0. 概要
ニューラルネットワークは決定的な答えを出す。これは時に大きな問題を起こす。例えば、自動運転において安全を確認するカメラが故障しているにも関わらず、人がいないから安全だといった識別をしてしまったり等、様々である。このように現実のタスクにニューラルネットワークを適用するためには機械の答えをどのように信用するかの工夫が必要である。その工夫の1つとして「不確実性」という指標がある。これはニューラルネットワークの出力した結果が「どれ程、信用できるものなのか」を数値として提供してくれるものである。今回はこの方法について整理していきたい。
1. Bayesian Neural Networkの出力
ベイズニューラルネットワークの出力は、何らかの出力値を表す平均$\mu$、及びその出力値の不確実性を示す分散$\sigma ^2$がある。この2つの出力を得るために一般的には複数解のサンプリングを行い、確率分布を構築する。多くの場合、入力されるデータセット及び構築される確率分布は正規分布を仮定している。
一般的にニューラルネットワークの予測事後確率分布$p(y^{*}|x^{*})$を求めることは容易ではない、そこで我々は近似的な手法を用いている。
\mathbb{E}_{q} p(y^{*}|x^{*}) \approx \dfrac {1}{T}\sum ^{T}_{t=1}p_{w_{t}}p(y^{*}|x^{*})
この確率分布と平均値から計算される分散$\sigma ^2$はAleatoric uncertainty及びepistemic uncertaintyの合計である。
Var_{q}(p(y^{*}|x^{*})) = aleatoric + epistemic
ここで、
Aleatoricは偶然の不確実性を指し、いくら学習したとしても改善する見込みは少ない。これはロバスト性の指標になる。
Epistemicはモデルの不確実性を指し、学習することによって改善する見込みがある。これは精度の指標になる。
2. Aleatoric
Aleatoricは偶然の不確実性を指す。
例えば、入力データとして予期されていなかった外れ値等がこれにあたる。現実のタスクにおいては、太陽光の入射によってカメラが真っ白になってしまう等の環境ノイズも考えられるだろう。
ここで、
入力データ$x$の取り得る全ての範囲で出力$y$を得たとして、その出力値の分散が常に均一的な場合をhomoscedasticityという。
対して、入力データ$x$を動かすことによって出力される$y$の分散が不均一のものを分散不均一性、heteroscedasticityという。
2.1 heteroscedasticity
heteroscedasticityについてpure heteroscedasticity及びdiscrete heteroscedasticityについて説明する。
2.1.1 pure heteroscedasticity
例えば、所得と消費の関係性を見た時に、所得が多ければ多いほど、消費の分散は高くなると考えられる。
このことをdiscrepancy(ばらつき)が大きいといい、heteroscedasticityがあるという。
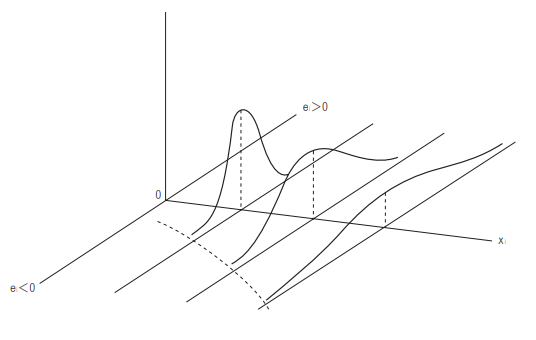
これに対応したモデルを用いると、このように、$x$が取り得るある値の時の分散のスケールを加味出来るようになる。
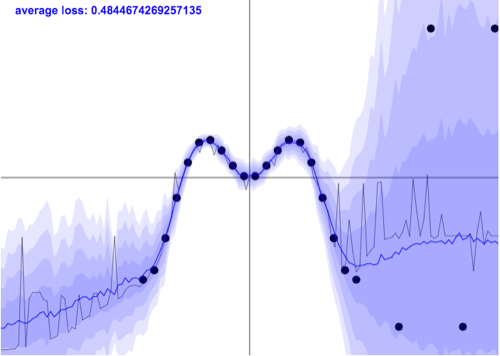
2.1.2 discrete heteroskedasticity
次に、テストの結果を基に上から下を順に集めたグループAと平均点まわりで集めたグループBで平均値と分散値を計算した時を考える。
この時、平均値は同じでも分散値は大きく異なるはずである。これをdiscrete heteroskedasticityという。
2.1.3 heteroskedasticityにおける分散の表現
換言して整理すると、入力値によってノイズの大きさが異なるということである。
よって、出力$f^{w} (x)$のサンプリングによって得られる正規分布は、入力値$x$毎に異なる分散値$g$があるということになる。
数式で表現すると以下のようになる。
y \sim N\left( f^{w} (x), g^{w} (x)^{-1} \right)
分散値は
\mathbb{L}_{NN} (\theta) = \dfrac{1}{N} \sum^{N}_{i=1}\dfrac{1}{2 \sigma (x_{i})^{2}}||y_i-f(x_i)||^{2} + \dfrac{1}{2} log \sigma (x_i)^{2}
で表現されて、
\dfrac{1}{2} log \sigma (x_i)^{2}
は$g$を示している。
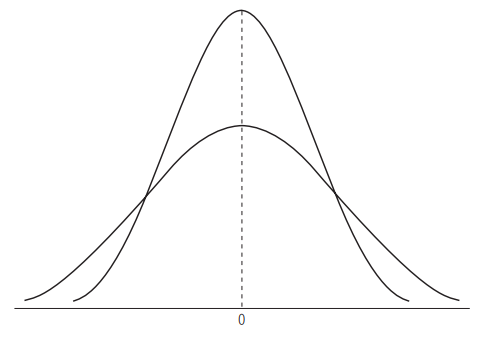
2.2 homoscedasticity
homoscedasticityはheteroscedasticityに対して、全ての入力値に対して同じ観測ノイズが含まれると想定されている。
画像からも分かる通り、殆ど均一の分散値で外れ値の分散値を上手く表現できていない。
よって、系統誤差に近く、これはモデル精度とも言い換えられ$\tau$によって表現される。
y \sim N\left( f^{w} (x), \tau^{-1} I \right)
3. Epistemic
Epistemicはモデルの不確実性を指す。
例えば、落下速度を推定するモデルが重力加速度のみを中心に構築されており、空気抵抗が抜けていた場合には正しい結果を得られない。
この場合は、モデルに空気抵抗の項を導入すればよい。これは、モデルの表現力が足りていないともいえるし、人間の認識力不足ともいえる。
一般的に認識不足に起因する場合はV&V等によってこの問題が解決されることが多い。
なので、未学習データに対する識別と不確実性の関係を語る時に重要な指標。
4. 分散値の計算
一般的に分散の計算は以下の式によって行われる。
Var_{q}(p(y^{*}|x^{*})) = \mathbb{E}_{q} [(y-E[y])^2]\\
= \mathbb{E}_{q} [yy^{T}]-\mathbb{E}_{q}[Y]\mathbb{E}_{q}[Y]^{T}
馴染みのない書き方のため、BNNの出力値(平均値)$\overline{y}=y=f(x)$、及びラベルを$t$として書き換えると以下のようになる。
Var_{q}(p(y^{*}|x^{*})) = \mathbb{E} [(t- \overline{y})^{2}]\\
=\mathbb{E} [t^{2}] - \overline{y}^{2}\\
要するに正解値と予測値(平均)との2乗誤差である。
これを
Var_{q}(p(y^{*}|x^{*})) = aleatoric + epistemic
aleatoric及びepistemicに書き直すと以下のようになる。
Var_{q}(p(y^{*}|x^{*})) = \mathbb{E}_{q} [(y-E[y])^2] = \mathbb{E}_{q} [yy^{T}]-\mathbb{E}_{q}[Y]\mathbb{E}_{q}[Y]^{T}\\
= \int_{\Omega} [diag (\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}])-\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}]\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}]^{T}]q_{\theta} (w) dw \\
+ \int_{\Omega} [ \mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}] - \mathbb{E}_{p(y^{*}|x^{*})}(y^{*}) ] [ \mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}] - \mathbb{E}_{p(y^{*}|x^{*})}(y^{*}) ]^{T} q_{\theta} (w) dw
すなわち、
aleatoric = \int_{\Omega} [diag (\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}])-\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}]\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}]^{T}]q_{\theta} (w) dw, \\
epistemic = \int_{\Omega} [ \mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}] - \mathbb{E}_{p(y^{*}|x^{*})}(y^{*}) ] [ \mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}] - \mathbb{E}_{p(y^{*}|x^{*})}(y^{*}) ]^{T} q_{\theta} (w) dw, \\
Var_{q}(p(y^{*}|x^{*})) = aleatoric + epistemic
となる。
ここで
・$\Omega$は$w$が取り得る全ての空間、すなわち$\Omega \in w$
・diagは対角行列を指す。重みの分散共分散行列から分散値を抽出するために用いられている
・$E[=y^{*}]$は入力$x^{*}$の出力結果を示す。予測事後分布$p(y^{*}|x^{*}, w)$、変分予測事後分布$q(y^{*}|x^{*}, w)$に基づいて$y^{*}$を得ている
・$q(w)$は計算することが何回である事後分布$p(w|D)$の近似分布である
4.1. Aleatoricの不確実性
Aleatoricの不確実性とはデータセットからの出力の変動値を得ることである。式は以下である。
aleatoric = \int_{\Omega} [diag (\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}])-\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}]\mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}]^{T}]q_{\theta} (w) dw, \\
Aleatoricにはhomoscedasticity、heteroscedasticityの2つがあった。前者は平均値を得ることで均一な不確実性を得る。後者は入力1つ1つに計算すれば良いということになる。
これを識別タスクに適用する場合、
aleatoric = \dfrac {1}{T}\sum ^{T}_{t=1} diag(\hat{p}_t) - \hat{p}_t \hat{p}_t^{T}
と表現することが出来る。$T$はサンプリングの数を示す。
また、この時、$\hat{p}_t$は
\hat{p}_t = Softmax(f^{\hat{w}_t} (x^{*}))
Softmaxの出力(確率分布)である。
これによって得られた対角ベクトルで、ひときわ大きな値がある場合は、そのクラスに誤差を大きくする何らかの不適切なデータセットがあると考えられる。
4.2. Epistemicの不確実性
これはモデルに入力を与えた時の出力結果の変動を平均で得ている。
epistemic = \int_{\Omega} [ \mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}] - \mathbb{E}_{p(y^{*}|x^{*})}(y^{*}) ] [ \mathbb{E}_{p(y^{*}|x^{*}, w)}[y^{*}] - \mathbb{E}_{p(y^{*}|x^{*})}(y^{*}) ]^{T} q_{\theta} (w) dw, \\
これも同様に識別タスクに適用する場合、
epistemic = \sigma ^{2} + \dfrac {1}{T}\sum ^{T}_{t=1} (\hat{p}_t - \overline{p})(\hat{p}_t - \overline{p})^{T}
と表現することができる。$T$はサンプリングの数を示す。$\sigma ^{2}$は$\tau^{-1}$と同等の処理を表す。
ここで、出力値はサンプリングされたものを平均化して以下のように与える。
\overline{p} = \dfrac {1}{T}\sum ^{T}_{t=1} \hat{p}_t
ここで、$\hat{p}_t$はSoftmaxの値とする。
これはある入力の時に出力をサンプリングした結果として、どれくらい値が変動するかをデータセット単位で見ている。
値が大きく変動するときは、そのデータセットに対して適切なモデルを構築出来ていないといえる。
4.3. Aleatoric (Heteroscedastic) and Epistemicの不確実性
Yarin galは以下の式によってAleatoric and Epistemicの不確実性を捉えられるといっている
Var(y) \approx \dfrac{1}{T} \sum^{T}_{t=1} \hat y^{2}_{t} - (\dfrac{1}{T}\sum^{T}_{t=1} \hat y_{t})^{2} + \sum^{T}_{t=1} \hat \sigma^{2}_{t}
ここで、
\sum^{T}_{t=1} \hat \sigma^{2}_{t}
はAleartoricを示しており、$\sigma^2$は予測値の空間における不確実性を提供している。