はじめに
現在進行中のプロジェクトにおいて、WebFluxを導入いたしました。
私はこれまでJPAを用いてORMを利用しておりましたが、WebFlux導入に伴い、R2DBCへ移行いたしました。
今回の移行に際し、発生した主要な問題点と私が解決した方法についてまとめさせていただきます.
- 翻訳ツールの助けを借りて書いた文章なので、誤りがあるかもしれません
WebFluxとは?
Spring 5.0で導入されたリアクティブウェブフレームワークであり、以下のように説明されています。
紹介文が詳しく、とても参考になりました。
私自身は、WebFluxの主な利点は大きく2つあると考えております.
完全なノンブロッキング方式のサポート
It is fully non-blocking, supports Reactive Streams back pressure, and runs on such servers as Netty, Undertow, and Servlet containers.
完全なノンブロッキング方式をサポートいたします。
従来のSpring MVCの方式と比較して見てまいりましょう。
Spring MVCの場合
Spring MVCはThreadPoolを使用しております。
Tomcatの場合、デフォルトで最大200個まで生成されるためです。
@GetMapping
public List<Post> getAllPosts(){
return postService.getAllPosts();
}
次のようにポストを取得するAPIがあるとします。
- GETリクエストがgetAllPosts()に入り(ThreadPoolからスレッドが割り当てられる)
- postServiceがfindAll()でクエリをDBに要求する
- その間、割り当てられたスレッドは待機状態になり(クエリが返されるまで何もできない)
- DBからクエリ結果が返される
- スレッドが結果をユーザーに応答する
- スレッドがThreadPoolに返却され、他のリクエストを処理できるようになる
上記のような流れで進みます。
その間、割り当てられたスレッドは待機状態になり(クエリが返されるまで何もできない) この状態では、スレッドは何も処理できず待機状態を維持いたします。
クエリが非常に長い時間を要する状況の場合、
もし200個のスレッドがすべてこの状態になってしまうと、新たなリクエストはキューで待機することになるでしょう。
これが従来のブロッキング方式の欠点です。
WebFluxの場合
一方、WebFluxでは以下のような流れとなります。
例えば、次のような場合です。
@GetMapping
public Flux<Post> getAllPosts() {
return postService.getAllPosts(); // 非同期でDBにリクエスト
}
- GETリクエストがgetAllPosts()に入り(イベントループで処理)
- postServiceがfindAll()クエリを非同期でDBにリクエスト
- スレッドはDBの応答を待たずにすぐ次の作業が可能
- DB作業はバックグラウンドで進行
- スレッドは即座に他のリクエストを処理できる状態になる
- 新たなHTTPリクエストが入れば即時に処理可能
- 他のAPIリクエストも処理可能
- DBからデータが準備されると、イベントで通知
- コールバックでデータを処理
- 準備されたデータをFluxを通じてユーザーにストリーミングで返す
ブロッキング方式との最大の違いは、
postServiceがfindAll()クエリを非同期でDBにリクエストし、スレッドが他の作業を行える点にあります。
そして、クエリの応答が到着した際にコールバックでデータを処理してユーザーに返す仕組みです。
そのため、クエリに非常に長い時間がかかる状況でも、DB作業が遅延しても他のリクエストを処理することができ、実質的により多くのリクエストを効率的に処理できるようになります。
これがWebFluxがノンブロッキングをサポートする際の最大の利点であると考えております。
Reactive Streams バックプレッシャーのサポート
WebFluxの利点を非常に簡潔にまとめましたが、追加の記事は次の機会があれば改めて投稿させていただきます。
JPAの代わりにR2DBCを使用すべき理由
WebFluxを導入すると、IntelliJのような高度なIDEが警告を発生させます。
もしJPAを使用している場合、以下のような警告が表示されることでしょう.
postRepository.findAll(); // 기아 문제가 발생할 수 있음
なぜなら、JPAがブロッキング方式で動作するためです。
WebFluxの核心はノンブロッキング(Non-blocking)な演算を提供することにありますが、JPAはこれを阻害いたします。
JPAの問題
JPAは内部的に同期方式でデータベース(DB)と通信しており、これをWebFlux環境で使用すると、以下のような問題が発生します。
1. postServiceがfindAll()クエリを非同期でDBにリクエスト
- スレッドはDBの応答を待たずにすぐ次の作業が可能
- DB作業はバックグラウンドで進行
2. スレッドは即座に他のリクエストを処理できる状態になる
- 新たなHTTPリクエストが入れば即時に処理可能
- 他のAPIリクエストも処理可能
つまり、JPAを使用するとWebFluxの利点である高い処理量と非同期の特性を活かすことができなくなります。
だからR2DBCを使う
public interface PostRepository extends ReactiveCrudRepository<Post, Long> {
Flux<Post> findAll(); // 非同期処理対応
}
R2DBCは完全に非同期なデータベースリクエスト処理を行い、したがってWebFluxと完全に互換性があるといえます。
公式ドキュメントにも次のように説明されています。
In a Nutshell
Based on the Reactive Streams specification. R2DBC is founded on the Reactive Streams specification, which provides a fully-reactive non-blocking API.
- R2DBCはReactive Streams仕様を基盤としており、完全なノンブロッキングAPIを提供いたします
Works with relational databases. In contrast to the blocking nature of JDBC, R2DBC allows you to work with SQL databases using a reactive API.
- 関係型データベースをサポートしており、
- JDBCのブロッキング特性とは対照的に、R2DBCはSQLデータベースで非同期APIを利用可能にいたします
Supports scalable solutions. With Reactive Streams, R2DBC enables you to move from the classic “one thread per connection” model to a more powerful and scalable approach.
- Reactive Streamsを活用し、従来の「スレッドごとに1つの接続」というモデルから、より強力でスケーラブルなアプローチへの移行を可能にいたします
Provides an open specification. R2DBC is an open specification and establishes a Service Provider Interface (SPI) for driver vendors to implement and clients to consume.
- オープンな仕様を提供しており、
R2DBCはオープンな仕様であり、ドライバーベンダーが実装し、クライアントが利用するためのService Provider Interface (SPI)を確立いたします。
適用に際して遭遇した問題点
適用しながら遭遇した問題点を簡潔にこちらにまとめさせていただきます。
flyway
現在のプロジェクトではflywayを通じてマイグレーションを実施しておりました。
しかし、JPAおよびJDBCを削除したところ、flywayが動作しなくなりました。
その理由は、flywayがJDBCを通じて動作するためです。
そこで、再度JDBCを追加することにいたしました。
spring:
datasource:
url: jdbc:mysql://localhost:port/name
username: name
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
flyway:
enabled: true
locations: classpath:db/migration
以下のように自動設定用のymlを設定いたしましたが、動作しませんでした。
そこで、手動で
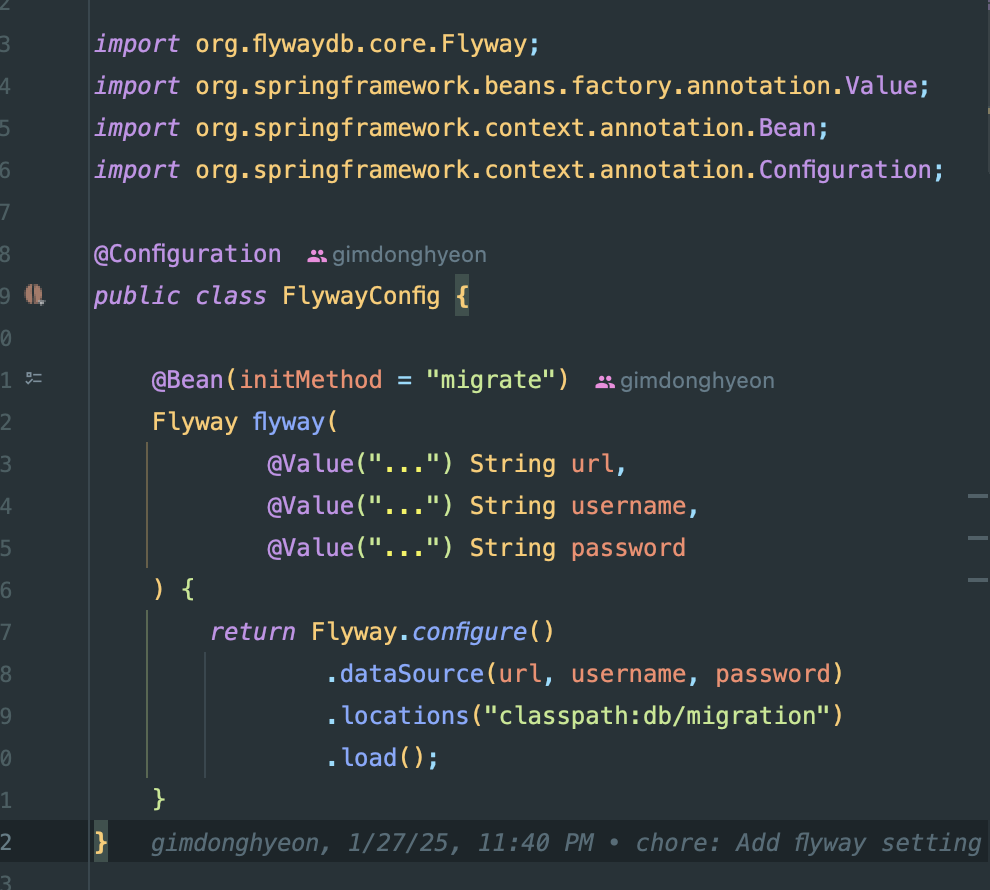
以下のように@Beanを生成してflywayが動作するようにいたしました。
なぜflywayが動作しなかったのか?
正確な原因かは分かりませんが、
- Gradleの依存関係が正しく設定されている点
- ログ上でflyway自体がロードされていなかった点
から、現在のauto configurationがflywayを実行できていないと予測するに至りました.

Spring公式ドキュメントには、次のような内容が記載されております。
HikariCPが性能的に優れているため、これが使用可能であればこれを選択する
あるいは、Tomcat pooling、DBCP2、Oracle UCPの順で使用する
もし手動設定を行う場合は、auto configurationが適用されない
ここで、私は
もし手動設定を行う場合は、auto configurationが適用されない
という文が、R2DBCの設定部分にも該当するのではないかと疑問に思いました。
そこで、設定にSpring Bootのローディングログオプションを付与し、再度ログを確認いたしました.
logging:
level:
org.springframework.boot.autoconfigure: DEBUG
lywayAutoConfiguration:
Did not match:
- AnyNestedCondition 0 matched 3 did not; NestedCondition on FlywayAutoConfiguration.FlywayDataSourceCondition.FlywayUrlCondition @ConditionalOnProperty (spring.flyway.url) did not find property 'url'; NestedCondition on FlywayAutoConfiguration.FlywayDataSourceCondition.JdbcConnectionDetailsCondition @ConditionalOnBean (types: org.springframework.boot.autoconfigure.jdbc.JdbcConnectionDetails; SearchStrategy: all) did not find any beans of type org.springframework.boot.autoconfigure.jdbc.JdbcConnectionDetails; NestedCondition on FlywayAutoConfiguration.FlywayDataSourceCondition.DataSourceBeanCondition @ConditionalOnBean (types: javax.sql.DataSource; SearchStrategy: all) did not find any beans of type javax.sql.DataSource (FlywayAutoConfiguration.FlywayDataSourceCondition)
Matched:
- @ConditionalOnClass found required class 'org.flywaydb.core.Flyway' (OnClassCondition)
- @ConditionalOnProperty (spring.flyway.enabled) matched (OnPropertyCondition)
FlywayAutoConfiguration.FlywayConfiguration:
Did not match:
- Ancestor org.springframework.boot.autoconfigure.flyway.FlywayAutoConfiguration did not match (ConditionEvaluationReport.AncestorsMatchedCondition)
Matched:
- @ConditionalOnClass found required class 'org.springframework.jdbc.support.JdbcUtils' (OnClassCondition)
次のようにログが出力されました。
現在、flywayは読み込まれておりますが、以下の3点の問題が存在します。
- DataSourceが存在しない
- JdbcConnectionDetailsが構成されていない
- DataSource beanが構成されていない
上記のログから、
DataSourceが構成されていない
という状況であることが分かりました。
意外にも、正解は非常にシンプルな箇所にありました。
詳細については、以下のSpring公式ドキュメントの該当箇所をご参照ください。
このSpring公式ドキュメントのR2DBCに関する記述を整理すると、
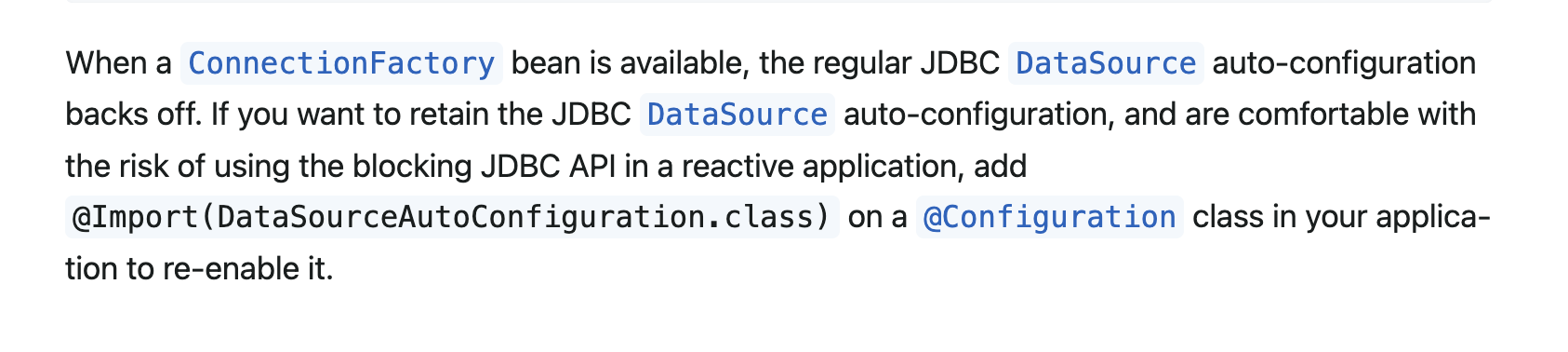
R2DBC ConnectionFactory Beanが存在する場合、Spring BootはJDBCベースのDataSource自動構成を無効化(バックオフ)する
と明確に記載されておりました。
つまり、flywayが自動で動作しなかった理由は、R2DBC ConnectionFactoryが存在しているために、JDBCベースのDataSourceが動作せず、DataSourceとして定義したデータベース接続オプションがflywayに適用されなかったからです!!!
flyway:
enabled: true
locations: classpath:db/migration
url: jdbc:mysql://localhost:port/name
user: user
password: password
以下のようにflyway設定を適用したところ、
正常に動作していることを確認いたしました。
おそらく、flyway-coreはJDBCで動作するとの理解でございます。
この際に必要なJDBC接続は、JDBCドライバ(mysql-connector-j)を通じて行われるようです。
そのため、JDBCの全機能がなくても動作すると考えております.
implementation 'org.flywaydb:flyway-core'
implementation 'org.flywaydb:flyway-mysql'
runtimeOnly 'com.mysql:mysql-connector-j'
上記のような過程を通じて、全体のJDBC依存性を削除し、flywayのローディングに関する問題を解決することができました。
save()呼び出し時にupdateクエリが発行される問題の解決
JWTを使用したstatelessなアクセストークンと、
我々のサーバーが保持するrefreshtokenを利用したアーキテクチャで設計する際、
私は通常Redisを好むのですが、まだ利用者数がどれほどになるか分からないコスト面や、現状ではRDBMSにrefreshtokenを格納することにしました。
しかし、そこで問題が発生しました.
package com.example.demo.auth.domain.model.entity;
import com.example.demo.member.domain.constant.MemberRole;
import lombok.*;
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Column;
import org.springframework.data.relational.core.mapping.Table;
import java.time.LocalDateTime;
@Table("refresh_tokens")
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PUBLIC)
@Getter
public class RefreshToken {
@Id
@Column("token")
private String token;
@Column("member_id")
private Long memberId;
@Column("role")
private MemberRole role;
@Column("expires_at")
private LocalDateTime expiresAt;
}
以下のようにrefreshTokenを格納するテーブルが存在する場合
public Mono<TokenPair> createToken(final AuthenticatedMember authenticatedMember) {
return tx.execute(() ->
refreshTokenRepository.deleteByMemberId(authenticatedMember.id())
.then(Mono.just(authenticatedMember))
.map(tokenProvider::createToken)
.flatMap(tokenPair -> {
RefreshToken refreshToken = tokenProvider.createRefreshTokenEntity(tokenPair, authenticatedMember);
return refreshTokenRepository.save(refreshToken)
.thenReturn(tokenPair);
})
);
}
以下のようなロジックがございます。
JWT形式でアクセストークンとリフレッシュトークンを発行し、
refreshtokenRepository.save(RefreshToken);
リフレッシュトークンはsave()を呼び出して保存するシンプルなロジックです.
しかし、ここで予期せぬ問題が発生いたしました。
R2DBCの予期せぬ問題
このAPIを呼び出すテストコードを実行したところ、
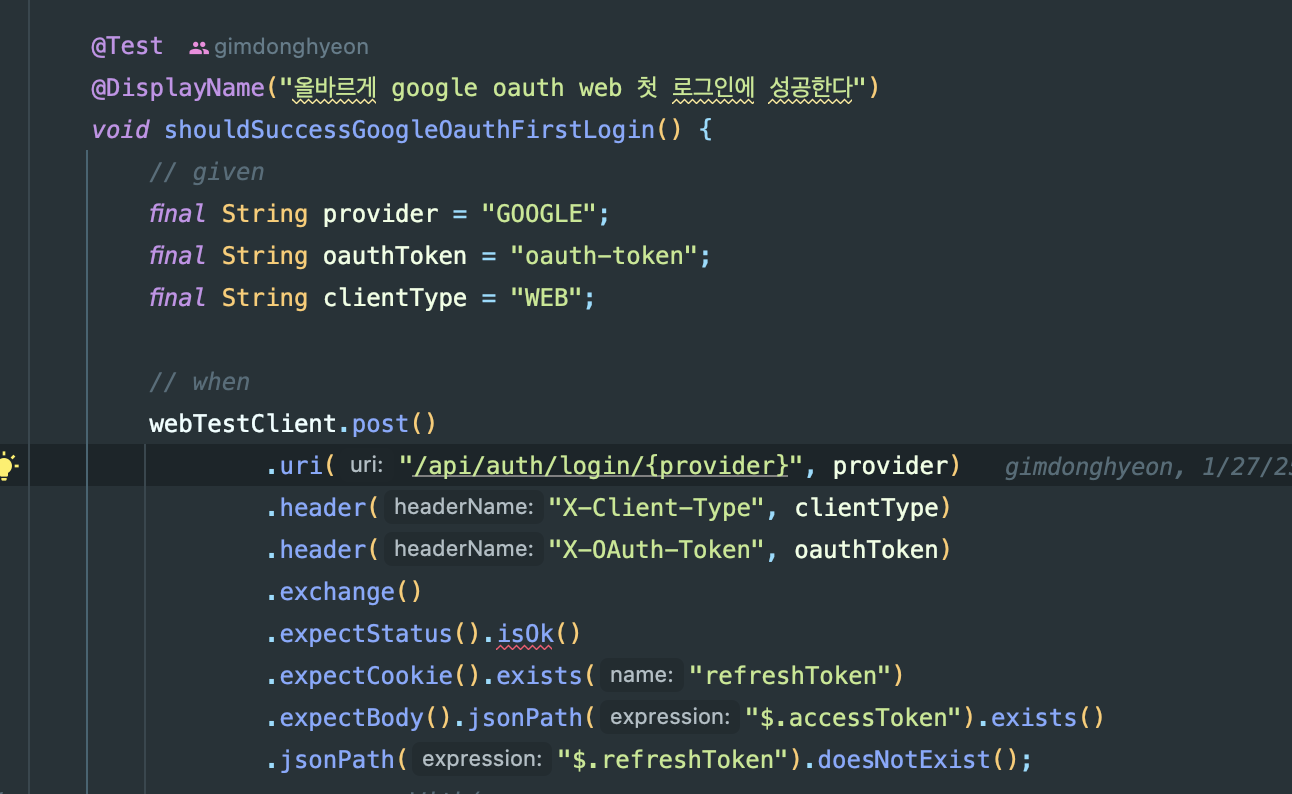
このような動作となった結果、
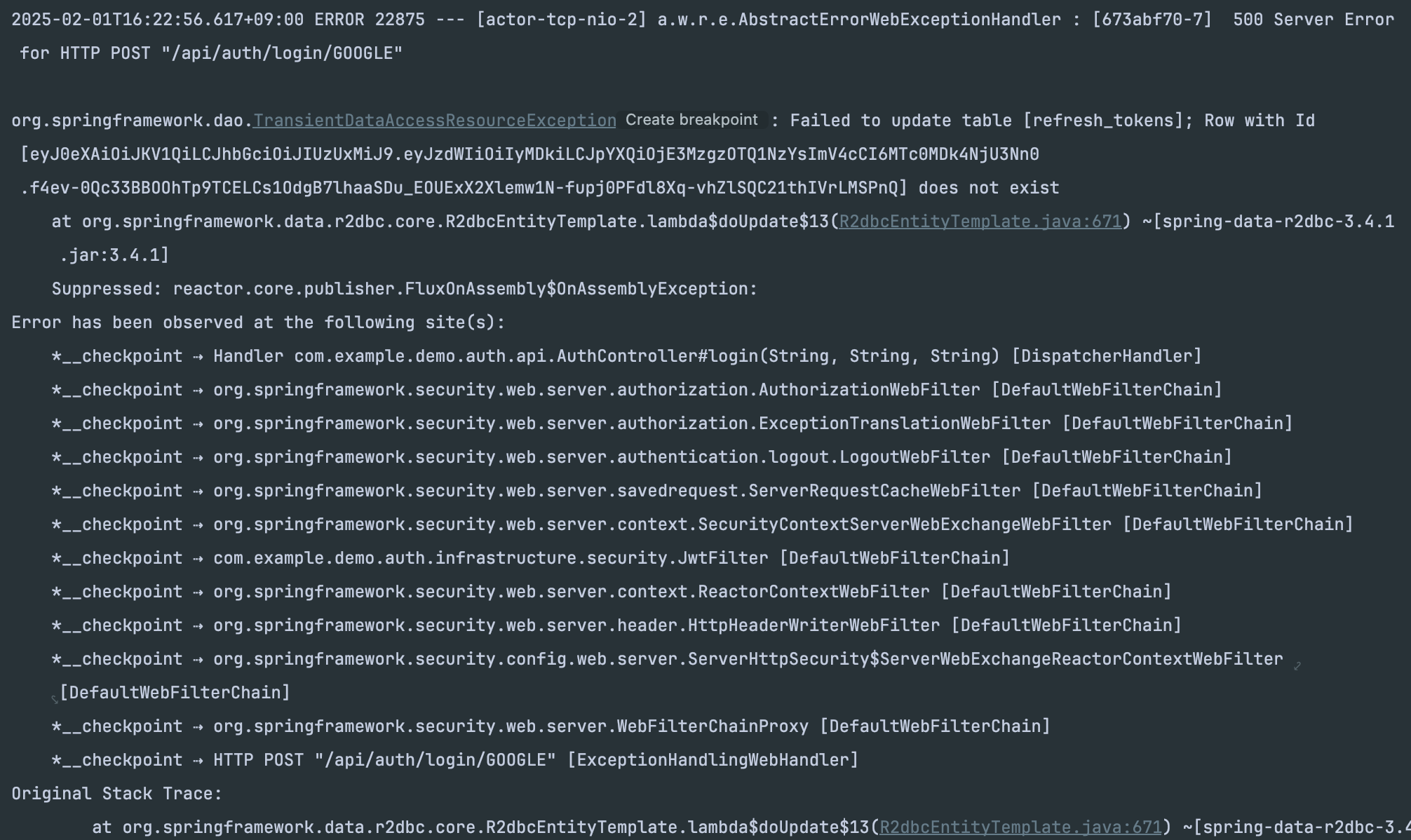
次のようなエラーが発生しておりました。
現在、JPAからR2DBCへ移行する際に、
public interface RefreshTokenRepository extends JpaRepository<RefreshToken, String> {
というJPAを利用したリポジトリ構成から、
public interface RefreshTokenRepository extends ReactiveCrudRepository<RefreshToken, String> {
とReactiveCrudRepositoryに変更いたしましたが、
この違いに起因して、JPAで新規エンティティかどうかを識別する際に使用される isNew(); が正常に動作しなくなっているのではないか、と予測することができました.
Updateクエリが発生していた原因
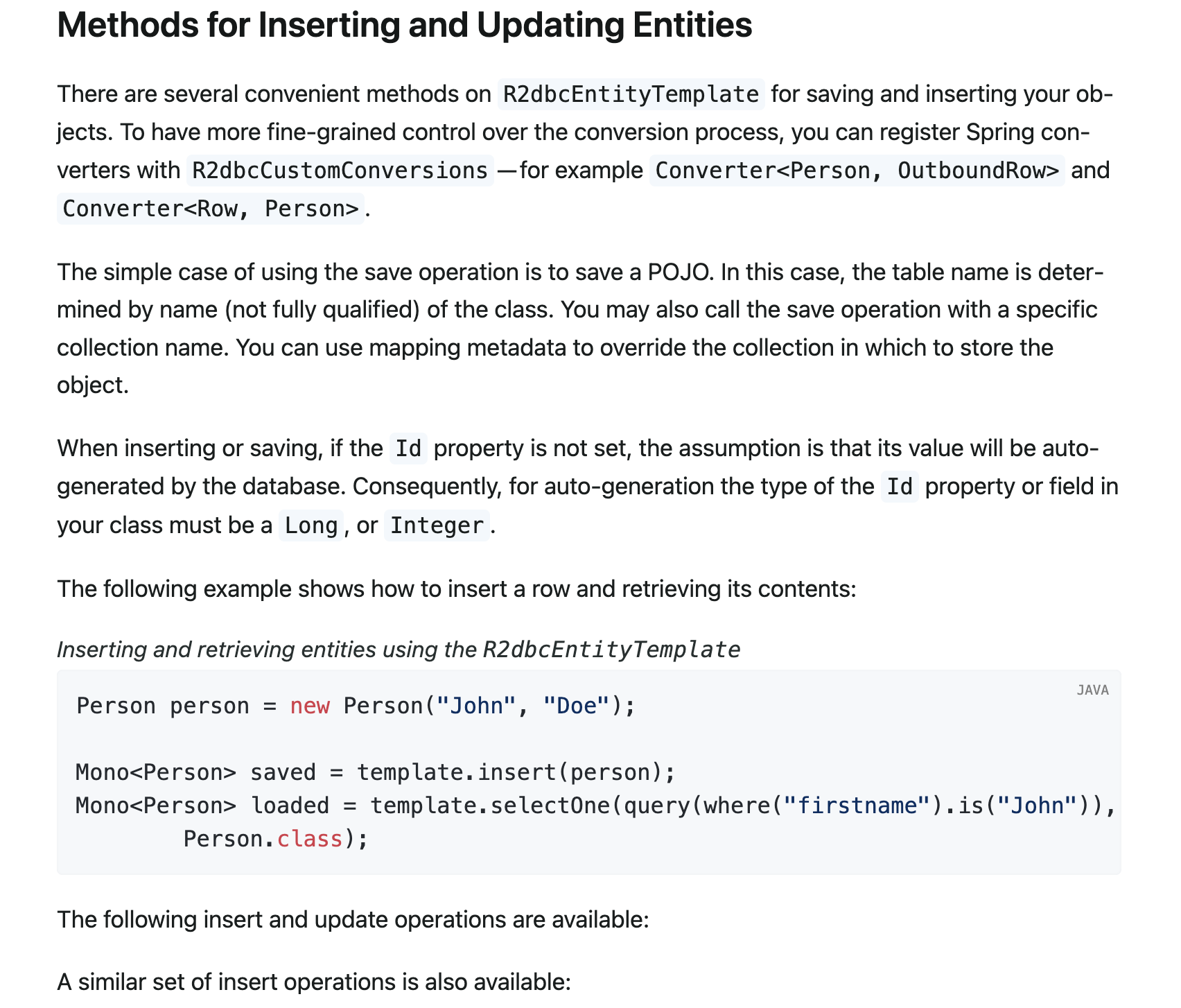

この問題についても、以下の公式ドキュメントに記載されておりました。
When inserting or saving, if the Id property is not set, the assumption is that its value will be auto-generated by the database. Consequently, for auto-generation the type of the Id property or field in your class must be a Long, or Integer.
挿入または保存する際、もしIdプロパティが設定されていなければ、その値がデータベースによって自動生成されるという仮定がなされる。
この文言から、もしIdが既に設定されている場合、既存のオブジェクトと判断され、単にupdateクエリが発行されると推測できました。
解決策
とりあえず、暫定的に@Queryを使用して
@Query("INSERT INTO refresh_tokens (token, member_id, role, expires_at) VALUES (:#{#token.token}, :#{#token.memberId}, :#{#token.role}, :#{#token.expiresAt})")
Mono<RefreshToken> save(RefreshToken token);
とりあえずこのように記述いたしました。
この方法では拡張に対して脆弱という致命的な欠点が生じますが、
現時点ではこのrefreshtokenについて追加で拡張する予定は全くなく、
もし拡張される場合はRedisへ移行するため、現状ではこれで十分だと考えております。
JPAとはどう異なるのか?
JPAには次のようなロジックが存在します。
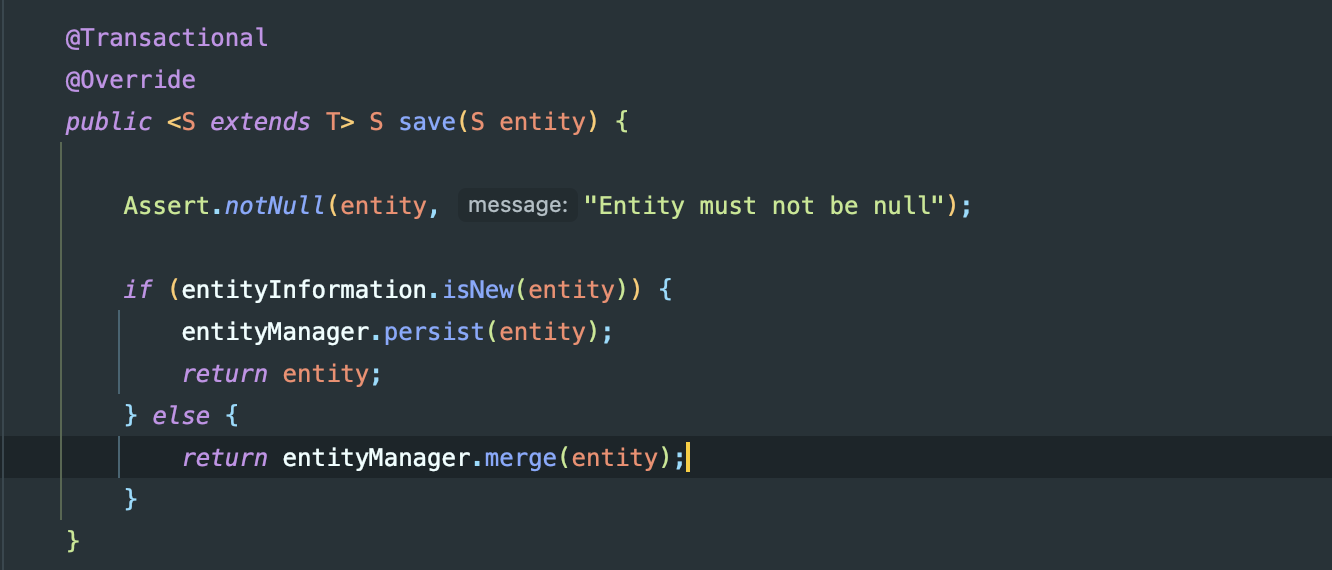
@IDフィールドがnullであれば、そのエンティティは新規エンティティと判断されます。
しかし、何か値が入っている場合はどうなるのでしょうか?
return entityManager.merge(entity);
次のメソッドを呼び出して、永続性コンテキストに該当エンティティが存在するかを判断し、存在しなければ
selectクエリで該当のIDをもつオブジェクトがデータベースにあるかを確認いたします。
(ここで、クエリがもう一度発生してN+1問題が起こる可能性があります。)
もしJPAで実装していれば、N+1問題を解消するために
isNew()をオーバーライドして、selectクエリが発生しないように再定義していたことでしょう。
しかし、ReactiveCrudRepositoryは異なります。
ReactiveCrudRepositoryは永続性コンテキストの存在がなく、単に
@Idがある場合はupdate()、ない場合はinsertと判断するため、
この問題が発生すると考えられます。
(あらゆる面でJPAは素晴らしいと考えております)
トランザクションはどのように適用されるのか?
果たしてReactive環境ではトランザクションがどのように適用されるのか、
非常に気になりました。
詳細については、以下のSpring公式ブログ記事をご参照ください。

Over time, MongoDB started to support multi-document transactions with MongoDB Server 4.0. R2DBC (the specification for reactive SQL database drivers) started to emerge, and we decided to pick up on R2DBC with Spring Data R2DBC. Both projects wanted to expose transactional behavior, so they eventually provided inTransaction(…) methods on their Template APIs to perform units of work guarded by native transactions.
r2dbcのリアクティブ環境でもトランザクション処理機能が導入されるとの記述がございます。
要するに、
@Transaction
という宣言型トランザクションを使用できるという意味になります。
Starting with Spring Framework 5.2 M2, Spring supports reactive transaction management through the ReactiveTransactionManager SPI.
これは、Spring Framework 5.2からサポートされております。
@Transactional
public Mono<TokenPair> createToken(final AuthenticatedMember authenticatedMember) {
return refreshTokenRepository.deleteByMemberId(authenticatedMember.id())
.then(Mono.just(authenticatedMember))
.map(tokenProvider::createToken)
.flatMap(tokenPair -> {
RefreshToken refreshToken = tokenProvider.createRefreshTokenEntity(tokenPair, authenticatedMember);
return refreshTokenRepository.save(refreshToken)
.thenReturn(tokenPair);
});
}
次のように利用できることを確認いたしました。
Reactive環境において @Transaction はどのように動作するのでしょうか?
従来のトランザクションは、ThreadLocalを使用して同一スレッド内でトランザクション状態を伝播いたします。
すなわち、同一スレッドで @Transaction が付与されたすべてのコードが実行され、スレッドが同じであるためすべての処理が同一トランザクションを共有いたします。
では、Reactive環境において @Transaction はどのように動作するのでしょうか?
この点も、該当のSpringブログにて確認することができました。
Reactor Contextの役割
Reactor Contextとは?
Reactor Context is to reactive programming what ThreadLocal is to imperative programming: Contexts allow binding contextual data to a particular execution. For reactive programming, this is a Subscription. Reactor’s Context lets Spring bind the transaction state, along with all resources and synchronizations, to a particular Subscription.
Reactor Contextは、リアクティブプログラミングにおいて、ThreadLocalが命令型プログラミングに果たす役割と同様のものです。
コンテキストは、特定の実行に対してコンテキストデータをバインドすることを可能にします。
リアクティブプログラミングの場合、これはSubscriptionとなります。
ReactorのContextは、Springがトランザクション状態とすべてのリソースおよび同期情報を特定のSubscriptionにバインドすることを可能にします。
この文を簡単にまとめると、
- ThreadLocalの代わりに、Reactor Contextを用いてトランザクションを管理します。
For reactive programming, this is a Subscription.
- リアクティブプログラミングでは、Subscriptionがコード実行の基本単位となります
もう少し整理すると
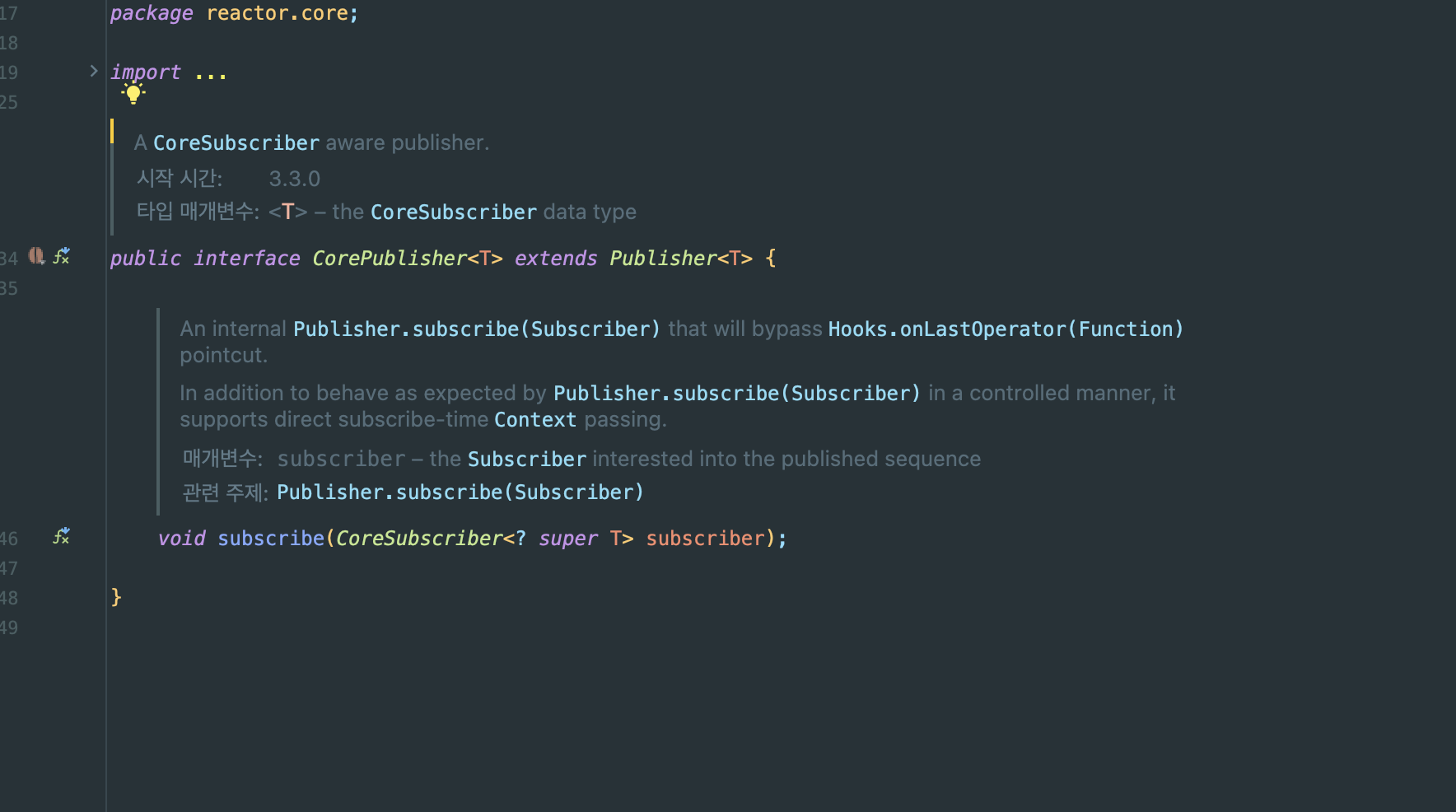
例えば、@Transactionalアノテーションが適用されたリアクティブなメソッド(返却型がMonoやFluxのメソッド)は、実際にはそのPublisherがサブスクライブされる時点でトランザクションが開始されます。
この際、トランザクションの状態(例:トランザクション開始の有無、関連するリソースなど)はReactor Contextに保存され、サブスクリプション内で実行される全ての演算が同一のトランザクション範囲を共有することになります。
つまり、SpringはReactor Contextを活用することにより、リアクティブなコードが複数のスレッドで実行された場合でも、同一のSubscription内ではトランザクション状態および同期情報が安全に伝播・管理されるようにしています。
プロジェクション(projection)マッピングの問題
確かに正しいクエリが発行され、リストも正しく返却されているのに、
結果を確認してみると、値のマッピングが正しく行われていない問題を確認いたしました。

ロウクエリをそのままデバッグで確認したところ、

正しく値は入っているものの、マッピングが行われていないことが確認されました。
おそらく、JPAのような高度なprojectionは、まだサポートされていないようです。
したがって
@Repository
@RequiredArgsConstructor
public class MemberTermRepositoryImpl implements MemberTermCustomRepository {
private final R2dbcEntityTemplate r2dbcEntityTemplate;
次のようにカスタムRepositoryを定義し、
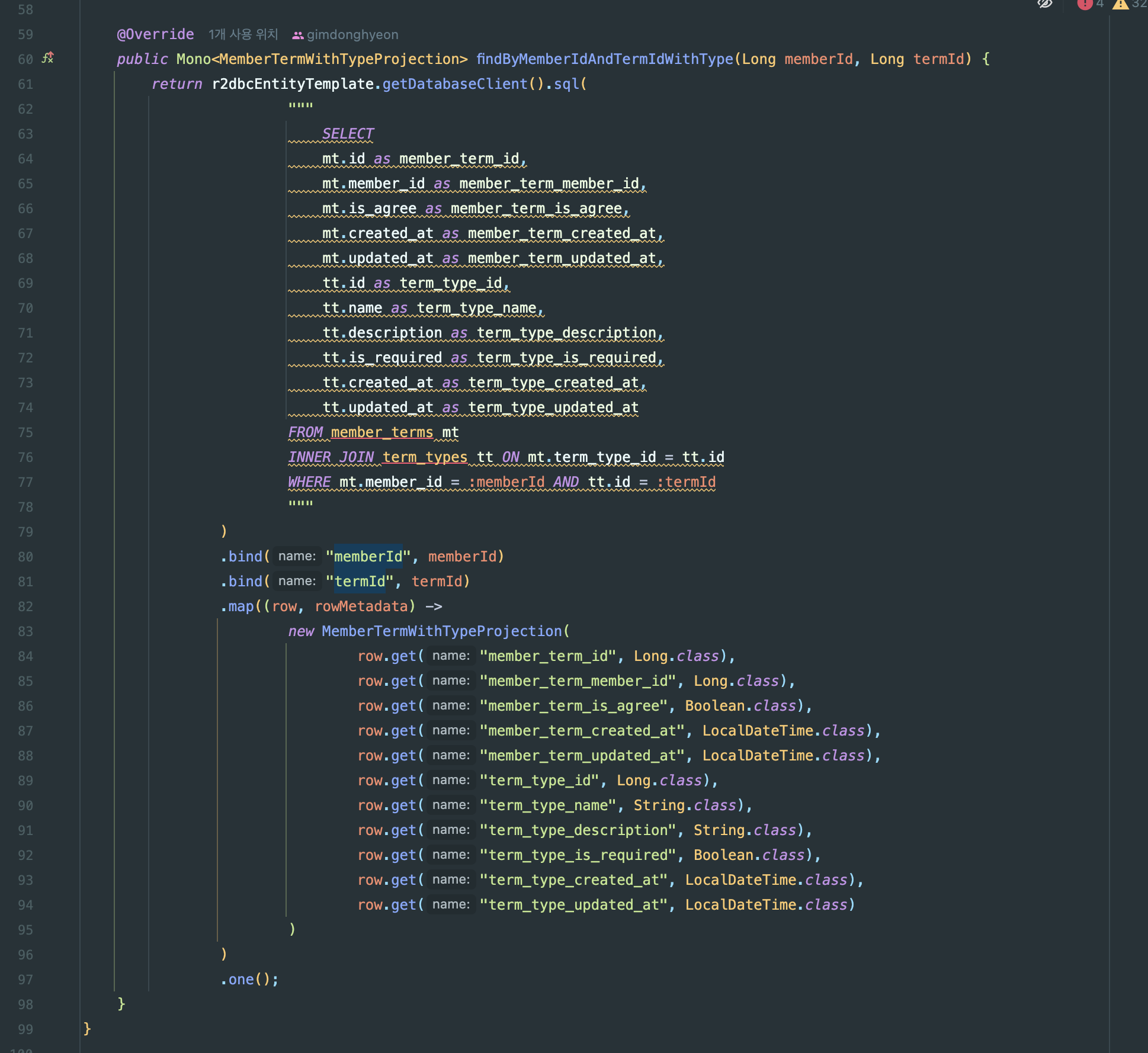
直接マッピングを行うコードを通じてマッピングし、解決いたしました。
まだJPAよりもサポートしている機能が少ないように感じられます。
終わりに
今回、JPAの代わりにR2DBCを適用することで、多くのことを学んだように感じます。
まず、最大の成果はリアクティブメソッドの動作方式をある程度把握できたことだと考えております。
まだR2DBCは、外部キーのサポート、複合キーのサポート、Lazy Loadingなど、さまざまな面でサポートする機能が少ない未成熟なフレームワークのようです。
しかし、興味深く楽しい部分が多く、成長中のエコシステムであるだけに、オープンソースに貢献したい…と思わせる内容となりました.
追加的なレファレンス