_DF], axis=1)
#--------------------------------------------------------------
#3. 所属クラスタ取得
#サンプル毎のクラスタ割合のMaxからクラスタを特定
#--------------------------------------------------------------
# 所属クラスタを取得
cluster_membership = np.argmax(u, axis=0)
#--------------------------------------------------------------
#4. 所属クラスタ用のカラムを追加
#--------------------------------------------------------------
#所属クラスタデータをPandasに変換
CM_DF = pd.DataFrame(cluster_membership)
#カラム名を設定
CM_DF = CM_DF.rename(columns={0: "$CM-Cluster"})
#所属クラスタデータを追加
outputData = pd.concat([outputData,CM_DF], axis=1)
#Modelerにデータを戻す
modelerpy.writePandasDataframe(outputData)
c. 拡張ノード - シンタックス詳細
詳細をみていきましょう。
c-1. ライブラリインポート
ライブラリをインポートしています。
c-means用にskfuzzyもインポートします。
#--------------------------------------------------------------
#ライブラリインポート
#--------------------------------------------------------------
#SPSS Modeler ライブラリ
import modelerpy
#numpyインポート
import numpy as np
import pandas as pd
#クラスタモデルインポート
#scikit-fuzzy library
import skfuzzy as fuzz
c-2. 定数定義
クラスタリング用の定数をここで設定しています。``
・Irisなのでクラスタ数は3。
・c-meansのパラメータは一旦、2。(何回も変えながら結果を確認しましょう。)
・反復回数は、1000。
・エラー率は、0.001。(データが少ないので0.01などでもいいと思います。)
・実行毎に結果が異なることがないようにseedを設定しています。
#--------------------------------------------------------------
# C-Meansモデルに渡すためのパラメータ設定
# 今回はクラスタ数は3つで作成。
# Fuzzy C-meansのパラメータは2。
# 繰り返し回数は1000
# エラー率は0.001
# Seedは12345678
#--------------------------------------------------------------
# Define parameters
c = 3 # Number of clusters
m = 2 # Fuzziness parameter
max_iter = 1000 # Maximum number of iterations allowed.
errp = 0.001 # Stopping criterion
seed_value = 12345678 # Seed
c-3. データモデル定義
Modelerとのやり取りで使うデータモデルを定義します。
#--------------------------------------------------------------
#データモデル定義処理
#--------------------------------------------------------------
if modelerpy.isComputeDataModelOnly():
#--------------------------------------------------------------
#データモデル取得
#--------------------------------------------------------------
modelerDataModel = modelerpy.getDataModel()
#--------------------------------------------------------------
#モデル用変数フィールドを追加
#--------------------------------------------------------------
#クラスタ数でループ
for n_clt in range(0, c) :
#データモデルにクラスタフィールドを追加
field_name = f"Cluster{n_clt}"
modelerDataModel.addField(modelerpy.Field(field_name, "real", measure="continuous"))
#所属クラスタ用フィールドを追加
modelerDataModel.addField(modelerpy.Field("$CM-Cluster", "integer", measure="continuous"))
#修正したデータモデルをModelerへ戻します。
modelerpy.setOutputDataModel(modelerDataModel)
詳しく見ていきます。
if modelerpy.isComputeDataModelOnly():
ここは後続がフィルターノード等、データモデルのみを参照するノードの場合に通過する条件分岐ですね。ちなみに、この記述は必須なのでおまじないと思って書いてください。
#--------------------------------------------------------------
#データモデル取得
#--------------------------------------------------------------
modelerDataModel = modelerpy.getDataModel()
modelerpy.getDataModel()でデータモデルを取得しています。これも定型文ですね。
#--------------------------------------------------------------
#モデル用変数フィールドを追加
#--------------------------------------------------------------
#クラスタ数でループ
for n_clt in range(0, c) :
#データモデルにクラスタフィールドを追加
field_name = f"Cluster{n_clt}"
modelerDataModel.addField(modelerpy.Field(field_name, "real", measure="continuous"))
ここでは、取得したデータモデルに、クラスタ毎の所属割合を格納するためのカラムを追加しています。
for文では、最初に設定したクラスタ数分ループし、"Cluster1","Cluster2"のようにカラム名を設定しながら、実数値が格納できるように定義しています。
#所属クラスタ用フィールドを追加
modelerDataModel.addField(modelerpy.Field("$CM-Cluster", "integer", measure="continuous"))
つづいて、$CM-Clusterという一番割合が高いクラスタ番号を格納するカラムを定義しています。
#修正したデータモデルをModelerへ戻します。
modelerpy.setOutputDataModel(modelerDataModel)
最後にカラムを追加したデータモデルをModelerに戻しています。
c-4. fuzzy c-meansクラスタリング処理
さて、本題のクラスタリング処理を見ていきましょう。
fuzzy c-meansで、各クラスタ所属する割合を取得した後に、一番割合の高いクラスタ番号を求めています。
クラスタリングは都度実施するようになっているため、seedを設定して、結果が変わらないようにしています。
#--------------------------------------------------------------
#Fuzzy C-Meansモデル処理
#--------------------------------------------------------------
else:
#データをPandasで取得
modelerData = modelerpy.readPandasDataframe()
outputData = None
#学習データを作成
#モデル作成に不要なClassの列を削除します。
input_df = modelerData.drop("Class", axis=1)
#--------------------------------------------------------------
#C-Meansモデル作成開始
# 1. クラスタモデル作成
# 2. データを修正
# 3. 所属クラスタ取得
# 4. データを修正
#--------------------------------------------------------------
#--------------------------------------------------------------
#1. C-Meansモデル作成
# 学習データの形に注意。irisのデータを転置しています。
# initはなし。
#--------------------------------------------------------------
cntr, u, _, _, _, _, _ = fuzz.cluster.cmeans(input_df.T, c, m, error=errp, maxiter=max_iter, init=None, seed=seed_value)
#--------------------------------------------------------------
#2. データ修正
#Modelerに戻すためにデータフレームを修正
#--------------------------------------------------------------
#戻り値の配列は転置してPandasに変換
U_DF = pd.DataFrame(u.T)
#カラム名をデータモデルで定義したものに合わせます。
#クラスタ数でループ カラム名を変更
for cnt in range(0,c):
#データモデルにクラスタフィールドを追加
field_name = f"Cluster{cnt}"
U_DF = U_DF.rename(columns={cnt: field_name})
#C-Means戻り値を入力データ(学習データではない)に追加。
outputData = pd.concat([modelerData,U_DF], axis=1)
#--------------------------------------------------------------
#3. 所属クラスタ取得
#サンプル毎のクラスタ割合のMaxからクラスタを特定
#--------------------------------------------------------------
# 所属クラスタを取得
cluster_membership = np.argmax(u, axis=0)
#--------------------------------------------------------------
#4. 所属クラスタ用のカラムを追加
#--------------------------------------------------------------
#所属クラスタデータをPandasに変換
CM_DF = pd.DataFrame(cluster_membership)
#カラム名を設定
CM_DF = CM_DF.rename(columns={0: "$CM-Cluster"})
#所属クラスタデータを追加
outputData = pd.concat([outputData,CM_DF], axis=1)
#Modelerにデータを戻す
modelerpy.writePandasDataframe(outputData)
詳細をみていきます。
#データをPandasで取得
modelerData = modelerpy.readPandasDataframe()
outputData = None
まずは、modelerpy.readPandasDataframe()でModelerからデータを取得しています。
#学習データを作成
#モデル作成に不要なClassの列を削除します。
input_df = modelerData.drop("Class", axis=1)
つづいて、fuzzy c-menasに投入するデータはClass列が不要なため、削除しています。
#--------------------------------------------------------------
#1. C-Meansモデル作成
# 学習データの形に注意。irisのデータを転置しています。
# initはなし。
#--------------------------------------------------------------
cntr, u, _, _, _, _, _ = fuzz.cluster.cmeans(input_df.T, c, m, error=errp, maxiter=max_iter, init=None, seed=seed_value)
fuzzy c-menasを実行しています。戻り値は、u(クラスタの所属割合が格納された配列)以外は使いません。cntrで各クラスタの中心値を取得していますが今回は使用しませんでした。
input_df.Tと学習データの行と列を入れ替えているので注意していください。
これは、説明の部分にも書きましたが、fuzzy c-menasに投入する学習データは、形状が(S_features,N_samples)とする必要があるためです。
#--------------------------------------------------------------
#2. データ修正
#Modelerに戻すためにデータフレームを修正
#--------------------------------------------------------------
#戻り値の配列は転置してPandasに変換
U_DF = pd.DataFrame(u.T)
#カラム名をデータモデルで定義したものに合わせます。
#クラスタ数でループ カラム名を変更
for cnt in range(0,c):
#データモデルにクラスタフィールドを追加
field_name = f"Cluster{cnt}"
U_DF = U_DF.rename(columns={cnt: field_name})
#C-Means戻り値を入力データ(学習データではない)に追加。
outputData = pd.concat([modelerData,U_DF], axis=1)
結果の配列データを転置して元の入力データに結合しています。
データモデルの定義と同様にカラム名などを設定してから実施しています。
#--------------------------------------------------------------
#3. 所属クラスタ取得
#サンプル毎のクラスタ割合のMaxからクラスタを特定
#--------------------------------------------------------------
# 所属クラスタを取得
cluster_membership = np.argmax(u, axis=0)
各レコード毎に一番所属割合が高いクラスタを取得しています。
単純に割合が高いインデックスを取得しているだけです。
#--------------------------------------------------------------
#4. 所属クラスタ用のカラムを追加
#--------------------------------------------------------------
#所属クラスタデータをPandasに変換
CM_DF = pd.DataFrame(cluster_membership)
#カラム名を設定
CM_DF = CM_DF.rename(columns={0: "$CM-Cluster"})
#所属クラスタデータを追加
outputData = pd.concat([outputData,CM_DF], axis=1)
取得したクラスタ番号を先ほどのデータにさらに追加します。
データモデルの定義と同じカラム名を設定しています。
#Modelerにデータを戻す
modelerpy.writePandasDataframe(outputData)
最後にModelerへ結果を戻しています。
d. 結果確認
テーブルノードで結果を確認します。
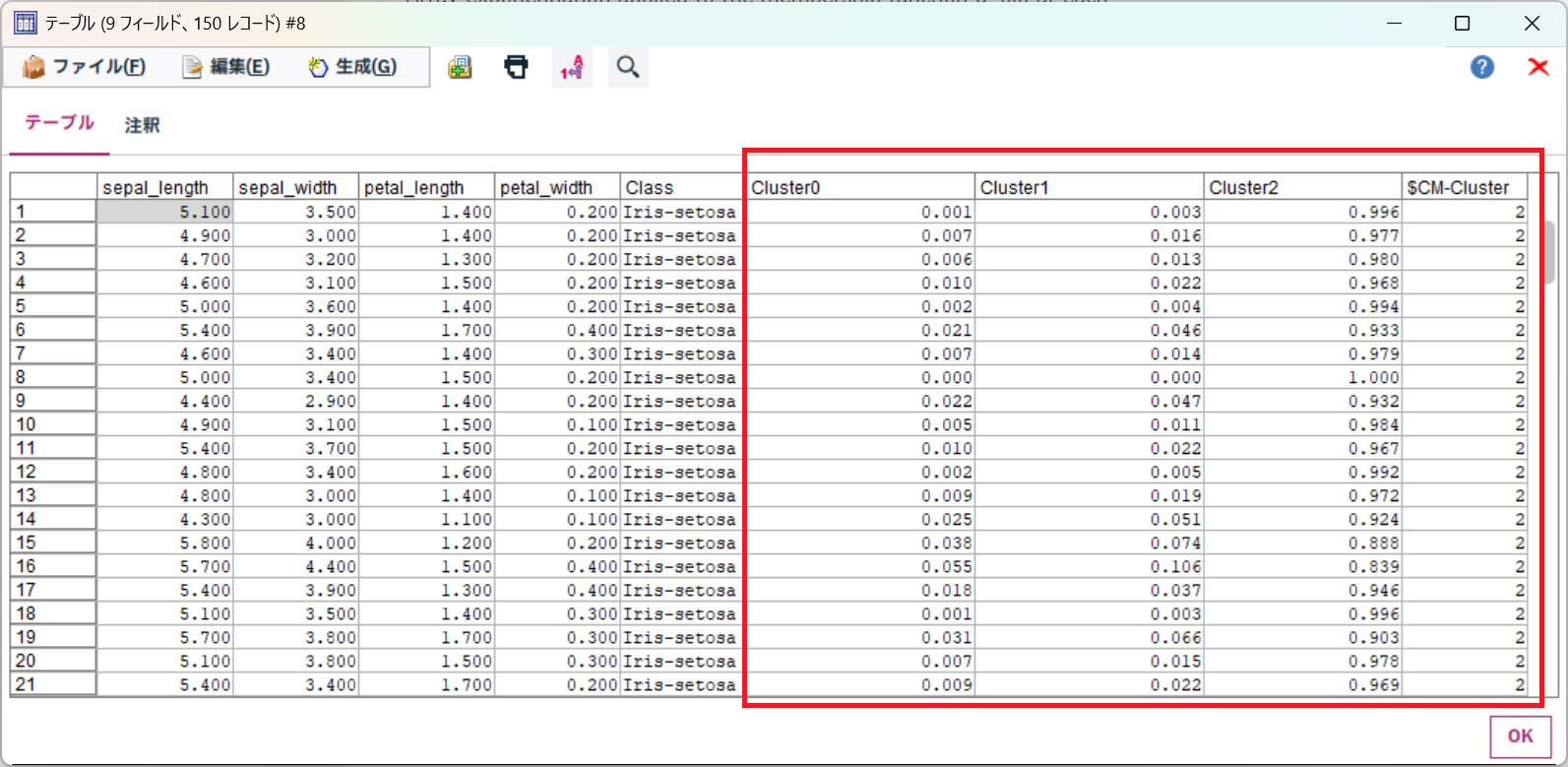
各クラスタに所属する割合と一番割合の高いクラスタ番号が取得できていますね。
このように、K-Meansなどのハードクラスタリングとはことなり、各クラスタに所属する割合が分かるとことがソフトクラスタリングの特徴ですね。
4. まとめ
今回は、ソフトクラスタリングにチャレンジしてみました。まだ、パラメータなど理解ができていない部分も多くあります。
今後も勉強を続けていきます。
複数のクラスタに所属する割合が分かるので、その割合からレコードの特性を理解したり、モデルの入力変数にするなど活用していくことができそうですね。
以上になります。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログ
今後は、ヒモトクブログなどは以下のTechXchangeのコミュニティに統合される予定です。
IBM TechXchange Data Science Japan