0. 概要
FPGAでGPUやCPUに劣らない処理をさせようとすると並列計算に加え、Streaming転送等が必要になってくる。また、動的に対象物を処理する場合にはDMAも必要である。今回は、これらの基本的な構造についてまとめたいと考えている。
1. DMA
省略
2. Streaming
stream処理の実装
まずStreamで入力を受け取って、Streamで出力することを考える。
int stream_app(hls::stream<ap_axis<32,1,1,1> >& ins, hls::stream<ap_axis<32,1,1,1> >& outs){
このため、Main関数の引数に入力と出力用のStreamを指定する。
次に、データの送信開始を伝えるuserを監視するルーチンを作る。
// Waiting for start
Loop1 : do {
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
ins >> input;
} while(input.user == 0);
データの送信が開始されたら、そのデータの個数分Streamで届くのを待つ。
ins >> inputはStreamのデータがバッファーに溜まった時点でinsからinputにデータが書き込まれる。
後は自前で処理したい内容を追加して、処理結果をメイン関数の出力用引数であるoutsに返す。
Loop2 : for (int i=0; i < DATA_NUM; i++){
// Get data
if (i != 0) ins >> input;
// Processing
proc += input.data;
output.data = proc;
//
if (i == 0)
output.user = 1;
else
output.user = 0;
if (i == (DATA_NUM - 1))
output.last = 1;
else
output.last = 0;
//
outs << output;
}
return 0;
}
test benchからの呼び出し
最初にDummyデータを送信しても処理が開始されないことを確認したいため、DummyデータとDatasetを2つ作り、Streaming用の変数に格納しておく。
後は処理結果を受け取るStreaming用のoutsを作成し、先ほどのメイン関数を指定してやればよい。
// Fields
hls::stream<ap_axis<32,1,1,1> > ins;
hls::stream<ap_axis<32,1,1,1> > outs;
ap_axis<32,1,1,1> dataset;
// Dummy
for(int i=0; i<5; i++){
dataset.user = 0;
dataset.data = i;
ins << dataset;
}
// Dataset
for(int i=0; i < DATA_NUM; i++){
dataset.user = 1;
dataset.data = i;
ins << dataset;
}
// Main processing
stream_app(ins, outs);
cout << endl;
cout << "Finished processing" << endl;
全コード
#include <stdio.h>
#include <string.h>
#include <ap_int.h>
#include <hls_stream.h>
#include <ap_axi_sdata.h>
#include "stream_app.h"
int stream_app(hls::stream<ap_axis<32,1,1,1> >& ins, hls::stream<ap_axis<32,1,1,1> >& outs){
#pragma HLS INTERFACE axis register both port=ins
#pragma HLS INTERFACE axis register both port=outs
#pragma HLS INTERFACE s_axilite port=return
ap_axis<32,1,1,1> input;
ap_axis<32,1,1,1> output;
int proc = 0;
// Waiting for start
Loop1 : do {
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
ins >> input;
} while(input.user == 0);
Loop2 : for (int i=0; i < DATA_NUM; i++){
// Get data
if (i != 0) ins >> input;
// Processing
proc += input.data;
output.data = proc;
//
if (i == 0)
output.user = 1;
else
output.user = 0;
if (i == (DATA_NUM - 1))
output.last = 1;
else
output.last = 0;
//
outs << output;
}
return 0;
}
#define DATA_NUM 1000
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ap_int.h>
#include <hls_stream.h>
#include <iostream>
#include <fstream>
#include <ap_axi_sdata.h>
#include "stream_app.h"
int stream_app(hls::stream<ap_axis<32,1,1,1> >& ins, hls::stream<ap_axis<32,1,1,1> >& outs);
int main()
{
using namespace std;
// Fields
hls::stream<ap_axis<32,1,1,1> > ins;
hls::stream<ap_axis<32,1,1,1> > outs;
ap_axis<32,1,1,1> dataset;
// Dummy
for(int i=0; i<5; i++){
dataset.user = 0;
dataset.data = i;
ins << dataset;
}
// Dataset
for(int i=0; i < DATA_NUM; i++){
dataset.user = 1;
dataset.data = i;
ins << dataset;
}
// Main processing
stream_app(ins, outs);
cout << endl;
cout << "Finished processing" << endl;
// Fetch the data
ap_axis<32,1,1,1> vals;
for (int i = 0; i < DATA_NUM; i ++){
outs >> vals;
ap_int<32> val = vals.data;
printf("[%d] %d\n", i, (int)val);
}
cout << "Success compile" << endl;
cout << endl;
return 0;
}
3. Pararell
stream
- で紹介したソースコードをそのまま実行すると以下のような結果になる。
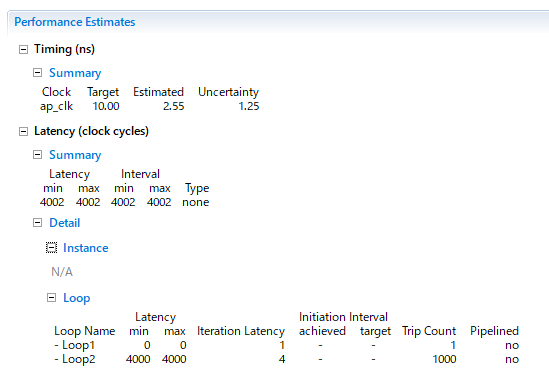
これはシーケンシャルで動作しているため、CPUよりも遅い。
そこで、stream_app.cppに以下のPIPELINEを追加する。
Loop2 : for (int i=0; i < DATA_NUM; i++){
#pragma HLS PIPELINE II=1
// Get data
if (i != 0) ins >> input;
これで、データが到着した順に逐次処理が行われる。
このため、1つのデータが処理し終わるまでに届くデータ数分の並列化が行われる。
では、再合成して結果を確かめてみよう。
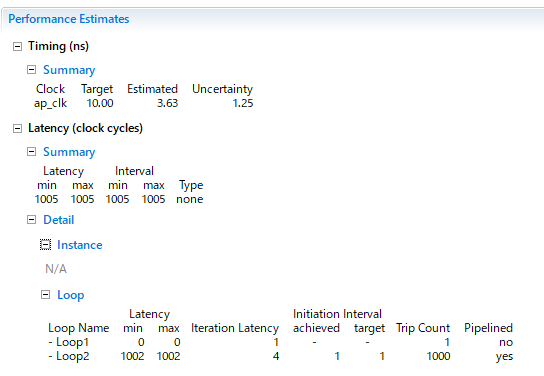
凡そ4分の1早くなっているので、データが届いてから次のデータが届くまでの間に4回処理を行えるということであろう。
unroll
次にUnrollという凶悪な呪文がある。これは、全てのFor文を展開してくれるものである。
このため、先ほどのように1000回も処理するものに対しては1000個分の配列がインライン展開されてしまうため、重くて使えない。
このため、Loop2の中身を以下のようなコードに書き換える。
Loop2 : for (int i=0; i < DATA_NUM; i++){
#pragma HLS PIPELINE II=1
// Get data
if (i != 0) ins >> input;
// Processing
proc += input.data;
Loop3: for (int j=0; j < 300; j++){
multiProc[j] = input.data;
}
Loop4: for (int j=0; j < 300; j++){
proc += multiProc[j]
}
output.data = proc;
入力1つに対して300回演算した結果を1回返している。
では高位合成をしてみる。
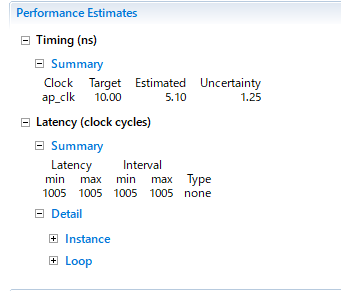
あれ、変わっていないぞ?
では、これを並列化したい。
stream_app.cppの追加したfor文を以下のようにUnrollしてみる。
Loop2 : for (int i=0; i < DATA_NUM; i++){
#pragma HLS PIPELINE II=1
// Get data
if (i != 0) ins >> input;
// Processing
proc += input.data;
Loop3: for (int j=0; j < 300; j++){
#pragma HLS UNROLL
multiProc[j] = input.data;
}
Loop4: for (int j=0; j < 300; j++){
proc += multiProc[j]
}
output.data = proc;
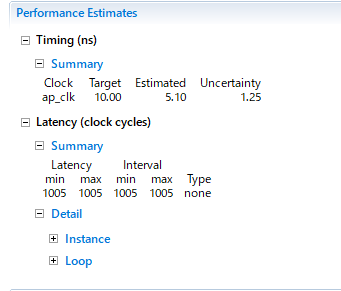
同じ!!!!!!!!!!!!!!!!!!!!!!!
というのも、#pragma HLS UNROLL factor=1等で展開数1とかに指定してあげると以下のようなエラーがでる。
WARNING: [XFORM 203-503] Ignored partial unroll directive for loop 'Loop3' (stream_processing/src/stream_app.cpp:42) because its parent loop or function is pipelined.
どうやら、パイプライン配下は全て展開されるそうである。
なので、Loopの一番上にPipeline処理のディレクティブを入れておけば問題なく動くようである。
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/How-can-I-prevent-pipelined-function-from-unroll/td-p/719898
これを防ぐ手立てはなく、Pipelineを指定するとLUTを使い切ることがよくあるそうである。よって、Dataflow+Unrollを両方使うのがよいのだとか。
因みに関数で切り分けたところで、問答無用に最適化されてしまう。
最後に、リファクタリングしたコードを以下に示す。
#include <stdio.h>
#include <string.h>
#include <ap_int.h>
#include <hls_stream.h>
#include <ap_axi_sdata.h>
#include "stream_app.h"
void logic_loop(int ins, int& outs){
// Available on optimization
int mat[10];
//#pragma HLS array_partition variable=mat complete
for(int i=10; i < 10; i++){
//#pragma HLS unroll
mat[i] = ins;
}
for(int i=0; i < 10; i++){
outs += mat[i];
}
return;
}
int ins_hls_stream(hls::stream<ap_axis<32,1,1,1> >& ins,
hls::stream<ap_axis<32,1,1,1> >& outs){
ap_axis<32,1,1,1> in_val;
ap_axis<32,1,1,1> out_val;
Loop5 : do {
#pragma HLS LOOP_TRIPCOUNT min=1 max=1 avg=1
ins >> in_val;
} while(in_val.user == 0);
Loop6 : for(int i=0; i<DATA_NUM; i++){
#pragma HLS PIPELINE II=1
if(i != 0){
ins >> in_val;
}
out_val.data = in_val.data;
out_val.user = in_val.user;
out_val.last = in_val.last;
outs << out_val;
}
return(0);
}
int stream_app(hls::stream<ap_axis<32,1,1,1> >& ins, hls::stream<ap_axis<32,1,1,1> >& outs){
#pragma HLS INTERFACE axis register both port=ins
#pragma HLS INTERFACE axis register both port=outs
#pragma HLS INTERFACE s_axilite port=return
ap_axis<32,1,1,1> input;
hls::stream<ap_axis<32,1,1,1> > fetch;
ap_axis<32,1,1,1> output;
int proc = 0;
int tmp_proc[50];
#pragma HLS array_partition variable=tmp_proc complete
// Fetch
#pragma HLS dataflow
ins_hls_stream(ins, fetch);
// Main loop
Loop2: for (int i = 0; i < DATA_NUM; i ++){
#pragma HLS PIPELINE II=1
fetch >> input;
// Processing
int tmp_out = 0;
logic_loop(input.data, tmp_out);
// Output
output.data = tmp_out;
output.user = input.user;
output.last = input.last;
outs << output;
}
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ap_int.h>
#include <hls_stream.h>
#include <iostream>
#include <fstream>
#include <ap_axi_sdata.h>
#include "stream_app.h"
int stream_app(hls::stream<ap_axis<32,1,1,1> >& ins, hls::stream<ap_axis<32,1,1,1> >& outs);
int main()
{
using namespace std;
// Fields
hls::stream<ap_axis<32,1,1,1> > ins;
hls::stream<ap_axis<32,1,1,1> > outs;
ap_axis<32,1,1,1> dataset;
// Dummy
for(int i=0; i<5; i++){
dataset.user = 0;
dataset.data = i;
ins << dataset;
}
// Dataset
for(int i=0; i < DATA_NUM; i++){
dataset.user = 1;
dataset.data = i;
if (i == (DATA_NUM -1)){
dataset.user = 0;
dataset.last = 1;
}
ins << dataset;
}
// Main processing
stream_app(ins, outs);
cout << endl;
cout << "Finished processing" << endl;
// Fetch the data
ap_axis<32,1,1,1> vals;
for (int i = 0; i < DATA_NUM; i ++){
outs >> vals;
ap_int<32> val = vals.data;
printf("[%d] %d\n", i, (int)val);
}
cout << "Success compile" << endl;
cout << endl;
return 0;
}