0. 概要
少し厨二病らしさを感じさせるDarknetのYoloですが、ここ最近、進化が止まらないですね。気がつけばバージョンアップを繰り返しv3にまで。
さて、このYolo v3が如何ほどの性能なのか試したいので、自前のデータを使って学習させるまでを解説したいと思います。
なお、大体の解説はdarknetの公式サイトに書かれています。
https://pjreddie.com/darknet/
1. Installation
まず、gitからソースコードを取得
$ git clone https://github.com/pjreddie/darknet.git
$ cd darknet
GPUを使う場合は、Makefileを開いてGPUのフラグを立ててからコンパイル
Makefileファイルを開く
$ vi Makefile
GPU=0 を GPU=1に変更する
CUDNNも入っている場合は
CUDNN=0 を CUDNN=1に変更する。
動画の処理やマルチインプット処理をさせたい場合は
opencvも必要なので、それは1.2を見てね。
GPU=1
CUDNN=1
OPENCV=0
OPENMP=0
DEBUG=0
ARCH= -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
# -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
VPATH=./src/:./examples
SLIB=libdarknet.so
ALIB=libdarknet.a
EXEC=darknet
OBJDIR=./obj/
CC=gcc
NVCC=nvcc
AR=ar
ARFLAGS=rcs
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -Isrc/
CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
...
コンパイルする。
$ make
実行する。
$ ./darknet
こんな感じのエラーが出れば動いてる。
usage: ./darknet <function>
1.2. Installation with opencv
opencv 3.4だとエラーが出るみたいなので、3.3で進めます。
また、Condaが入っている場合はリンクエラーがでます。これを解決するのは結構難しい。
そこで、以下のように.bashrc等にあるanacondaのエクスポートを外しておく。
エクスポートの一覧はexport -pで見られる。
# added by Anaconda3 installer (if you use ros, change comment-out the bellow)
#export PATH="/home/your_name/anaconda3/bin:$PATH"
次にOpencvのインストール。忘れてはいけないのはffmpegのフラグを立てること。
ビルドに必要な奴
sudo apt-get install cmake libeigen3-dev libgtk-3-dev qt5-default freeglut3-dev \
libvtk6-qt-dev libtbb-dev ffmpeg libdc1394-22-dev libavcodec-dev libavformat-dev \
libswscale-dev libjpeg-dev libjasper-dev libpng++-dev libtiff5-dev \
libopenexr-dev libwebp-dev libhdf5-dev libpython3.5-dev python3-numpy \
python3-scipy python3-matplotlib libopenblas-dev liblapacke-dev
次にgitからopencvを持ってくる
$ mkdir cv && cd cv
$ git clone https://github.com/Itseez/opencv.git
$ cd opencv
$ git tag
$ git checkout 3.3.0
ビルドの設定
$ mkdir build && cd build
cmake -G "Unix Makefiles" --build . -D BUILD_CUDA_STUBS=OFF -D BUILD_DOCS=OFF \
-D BUILD_EXAMPLES=OFF -D BUILD_JASPER=OFF -D BUILD_JPEG=OFF -D BUILD_OPENEXR=OFF \
-D BUILD_PACKAGE=ON -D BUILD_PERF_TESTS=OFF -D BUILD_PNG=OFF -D BUILD_SHARED_LIBS=ON \
-D BUILD_TBB=OFF -D BUILD_TESTS=OFF -D BUILD_TIFF=OFF -D BUILD_WITH_DEBUG_INFO=ON \
-D BUILD_ZLIB=OFF -D BUILD_WEBP=OFF -D BUILD_opencv_apps=ON -D BUILD_opencv_calib3d=ON \
-D BUILD_opencv_core=ON -D BUILD_opencv_cudaarithm=OFF -D BUILD_opencv_cudabgsegm=OFF \
-D BUILD_opencv_cudacodec=OFF -D BUILD_opencv_cudafeatures2d=OFF -D BUILD_opencv_cudafilters=OFF \
-D BUILD_opencv_cudaimgproc=OFF -D BUILD_opencv_cudalegacy=OFF -D BUILD_opencv_cudaobjdetect=OFF \
-D BUILD_opencv_cudaoptflow=OFF -D BUILD_opencv_cudastereo=OFF -D BUILD_opencv_cudawarping=OFF \
-D BUILD_opencv_cudev=OFF -D BUILD_opencv_features2d=ON -D BUILD_opencv_flann=ON \
-D BUILD_opencv_highgui=ON -D BUILD_opencv_imgcodecs=ON -D BUILD_opencv_imgproc=ON \
-D BUILD_opencv_java=OFF -D BUILD_opencv_ml=ON -D BUILD_opencv_objdetect=ON \
-D BUILD_opencv_photo=ON -D BUILD_opencv_python2=OFF -D BUILD_opencv_python3=ON \
-D BUILD_opencv_shape=ON -D BUILD_opencv_stitching=ON -D BUILD_opencv_superres=ON \
-D BUILD_opencv_ts=ON -D BUILD_opencv_video=ON -D BUILD_opencv_videoio=ON \
-D BUILD_opencv_videostab=ON -D BUILD_opencv_viz=OFF -D BUILD_opencv_world=OFF \
-D CMAKE_BUILD_TYPE=RELEASE -D WITH_1394=ON -D WITH_CUBLAS=OFF -D WITH_CUDA=OFF \
-D WITH_CUFFT=OFF -D WITH_EIGEN=ON -D WITH_FFMPEG=ON -D WITH_GDAL=OFF -D WITH_GPHOTO2=OFF \
-D WITH_GIGEAPI=ON -D WITH_GSTREAMER=OFF -D WITH_GTK=ON -D WITH_INTELPERC=OFF -D WITH_IPP=ON \
-D WITH_IPP_A=OFF -D WITH_JASPER=ON -D WITH_JPEG=ON -D WITH_LIBV4L=ON -D WITH_OPENCL=ON \
-D WITH_OPENCLAMDBLAS=OFF -D WITH_OPENCLAMDFFT=OFF -D WITH_OPENCL_SVM=OFF -D WITH_OPENEXR=ON \
-D WITH_OPENGL=ON -D WITH_OPENMP=OFF -D WITH_OPENNI=OFF -D WITH_PNG=ON -D WITH_PTHREADS_PF=OFF \
-D WITH_PVAPI=OFF -D WITH_QT=ON -D WITH_TBB=ON -D WITH_TIFF=ON -D WITH_UNICAP=OFF \
-D WITH_V4L=OFF -D WITH_VTK=OFF -D WITH_WEBP=ON -D WITH_XIMEA=OFF -D WITH_XINE=OFF \
-D WITH_LAPACKE=ON -D WITH_MATLAB=OFF ..
buildする。 j以降の数字はCPUのスレッド数。
$ make -j128
$ sudo make install
どうやら途中でビルドが止まることがあるらしい。
その場合は1スレッドでやるとよいとのこと。
起動確認
$ python3
これでインポートされればおk
import cv2
cv2.__version__
ここからはめちゃくちゃ突っかかりポイント。
Stackoverflowとか見る限り、ベアメタルからやり直している人やソースコードを書き換えている人が多かった。
しかし、そんな必要はない。
daraknetのMakefileを以下のように変更する。
1 GPU=1
2 CUDNN=1
3 OPENCV=1
4 OPENMP=0
5 DEBUG=1
6
7 ARCH= -gencode arch=compute_30,code=sm_30 \
8 -gencode arch=compute_35,code=sm_35 \
9 -gencode arch=compute_50,code=[sm_50,compute_50] \
10 -gencode arch=compute_52,code=[sm_52,compute_52]
11 # -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
12
13 # This is what I use, uncomment if you know your arch and want to specify
14 # ARCH= -gencode arch=compute_52,code=compute_52
15
16 VPATH=./src/:./examples
17 SLIB=libdarknet.so
18 ALIB=libdarknet.a
19 EXEC=darknet
20 OBJDIR=./obj/
21
22 CC=gcc
23 NVCC=nvcc
24 AR=ar
25 ARFLAGS=rcs
26 OPTS=-Ofast
27 LDFLAGS= -lm -pthread
28 COMMON= -Iinclude/ -Isrc/
29 CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
30
31 ifeq ($(OPENMP), 1)
32 CFLAGS+= -fopenmp
33 endif
34
35 #ifeq ($(DEBUG), 1)
36 #OPTS=-O0 -g
37 #endif
38
39 ifeq ($(DEBUG), 1)
40 OPTS=-Og -g
41 endif
42
変更箇所はOpencvを使うためのフラグである3行目と
31行目から41行目のコンパイラの最適化部分。
このコンパイラの最適化を外さないと、リンクが上手くいかずRoundエラーとか
Qt5エラーがでまくる。これは中々引っ掛かるとつらい。
あとは、コンパイルする。
$ make
実行する。
./darknet
こんな感じのエラーが出れば動いてる。
usage: ./darknet <function>
2. Run
とりあえずYolo v3といったらこの画像。
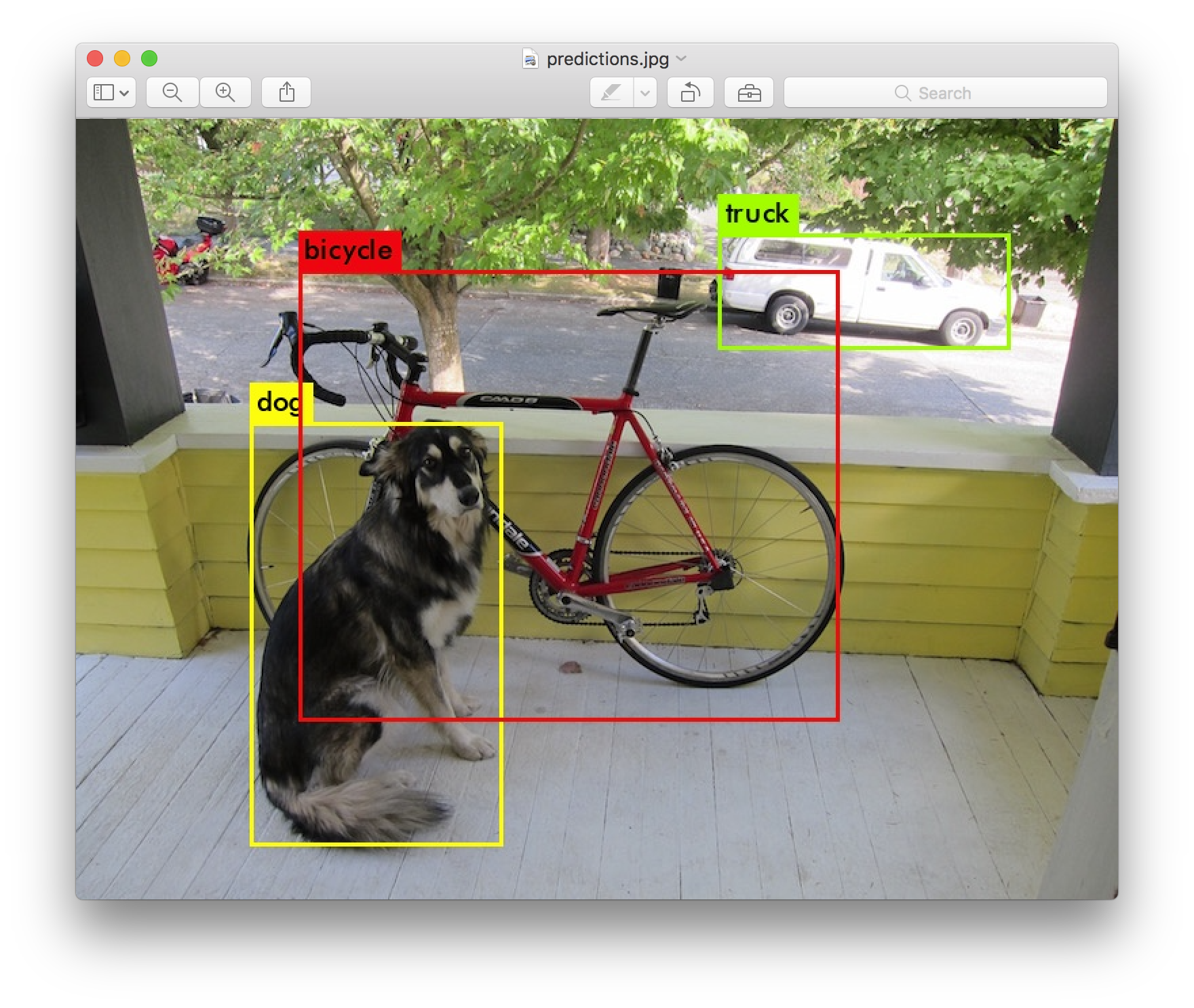
これを出力してみる。
まずはdarknet直下のフォルダにweightをダウンロード
$ wget https://pjreddie.com/media/files/yolov3.weights
cfgファイルはdarknetをgit cloneした際にcfgフォルダに含まれているので、何かをダウンロードする必要はない。
このまま実行する。
$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
するとこんな感じの標準出力と一緒に画像も出力される。
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
画像を見てみると、あの有名な画像が表示される。
$ display predictions.png
3. Training / Customize using my dataset
さて、本題。自前で用意したデータで学習させる。
まず、用意するデータ構造は以下。
darknet
| - ...
|- cfg
|- task
|- datasets.data
|- class.txt
|- train.txt
|- test.txt
|- yolov3-voc.cfg
|- datasets
|- img1.png
|- img1.txt
|- img2.png
|- img2.txt
|- ...
フォルダの配置は様々なやり方があるが、
個人的に、識別したいタスクごとにフォルダを切りたいので、このような配置にした。
では、手順と伴に各フォルダ/ファイルの生成をしていく。
ルートフォルダはdarknet直下とする。
まずはタスクフォルダを生成する。これから、このフォルダにデータセットやモデル情報を入れていく。
$ mkdir ./cfg/task
次に、データセット情報をまとめたファイルを作る。
$ vi ./cfg/task/datasets.data
datasets.dataの中身はこんな感じ。
classes= 1
train = /YOUR_PATH/darknet/cfg/task/train.txt
valid = /YOUR_PATH/darknet/cfg/task/test.txt
names = /YOUR_PATH/darknet/cfg/task/class.txt
backup = /YOUR_PATH/darknet/cfg/task/backup
classesはタスクのクラス数。今回は、人を識別したいので1クラス
train、validはデータセットのパスが書かれたテキスト
namesはクラスの名前
backupはWeightの保存先
class.txtの中身はこんな感じ
people
1クラスしかないのでpeopleのみ。
次にtrain.txtの中身をこんな感じに作る。
/YOUR_PATH/darknet/cfg/task/datasets/img_0-0.jpg
/YOUR_PATH/darknet/cfg/task/datasets/img_0-1.jpg
/YOUR_PATH/darknet/cfg/task/datasets/img_0-2.jpg
...
1行毎にトレーニングデータに用いる画像のパスを書いていく。
なお、/YOUR_PATH/darknet/cfg/task/datasets/img_0-0.jpgに対応するラベルは、
/YOUR_PATH/darknet/cfg/task/datasets/img_0-0.txtに作成する。
ラベルの/YOUR_PATH/darknet/cfg/task/datasets/img_0-0.txtはこんな感じに作る。
0 0.6015625 0.0 0.0130085744628398 0.0130085744628398
0 0.63671875 0.04296875 0.004952784185470923 0.004952784185470923
0 0.65234375 0.05859375 0.015759324877162584 0.015759324877162584
フォーマットは以下である
[クラス] [矩形の中心座標x] [矩形の中心座標y] [矩形のwidth] [矩形のheight]
1枚の画像に2つのBounding Boxが含まれる場合は2行に分けてかけばよい。
なお、各座標は0 - 1に正規化されている。
train.txtと同様にtest.txtの中身も作る。
最後にyolov3-voc.cfgを作る。
まずは、ひな形をコピーしてくる。
$ cp /YOUR_PATH/darknet/cfg/yolov3-voc.cfg /YOUR_PATH/darknet/cfg/task/
次にtask内のyolov3-voc.cfgを開き、修正する。
冒頭に書かれているコンフィグを画像にあったものにする。
特に大きさは重要。
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=16
subdivisions=6
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 50200
policy=steps
steps=40000,45000
scales=.1,.1
次に、classesでGrepすると3カ所ほど以下のような記述があるはずである。
[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
これのfiltersとclassesを変更する。
classesは今回は1なので、1にする。次に、filtersは以下の計算式に従う。
filters=mask_num * (classes + 5)の計算式に従い、設定する。
これはAnchorを採用した数(Mask)×(そのクラスである確率を出力するレイヤー, x, y, w, h, p)という意味である。
今回classesが1で、mask_numが3つなので、filtersは18となる。
なので、こんな形に整形して、3カ所分修正したら終わり。
[convolutional]
size=1
stride=1
pad=1
# filters=75
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
最後に以下のコマンドでトレーニングを実行
./darknet detector train ./cfg/your_task/datasets.data cfg/your_task/yolov3-voc.cfg
学習が始まった。
めでたしめでたし。
4. Testing
Predictionは以下のコマンドで行う。
./darknet detector test cfg/task/datasets.data cfg/task/yolov3-voc.cfg cfg/task/backup/yolov3-voc_200.weight ./cfg/task/datasets/img_0-0.jpg -thresh 0.01
threshに指定する値で画像に出力する識別結果を制限できる。
0.1を指定した場合は「そのクラスである確率は10%以上」と識別されたものだけが画像に表示される。