0. 概要
最近CNNのFPGA搭載化が流行ってきましたね。
もうFPGA化に際しては、FINN以上のものは生まれないだろうなーってなんて思っていたところ、YoloをFPGAで動かしている動画を発見。
https://www.youtube.com/watch?v=_iMboyu8iWc
どうやら中原先生の成果らしい。論文(A Lightweight YOLOv2 A Binarized CNN with A Parallel Support Vector Regression for an FPGA)は以下。
https://www.researchgate.net/publication/323375650_A_Lightweight_YOLOv2_A_Binarized_CNN_with_A_Parallel_Support_Vector_Regression_for_an_FPGA
2分くらいで斜め読みしたところ、特徴的な点は以下であった?
・Batch NormalizationはFINNの論文を参考に閾値フィルタリング
・畳み込み層はBinary-netとXNOR-netを参考に2値化(学習後に2値へ変換)
・畳み込み層から結合層の際にFully convolution layer構造を使うと非常にメモリを消費するため、
SVRに変更
学習から識別までの流れとしては以下であった。
Yoloで学習→バイナリ化→結合層より前を抽出→結合層にSVRを追加して再学習→識別
上2つは分かるが、一番下の結合層をSVRに変更なんてできるのか・・・?
もしこれができるのであれば、軽く論文を読む限りは、メモリの削減量が物凄い。
SVR自体のWeightは1つしかないらしい。
すなわち、今までの結合層はInput×Outputのノード分のWeightがあったが、
この手法だとOutputの個数しかないらしい。でも演算の回数は変わらないような気がする。
ようはノード1つのニューラルネットワークに近い?
仮に結合層のInputが2 * 2 * 128でOutputが5だった場合、旧来の方法では、2560の重みが必要
それに対して今回の方法だと5つだけ。これは凄い。
そこで少し実験してみた。
結果: SVRに変更してもニューラルネットワークより重みの数と計算量を減らすことができなさそう。どうすればよいのか・・・。
1. BNNのプログラム作成
Binary-netの素体がGithubに上がっていたのでこれを拝借
https://github.com/DingKe/nn_playground/tree/master/binarynet
SVRを使うので、回帰問題に変更したい。
そこで、取り合えずmnistで入力に1が入ってきたら0.1を出力、2が入ってきたら0.2を出力みたいなクソプログラムを作ってみる。試せればよいので値の範囲とか細かいことは気にしない。
mnist_cnn.pyを開き、ラベルをone-hot-vectorから回帰に変更。
また、結合層のDenseも浮動小数点化する。もちろん損失関数も変更。
X_train = X_train.reshape(60000, 1, 28, 28)
X_test = X_test.reshape(10000, 1, 28, 28)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = y_train / 10
Y_test = y_test / 10
model = Sequential()
# conv1
model.add(BinaryConv2D(256, kernel_size=kernel_size, input_shape=(channels, img_rows, img_cols),
data_format='channels_first',
H=H, kernel_lr_multiplier=kernel_lr_multiplier,
padding='same', use_bias=use_bias, name='conv1'))
model.add(BatchNormalization(epsilon=epsilon, momentum=momentum, axis=1, name='bn1'))
model.add(Activation(binary_tanh, name='act1'))
# conv2
model.add(BinaryConv2D(256, kernel_size=kernel_size, H=H, kernel_lr_multiplier=kernel_lr_multiplier,
data_format='channels_first',
padding='same', use_bias=use_bias, name='conv2'))
model.add(MaxPooling2D(pool_size=pool_size, name='pool2', data_format='channels_first'))
model.add(BatchNormalization(epsilon=epsilon, momentum=momentum, axis=1, name='bn2'))
model.add(Activation(binary_tanh, name='act2'))
# conv3
model.add(BinaryConv2D(512, kernel_size=kernel_size, H=H, kernel_lr_multiplier=kernel_lr_multiplier,
data_format='channels_first',
padding='same', use_bias=use_bias, name='conv3'))
model.add(BatchNormalization(epsilon=epsilon, momentum=momentum, axis=1, name='bn3'))
model.add(Activation(binary_tanh, name='act3'))
# conv4
model.add(BinaryConv2D(512, kernel_size=kernel_size, H=H, kernel_lr_multiplier=kernel_lr_multiplier,
data_format='channels_first',
padding='same', use_bias=use_bias, name='conv4'))
model.add(MaxPooling2D(pool_size=pool_size, name='pool4', data_format='channels_first'))
model.add(BatchNormalization(epsilon=epsilon, momentum=momentum, axis=1, name='bn4'))
model.add(Activation(binary_tanh, name='act4'))
model.add(Flatten(name='flt'))
# dense1
model.add(Dense(1))
model.add(BatchNormalization(epsilon=epsilon, momentum=momentum, name='bn5'))
opt = Adam(lr=lr_start)
model.compile(loss='mean_squared_error', optimizer=opt, metrics=['acc'])
model.summary()
これで、取り合えず5分くらい学習を行うと
Test dataのラベル: [0.5 0. 0.4 0.1 0.9 0.2 0.1 0.3 0.1 0.4]
Prediction: [0.47359747 0.08724903 0.45469939 0.19697031 0.81849686 0.30036611
0.20007152 0.31680289 0.1996292 0.41415244]
一応小数点一桁目だけど見れば、そこそこ合ってそう。
学習時間を掛ければきっちり合うだろうが、今回はトレンドを得られたのでよしとする。
2. 結合層をSVRに変更
次に、上記のプログラムのFlatten箇所の出力のみを得る。
トレーニングに使った画像6万枚でもよいが、それだとちと重いので今回は3000枚くらい。
intermediante_layer_model = Model(inputs=model.input, outputs=model.get_layer("flt").output)
x_input = intermediante_layer_model.predict(X_train[0:3000])
ここで、x_inputを見ると以下のように512×7×7の出力を得られている
[1, -1, -1, -1, ... 1]
今度はこれをSVRに学習させていく。
model.load_weights('param.hdf5')
intermediante_layer_model = Model(inputs=model.input, outputs=model.get_layer("flt").output)
x_input = intermediante_layer_model.predict(X_train[0:3000])
svr_lin = SVR(kernel='linear', C=1e3)
y_lin = svr_lin.fit(x_input, Y_train[0:3000])
x_input_test = intermediante_layer_model.predict(X_test[0:10])
print(Y_test[0:10])
print(y_lin.predict(x_input_test))
では、実行する。
Test dataのラベル: [0.7 0.2 0.1 0. 0.4 0.1 0.4 0.9 0.5 0.9]
Prediction: [0.66795861 0.14231277 0.17944743 0.18836471 0.52399224 0.19437069
0.52518306 0.66133984 0.45813019 0.8193802 ]
精度はそこそこかな・・・?
一応FPGA搭載を考えて、SVRのフォワードプロパゲーションも再現してみる。
3. SVRのWeightを取り出して計算
coef_を呼び出すとSVRのWeightを取得できる。Biasはintercept_である。
次に、ニューラルネットワークと同じ要領でまずは入力とWeightをお互いを掛け合わせて、最後にBiasを足す。
get_svr_weight = y_lin.coef_[0]
get_svr_bias = y_lin.intercept_[0]
inference = np.sum(get_svr_weight * x_input_test[0]) + get_svr_bias
print(inference)
すると以下の結果が得られた。
0.6679586141390711
うむ、svr.predictで推論した結果と手動計算が合っている。
因みに、svr.predictの結果は以下。
0.66795861
しかし、Weightの数 (coef_)を見てみると7 * 7 * 512個分ある・・・。
入力値を各次元に分解して最適化したのだと思われる。あれ?それだとニューラルネットワークと重みの数が同じだ
4. 論文を見返してみる
ニューラルネットワークと重みの数が同じだ・・・
ってことで、論文を見返してみる。
まずはSVRの計算式から、

論文だとWeightは1個に見える、パーセプションと計算が似てるって書いてあるから
今回の計算方法で間違いはないだろう。そのほかの条件式は、SVRのジェネラルな条件式だから今は無視する。

Yolov2はFCL構造なので、畳み込み演算を全てのレイヤーで実施している(?)。最終層は違うような・・?
畳み込み層において、和演算からの積がボトルネックだといっている。また、重みに大きなメモリを必要にするとも。
そして、畳み込み演算と比較してSVRは計算量が少なく、FPGAに搭載しやすいよと書いてある・・・。
ん?これは最終層のFully connected layerではなく、畳み込み演算をSVRに置き換えるという話・・(?)
でも、Yolo v2の最終層ってFully connected layerじゃなかったっけ?!
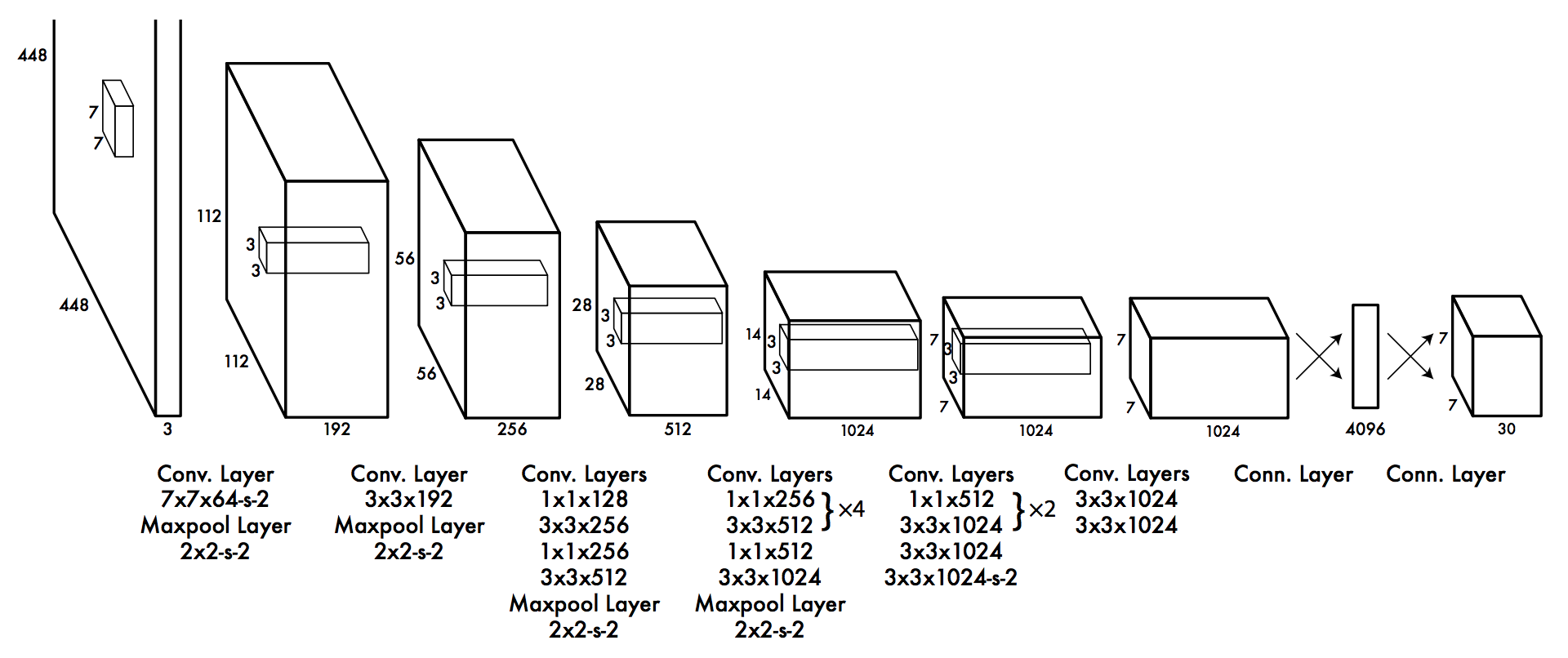
↑ yolo v2.
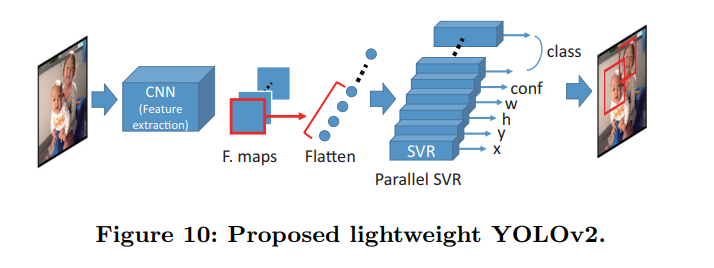
しかし、論文の図を見てみると、畳み込み演算をした後に、その特徴量をSVRに入力している。
ということは、Fully connedted layerをSVRに置き換えた今の方法で合っている・・・?
といっても、SVRが各クラス分用意されていれば、そのWeightの数はニューラルネットワークと変わらないし、処理回数も計算手法がニューラルネットワークと同じなので、変わらないだろうし。
強いて言えば最適化手法が異なるので、精度には関係があるかもしれない。
うーん、いまいち分からないぞ~。
2017年の夏頃にXilinxがYoloを(その時はまだ未発売の)UltraScaleで動かしているのを米国の展示会で見た気がする。あれはどうやって実装していたんだろうか。UltraScaleなら普通に実装してもBBとClassの数を減らせば収まりそうな気もする。
5. 結果&比較
一応最後に、精度だけ比較しておきます。
まずは、ただのCNN(結合層あり)。
CNN (Fully connedted layer):
Test dataのラベル: [0.7 0.2 0.1 0. 0.4 0.1 0.4 0.9 0.5 0.9]
Prediction: [[0.76504064] [0.22770569] [0.1544111 ] [0.04696366] [0.56249446] [0.16403013] [0.4048999 ] [0.764249 ] [0.58280826] [0.90762067]]
次に今回の実験
CNN (+SVR):
Test dataのラベル: [0.7 0.2 0.1 0. 0.4 0.1 0.4 0.9 0.5 0.9]
Prediction: [0.66795861 0.14231277 0.17944743 0.18836471 0.52399224 0.19437069
0.52518306 0.66133984 0.45813019 0.8193802 ]
おー!!結構近い!
これが座標なら殆ど間違ってないといってもよい!Weightの数が減らせるなら凄い。
今後のFPGAではこの実装が一般的になる??というか実装あってるかな?
何かお気づきの点があればご指摘お願いします。