TL;DR
- KubernetesでDockerアプリケーションの開発環境を運用できる
- telepresenceを使い、開発したいコンテナだけをローカルで動かせる
- コンテナをローカルで動かしつつ、Kubernetes内のネットワークに透過的にアクセスできる
- 開発時以外は、Kubernetesクラスタ内で通常のコンテナが起動している
- Auto ScalingやALBの集約によって低コストで運用できる
インフラは全てTerraformでコードとして管理しているので、以下のリポジトリを参考に。
https://github.com/hareku/terraform-kubernetes-development
全体のアーキテクチャ図
HTTP / HTTPSアクセスの流れ

開発時の図
※Podを以下のような、Nginx,Go,MySQLの3コンテナとする。

Telepresenceによる開発時の図

背景
組織の背景として、10~20ほどのDockerアプリケーションを運用しており、それらは全て各エンジニアに与えられたEC2インスタンス上で開発されている。
しかし開発したいアプリケーションの数が増えるにつれ、以下のような課題が出てきた。
- EC2インスタンスのリソース不足
- メモリ不足やEBSの空きストレージ不足、CPUの高負荷など
- Chefのプロビジョニングとの非整合によるエラー
- ほとんどのプロジェクトはChefが設定するDNSや環境変数に依存している
- ファイルがEC2上にある上での弊害
- SSHFSでのマウントには遅延があるため、ローカルからのGitなどはまともに扱えない
- 開発プロジェクトの自動更新
- 今までは依存している他プロジェクトを
git pullして最新にする必要があった
- 今までは依存している他プロジェクトを
- デザイナーの開発環境への敷居
- インスタンスへのSSHや各dockerコマンドなどを意識しなければならない
これらの課題を解決するため、Kubernetesで自律的な開発環境を構築することになった。
ちなみに移行前の開発環境は以下のようになっている。

なぜ全てローカルで開発しないのか
**「パブリックにアクセスできるIPが必要」「プロジェクト数が多くリソース不足」**という点にある。
新しいプロジェクトではDockerを用いているが、それ以前に作られた非Dockerプロジェクトの数は多く、そしてそれらはマイクロサービスではないがマイクロサービスのような複雑な依存性を持っている。より具体的には、複数ドメインにまたがる通信やRewriteが数多く存在している。
また全ての非DockerプロジェクトをDocker化し、1つのローカルマシンで動かすことは、リソース的にもコストパフォーマンス的にも妥当なものではない。そのため非Dockerプロジェクトが動いているEC2インスタンス上からアクセスするためのパブリックなIPが必要ということになる。
各開発環境へのHTTP/HTTPSアクセスは全て1つのApplication Load Balancerを通しており、証明書なども全てAWSのリソースを使用している。
Telepresenceによるローカルでの開発

Telepresenceを使うことにより、Kubernetesクラスタにある**DeplyomentのPod中の1つのコンテナをローカルで起動することができる。**また同じPod内のコンテナや別Podからもローカルのコンテナと透過的に相互アクセスできる。
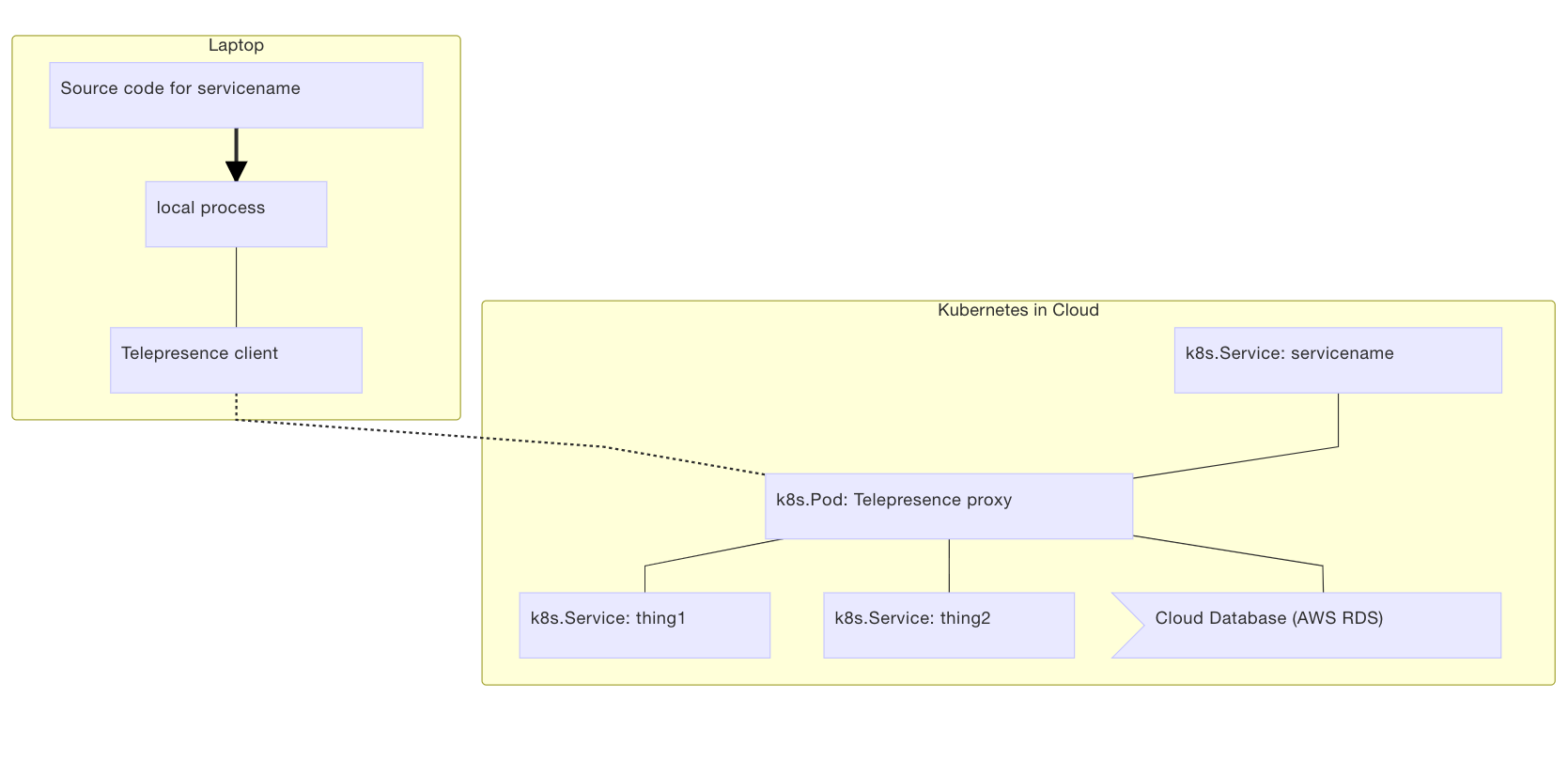
Telepresenceの内部実装
Telepresenceの内部はkubectl port-forwardを使っているだけである。要するにHTTPSトンネリングによってKubernetesのDeploymentやPodにポートフォワードする機能のため、例えば会社のネットワークにポート制限などがあってもHTTPSさえ通れば問題ない。
またPodの環境変数も全てローカルのコンテナにきちんと渡されるため、そのあたりも意識しなくて良い。例えばmy-appというDeploymentのGoコンテナだけをローカルで起動したい場合、以下のようなコマンドを打つだけである。
telepresence --swap-deployment my-app:go --docker-run --rm -it -v $(pwd):/var/www go:latest
もちろんDockerを使わず、ローカルのGoプロセスを動かすこともできる。
telepresence --swap-deployment my-app:go --method inject-tcp --expose 8080 --run go run main.go
このコマンドで、Deployment(my-app)のReplicasは0になり、そしてTelepresenceが代わりのDeploymentを作成し、そのDeploymentの中のGoコンテナはローカルのものである。ちなみにMacBookはスリープしてもDockerのコンテナは終了しないため、閉じていても普通に動き続ける。
exitすれば代わりのDeploymentは削除され、そして元のDeployment(my-app)のReplicas値が戻る。
そのあたりを含めた内部的な実装はTelepresenceの「How it works」で紹介されている。WindowsもWindows Subsystem for LinuxをインストールすればTelepresenceを使える。そちらもドキュメントの「Windows Support」を参照して欲しい。
Kubernetesによる開発環境の構築
ここでは具体的な開発環境の構築方法について解説していく。
Amazon EKSの選択と料金

Kubernetesの基盤として、Amazon EKSを選択している。これは既存の開発用DBやセキュリティグループを含めた様々な資産を活かすためである。
Amazon EKSではコントロールプレーンをマネージドで提供し、料金は東京リージョンで1時間あたり$0.20、月に$144となっている。その$144に加えて、リソースを動かすためのインスタンスやALBの料金が上乗せされる。ただしインスタンスに関してはスポットインスタンスを用いて安価に運用できる。
料金はどれほどのインスタンスを起動させるかで非常にブレてくるが、m4.2xlarge(8vCPU、32GBメモリ、$0.1331/h)を1日12時間を6台と計算すると、およそ月$287である。それにEKSやALB、EFSを加えるとおよそ合計で月$500になるが、組織的な開発環境としては十分現実的なコストとして収まっている。
スポットインスタンスの注意点
Cluster AutoscalerはまだAWSのスポットフリートに対応しておらず、単一のインスタンスタイプを選択しなければならない。しかしm5やt3などの次世代のインスタンスタイプだとAWS側で余っている量が少なく、スポットリクエストがcapacity not availableエラーになってスケールアウトできない事態に陥りやすい。
対策として、m4などの旧世代のインスタンスタイプを利用する。m4などでも容量不足によるスケールアウトエラーが出てくる可能性はあるが、今のところ遭遇していないので良しとしている。
開発環境の起動はDashboardから
Kubernetesは公式にDashboardを提供しており、開発環境の起動もここから行う。起動はとても簡単で、起動したいプロジェクトのReplica数を0から1にするだけである。
ログイン方式は、Deploymentのスケールのみが可能なServiceAccountのトークンを配布する手段を取っている。
開発環境の自動スケールイン
開発環境は勤務時間外に使われることはないため、CronJobにて一斉にDeploymentのReplica数を0にしている。もし指定の時刻に自動で起動したいのであれば、hjacobs/kube-downscalerで対応できる。
Terraformによるインフラの管理

今回のインフラは全てTerraformで管理している。
https://github.com/hareku/terraform-kubernetes-development
また各エコシステムや開発環境のデプロイはHelmを用いて、Terraform上から操作している。TerraformのHelm ProvidierはTerraform上のリソース値をvalueに直接渡せるため、手動で値を変えたりすることがない。
各プロジェクトの開発環境は、全てHelm Chartで管理している。Chartに関しては作るのが面倒であるが、TerraformのKubernetes ProvidierがIngressなどのbetaバージョンに対応しておらず、またメンテナ不足のため、今後もGA以外は実装しない方針を執っている。そのため現状はHelm Chartで管理する手段しかない。
Kubernetesの周辺システム
今回用いたKubernetesの各周辺システムを紹介する。
-
Kubernetes Dashboard
- ダッシュボード上から各プロジェクトを起動する
- Deploymentのスケールのみが可能なServiceAccountのトークンを配布している
-
kube2iam
- Kubernetes上で動作する各Podに異なるIAMロールを付与する
-
ALB Ingress Controller
- Ingressリソースの作成を検知してALBを作成する
-
jakubkulhan/ingress-merge
- 各プロジェクトのIngressを1つのIngressにまとめる
-
External DNS
- 各ServiceやIngressのホスト名からRoute53にレコードを自動登録する
-
efs-provisioner
- Amazon EFSをKubernetes上で永続ボリュームとして扱えるようにする
-
Cluster Autoscaler
- 需要に応じてノードであるEC2インスタンス数を調整する
-
EC2 Spot Termination Notice Handler
- スポットインスタンスの監視とdrain処理をする
まとめ
まだ完全に移行できている訳ではないため、これから何らかの問題が出てくるかも知れない。
細かい部分は省略しているため、何か疑問点などあればコメント欄やTwitter(@hareku908)まで。