GUIでもPLSを実装したい!
みなさん、こんにちは。前回までは 拡張ノード + Python で PLSモデルを実装してみました。
今回は、ファミリー製品である SPSS Statistics と連携して PLSモデルを実装したいと思います。
こちらは、Pythonなどの知識がなくてもGUIでPLSが実装できます。
但し、SPSS Statisticsのライセンスが必要になります。以下のサポートページに記載がありますが、Statistics Base EditionのライセンスがあればOKです。
Modeler と Statisticsの対応一覧は以下の通りです。
Modelerのバージョンに合わせて連携するStatisticsのバージョンを合わせる必要があります。
| Modeler version | Statistics version |
|---|---|
| 18.2.2 | 27.0.0 |
| 18.3 | 28.0.0 and future fix packs |
| 18.4 | 28.0.1 |
| 18.5 | 29.0.1 and future fix packs |
| 18.6 | 30.0.0 and future fix packs |
本記事で使用したストリームと出力結果をアップロードしています。ご自由にダウンロードしてください。
データは以下のページから、"gasoline.csv"をダウンロードして使用してください。
0.2025/04/01時点の注意点
現時点では、SPSS Modeler v18.6 + SPSS Statistics v30.0の組み合わせでは、GUIを使った連携ができない状況です。
※.不具合とのことですが、シンタックスを記載すれば連携が可能な状況です。
そのため、本記事においては、SPSS Modeler v18.5 + SPSS Statistics v29.0.1 で実施しています。
1.Statisticsの導入
以下のサイトを参考に、インストールを及びライセンス認証を実施してください。
2.ModelerとStatisticsを連携させる
次にModelerとStatisticsを連携させます。
①.連携パスの設定
SPSS Modelerのメニューバーから[ツール]>[オプション]>[ヘルパーアプリケーション]を選択します。
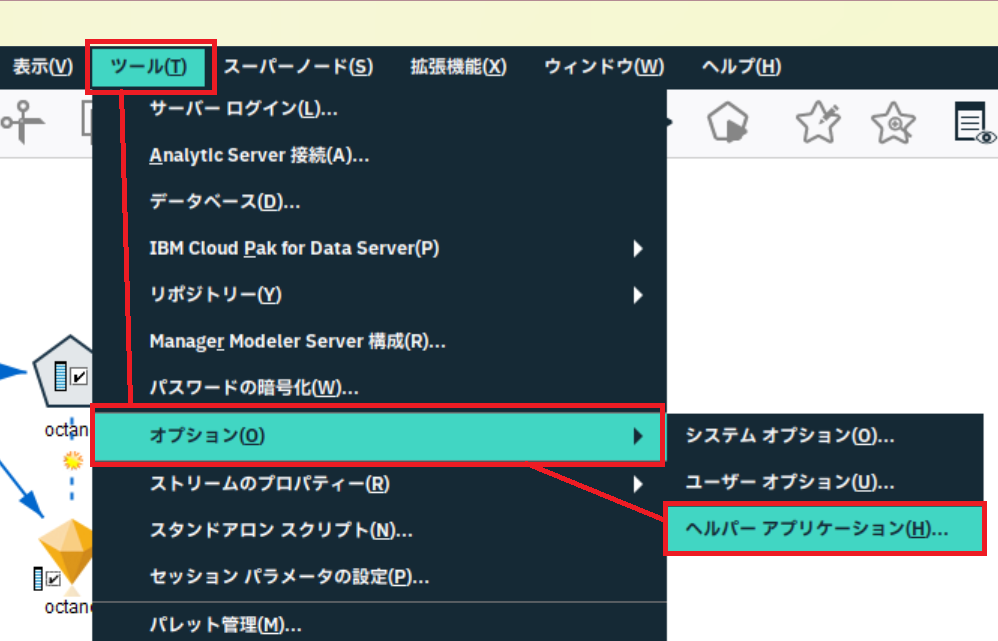
つづいて、ヘルパーアプリケーションの画面で[IBM SPSS Statistics ロケーションユーティリティー]を選択します。
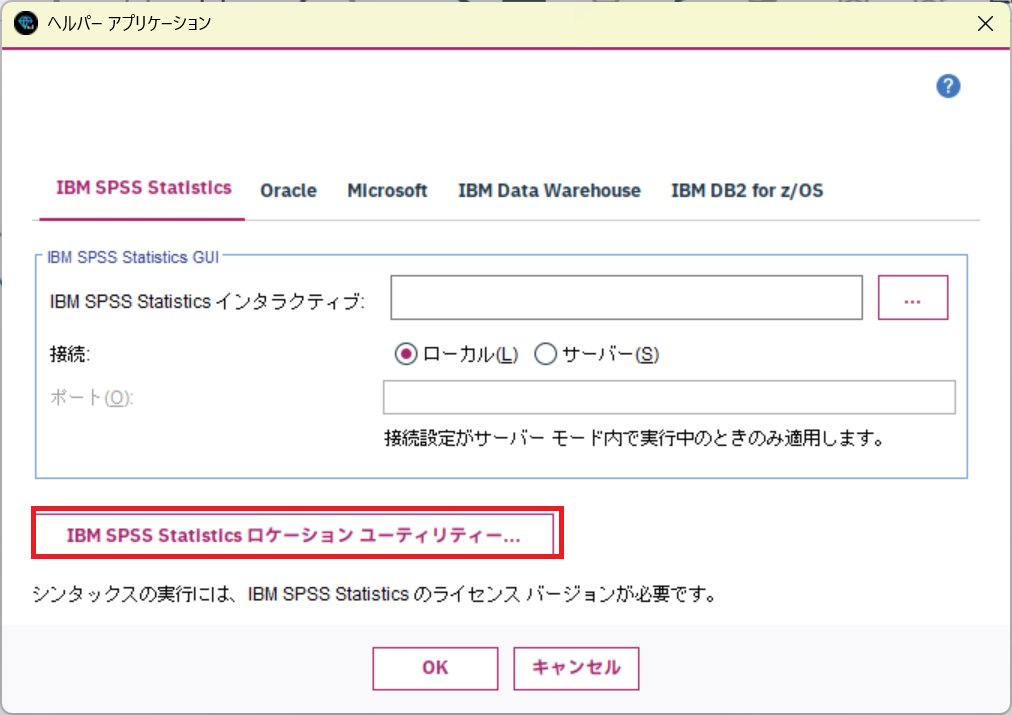
Statisticsユーティリティーの画面で[Statisticsの検索]もしくは、[参照]から対応するStatisticsバージョンのインストールパスを指定します。
※.v28.0などからは、デフォルトでは[ C:\Program Files\IBM\SPSS Statistics ]となります。
②.連携の確認
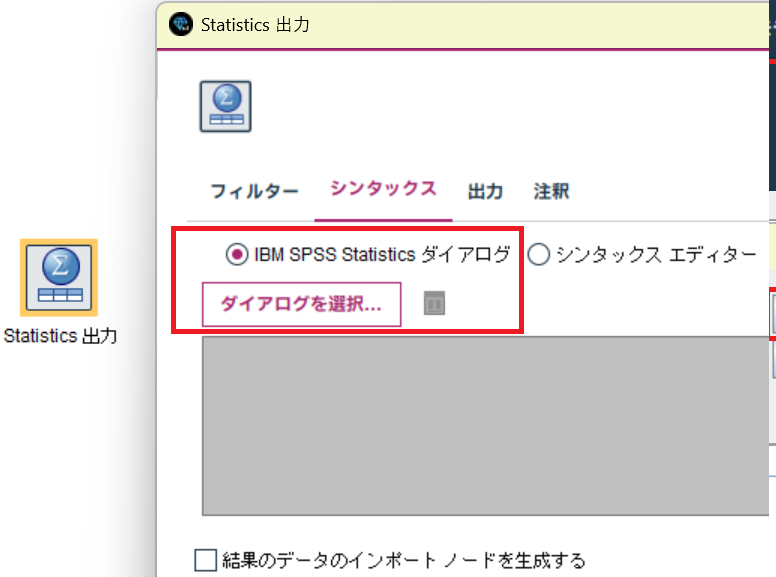
IBM SPSS Statisticsパレットより、Statistics出力をストリームキャンバスに配置します。

配置したStatistics出力ノードの編集画面で、[IBM SPSS Statisticsダイアログ]が選択できるようになっていることを確認してください。
ライセンスが未登録であったり、連携がうまくいっていない場合はアクティブになりません。
3. StatisticsでPLSを使えるようにする。
連携がうまくいったら、次はStatisticsでPLSを使えるようにしましょう。
PLSは標準では使えず、[拡張ハブ]から[Python 拡張モジュール]をインストールする必要があります。
※. インターネットへの接続が必要です。
①. Statisticsへの拡張モジュールインストール
SPSS Statisticsを起動して、メニューバーから[拡張機能]>[拡張ハブ]を選択します。
※. インターネットへの接続が必要です。
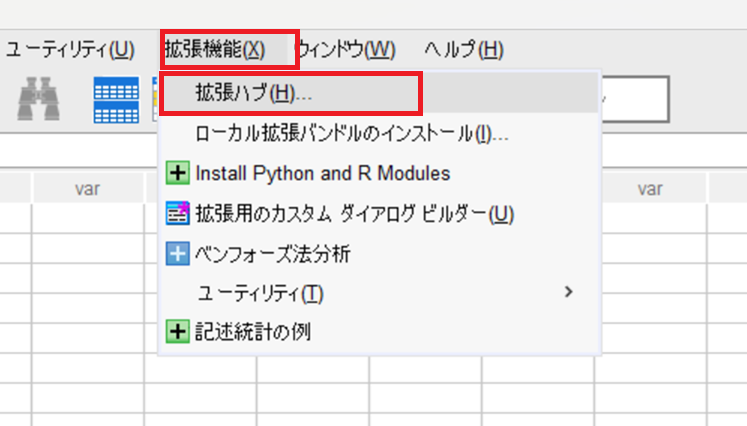
拡張機能の一覧から、[PLS]の[拡張の取得]に チェック を入れて、画面下部の[OK]をクリックします。
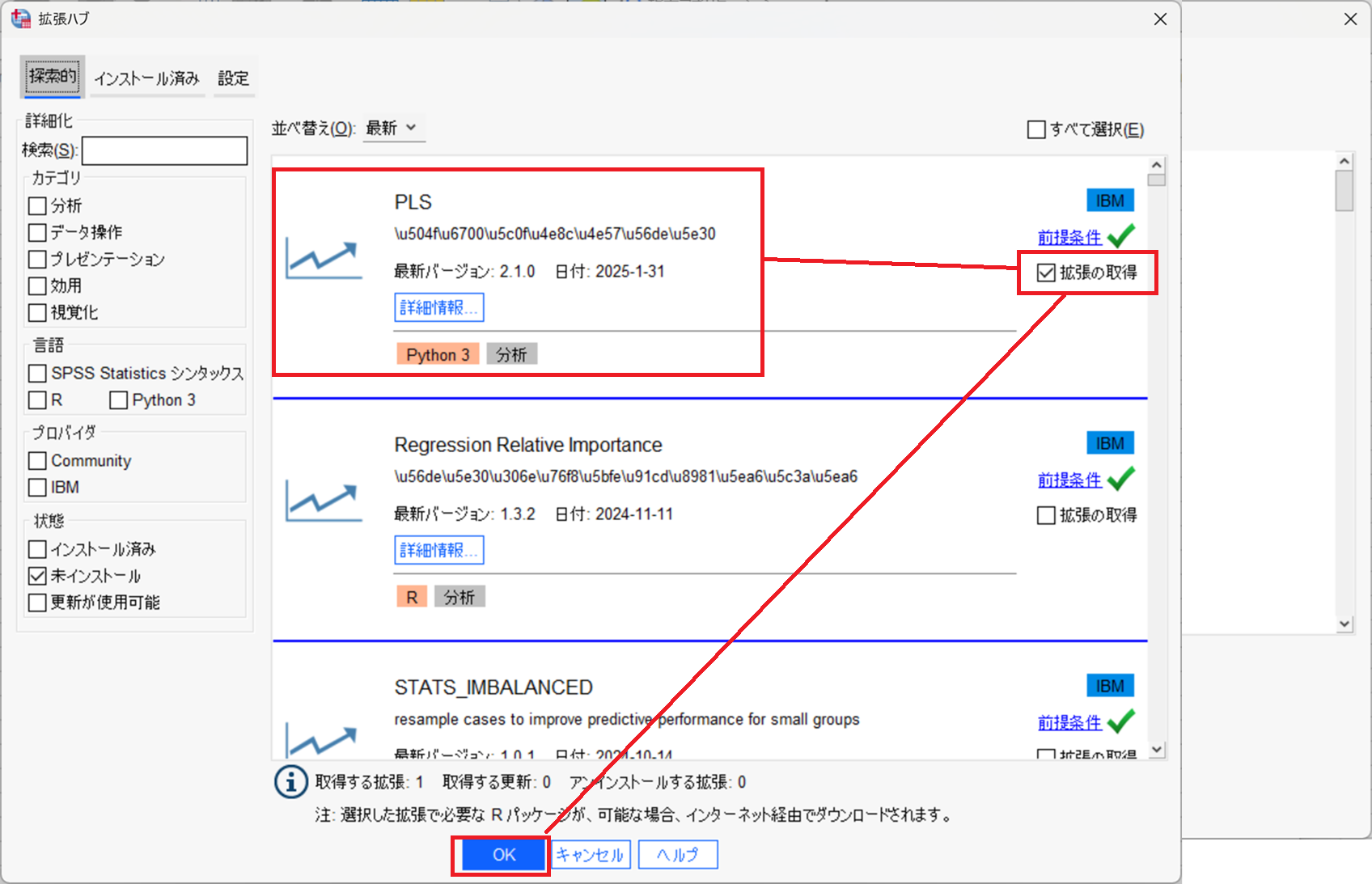
ライセンス規約に同意して、完了をクリックします。
ダウンロードとインストールが開始されます。
最終的に、ログが出力されます。正常にインストールされていることを確認しましょう。
4. ModelerからStatisticsのPLSを実行する。
さて、準備が終わったのでいよいよStatisticsのPLSを実行してみます。
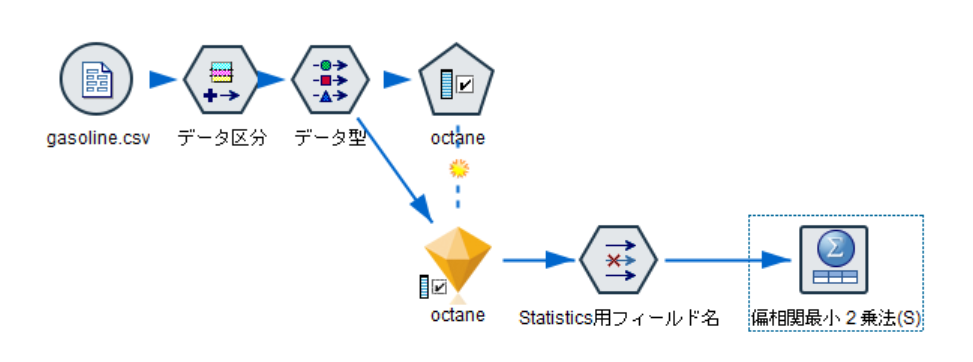
①. ストリーム全体
以下がストリーム全体です。
特徴量選択までは、前回までの記事と同じ処理なので説明は省略します。
特徴量選択までは、前回の記事を参考にしてください。
②. Statisticsへデータを連携するためにフィールド名を変更
Statisticsでは、フィールド名に命名規則が存在します。
以下はIBMサポートページ。
そのため、Modelerで入力したフィールド名のままではStatisticsへデータを連携できない場合があります。
そこで、フィールド名を変更します。
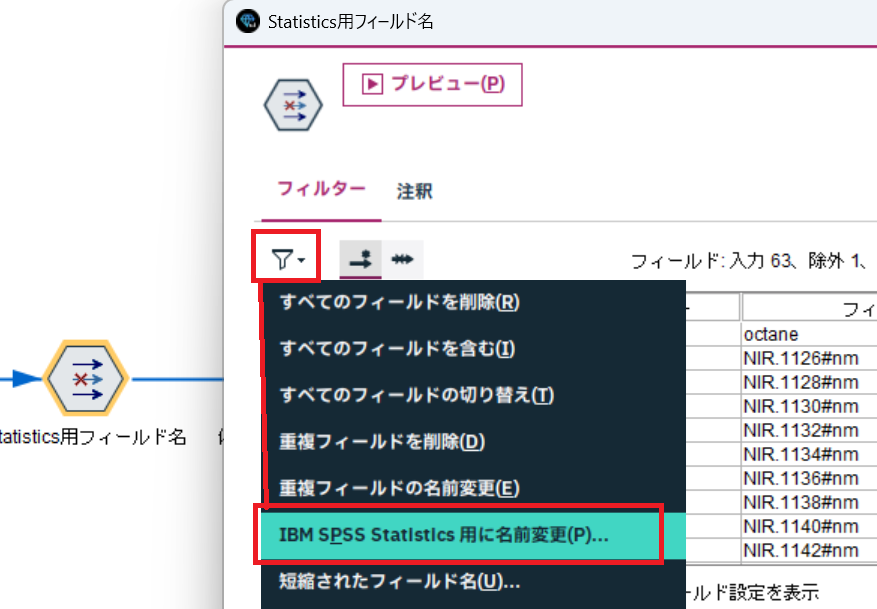
フィルターノードを特徴量選択のモデルナゲットからリンクして、 をクリックして、[ IBM SPSS Statistics用に名前変更 ]を選択します。
をクリックして、[ IBM SPSS Statistics用に名前変更 ]を選択します。
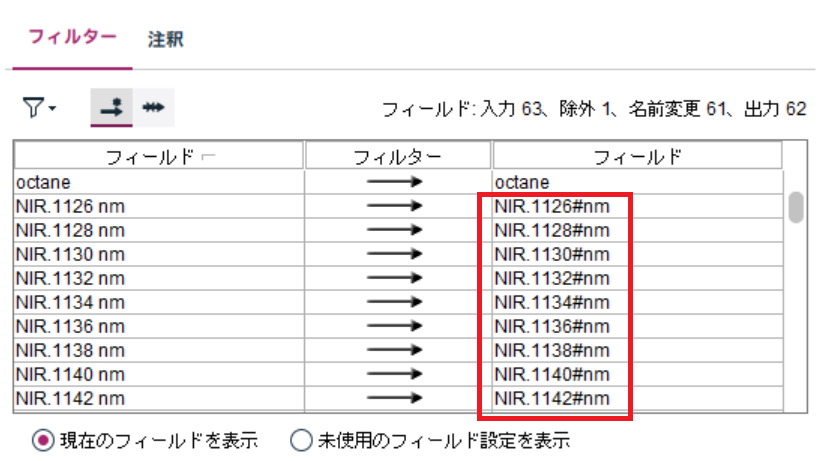
ここではデフォルトのままOKをクリックします。
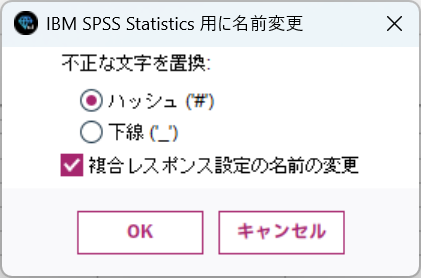
そうすると、スペースなどStatisticsの命名規則に合わない文字は置換されます。ここでは、"#"に置換されていますね。
IBMのサポートページ
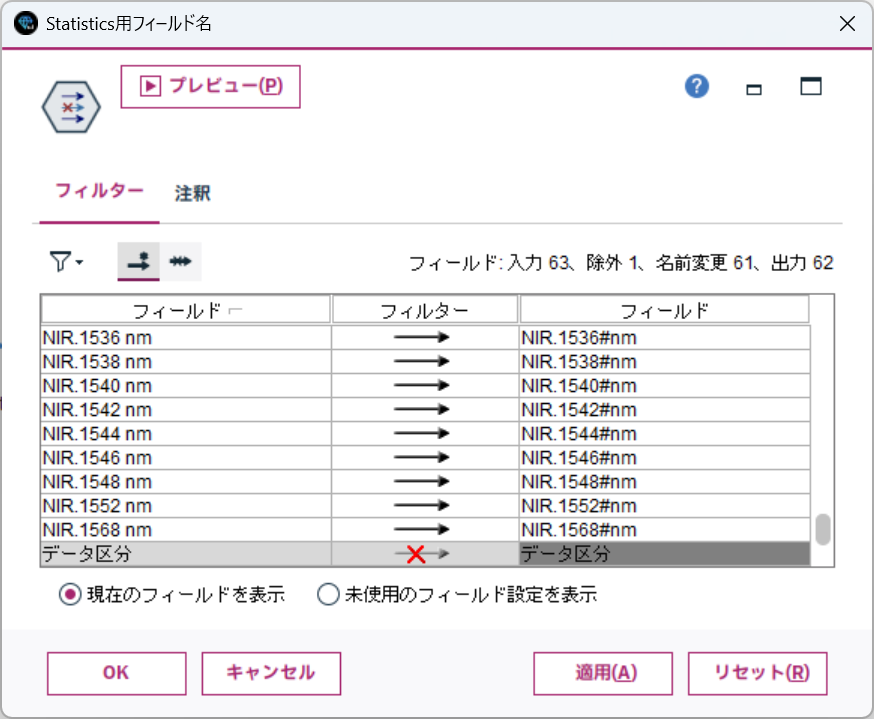
また、データ区分ノードは除外します。
③. Statistics出力ノードでPLSを実行する
今回は、Statistics出力ノードを使用します。Statisticsモデルノードでは簡単には実装できそうもなかったです。とほほ。
Statistics出力ノードをフィルターノードからリンクして編集画面を開きます。

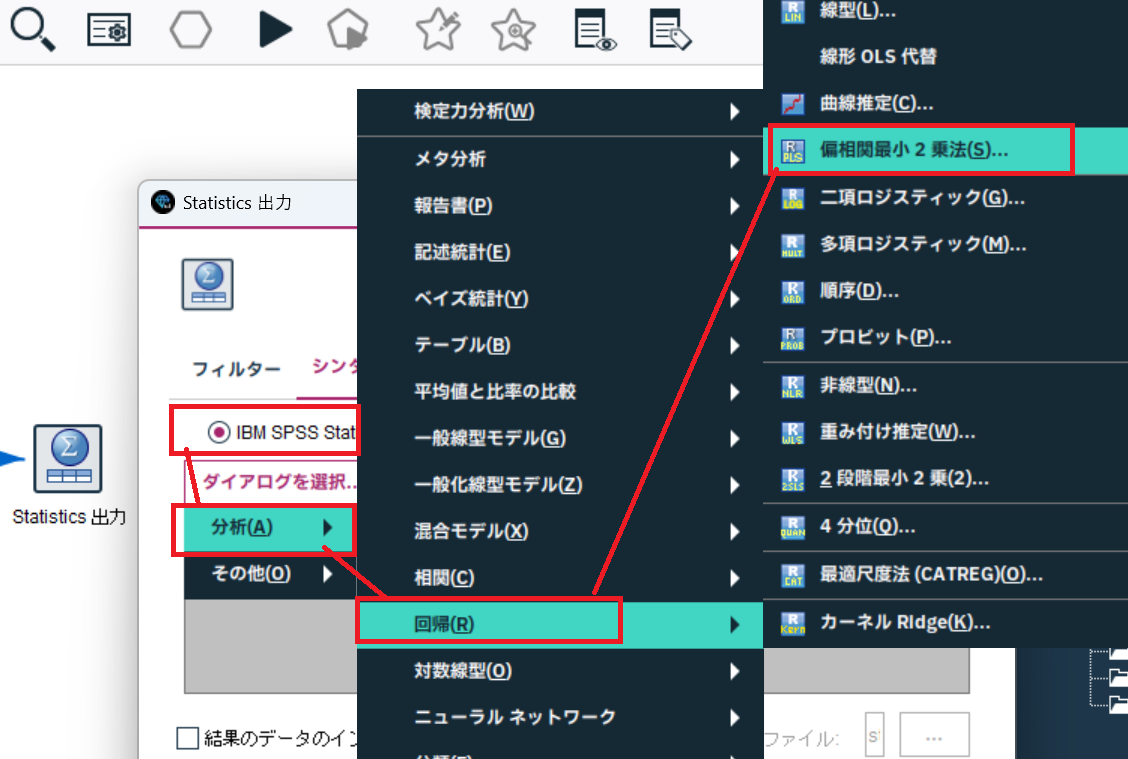
Statistics出力ノードのメニューから[IBM SPSS Statisticsダイアログ]>[分析]>[回帰]>[偏相関最小2乗法]を選択します。
※.偏相関最小二乗法 (PLS。潜在的構造投影方法 (projection to latent structure) とも呼ばれます)
という名前も、PLSの本質的な手法を示しており、PLS(Partial Least Squares)「部分的最小二乗回帰」と同じ意味で使われるみたいです。
ダイアログ画面が開きます。
従属変数に "ocatane"、独立変数に スペクトル変数を全て(61変数) を選択します。
そして、潜在因子の最大数に "6" をセットしてOKをクリックします。
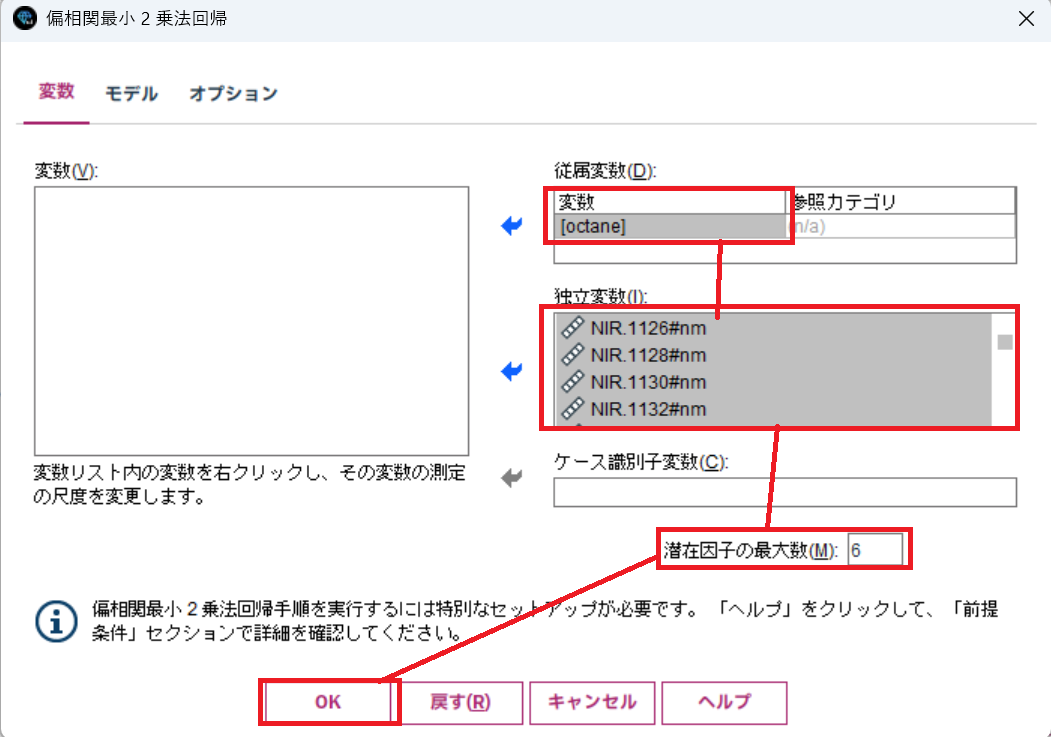
最後に実行ボタンをクリックします。
④. PLSの結果を確認する
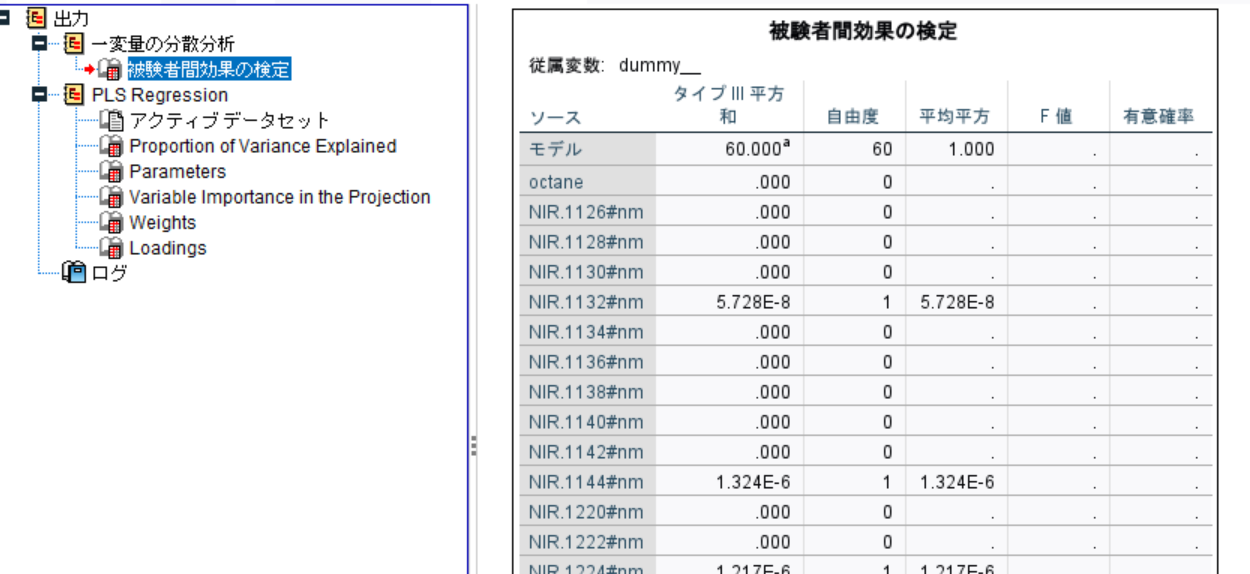
a. 被験者間効果の検定(Test of Between-Subjects Effects)
説明変数(独立変数)の影響度が出力されています。
F値と有意確率が算出されていないため、別途確認は必要かも。
b. 分散の説明割合(Proportion of Variance Explained)
この指標は、PLSモデルでどれだけの分散が説明できているかを示します。
通常、**X(説明変数)とY(目的変数)**の分散の割合が示されます。
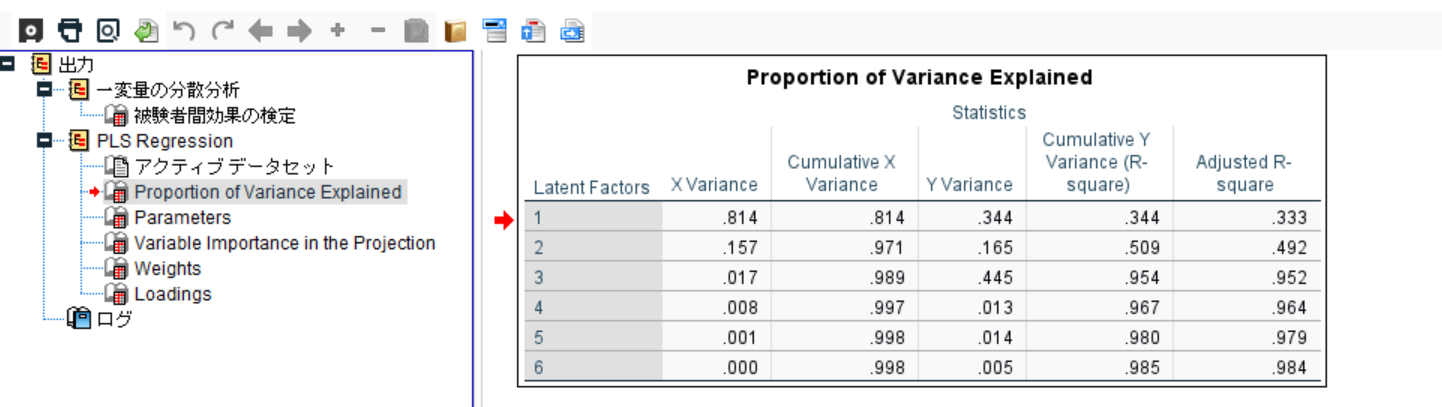
X Variance(説明変数の分散割合)
・1つ目の潜在因子で 81.4% のXの分散を説明
・2つ目で追加 15.7% を説明し、累積で 97.1%
・3つ目までで 98.9% を説明しているため、これ以上の因子を追加する必要性は低い可能性あり
Y Variance(目的変数の分散割合)
・1つ目の潜在因子で 34.4% 説明
・2つ目で追加 16.5% を説明し、累積で 50.9%
・3つ目までで 95.4% 説明
R²とAdjusted R²(決定係数)
・R² = 0.985(98.5%の説明力)であり、モデルの適合度は非常に高い
・Adjusted R² も 0.984 で大きな乖離なし → 過学習の可能性は低い
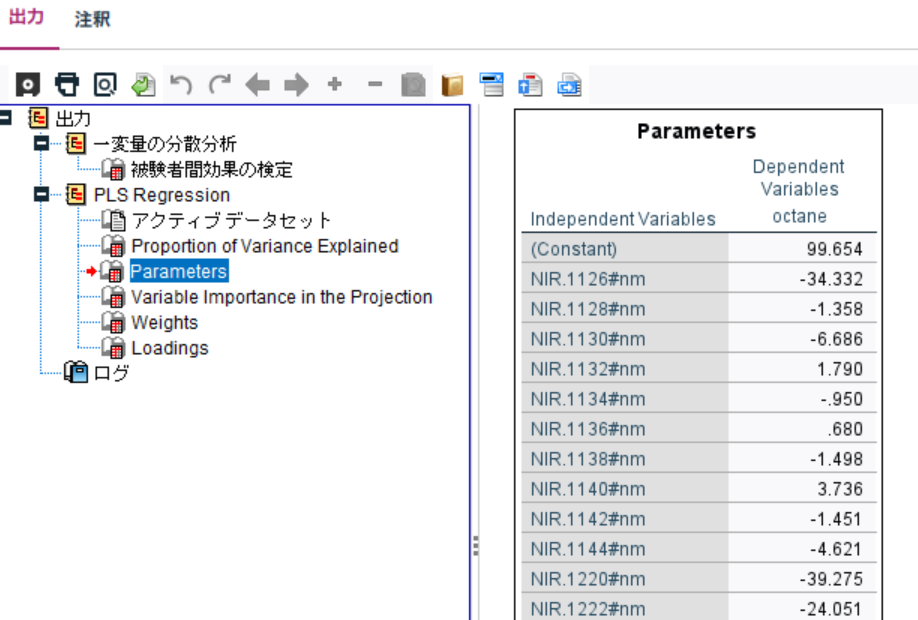
c. 変数ごとの回帰係数(Parameters)
各説明変数の影響を示す係数が得られます。
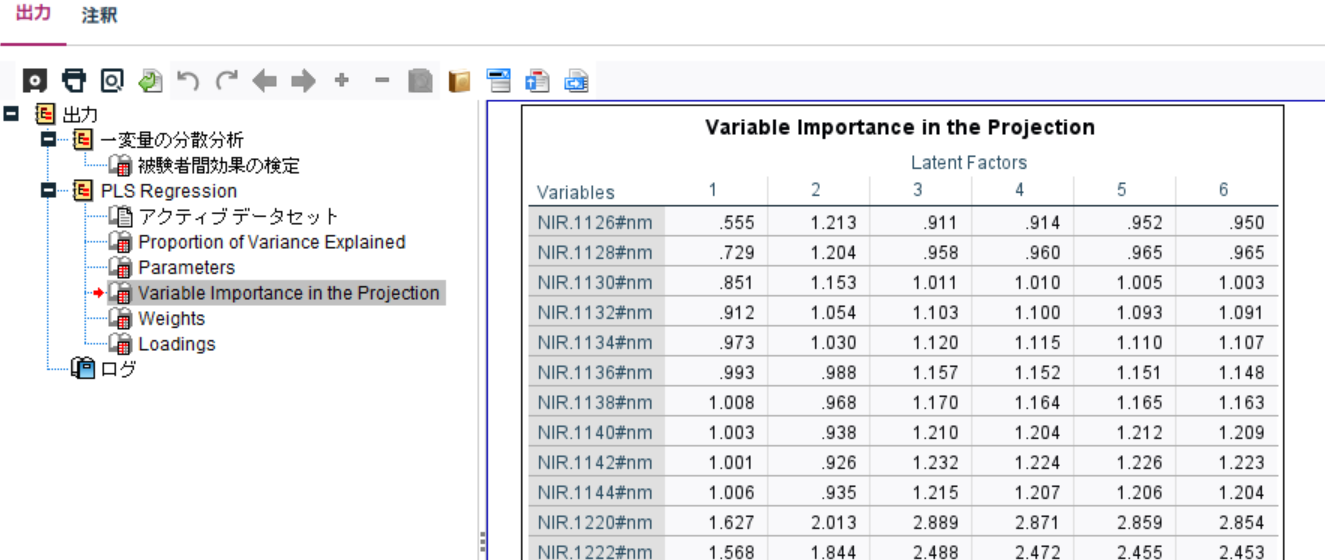
d. 変数ごとの影響度(Variable Importance in the Projection)
一般的に、VIP値が 1.0 より大きい場合、その変数は重要と見なされ、1.0未満 であれば、影響が小さいと考えられます。
各変数と潜在変数の関係を解釈することができそうです。
e. 変数ごとの重み(Weights)
Weightsは、各説明変数(NIR波長)が各潜在因子(Latent Variable)にどの程度寄与しているかを示します。
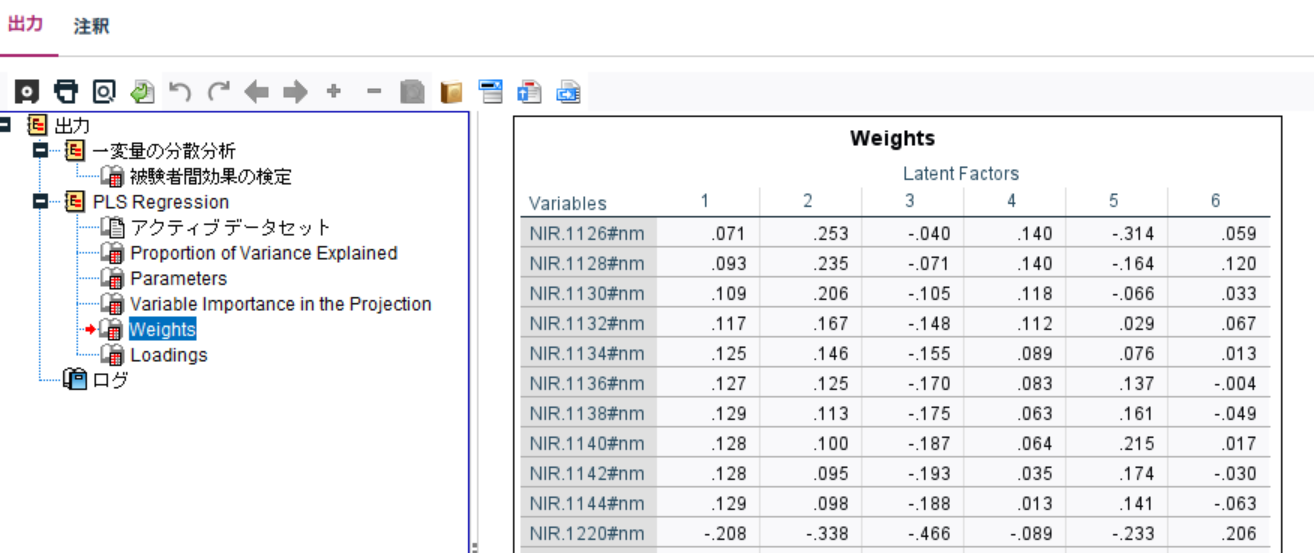
NIR.1126#nmとNIR.1128#nm
・どの因子でも正の重みが高く、PLSモデルで重要な変数
・特に**第3因子以降(>1.0)**の影響が強い
・目的変数(octane)の変動と強く関連している可能性がある
NIR.1568#nm
・第1, 3因子では影響が小さいが、第4, 5, 6因子では負の影響が強い
・目的変数とは反対の影響を与える可能性がある
octane(目的変数)
・第3, 5, 6因子で比較的高い値を持つ(0.654, 0.537, 0.516)
・第3因子が最もoctaneを説明する役割を持っている
f. 変数ごとの負荷量(Loadings)
Loadings(負荷量) は、各変数が潜在因子(Latent Factors)にどれだけ関連しているか、またはどれだけ寄与しているかを示す指標です。負荷量(Loadings)は、観測された変数が潜在因子にどれだけ貢献するかを表し、PLSモデルにおいてその因子の解釈の参考になります。
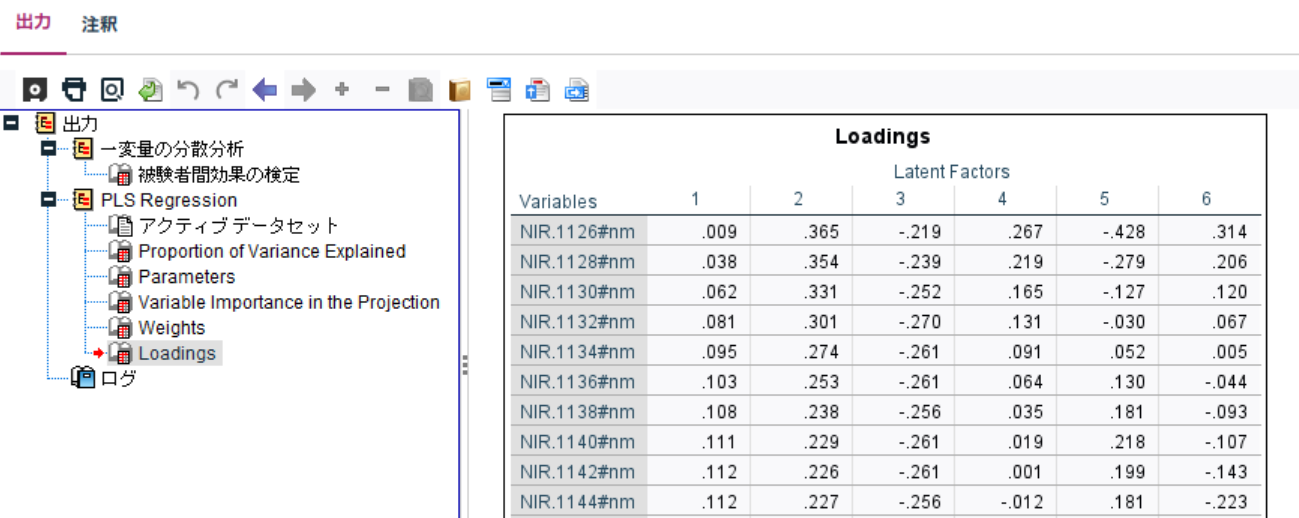
NIR.1126#nm と NIR.1128#nm は、特に 潜在因子2 に強く関連しており、これらの波長が octane の予測に大きく寄与していると解釈できます。
NIR.1568#nm は、負の影響を持つ波長であり、特に 潜在因子1 と 潜在因子4 で逆の影響を与えていることが分かります。この波長が octane の予測においては少し逆方向の役割を果たしている可能性があります。
octane の負荷量がすべて 1.000 となっていることは、PLSモデルにおいて目的変数 octane が全ての潜在因子(1~6)に同じ重みで貢献していることを意味します。つまり、PLSアルゴリズムは octane を予測するために全ての潜在因子を均等に活用しているということです。
5. まとめ
はい、ModelerからStatisticsの機能を呼び出すことでPLSを実装してみました。
ただ、モデルを作って予測値を算出するやり方が残念ながら現時点では分かりませんでした。
シンタックスで実装できるか?と試行錯誤したのですが、コマンドで予測結果を出力できないんですよね。
とほほ。。
※. SPSS Modeler v18.6 + SPSS Statistics v30.0で実装してみたい方は、GitHubにあるストリームをダウンロードいただき、シンタックスをコピーして活用してみてください。
Statisticsモデルノードでは、以下のモデルが対応しています。これらについては、Modelerのモデル作成ノードと同じような使い方が可能です。ここにPLSも対応を期待したいですね。
SPSS Statistics関連のノードについては、西牧さんの記事にたくさんあります。ぜひ参考にしてください。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログ
今後は、ヒモトクブログなどは以下のTechXchangeのコミュニティに統合される予定です。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan