はじめに
みなさん、データ分析はお好きですか?
初めまして!DMM WEBCAMPでメンターをしている@haraso_1130です。
突然ですが、下の画像を見てください。

なんと東京都23区内の物件で5DK8万円!?
23区内なら平気でワンルーム月8万とかしますよね...
この物件は自分が
**「Python」**を用いて
**「スクレイピング」**によってデータを収集し
**「機械学習」**でデータ分析を行なった結果
発見することができた物件です。
この記事は、(基本的に)コピペだけで実際にデータ分析を行いデータ分析を好きになってもらうための記事です。
つまりふわっと**「なんかすごいことができる!」**くらいの感想を持ってもらう事を目標にしています。
なので読んでいて「何言ってるかわかんねーな」的なところがあったら「著者の説明が下手なだけ」と思ってガンガン進んで行ってください。
想定読者としては以下のように考えています。
・データ分析に興味がある人
・データ分析を敬遠している人
・その他の人
以上から**コードの解説は深く行わず、「今どういうことをどういう理由でやっているのか」**を中心に解説していきます。
また、「コピペで動かす」とありますが、読むだけでもデータ分析の面白さがわかるように工夫したつもりです!
ただの宣伝ですが、この記事を読んで「データ分析をしてみたい!」と思ってくださった方は自分のブログで独学方法などを書いているので参考にしてみてください。
この記事でやること
・Pythonの環境構築からスクレイピング、機械学習の実装まで
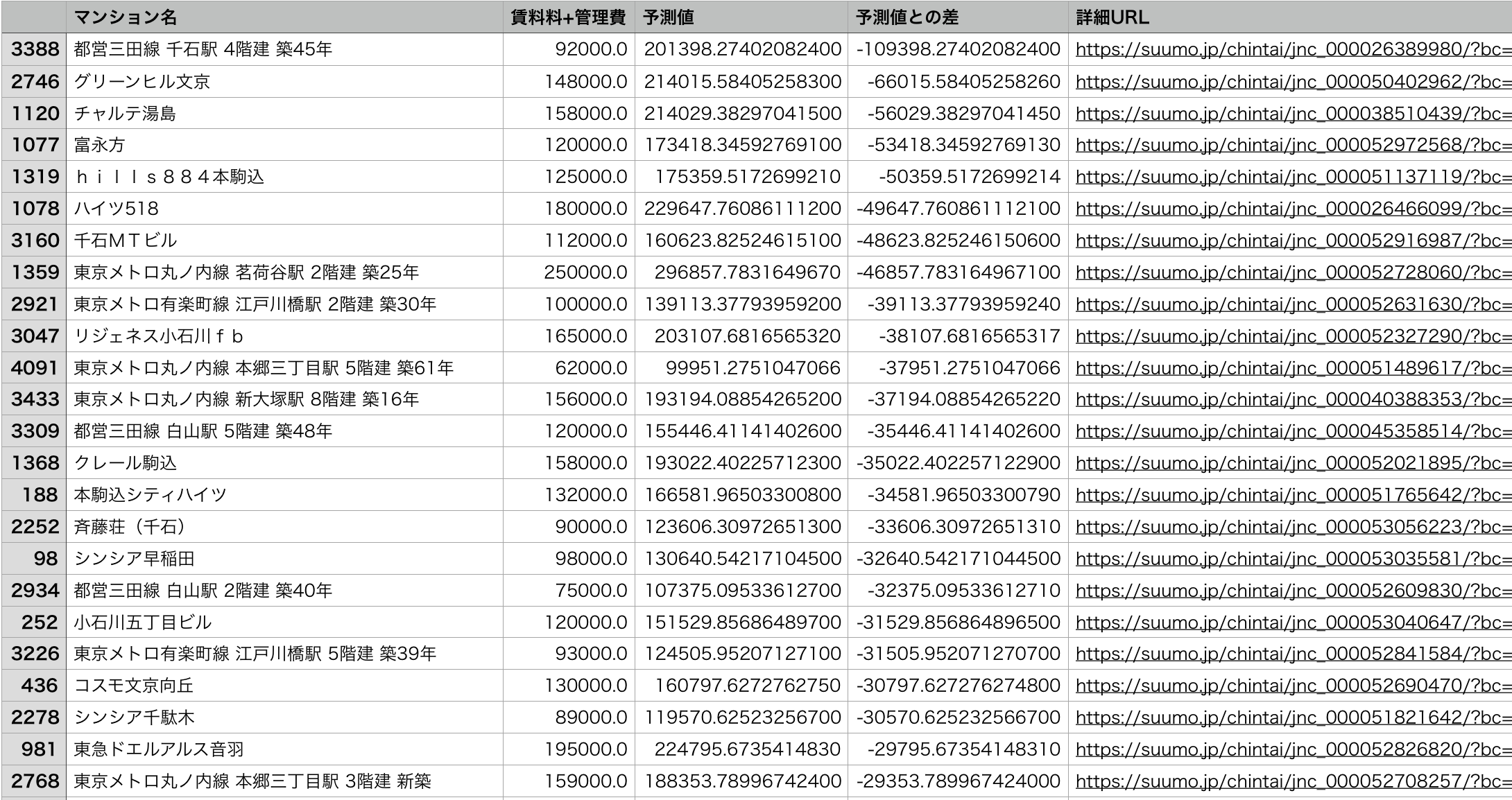
・以下の画像のようなお得物件探索表を作成:作成したモデルを使ってお得物件を発見しましょう。
この記事でやらないこと
・コードの詳細な説明
・機械学習アルゴリズムの説明
この記事はあくまでデータ分析を好きなってもらうための記事です。
小難しい話はできるだけ省略していきます!
(プログラミング学習って「理論・基礎→実践」よりも「実践→理論・基礎」の方が圧倒的に効率よく学習できる気がします...)
自分の環境
macOS High Sierra ver10.13.6 (めんどくさがらずにアプデしろよ)
python3.7.3
Jupyter lab
注意
記事のタイトルに**「コピペで動く」と書いていますが、何人かの知人に試してもらったところJupyter Notebook or lab**ではほぼ間違えなく動作するはずです!※2019/12/17時点
もし動かなければ教えてください...
また、動かない場合、その理由としてライブラリが入ってない可能性が一番高いです。
その都度、conda installでインストールしてください。
目次
| 目次 |
|---|
| 全体の流れ |
| 環境構築 |
| スクレイピング |
| データ分析 |
| お得物件の発見 |
| 実は... |
| 終わりに |
全体の流れ
まず全体の流れに付いて確認しましょう。
この記事では
1.コードを実行するための環境構築
2.スクレイピングを用いて自動で大量の情報を取得
3.取得した情報を元に機械学習モデルを作成
4.作成したモデルを用いて住宅価格を予測
5.予測値と実際の価格を比較してお得な物件を見つける。
という流れです。
モデルによる予測値と言われてもあまりピンとこないと思いまが、それは後述の機械学習パートで説明するので大丈夫です!
環境構築
先ほども説明しましたが、この記事のコードは全てJupyterでの実装を想定しています。
ここではJupyter labの導入方法について紹介します。
まず以下のリンクからAnacondaをインストールします。
【https://www.anaconda.com/distribution/】

その後
windowsの方
【https://www.python.jp/install/anaconda/windows/install.html 】
macの方
【https://www.python.jp/install/anaconda/macos/install.html 】
を参照してAnacondaのインストールを完了してください。
そして最近のAnacondaには元からjupyter labが入っています。
$ jupyter lab
windowsの方はコマンドプロンプトから、macのかたはターミナルから上記のコードを実行してください。
また、そもそもAnacondaが入っている方は
$ conda install -c conda-forge jupyterlab
$ jupyter lab
で大丈夫です。
これで環境構築は終わりです。
お手軽すぎる...!
適当にデスクトップにフォルダを作成してそこでnotebookを作成しましょう。
スクレイピング編
さて、そもそも「スクレイピング」とはなんでしょうか?
wikipediaさんによると
ウェブスクレイピングはWWWから自動的に情報を収集する処理に他ならない。
つまり**「インターネットから情報を自動で収集する」**、ということですね。(そのまんますぎる)
今回の分析では、何千、場合によっては何万といった賃貸物件のデータを利用するわけですが、1つの物件に対して
・物件名
・家賃
・広さ
・間取り
・立地(最寄り駅、最寄り駅までの距離、詳細な住所)
etc...
これを手動でExcelに何千回、何万回と打ち込んでいく...、考えただけでもいやになりますよね。
そこでプログラミングで一気にデータを集めます。
ここで一つ大事な注意があります。
スクレイピングする前には必ずそのサイトの利用規約を確認してください。
スクレイピングは著作権やサーバーへの不可等の問題があり、サイトによっては禁止されています。
幸いSUUMO利用規約には
「ユーザーは、本サイトを通じて提供されるすべてのコンテンツについて、当社の事前の承諾なく著作権法で定めるユーザー個人の私的利用の範囲を超える使用をしてはならないものとします。」
とだけ書いてあり、今回は私的利用なので大丈夫でしょう。
jupyterを開いて、
# url(ここにURLを入れてください)
url = ''
のシングルクォーテーションの間に東京23区内で好きな区のurlを入れてコードを実行してください。
以下のリンクから23区を選択する画面へ飛べるようになっています。
【https://suumo.jp/chintai/tokyo/city/ 】
例えば文京区ならhttps://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&pc=50
データの収集にはかなり時間がかかるので寝る前に走らせる事をオススメします。
※追記(2019/12/29)
現在「おすすめ順」だと動かないケースを確認しています。
対症療法的な対策ですが「新着順」でソートすると動くようです。
根本的な原因がわかり次第また更新します。
なお、このコードは東京23区だけでなく、東京以外の情報も取得することが可能です。(試してみたところ岡山県のデータは取得できました)しかし、この記事の後半のデータ分析パートでは東京都23区のデータを想定してコーディングしているため、しばしばコピペだけでは動作しないことがあります。
from bs4 import BeautifulSoup
import urllib3
import re
import requests
import time
import pandas as pd
from pandas import Series, DataFrame
# URL(ここにURLを入れてください)
url = ''
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c)
summary = soup.find("div",{'id':'js-bukkenList'})
body = soup.find("body")
pages = body.find_all("div",{'class':'pagination pagination_set-nav'})
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
pages_split0 = pages_split[0]
pages_split1 = pages_split0[-3:]
pages_split2 = pages_split1.replace('>','')
pages_split3 = int(pages_split2)
urls = []
urls.append(url)
for i in range(pages_split3-1):
pg = str(i+2)
url_page = url + '&page=' + pg
urls.append(url_page)
names = []
addresses = []
locations0 = []
locations1 = []
locations2 = []
ages = []
heights = []
floors = []
rent = []
admin = []
others = []
floor_plans = []
areas = []
detail_urls = []
for url in urls:
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c)
summary = soup.find("div",{'id':'js-bukkenList'})
apartments = summary.find_all("div",{'class':'cassetteitem'})
for apartment in apartments:
room_number = len(apartment.find_all('tbody'))
name = apartment.find('div', class_='cassetteitem_content-title').text
address = apartment.find('li', class_='cassetteitem_detail-col1').text
for i in range(room_number):
names.append(name)
addresses.append(address)
sublocation = apartment.find('li', class_='cassetteitem_detail-col2')
cols = sublocation.find_all('div')
for i in range(len(cols)):
text = cols[i].find(text=True)
for j in range(room_number):
if i == 0:
locations0.append(text)
elif i == 1:
locations1.append(text)
elif i == 2:
locations2.append(text)
age_and_height = apartment.find('li', class_='cassetteitem_detail-col3')
age = age_and_height('div')[0].text
height = age_and_height('div')[1].text
for i in range(room_number):
ages.append(age)
heights.append(height)
table = apartment.find('table')
rows = []
rows.append(table.find_all('tr'))
data = []
for row in rows:
for tr in row:
cols = tr.find_all('td')
if len(cols) != 0:
_floor = cols[2].text
_floor = re.sub('[\r\n\t]', '', _floor)
_rent_cell = cols[3].find('ul').find_all('li')
_rent = _rent_cell[0].find('span').text
_admin = _rent_cell[1].find('span').text
_deposit_cell = cols[4].find('ul').find_all('li')
_deposit = _deposit_cell[0].find('span').text
_reikin = _deposit_cell[1].find('span').text
_others = _deposit + '/' + _reikin
_floor_cell = cols[5].find('ul').find_all('li')
_floor_plan = _floor_cell[0].find('span').text
_area = _floor_cell[1].find('span').text
_detail_url = cols[8].find('a')['href']
_detail_url = 'https://suumo.jp' + _detail_url
text = [_floor, _rent, _admin, _others, _floor_plan, _area, _detail_url]
data.append(text)
for row in data:
floors.append(row[0])
rent.append(row[1])
admin.append(row[2])
others.append(row[3])
floor_plans.append(row[4])
areas.append(row[5])
detail_urls.append(row[6])
time.sleep(3)
names = Series(names)
addresses = Series(addresses)
locations0 = Series(locations0)
locations1 = Series(locations1)
locations2 = Series(locations2)
ages = Series(ages)
heights = Series(heights)
floors = Series(floors)
rent = Series(rent)
admin = Series(admin)
others = Series(others)
floor_plans = Series(floor_plans)
areas = Series(areas)
detail_urls = Series(detail_urls)
suumo_df = pd.concat([names, addresses, locations0, locations1, locations2, ages, heights, floors, rent, admin, others, floor_plans, areas, detail_urls], axis=1)
suumo_df.columns=['マンション名','住所','立地1','立地2','立地3','築年数','建物の高さ','階層','賃料料','管理費', '敷/礼/保証/敷引,償却','間取り','専有面積', '詳細URL']
suumo_df.to_csv('suumo.csv', sep = '\t', encoding='utf-16', header=True, index=False)
10秒くらい経ってもエラーを吐かなければ成功しています。気長に待ちましょう。
このコードが何をやっているか、説明します。
ほとんどのWebページはHTMLという言語によって作成されています。
ではSUUMOのWebサイトの構造をChromeの検証ツールを利用して確認見てみましょう。
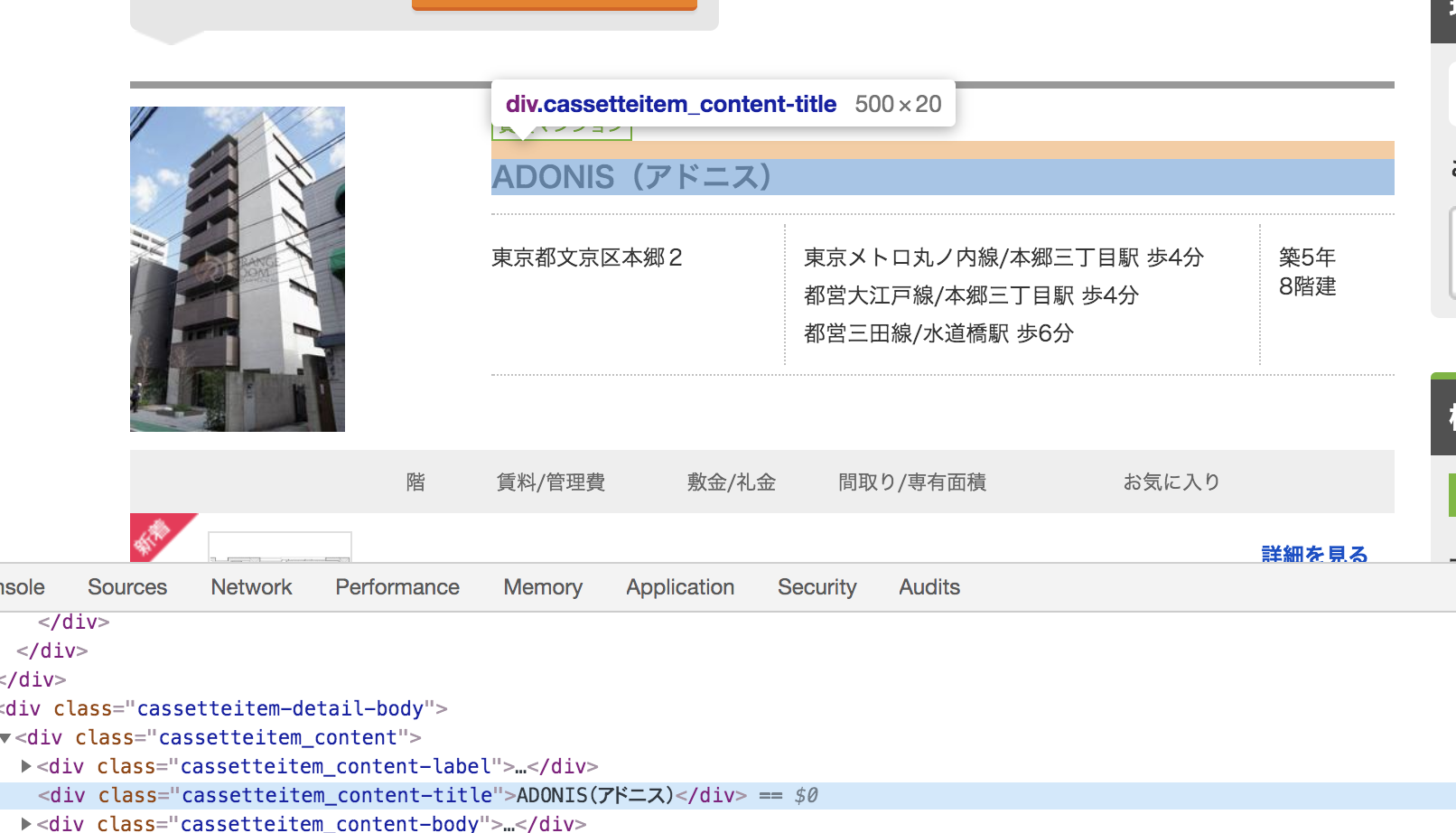
以上を見てみると賃貸の名前にはcassetteitem_content-titleという目印が付いていることがわかります。
スクレイピングではこのようなHTMLに付いている目印の情報を利用してデータを取得しています。
なお、本当は東京の賃貸情報全てのデータを取得したいのですがとてつもない時間がかかってしまうため、今回は一区のみに絞って分析を行っていきます。
データ分析編
おはようございます。
データが取得できていれば、スクレイピングを行ったノートブックと同じディレクトリにsuumo.csvというファイルができているはずです。
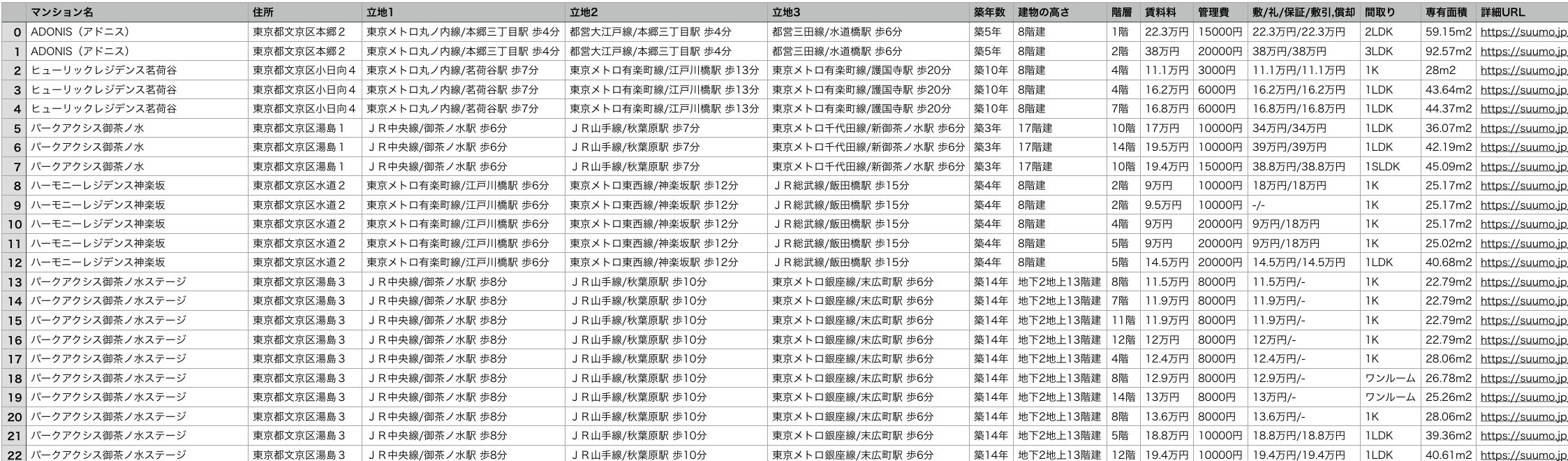
データは上のようになっています。
自分が初めて自分で大きなデータの取得に成功した時は**「おおおおおおお!!!すごい!!!」**と感動した記憶がありますが、皆さんはどうでしょうか。
このデータを用いてデータ分析を行っていくのですが、その前に機械学習モデルについて基礎的な概念を少し説明します。
教師あり学習
今回行う学習は教師あり学習と言われる学習方法(データ分析方法)です。
Wikipediaによると
事前に与えられたデータをいわば「例題(=先生からの助言)」とみなして、それをガイドに学習(=データへの何らかのフィッティング)を行うところからこの名がある。
とのことです。いまいちピンとこないので具体例を考えてみましょう。
今回は賃貸情報からその賃貸価格を予測するモデルを作成します。
私たちは家賃に関して一般的に以下のような知識を持っています。
面積が広い方が家賃が高い
駅に近いほど家賃が高い
築年数が小さいほど家賃が高い
これらの知識を持つことができている理由は、そのような事例を知っているからに他なりません。
またこれらの知識からある程度家賃を予測することができます。
これを機械にやらせようというのが機械学習です。
沢山のデータを機械に学習させ、面積、駅までの距離、築年数などから家賃を予測値として出力し、更にその予測値と実際の家賃(教師データ)の差が小さくなるように家賃を予測します。
また用語として、
家賃のような予測値として出力する値を目的変数
面積や築年数など、目的変数を特徴付ける情報を特徴量
と呼びます。
過学習
機械学習で一番の困難はこの過学習です。
過学習とは**「あるデータに過剰に適合してしまうこと」**です。
家賃を面積で予測するモデルを作成したとします。以下の画像はそのイメージです。
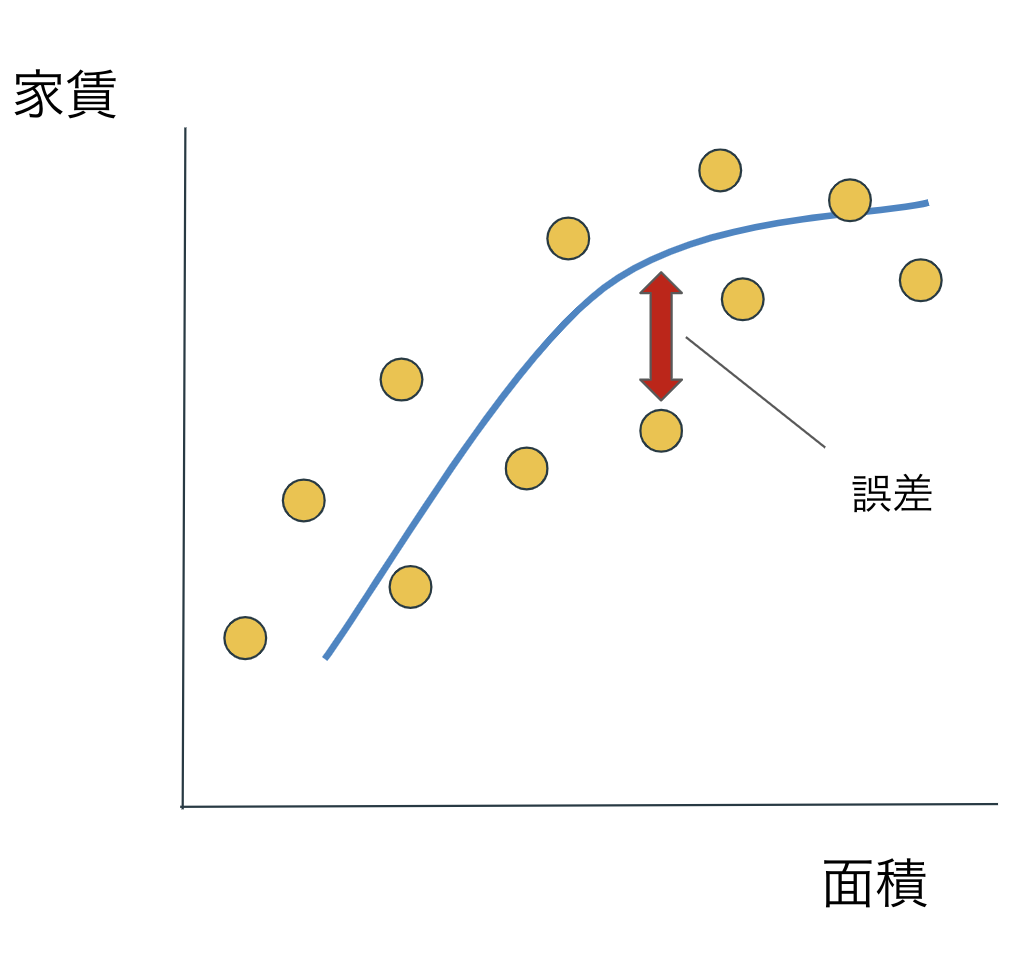
この誤差を更に小さくするために、モデルを複雑化させてみましょう。
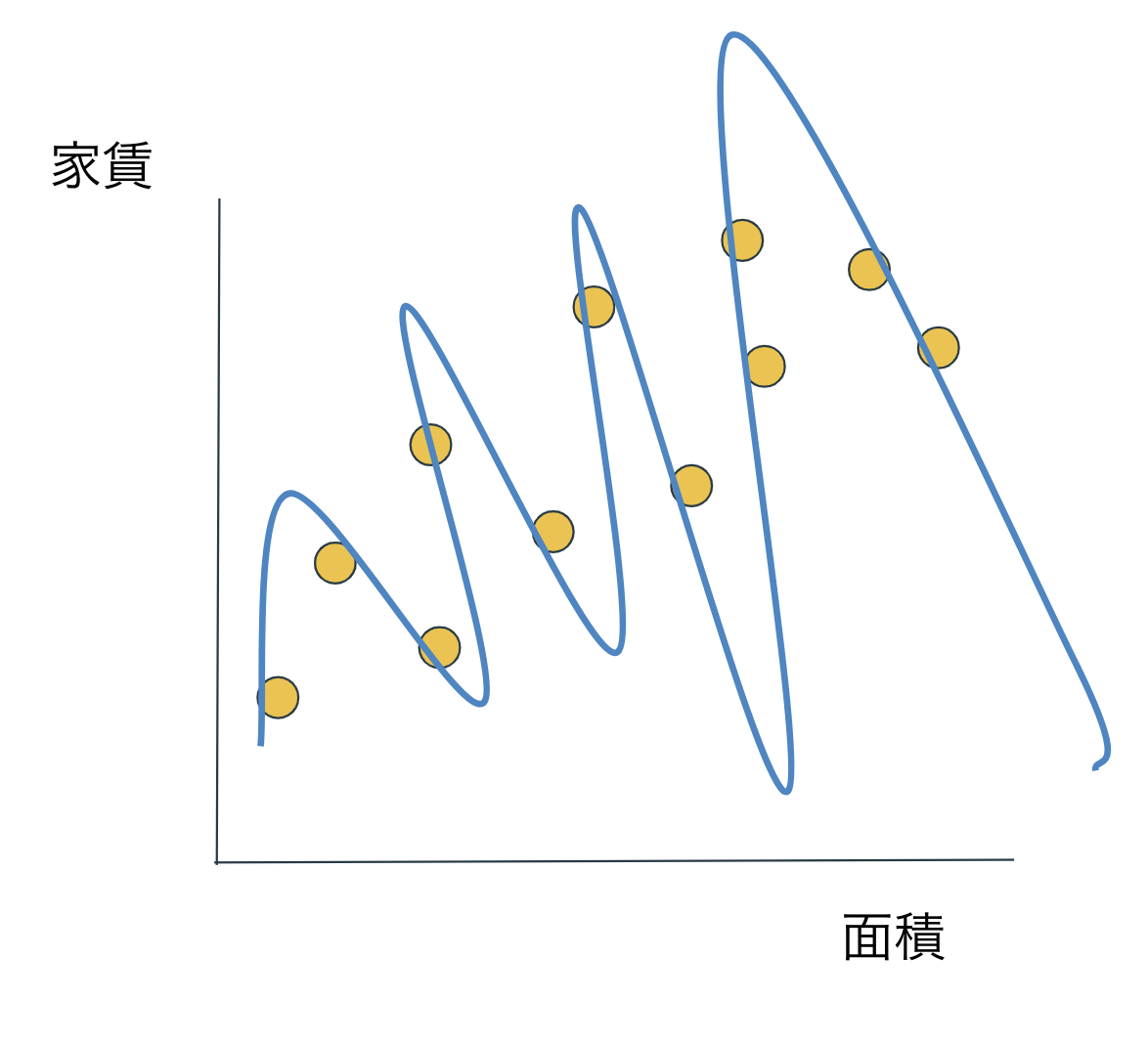
すごい!家賃を完璧に精度100%で予測できている!!!!...と喜べないんです。
このモデルを用いて、同じような分布をしている他のデータに対して当てはめてみましょう。
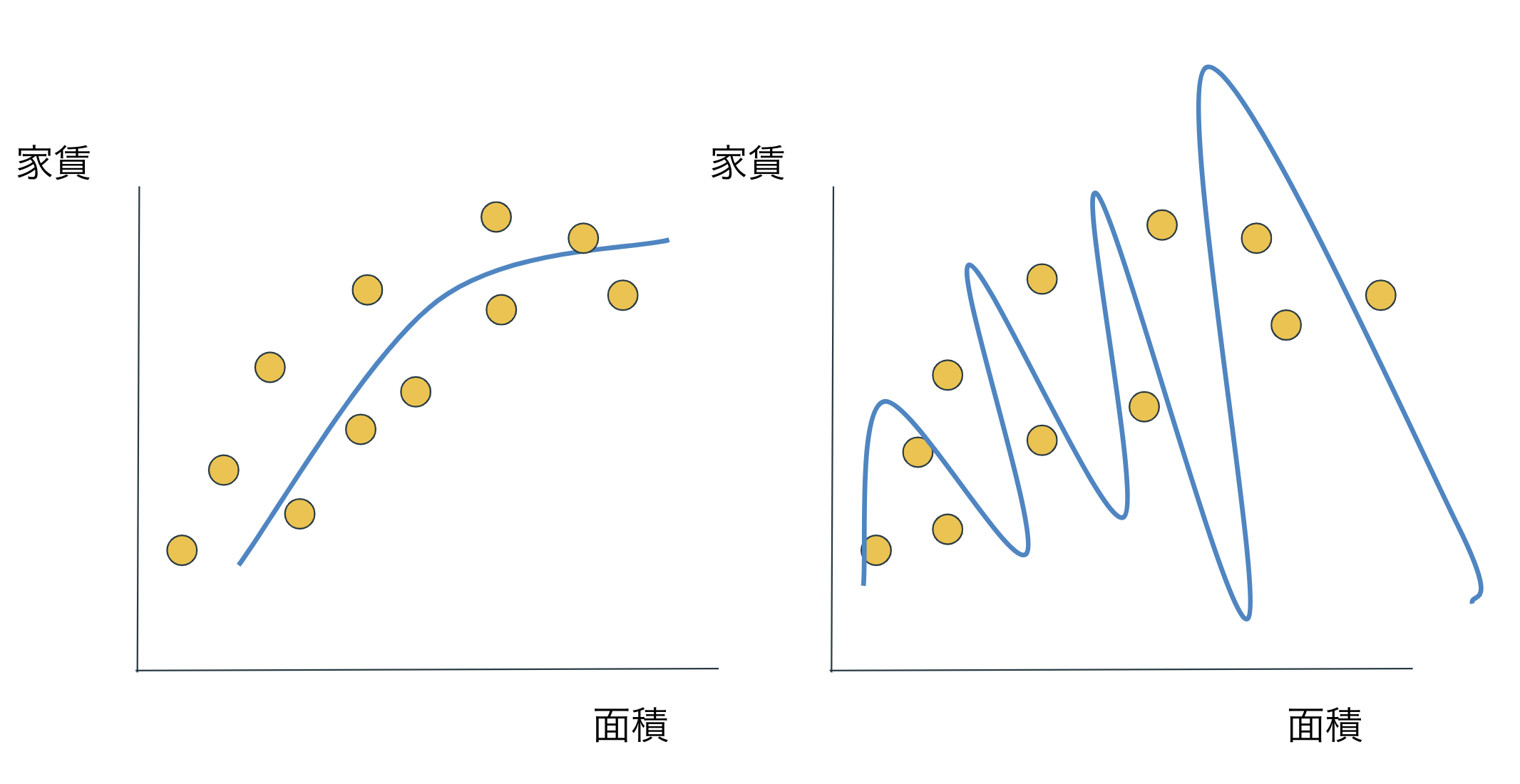
左の単純なモデルは同じくらいの性能を誇っていますが、右の複雑なモデルは明らかに予測に失敗しています。
機械学習の目的は一般的に未知のデータセットに対して最も性能がよいモデルを作ることです。
またこの未知のデータセットに対するモデルの性能のことを汎化性能と呼びます。
それではどのようにして汎化性能が高いモデルを作成するのでしょうか。
一番簡単な方法は下の画像のようにデータを分割することです。
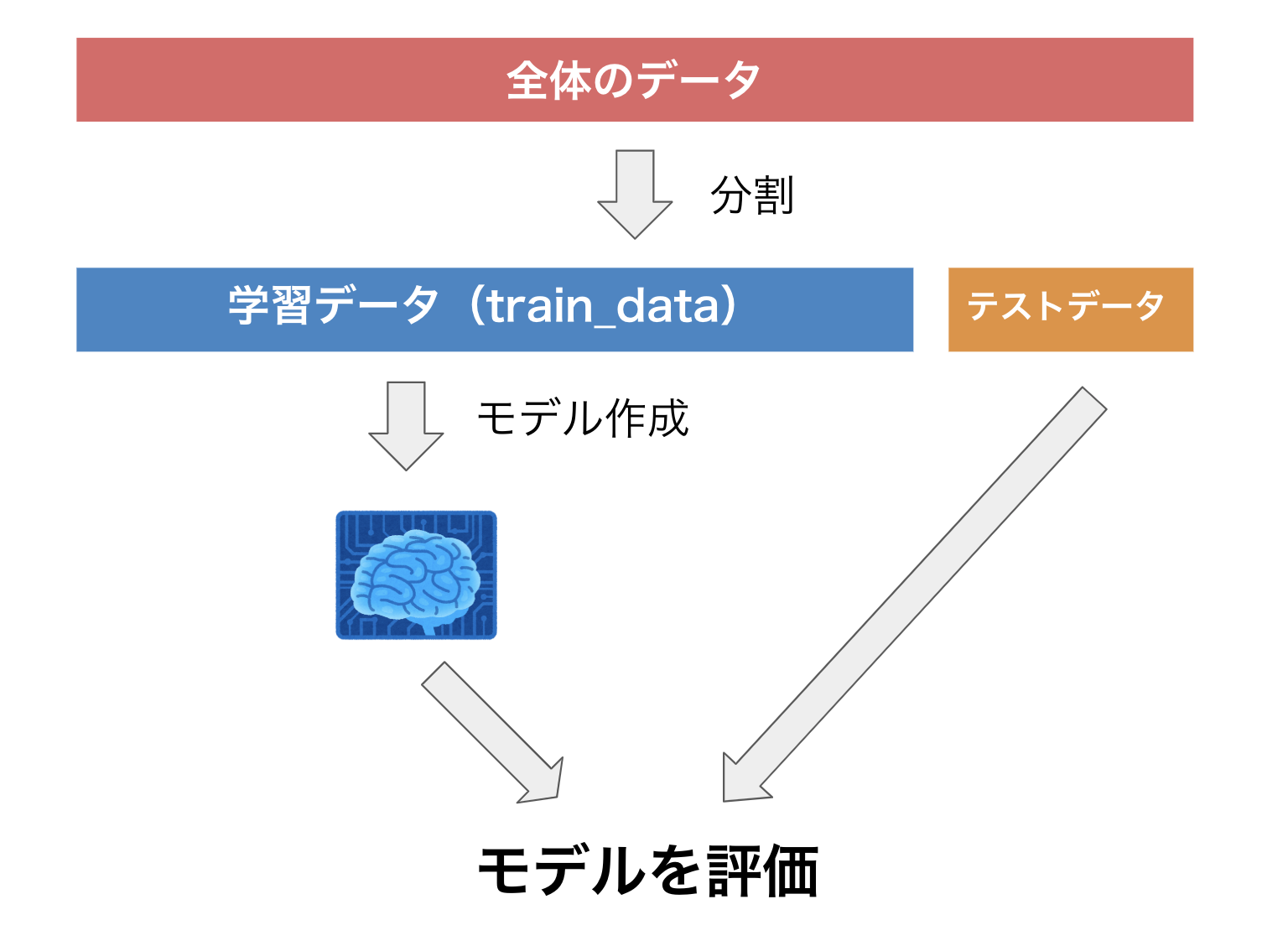
以下の手順で汎化性能を測定します。
1.データを学習データとテストデータに分割します。
2.学習データのみを用いてモデルを作成します。
3.作成したモデルを使って、テストデータへ当てはめ、予測値を算出します。
4.「算出した予測値」と「実際のテストデータの値(教師データ)」を用いてモデルの性能を測定
今回の機械学習のパートでも収集したデータの67%を学習データ、残りの33%をテストデータへ分割しています。
前処置編
実はこれがデータ分析のほとんどをしめるパートで、データ分析では機械が読み取れる形にデータを処理する必要があります。
例えば築年数のカラム(列の名前の事)を見てみましょう。
私たち人間はこれを見て**「建物の古さは、新築<築7年<築21年 である」**ということを認識できます。当たり前だと思うかもしれませんが、機械はこれを認識することができません。
なので
新築→0
築7年→7
築21年→21
と処理し、[0<7<21]と機械が認識できるようにしてやる必要があります。
また、2LDKなどの間取りはone-hot encoding(ダミー変数)、最寄り駅等はLabel encodingという手法を用いて処理しています。(気になったら調べてください)
また欠損値への対処も必要な場合があります。(欠損値補完は沼なのでここでは触れません...)
このような学習前にデータへ施す処理のことを総括して前処理と呼びます。
それでは実際にコードを実行していきましょう。
import pandas as pd
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
from sklearn import preprocessing
import pandas_profiling as pdp
df = pd.read_csv('suumo.csv', sep='\t', encoding='utf-16')
splitted1 = df['立地1'].str.split(' 歩', expand=True)
splitted1.columns = ['立地11', '立地12']
splitted2 = df['立地2'].str.split(' 歩', expand=True)
splitted2.columns = ['立地21', '立地22']
splitted3 = df['立地3'].str.split(' 歩', expand=True)
splitted3.columns = ['立地31', '立地32']
splitted4 = df['敷/礼/保証/敷引,償却'].str.split('/', expand=True)
splitted4.columns = ['敷金', '礼金']
df = pd.concat([df, splitted1, splitted2, splitted3, splitted4], axis=1)
df.drop(['立地1','立地2','立地3','敷/礼/保証/敷引,償却'], axis=1, inplace=True)
df = df.dropna(subset=['賃料料'])
df['賃料料'] = df['賃料料'].str.replace(u'万円', u'')
df['敷金'] = df['敷金'].str.replace(u'万円', u'')
df['礼金'] = df['礼金'].str.replace(u'万円', u'')
df['管理費'] = df['管理費'].str.replace(u'円', u'')
df['築年数'] = df['築年数'].str.replace(u'新築', u'0')
df['築年数'] = df['築年数'].str.replace(u'99年以上', u'0') #
df['築年数'] = df['築年数'].str.replace(u'築', u'')
df['築年数'] = df['築年数'].str.replace(u'年', u'')
df['専有面積'] = df['専有面積'].str.replace(u'm', u'')
df['立地12'] = df['立地12'].str.replace(u'分', u'')
df['立地22'] = df['立地22'].str.replace(u'分', u'')
df['立地32'] = df['立地32'].str.replace(u'分', u'')
df['管理費'] = df['管理費'].replace('-',0)
df['敷金'] = df['敷金'].replace('-',0)
df['礼金'] = df['礼金'].replace('-',0)
splitted5 = df['立地11'].str.split('/', expand=True)
splitted5.columns = ['路線1', '駅1']
splitted5['徒歩1'] = df['立地12']
splitted6 = df['立地21'].str.split('/', expand=True)
splitted6.columns = ['路線2', '駅2']
splitted6['徒歩2'] = df['立地22']
splitted7 = df['立地31'].str.split('/', expand=True)
splitted7.columns = ['路線3', '駅3']
splitted7['徒歩3'] = df['立地32']
df = pd.concat([df, splitted5, splitted6, splitted7], axis=1)
df.drop(['立地11','立地12','立地21','立地22','立地31','立地32'], axis=1, inplace=True)
df['賃料料'] = pd.to_numeric(df['賃料料'])
df['管理費'] = pd.to_numeric(df['管理費'])
df['敷金'] = pd.to_numeric(df['敷金'])
df['礼金'] = pd.to_numeric(df['礼金'])
df['築年数'] = pd.to_numeric(df['築年数'])
df['専有面積'] = pd.to_numeric(df['専有面積'])
df['賃料料'] = df['賃料料'] * 10000
df['敷金'] = df['敷金'] * 10000
df['礼金'] = df['礼金'] * 10000
df['徒歩1'] = pd.to_numeric(df['徒歩1'])
df['徒歩2'] = pd.to_numeric(df['徒歩2'])
df['徒歩3'] = pd.to_numeric(df['徒歩3'])
splitted8 = df['階層'].str.split('-', expand=True)
splitted8.columns = ['階1', '階2']
splitted8['階1'].str.encode('cp932')
splitted8['階1'] = splitted8['階1'].str.replace(u'階', u'')
splitted8['階1'] = splitted8['階1'].str.replace(u'B', u'-')
splitted8['階1'] = splitted8['階1'].str.replace(u'M', u'')
splitted8['階1'] = pd.to_numeric(splitted8['階1'])
df = pd.concat([df, splitted8], axis=1)
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下1地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下2地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下3地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下4地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下5地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下6地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下7地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下8地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'地下9地上', u'')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'平屋', u'1')
df['建物の高さ'] = df['建物の高さ'].str.replace(u'階建', u'')
df['建物の高さ'] = pd.to_numeric(df['建物の高さ'])
df = df.reset_index(drop=True)
df['間取りDK'] = 0
df['間取りK'] = 0
df['間取りL'] = 0
df['間取りS'] = 0
df['間取り'] = df['間取り'].str.replace(u'ワンルーム', u'1')
for x in range(len(df)):
if 'DK' in df['間取り'][x]:
df.loc[x,'間取りDK'] = 1
df['間取り'] = df['間取り'].str.replace(u'DK',u'')
for x in range(len(df)):
if 'K' in df['間取り'][x]:
df.loc[x,'間取りK'] = 1
df['間取り'] = df['間取り'].str.replace(u'K',u'')
for x in range(len(df)):
if 'L' in df['間取り'][x]:
df.loc[x,'間取りL'] = 1
df['間取り'] = df['間取り'].str.replace(u'L',u'')
for x in range(len(df)):
if 'S' in df['間取り'][x]:
df.loc[x,'間取りS'] = 1
df['間取り'] = df['間取り'].str.replace(u'S',u'')
df['間取り'] = pd.to_numeric(df['間取り'])
splitted9 = df['住所'].str.split('区', expand=True)
splitted9.columns = ['区', '市町村']
splitted9['区'] = splitted9['区'] + '区'
splitted9['区'] = splitted9['区'].str.replace('東京都','')
df = pd.concat([df, splitted9], axis=1)
df_for_search = df.copy()
df[['路線1','路線2','路線3', '駅1', '駅2','駅3','市町村']] = df[['路線1','路線2','路線3', '駅1', '駅2','駅3','市町村']].fillna("NAN")
oe = preprocessing.OrdinalEncoder()
df[['路線1','路線2','路線3', '駅1', '駅2','駅3','市町村']] = oe.fit_transform(df[['路線1','路線2','路線3', '駅1', '駅2','駅3','市町村']].values)
df['賃料料+管理費'] = df['賃料料'] + df['管理費']
# 上限価格を設定
df = df[df['賃料料+管理費'] < 300000]
df = df[["マンション名",'賃料料+管理費', '築年数', '建物の高さ', '階1',
'専有面積','路線1','路線2','路線3', '駅1', '駅2','駅3','徒歩1', '徒歩2','徒歩3','間取り', '間取りDK', '間取りK', '間取りL', '間取りS',
'市町村']]
df.columns = ['name','real_rent','age', 'hight', 'level','area', 'route_1','route_2','route_3','station_1','station_2','station_3','distance_1','distance_2','distance_3','room_number','DK','K','L','S','adress']
pdp.ProfileReport(df)
4点、説明をします。
・解析に必要ないと判断したため「区」や「詳細url」等の情報を入れていません
例えば今回自分は文京区でやっていますが、全てが文京区のデータなのでその情報に価値はないでしょう。
ただし、例えば東京23区全てのデータで分析を行う時は「区」の情報は非常に重要であるということに注意してください。
・「敷金」「礼金」の情報を入れていません。これは先ほどの理由とは逆に予測が簡単になりすぎる(意味を持たなくなる)からです。ほとんどの賃貸では敷金や礼金は家賃と同じかその2〜3倍に設定されています。「礼金7万円の賃貸の家賃は7万円と予測します!」と言われても何も得るものがないですよね...
・目的変数を家賃ではなく、「家賃+管理費」にしています。実際に月々払うのは「家賃+管理費」ですからね。
さらに家賃+管理費が30万円を超える物件のデータは下から三行目の
df = df[df['賃料料+管理費'] < 300000]
で除いています。
自分は家賃の上限無しでも分析し、お得物件を探してみたのですが、「この物件の予測家賃は200万円ですが、実際は150万円!なんと月50万円もお得!」と言われ悲しい気持ちになりました。(家賃30万の家も到底住めませんが...)ここは自分で値を変えてもらっても大丈夫です。
・**探索的データ解析(EDA)**にpandas-profilingを用いています。
個人的にとても気に入っているライブラリです。
データの全体の情報から...

各変数の基本統計量、
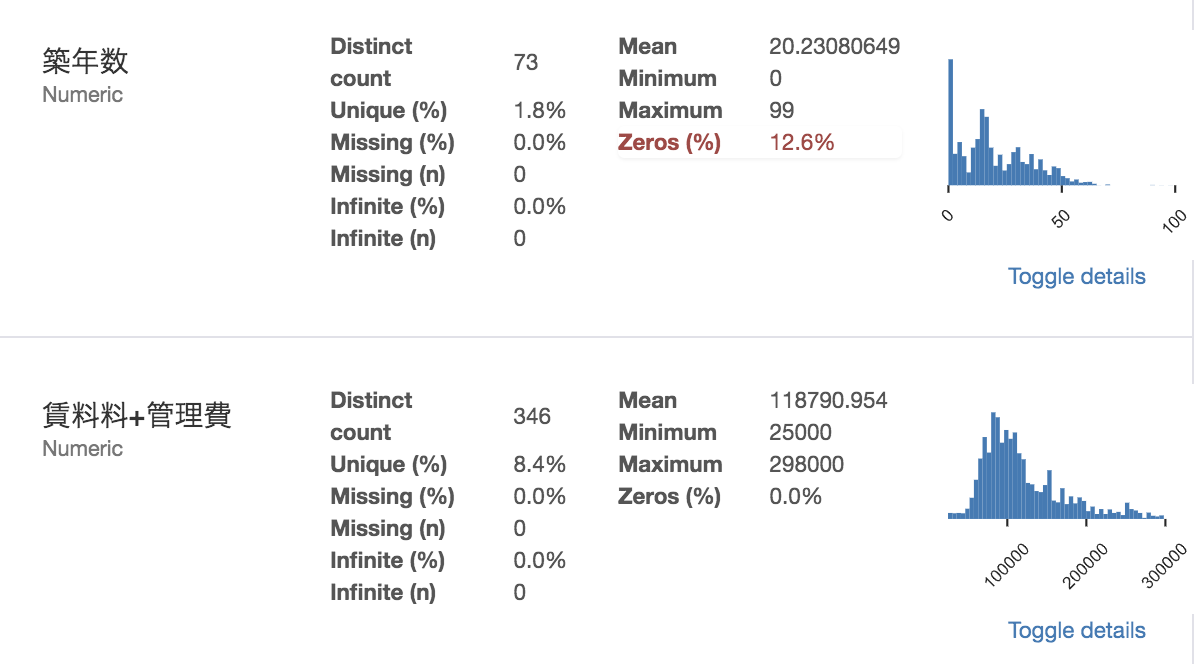
なんと相関係数行列まで表示してくれます...
便利すぎる...

追記(2020/1/7)
現在lightgbmでは特徴量の名前に日本語が使えないようです
特徴量作成
さて続いては特徴量作成のパートです。
ここも前処理として含まれます。
ここでは効きそうな(説明変数をうまく説明できそうな)新しい特徴量を既存の特徴量から作成していきます。
例えば下のコードでは
・面積を部屋の数で割った、一部屋あたりの面積
・最寄り駅の種類と最寄り駅までの距離の積(マイナーな駅まで徒歩5分とメジャーな駅まで駅5分だと後者の方が家賃が高そう)
といった特徴量を作成し加えています。
少しでもPythonの経験があれば是非オリジナルの特徴量を作成してみてください。
df["per_area"] = df["area"]/df["room_number"]
df["height_level"] = df["height"]*df["level"]
df["area_height_level"] = df["area"]*df["height_level"]
df["distance_staion_1"] = df["station_1"]*df["distance_1"]
機械学習編
ついに学習編です!!!
整形&作成したデータをもとに価格予測モデルを作成していきます。
ここで使う機械学習アルゴリズムはlightgbmです。
・精度が高い
・処理が早い
という特徴を持っており、機械学習の精度を競う大会では最もメジャーな方法と言っていいでしょう。(以前参加した制限時間がきついオフラインコンペでは上位10人が全員このアルゴリズムを使っていました...!)
まずターミナルorコマンドプロンプトで
conda install -c conda-forge lightgbm
と打ち込み、lightgbmをインストールしましょう。
それでは早速コードを実行してみましょう。
import matplotlib.pyplot as plt
import japanize_matplotlib
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
y = df["real_rent"]
X = df.drop(['real_rent',"name"], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.33, random_state=0)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
lgbm_params = {
'objective': 'regression',
'metric': 'rmse',
'num_leaves':80
}
model = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, verbose_eval=-1)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
print(r2_score(y_test, y_pred) )
lgb.plot_importance(model, figsize=(12, 6))
plt.show()
<結果>
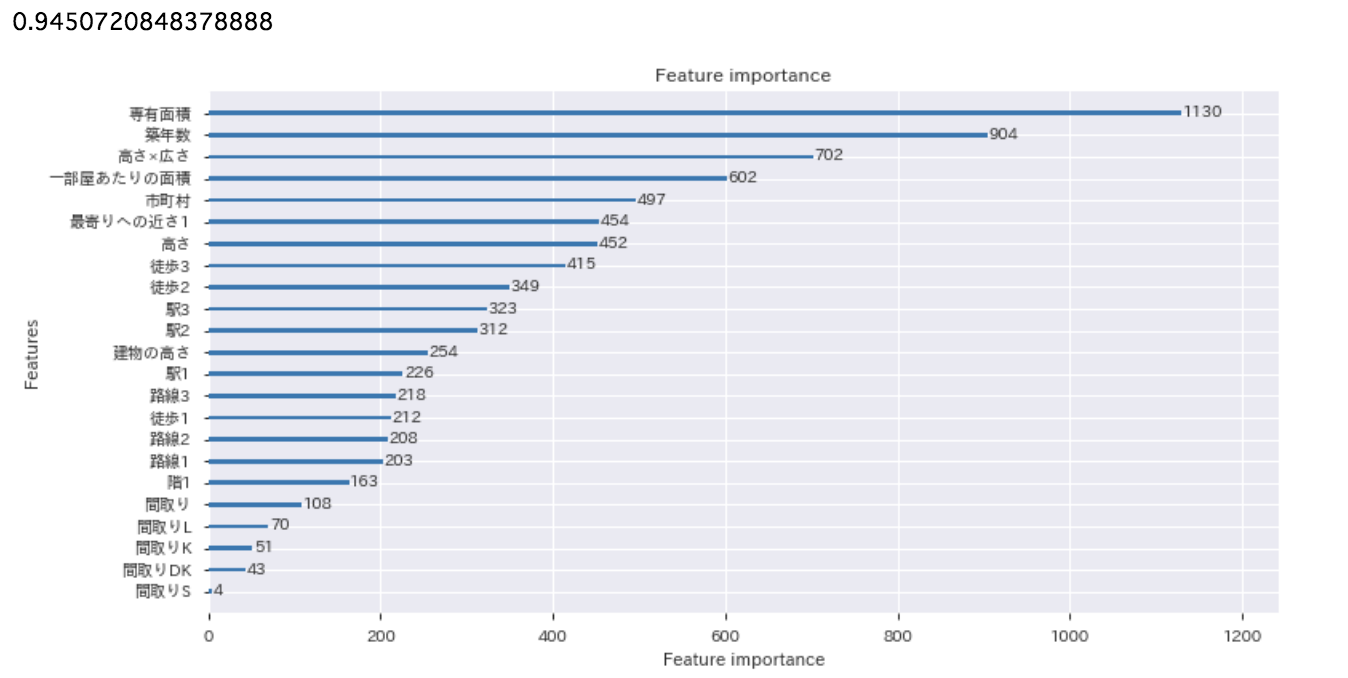
ここでもいくつか説明を加えます。
・結果として出て来た数字はこのモデルの精度を表しています。
この指標は0~1までの値を取り、1に近ければ近いほど良いということです。
今回自分の分析で出た「0.945」という指標から、このモデルが高い性能を持っていることがわかりますね。
イメージとしては94%くらいの精度で予測できています。
・feature_importanceは各特徴量の重要度を示しています。
やはり占有面積や築年数が重要なことがわかりますね。
自分で作った特徴量が結構いい働きをしてくれてて嬉しい。
お得物件探索編
pred = list(model.predict(X, num_iteration=model.best_iteration))
pred = pd.Series(pred, name="予測値")
diff = pd.Series(df["賃料料+管理費"]-pred,name="予測値との差")
df_search = pd.concat([df_for_search,diff,pred], axis=1)
df_search = df_search.sort_values("予測値との差")
df_search = df_search[["マンション名",'賃料料+管理費', '予測値', '予測値との差', '詳細URL']]
df_search.to_csv('otoku.csv', sep = '\t',encoding='utf-16')
上記のコードを実行すると下記のようなcsvファイルが作成されます。
このコードでは作成したモデルを利用して、全ての物件について家賃を予測し、その差が大きい、つまりお得順にソートした表を作成しています。
つまり作成されたcsvファイルの中で上にあればあるほどお得であるということです。
 例えば今回のモデルで一番お得であるとされた物件「A-standard本郷三丁目」について調べてみましょう。
右の詳細urlから飛ぶことができます。
例えば今回のモデルで一番お得であるとされた物件「A-standard本郷三丁目」について調べてみましょう。
右の詳細urlから飛ぶことができます。


最寄り駅まで徒歩3分
2LDK
54㎡
築7年
9階
これで月13万円は確かにかなりの好条件ですね...
控えめに言ってめちゃくちゃ住みたい...
予測値が23万円と出ていたので、
・文京区
・築10年以内
・最寄り駅から徒歩10分以内
・面積45㎡以上
の条件を指定してSUUMOで検索してみたところ、本当に20~23万くらいの物件が多く、この物件がお得なことがわかります。(ちなみに事故物件でもなかったです)
ぜひこの表を使って物件探しをしてみてください!
実は...
この章では「機械学習を勉強しないと簡単に騙されてしまう」という話をします。
先ほど作った表はものすごく効果的で素晴らしいものに思えます。
しかし実はあの表の67%の情報はほぼ無意味です
実はあのデータの中に今一番お得だと思ってる物件よりお得な物件がある可能性が十分にあります。
理由は「学習用データを用いて作成したモデルを学習用データへ当てはめているため、お得をお得として認識できないから」です。
そもそも、お得な物件とは(予測値)-(実際の価格(教師データ))が大きくなるような物件のことです。先ほどのマンションでは23万円と予測したが、実際は13万円で、10万円もお得ということが言えます。
しかし、この物件を学習用データに含めてしまうと「いやそれ知ってるし」と実際の価格とほとんど変わらない値を予測値として算出してしまうのです。
要は「カンニング」みたいなことが起こってるんですね。いかに難解で特殊な問題でも答えを知っていれば解けてしまうのと同じです。
この目的は「お得物件を探そう」でしたから、この問題は明らかに相当マズイです。
つまりは予測したいデータを学習データに含めてはいけないということですね
ちなみに解決方法としては以下の画像のように、何回かに分けて学習、予測をする方法などが考えられます。
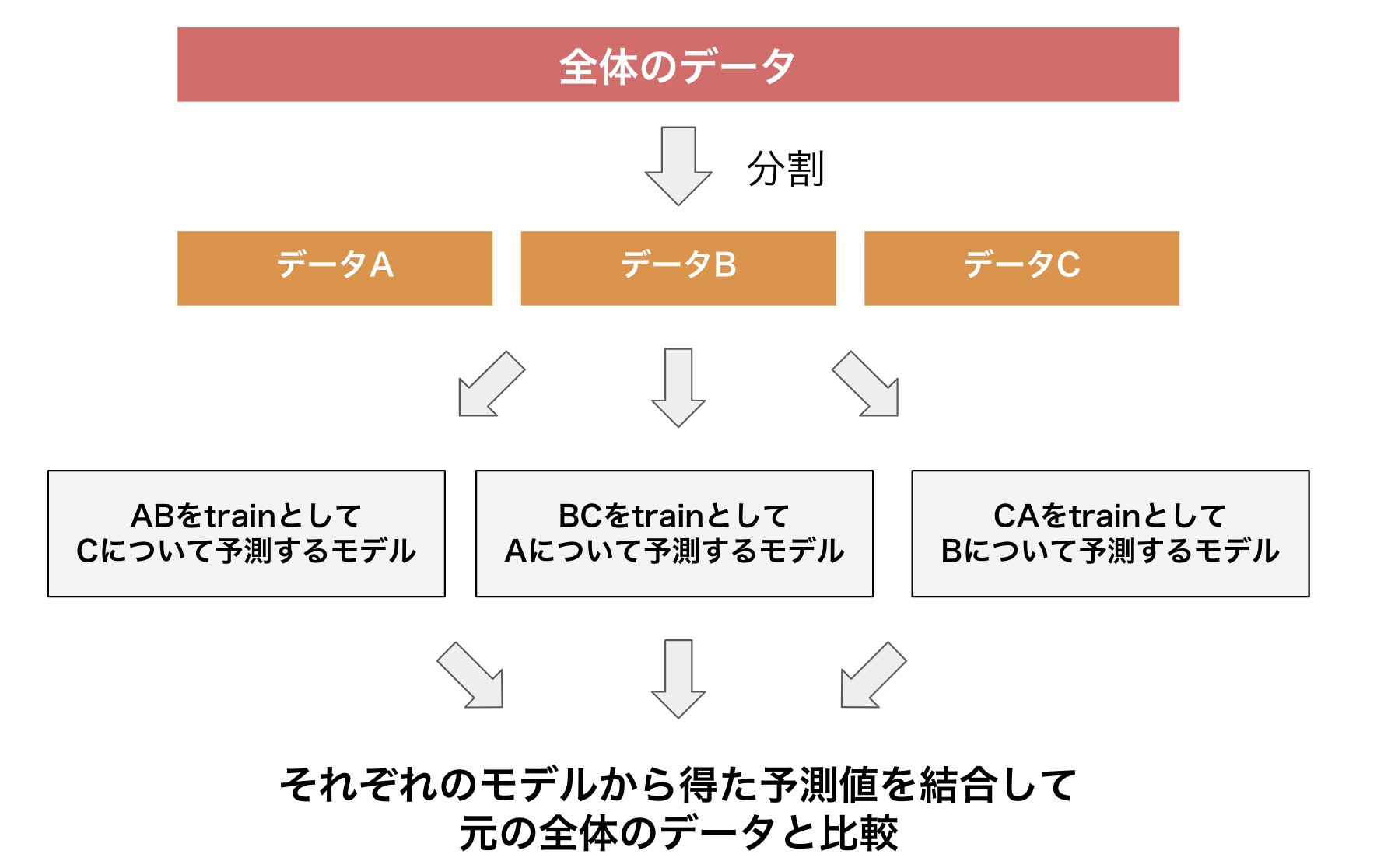
「なんかよくわかんねーな」と思っていても全然大丈夫です。少し複雑な話をしているので心配しないでください。
この章では
データ分析の知識ないと簡単に騙されちゃうじゃん...
データ分析って奥が深いんだなぁ
ということを紹介したいがために書いています。
終わりに
以上でこの記事の内容は終わりです。
ここまでお付き合いいただき本当にありがとうございました!
データ分析の楽しさとダイナミックさ、そして恐ろしさや奥深さを感じていただけたらとても嬉しいです。
自分が幸せになるためにも、不幸にならないためにも、データ分析は重要です。
人間って自覚以上に数字に弱いんですよね。
またこれでデータ分析を勉強してみたいと思った方は、違う記事で独学方法を紹介しているので参考にしてみてください。
参考
機械学習を使って東京23区のお買い得賃貸物件を探してみた
スクレイピングのコードはほとんどこの方のコードを参考にしました。
ただ、何箇所かそのままのコピペで動かないところがあったので修正しています。