SPSS Modelerでのテキストマイニング
みなさん、こんにちは。
今回は、SPSS Modelerでv18.1以降は日本語を解析するノードがサポート対象外となってしまったテキストマイニングをテーマにしています。下記URLの最後の方に記載されていますが、
「IBM SPSS Modeler Text Analytics の日本語アダプターは、バージョン 18.1以降非推奨になりました。」
とても、悲しいです。
※.2024/12月追記
SPSS Modeler v18.6で日本語サポートが復活しました。紹介記事も書いてみました。
SPSS Modeler Premiumライセンスを追加で購入しなくても、SPSS Modelerでテキストマイニングをしてみたい!、もしくは出来ますか?というユーザーの声や質問も多い状況です。
なので、「拡張ノード」 + 「Python」の組み合わせで実現してみようと思います。
※ 2025/03/11 記事で使用したストリームとデータをアップロードしました。
1.感情分析と形態素解析をやってみる
テキストマイニングといっても何をしましょう?となりますが、ここでは、感情分析と形態素解析をやってみようと思います。また、その結果を使ってSPSS Modelerでワードクラウドやアソシエーションモデルを作ってみます。
あと、できるだけ拡張ノードでの実装部分は最小限にして、標準ノードで実装可能な部分は標準ノードの機能を使っていきます。
今回の環境は以下の通りです。
| 項目 | 内容 |
|---|---|
| SPSS Modeler | v18.5(IF01 & IF06 適用) |
| OS | Windows 10(64bit) |
| Python | 3.10.7(デフォルト) |
2. まずは準備が必要
テキストマイニングをするために、前提となる設定やライブラリの導入を実施します。
①. 拡張ノードのネイティブPythonを利用するために
クラスター分析の記事では、拡張ノードのシンタックスは、「Python for Spark」を使用していました。今回は、v18.5から追加されたネイティブPythonを使用してみます。
少しだけ面倒なのは、ネイティブPythonで追加ライブラリを導入して使用する場合は、SPSS ModelerのPython環境へのアクセス権が必要になることです。デフォルトだと"C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv"になります。
ライブラリなど導入する際にアクセス権がないとエラーになってしまいます。そのため、管理者権限のあるユーザーでの利用もしくは、自身のユーザーアカウントでのアクセス権を付与しておいてください。
下記URL参考にして準備をしてください。
※ユーザーの環境によってはセキュリティ上難しい場合があると思います。その場合は、「Python for Spark」を利用することをお勧めします。こちらは、コンフィグファイルでPythonの環境を切り替えることができるので、アクセス権を付与できるフォルダにPythonの環境を構築しましょう。
以下のURLを参考してみてください。
②. 感情分析用モデルの準備
感情分析用のモデルは、「Huggingface Transformers」にある学習済みモデルを使用します。まずは、Transformersをpipでインストールしましょう。
下記例は、コマンドプロンプトからインストールする際の一例です。
デフォルトだと「 C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts」にPython.exeがあります。
C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts>python -m pip install transformers
「Huggingface Transformers」には、「自然言語理解」と「自然言語生成」の最先端の汎用アーキテクチャ(BERT、GPT-2など)と何千もの事前学習済みモデルを提供するライブラリです。下記URLの記事を参考にさせていただきました。
また、Pytorchも必要なため、Pytorchも導入します。
C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts>python -m pip install torch torchvision torchaudio
モデルは、Huggingfaceに公開されている、"koheiduck/bert-japanese-finetuned-sentiment"を利用しようと思います。
"daigo/bert-base-japanese-sentiment"を利用して分析している例もあったのですが、こちらは、現在非公開となっているので利用できませんでした。
トークナイザーはcl-tohoku/bert-base-japanese-whole-word-maskingを使用します。
※2025/1/29追記
v18.6で実行していた時にunidic_liteが導入されていない場合にエラーが発生したため、unidic_liteも導入する手順を追記します。
C:\Program Files\IBM\SPSS\Modeler\18.6\python_venv\Scripts>python.exe -m pip install unidic_lite
③. 形態素解析エンジン
本記事では、「MeCab」を使って形態素解析をしてみます。janomeが扱いやすいと思いますが、すでに下記のブログで「Python for Spark」を利用した例で記載されていますのでぜひ参考にしてください。
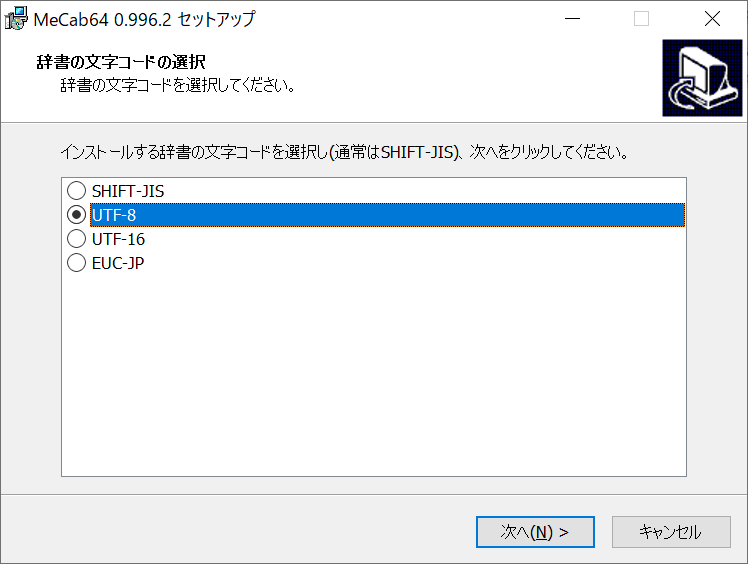
MeCabは、下記URLから「mecab-64-0.996.2.exe」をダウンロードしてインストールしてください。(2024/09 時点のバージョンです。)
辞書をビルドする時の文字コードは、「UTF-8」を選んでください。
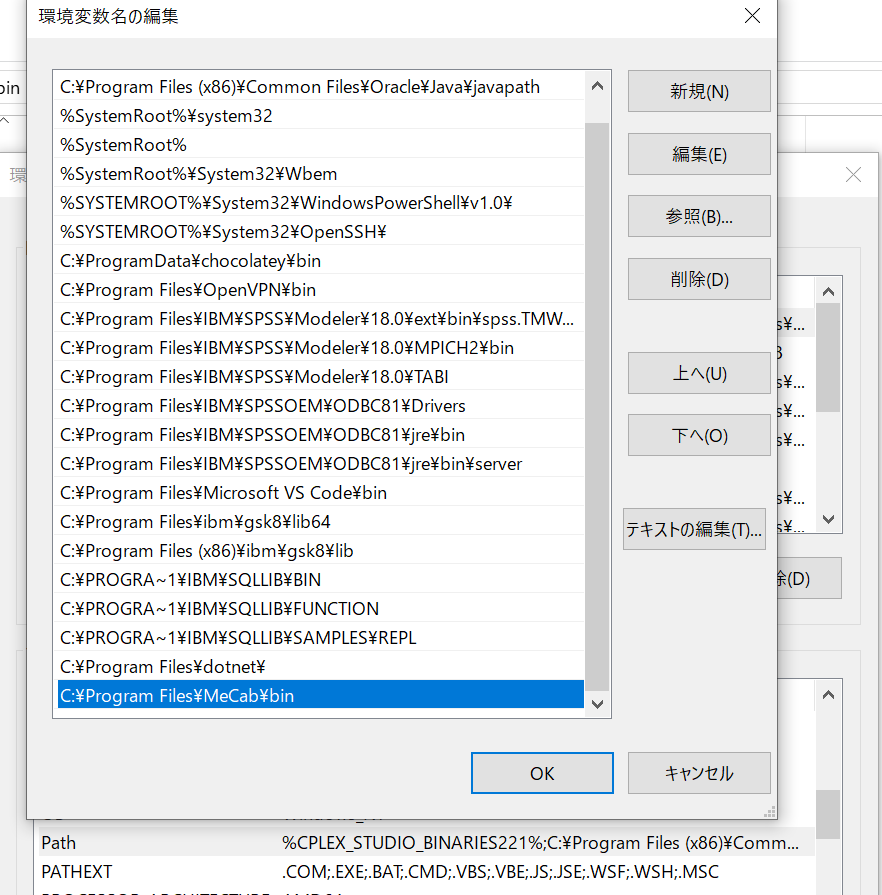
インストールが完了したら、システム環境変数「Path」にMeCabの実行パスを設定します。
例では、「C:\Program Files\MeCab\bin」を指定しています。
続いて、Python環境にMeCab用のライブラリを導入します。
C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts>python -m pip install mecab-python3
⑤. mecab用ライブラリ
その他、必要となるライブラリを導入します。
※. もしかすると必要ないかもしれませんが、念のため追記しました。
protobuf、fugashi、ipadicを導入します。
C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts>python -m pip install protobuf fugashi ipadic
⑤. Pandas
Pandasも使うため、導入をします。※.デフォルトで導入されているかもしれません。
C:\Program Files\IBM\SPSS\Modeler\18.5\python_venv\Scripts>python -m pip install pandas
3. 動作確認
準備ができたら、SPSS Modelerで動作確認をしてみましょう。
以下のような簡単なストリームで拡張の出力ノードを使います。
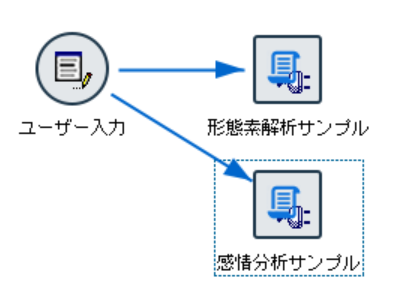
ユーザー入力ノードでは、適当な値を入れているだけです。

①.形態素解析
形態素解析からいきましょう。
拡張の出力ノードでは、シンタックスタブでPythonを選択します。
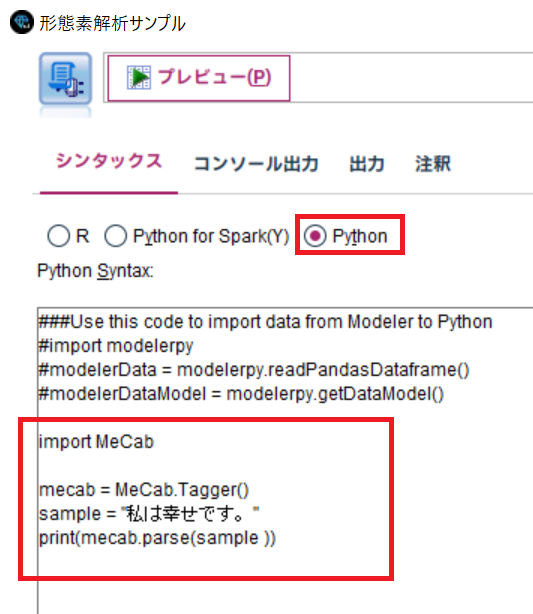
そして、以下のコードを貼り付けして、実行してください。
###Use this code to import data from Modeler to Python
#import modelerpy
#modelerData = modelerpy.readPandasDataframe()
#modelerDataModel = modelerpy.getDataModel()
import MeCab
mecab = MeCab.Tagger()
sample = "私は幸せです。"
print(mecab.parse(sample ))
実行結果は文字化けしますが、気にしないでください。
Python環境は、文字コードが"UTF-8"なんですが、Modelerの出力画面が"Shift-JIS"なので、文字化けしているようです。
標準出力の文字コードを変更しようとしても"IbmSpssModelerOutputCatcher"というライブラリを使っているらしく、エンコードが行えませんでした。解決策が見つかったら更新します。
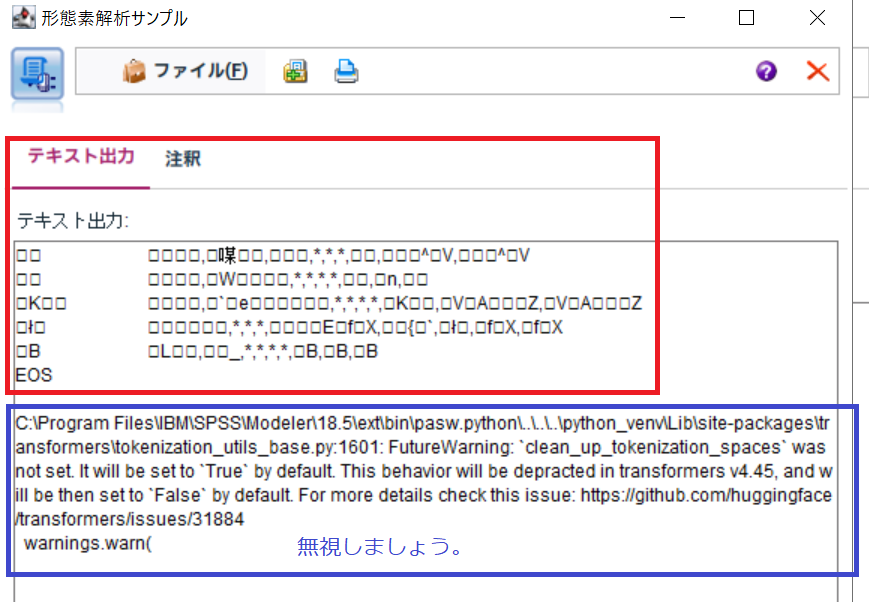
また、今までのエラーや標準出力などが一緒に表示される場合がありますが、気にせず無視しましょう。これも解決策が見つかったら更新します。
②.感情分析
つづいて、感情分析のサンプルを実行してみましょう。
形態素解析と同じように、拡張の出力ノードに以下のコードを貼り付けてください。
もちろん、シンタックスは"Python"を選択していください。
###Use this code to import data from Modeler to Python
#import modelerpy
#modelerData = modelerpy.readPandasDataframe()
#modelerDataModel = modelerpy.getDataModel()
#-------------------------------------------------------
# ライブラリインポート
#-------------------------------------------------------
# Modeler用ライブラリ
import modelerpy
# モデル構築用 Piplineタスク
from transformers import pipeline
# モデルロード用
from transformers import AutoModelForSequenceClassification
# Bert Tokenizer
from transformers import BertJapaneseTokenizer
#-------------------------------------------------------
# 感情分析モデル前処理
#-------------------------------------------------------
# daigo/bert-base-japanese-sentiment は非公開になっている
# koheiduck/bert-japanese-finetuned-sentimentを使います
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
# 東北大学の乾研究室が作成したtokenizerを使いますす
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 感情分析のPipline定義
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
sample = "私は、幸せです。"
result = nlp(sample)
# 結果を出力
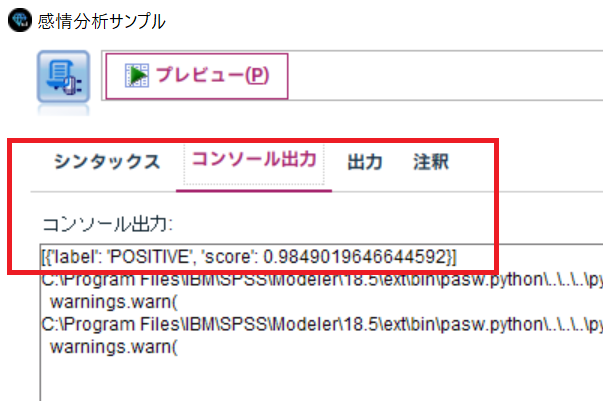
print(result)
"私は、幸せです。"の感情分析の結果は、"POSITIVE"となりました。
下の方にでているメッセージは無視してください。
以上で動作確認は終わりです。
4. 動作させるまでに発生したあれこれ その1
さて、ここまでの簡単な内容でも初めて触ると結構苦労しました。
いろいろ動作させるまでに苦労した点の第1弾を以下に参考までに記載します。
①. アクセス権の問題
準備の項でも説明していますが、アクセス権はきちんと設定しましょう。最初は結構エラーになることが多いと思います。
②. iFixの適用問題
2024年9月現在、SPSS Modeler v18.5にはIF022までiFixが公開されています。
(すべてのiFixが公開されてはいません。)
ここで、著者は最新のiFixまですべて適用して動作確認していたのですが、拡張ノードのPythonが全く動かない状態でした。過去にv18.5で作成したコードも動かなくなっていて、????と当初理由がわかりませんでした。
再インストールからiFixの適用を順番にやっていき、動作確認していく上でiFix07を適用するとPythonが動かなくると分かりました。(uiclient.jarがあやしいと思っています。)
環境に依存するかもしれませんので、参考までに書いておきます。著者は、IF001とIF006のみ適用した状態です。
③. Numpyの問題
2024年9月現在、Numpyは2.10がリリースされています。
著者の環境で2.X系のNumpyを使うと以下のようなエラーが発生して動きませんでした。
調べると、v2.0系で多く発生していそうだったので、v1.26.4にしたところ問題なく動きました。
ValueError: numpy.dtype size changed, may indicate binary incompatibility.
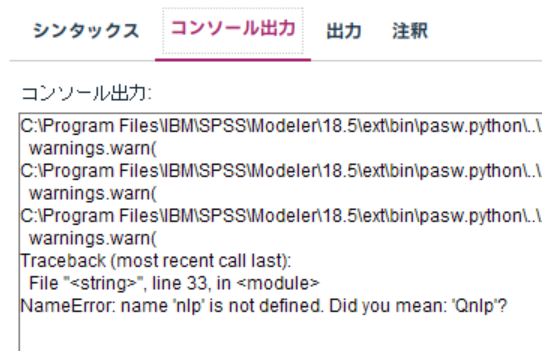
④. エラーはコンソール出力タブでみましょう
拡張ノードでエラーになると、下記画像のようなエラーメッセージがでます。
ここのメッセージからは、エラーの内容はわかりません。
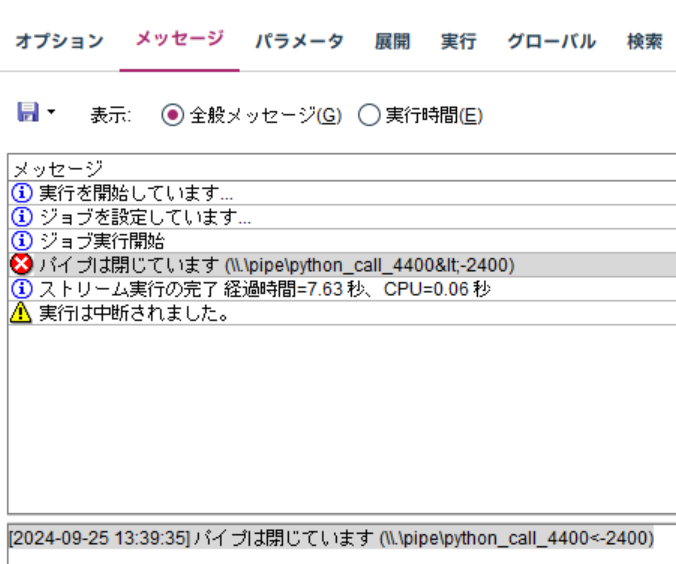
かならず、各ノードのコンソール出力タブを確認しましょう。
次回
次回は、サンプルデータを使った感情分析を紹介します。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログ