初めに
この記事は以下のような欲求を満たします。
- colab (pro)を計算リソースとして利用したい(これが一番大きい)
- 実験コード管理はgitでやりたい
- ハイパラ管理はymlファイルでやりたい
- 実験結果や学習済みモデルは専用のサービスで管理したい
- 1実験1スクリプトで実験をやりたい
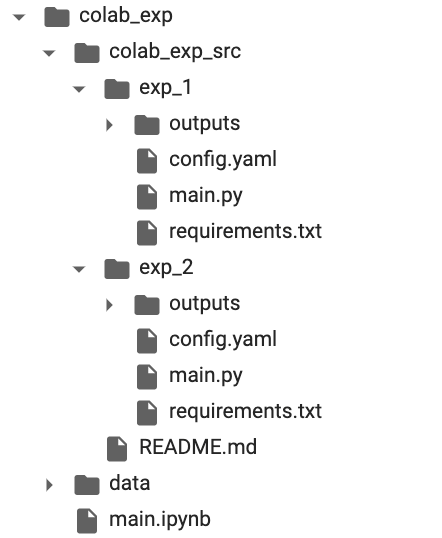
具体的には以下のようなディレクトリ構成になっており、
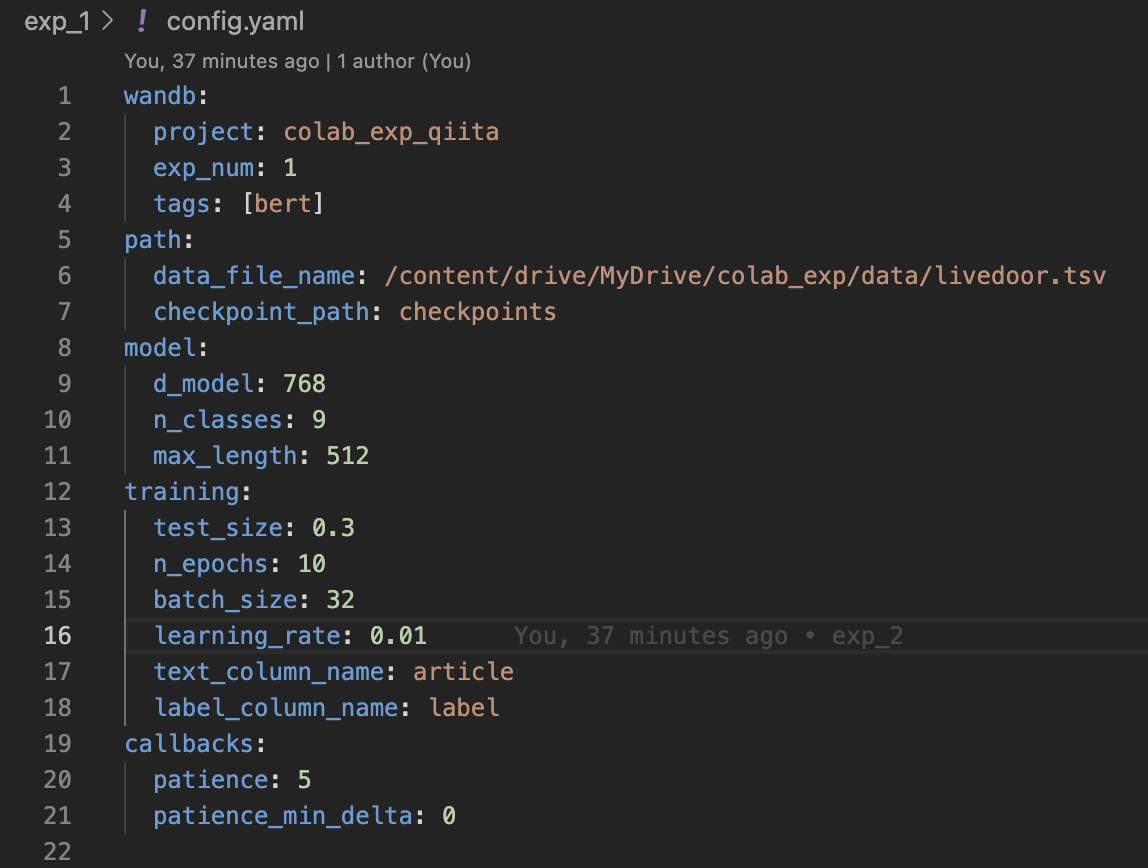
下画像のようにymlファイルでハイパラや実験に関しての情報を管理し
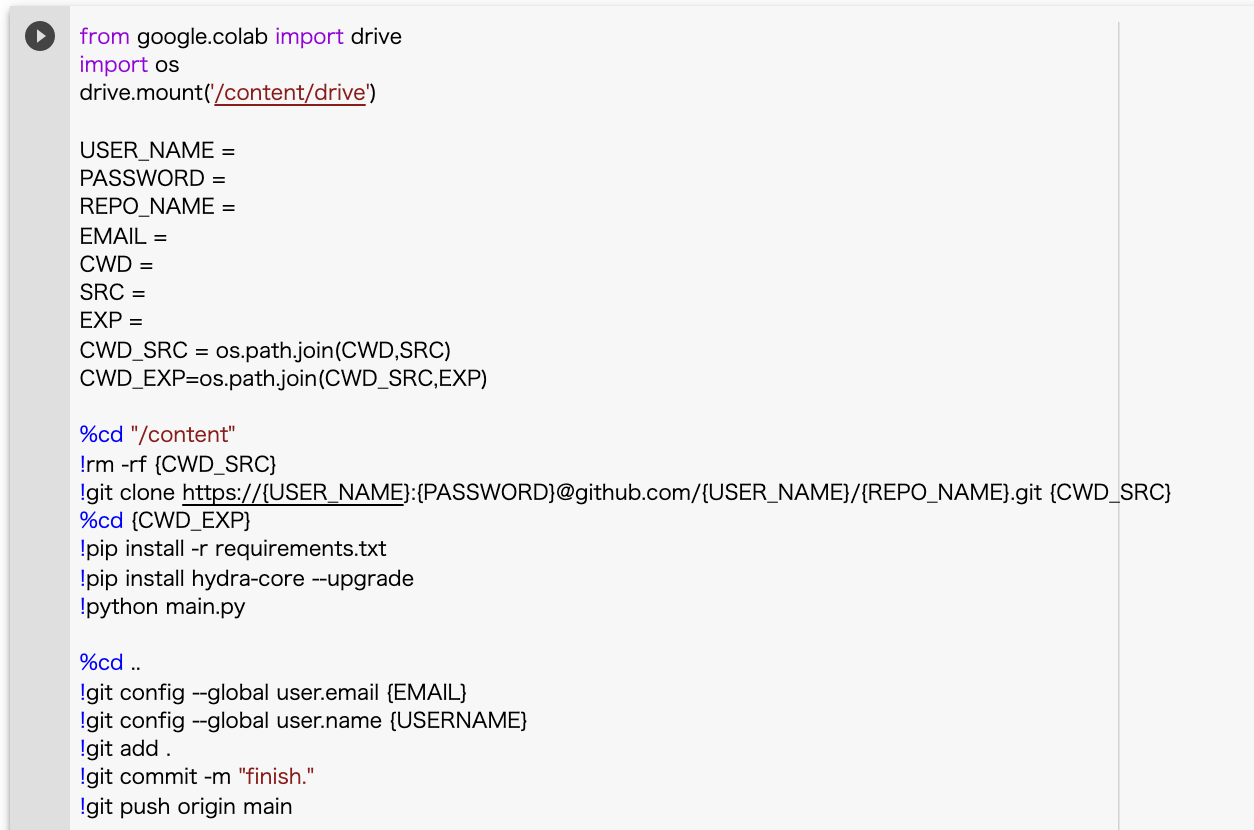
このようにcolabでコードを実行すると、
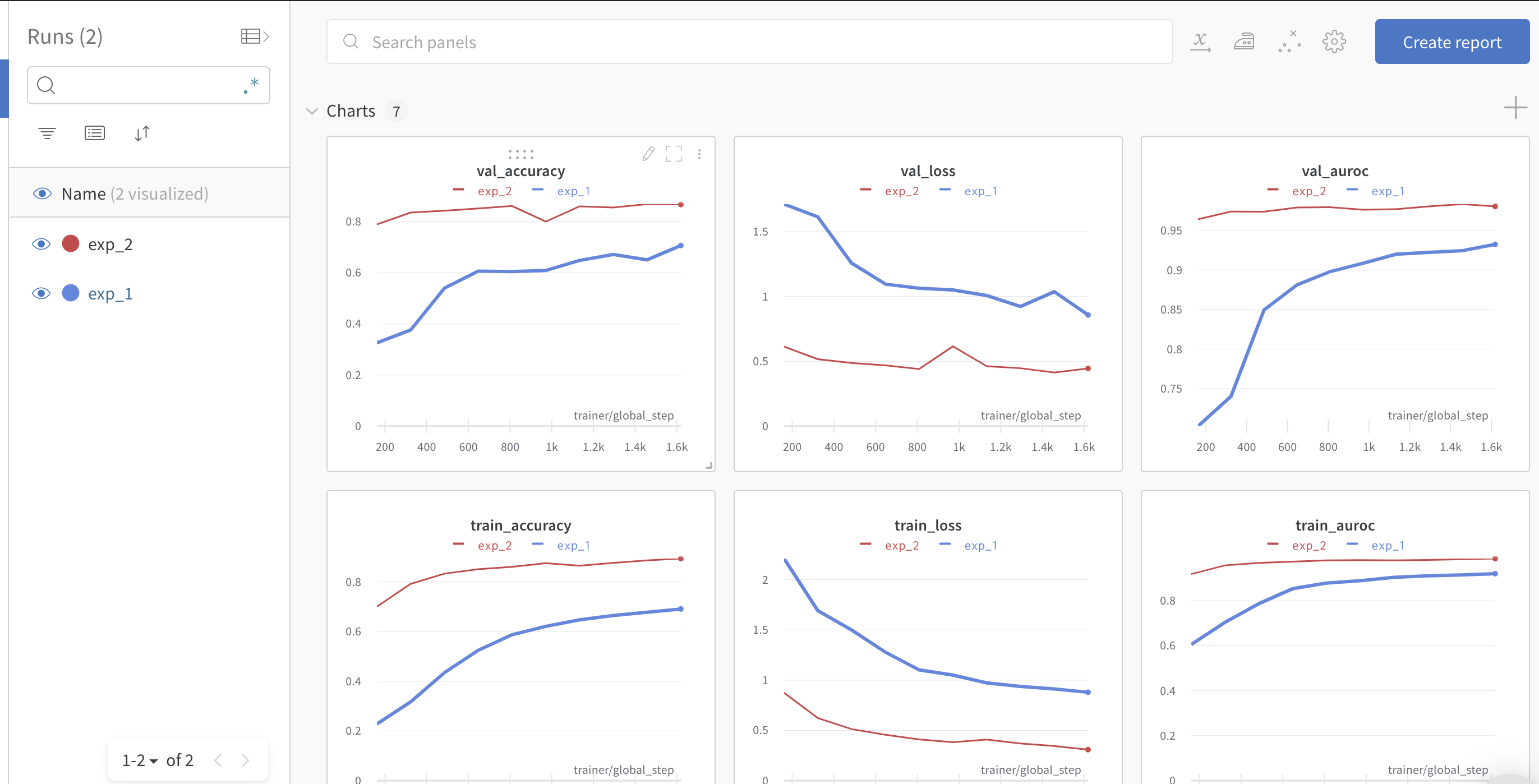
自動的にlogが下画像のように生成され、

さらにモデル管理することがきます。
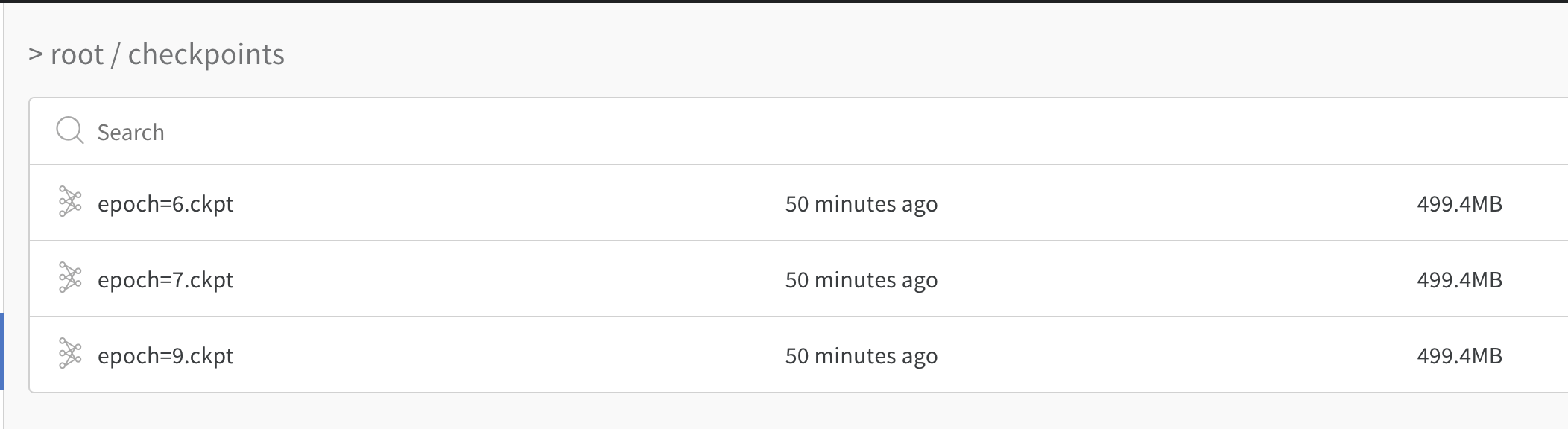
また、1実験1スクリプトを徹底するため、実験結果と対応するコードがすぐにわかります。
(ちなみに1実験1スクリプトのメリットについては下記の記事が非常に参考になります。)
なぜcolabで実験?
コスパが最強だからです。
例えばcolab proとGCEと比較してみましょう。
colab proではP100かV100が割り振られます。
ここでは週5で1日12時間で1ヶ月稼働させるとしましょう。
| machine | GPU | 価格/1時間 | 価格/1月 |
|---|---|---|---|
| Colab | P100 | _ | $9.9 |
| GCE | P100 | $2.48 | $595.2 |
| Colab | V100 | _ | $9.9 |
| GCE | V100 | $1.46 | $350.2 |
マジで安すぎる...!
P100でもガッツリ使えば月3~4万は浮きそう...
また上記のGCEの計算はGPUだけの価格ですので、広いメモリや高性能なCPUが必要な場合、その価格はさらに膨れ上がります。
colab(というかnotebook)の微妙なところ
実験管理が破綻する点です。
例えば以下のようなシチュエーションに遭遇したことはありませんか?(筆者は死ぬほどあります)
「なんかめっちゃ精度いいモデルできたけど再現できない...」
「このモデル、たまに変な挙動するけどどういう処理で学習させたんだっけ?」
「あれ、このモデル、あの処理を試したやつだっけ...?」
「人に自分の実験結果について共有したいけど、notebookが散らばりすぎて不可能...」
notebookはちょっとモデルを作ったり、EDAをすることには向いていますが、ガッツリモデル作成の実験をすることには不向きです。
まとめ(成果物)
この記事では以下の構成を作成します。
- colab (pro)を計算リソースとして利用
- 実験コードはgitで管理
- 1実験1スクリプトで実験管理
- ハイパラはhydraで管理
- 実験結果や学習済みモデルはwandbで管理
目次
| 目次 |
|---|
| 全体の構成について |
| 実験コードについて |
| [実行環境(google drive上)について](#実行環境(google drive上)について) |
| main.pyについて |
| pytorch-lightning |
| hydra(congi.yaml) |
| wandb |
| [Colab(google drive)上での作業について](#Colab(google drive)上での作業について) |
| 実際に実験を行ってみる |
| 終わりに |
実験コードについて
まず実験コードについては以下のようにしています。
一つの実験がexp_xxxで区切られており、以下のファイルを保持しています。
- main.py:実際に処理を行うスクリプト
- config.ymal:ハイパーパラメータやメタ情報を管理するyamlファイル
- requirements.txt:必要なパッケージ群
poetryの導入も考えましたが、手順がかなり煩雑になるため今回は見送りました。(1.poetryで仮想環境を作ってその中で実行 2.poetryでそのままシステムにインストールする、を試した両方ともかなりカオスになったので泣く泣くお蔵入りです。colabでのパッケージ管理に関して詳しい方がいたらコメント等で教えてください...)
hoge_project_src
├── exp_1
│ ├── main.py
│ ├── config.yaml
│ └── requirements.txt
├── exp_2
│ ├── main.py
│ ├── config.yaml
│ └── requirements.txt
├── exp_3
│ ├── main.py
│ ├── config.yaml
│ └── requirements.txt
└── .gitignore
実行環境(google drive上)について
実行環境(google drive)では以下のようにディレクトリを構成します。
それぞれについて説明すると
- data:学習データや、学習済みモデル等の置き場
- main.ipynb:実行主体
- hoge_project_src:実験コードをcloneしてきます。
hoge_progect
├── data
│ ├── hoge.csv
│ └── hoge.csv
├── maim.ipynb
└── hoge_project_src
├── exp_1
│ ├── main.py
│ ├── config.yaml
│ └── requirements.txt
├── exp_2
│ ├── main.py
│ ├── config.yaml
│ └── requirements.txt
├── exp_3
│ ├── main.py
│ ├── config.yaml
│ └── requirements.txt
└── .gitignore
main.pyについて
まずmain.pyは以下のようになります。
ここではサンプルとしてlivedoorのテキスト分類を学習済み日本語BERTを用いて行うとしましょう。
import os
import hydra
import numpy as np
import pandas as pd
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.optim as optim
from omegaconf import DictConfig
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.loggers import WandbLogger
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, Dataset
from torchmetrics.functional import accuracy, auroc
from transformers import BertModel, BertTokenizer
class BertDataset(Dataset):
def __init__(
self,
df: pd.DataFrame,
tokenizer: BertTokenizer,
max_length: int,
text_column_name: str,
label_column_name: str,
):
self.df = df
self.tokenizer = tokenizer
self.max_length = max_length
self.text_columm_name = text_column_name
self.label_column_name = label_column_name
def __len__(self):
return len(self.df)
def __getitem__(self, index: int):
df_row = self.df.iloc[index]
text = df_row[self.text_columm_name]
labels = df_row[self.label_column_name].astype(int)
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_length,
padding="max_length",
truncation=True,
return_token_type_ids=False,
return_attention_mask=False,
return_tensors="pt",
)
return encoding["input_ids"].flatten(), torch.tensor(labels)
class CreateDataModule(pl.LightningDataModule):
def __init__(
self,
train_df,
valid_df,
batch_size,
max_length,
text_column_name: str = "text",
label_column_name: str = "label",
pretrained_model="cl-tohoku/bert-base-japanese-whole-word-masking",
):
super().__init__()
self.train_df = train_df
self.valid_df = valid_df
self.batch_size = batch_size
self.max_length = max_length
self.tokenizer = BertTokenizer.from_pretrained(pretrained_model)
self.text_columm_name = text_column_name
self.label_column_name = label_column_name
def setup(self):
self.train_dataset = BertDataset(
self.train_df,
self.tokenizer,
self.max_length,
self.text_columm_name,
self.label_column_name,
)
self.vaild_dataset = BertDataset(
self.valid_df,
self.tokenizer,
self.max_length,
self.text_columm_name,
self.label_column_name,
)
def train_dataloader(self):
return DataLoader(
self.train_dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=os.cpu_count(),
)
def val_dataloader(self):
return DataLoader(
self.vaild_dataset, batch_size=self.batch_size, num_workers=os.cpu_count()
)
class CustumBert(pl.LightningModule):
def __init__(
self,
n_classes: int,
d_model: int,
learning_rate: float,
max_length: int,
pretrained_model="cl-tohoku/bert-base-japanese-whole-word-masking",
):
super().__init__()
self.bert = BertModel.from_pretrained(pretrained_model)
self.classifier = nn.Linear(d_model, n_classes)
self.lr = learning_rate
self.criterion = nn.CrossEntropyLoss()
self.n_classes = n_classes
for param in self.bert.parameters():
param.requires_grad = False
for param in self.bert.encoder.layer[-1].parameters():
param.requires_grad = True
for param in self.classifier.parameters():
param.requires_grad = True
def forward(self, inputs):
outputs = self.bert(inputs)[0]
preds = self.classifier(outputs[:, 0, :])
return preds
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(inputs=x)
loss = self.criterion(y_hat, y)
return {"loss": loss, "batch_preds": y_hat, "batch_labels": y}
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(inputs=x)
loss = self.criterion(y_hat, y)
return {"loss": loss, "batch_preds": y_hat, "batch_labels": y}
def training_epoch_end(self, outputs, mode="train"):
epoch_y_hats = torch.cat([x["batch_preds"] for x in outputs])
epoch_labels = torch.cat([x["batch_labels"] for x in outputs])
epoch_loss = self.criterion(epoch_y_hats, epoch_labels)
self.log(f"{mode}_loss", epoch_loss)
_, epoch_preds = torch.max(epoch_y_hats, 1)
epoch_accuracy = accuracy(epoch_preds, epoch_labels)
self.log(f"{mode}_accuracy", epoch_accuracy)
epoch_auroc = auroc(epoch_y_hats, epoch_labels, num_classes=self.n_classes)
self.log(f"{mode}_auroc", epoch_auroc)
def validation_epoch_end(self, outputs, mode="val"):
epoch_y_hats = torch.cat([x["batch_preds"] for x in outputs])
epoch_labels = torch.cat([x["batch_labels"] for x in outputs])
epoch_loss = self.criterion(epoch_y_hats, epoch_labels)
self.log(f"{mode}_loss", epoch_loss)
_, epoch_preds = torch.max(epoch_y_hats, 1)
epoch_accuracy = accuracy(epoch_preds, epoch_labels)
self.log(f"{mode}_accuracy", epoch_accuracy)
epoch_auroc = auroc(epoch_y_hats, epoch_labels, num_classes=self.n_classes)
self.log(f"{mode}_auroc", epoch_auroc)
def configure_optimizers(self):
return optim.Adam(self.parameters(), lr=self.lr)
def make_callbacks(min_delta, patience, checkpoint_path):
checkpoint_callback = ModelCheckpoint(
dirpath=checkpoint_path,
filename="{epoch}",
save_top_k=3,
verbose=True,
monitor="val_loss",
mode="min",
)
early_stop_callback = EarlyStopping(
monitor="val_loss", min_delta=min_delta, patience=patience, mode="min"
)
return [early_stop_callback, checkpoint_callback]
@hydra.main(config_path=".", config_name="config")
def main(cfg: DictConfig):
cwd = hydra.utils.get_original_cwd()
wandb_logger = WandbLogger(
name=("exp_" + str(cfg.wandb.exp_num)),
project=cfg.wandb.project,
tags=cfg.wandb.tags,
log_model=True,
)
checkpoint_path = os.path.join(
wandb_logger.experiment.dir, cfg.path.checkpoint_path
)
wandb_logger.log_hyperparams(cfg)
df = pd.read_csv(cfg.path.data_file_name, sep="\t").dropna().reset_index(drop=True)
df[cfg.training.label_column_name] = np.argmax(df.iloc[:, 2:].values, axis=1)
df[[cfg.training.text_column_name, cfg.training.label_column_name]]
train, test = train_test_split(df, test_size=cfg.training.test_size, shuffle=True)
data_module = CreateDataModule(
train,
test,
cfg.training.batch_size,
cfg.model.max_length,
cfg.training.text_column_name,
)
data_module.setup()
call_backs = make_callbacks(
cfg.callbacks.patience_min_delta, cfg.callbacks.patience, checkpoint_path
)
model = CustumBert(
n_classes=cfg.model.n_classes,
d_model=cfg.model.d_model,
learning_rate=cfg.training.learning_rate,
max_length=cfg.model.max_length,
)
trainer = pl.Trainer(
max_epochs=cfg.training.n_epochs,
gpus=1,
progress_bar_refresh_rate=30,
callbacks=call_backs,
logger=wandb_logger,
)
trainer.fit(model, data_module)
if __name__ == "__main__":
main()
pytorch-lightning
Pytorch-lightningそのものについては基本的に解説しません。
他にわかりやすい記事があるのでそちらを参照してください。
...が、ModelCheckpointのpathだけわかりにくいのでそこだけ後述します。
その他は普通にPytorch-lightningのコードを書いて、hydraを使ってyamlファイルからパラメータを渡せばいいだけです。
hydra(congi.yaml)
hydraを使うと学習に使用するパラメータをyamlで管理することができます。
使用方法は簡単で、以下のようにyamlファイルを設定し、
wandb:
project: colab_exp
exp_num: 6
tags: [bert]
path:
data_file_name: データセットの絶対パス
checkpoint_path: checkpoints
model:
d_model: 768
n_classes: 9
max_length: 512
training:
test_size: 0.3
n_epochs: 30
batch_size: 32
learning_rate: 0.0001
text_column_name: article
label_column_name: label
callbacks:
patience: 5
patience_min_delta: 0
以下のようにmain関数にデコレータを付与してあげます。
@hydra.main(config_path=".", config_name="config")
def main(cfg: DictConfig):
print(cfg.wandb.project)
例えばprint(cfg.wandb.project)はcolab_expと出力してくれます。
ここで一つ注意することは学習データのパスとして絶対パスを渡してやることです(相対パスからでもいけるがちょっとだけめんどくさい)
これはhydraの仕様によりカレントディレクトリが変更されてしまうことが原因です。(具体的には hoge_project_src/exp_xxx/outputs/2021-07-07/12-23-23、など)
一応
hydra.utils.get_original_cwd()
で変更前のカレントディレクトリを参照することもできますが、今回はその一つ上の階層であるdataを参照したいので、絶対パスをconfigに書いてしまう方が楽だと思います。
例)
path:
data_file_name: /content/drive/MyDrive/colab_exp/data/livedoor.tsv
wandb
wandbは機械学習の結果等を管理してくれるツールです。
実験結果がリモートサーバーに自動で保存されるので、非常に使いやすいです。
事前登録が必要なので下記で済ませておいてください。
https://wandb.ai/site
wandbについて最低限の解説を行います。
なぜwandb?
同様のサービスとしてMLflowなどがありますが、pytorch_lightningを使うのであればwandbが圧倒的に楽です。
というのも連携が非常に優秀で以下のようにpytorch_lightningに組み込まれています。
from pytorch_lightning.loggers import WandbLogger
Trainerの引数に渡してやると、基本的な設定は完了です。簡単すぎる...
trainer = pl.Trainer(
max_epochs=cfg.training.n_epochs,
gpus=1,
progress_bar_refresh_rate=30,
callbacks=call_backs,
logger=wandb_logger,
)
Trainerに渡した後はtraining_epoch_end等の中で
self.log(f"val_loss", epoch_loss)
のように記述すると勝手にlogをとってくれます。
最後に以下の部分だけ解説します。
wandb_logger = WandbLogger(
name=("exp_" + str(cfg.wandb.exp_num)),
project=cfg.wandb.project,
tags=cfg.wandb.tags,
log_model=True,
)
checkpoint_path = os.path.join(
wandb_logger.experiment.dir, cfg.path.checkpoint_path
)
wandb_logger.log_hyperparams(cfg)
まず
wandb_logger = WandbLogger(
name=("exp_" + str(cfg.wandb.exp_num)),
project=cfg.wandb.project,
tags=cfg.wandb.tags,
log_model=True,
)
の部分ではwandbを初期化しています。
ここで重要なのがlog_model=Trueです。
WandbLogger.experiment.dir以下の*.ckptを全て、wandbのリモートサーバに保存してくれます。
ちなみにhydraを使っている以上、カレントディレクトがhoge_project_src/exp_xxx/outputs/XXXX-XX-XX/XX-XX-XX
になっているので
WandbLogger.experiment.dir==hoge_project_src/exp_xxx/outputs/XXXX-XX-XX/XX-XX-XX/wandb
になります。
よって、wandbのlog_modelを機能させるためには
checkpoint_path = os.path.join(
wandb_logger.experiment.dir, cfg.path.checkpoint_path
)
のようにpytorchのmodel checkpointのpathはWandbLogger.experiment.dir以下に設定してやる必要があります。
(一応イニシャライズした後でもWandbLogger.experiment.dirを変更できるのらしいので、ディレクトリ構成に納得いかない方は適宜カスタムしてください。)
最後に以下のポイントですがlog_hyperparamsという関数を作利用することで、ハイパーパラメータをwandbに保存できる上に、wandb上のtableなどで利用することができます。
wandb_logger.log_hyperparams(cfg)
実際にはwandbのtableとして以下のように表示することができます!

比較しやすくてめっちゃ便利ですね!
Colab(google drive)上での作業について
次にColab(google drive)上での作業についてですが、以下の手順です。
1 ディレクトリ構成
まず以下のようにディレクトリを構成してください。
ここでdataには
- 学習データ
- 評価データ
- 外部モデル
などを入れます。
hoge_progect
├── data
│ └── hoge.csv
└── maim.ipynb
2 maim.ipynb
次にmain.ipynbの中身は以下のようになります。
処理としては大きく以下に別れています。
- driveをマウント
- hoge_project_src以下に実験コードをclone
- パッケージをインストール
- main.pyを実行
- モデル以外の生成物をpush
from google.colab import drive
import os
drive.mount('/content/drive')
USER_NAME = githubのusername
PASSWORD = githubのpassword
REPO_NAME = githubのrepo name
EMAIL = githubに登録しているemail
CWD = google grive上のカレントディレクトリ(main.ipynbを配置しているディレクトリ)
SRC = 実験コードをcloneするディレクトリ(main.ipynbを配置しているディレクトリの一階層下)
EXP = 実験番号("exp_01"など)
CWD_SRC = os.path.join(CWD,SRC)
CWD_EXP=os.path.join(CWD_SRC,EXP)
%cd "/content"
!rm -rf {CWD_SRC}
!git clone https://{USER_NAME}:{PASSWORD}@github.com/{USER_NAME}/{REPO_NAME}.git {CWD_SRC}
%cd {CWD_EXP}
!pip install -r requirements.txt
!pip install hydra-core --upgrade
!python main.py
%cd ..
!git config --global user.email {EMAIL}
!git config --global user.name {USERNAME}
!git add .
!git commit -m "finish."
!git push origin main
なお、.gitignoreに*.ckptを追加するのを忘れないでください。(基本的にモデルは重いのでgitで管理しない方がいいです)
また、hydraが吐き出すファイルは(今回の手順だと)正直いらないので、最後のgit add ~ git pushの下りは省略しても大丈夫です。
更に、下記パラメータについて少し補足します。
CWD = google grive上のカレントディレクトリ(main.ipynbを配置しているディレクトリ)
SRC = 実験コードをcloneするディレクトリ(main.ipynbを配置しているディレクトリの一階層下)
EXP = 実験番号("exp_01"など)
下記のような構成でexp_2を実行したい場合、
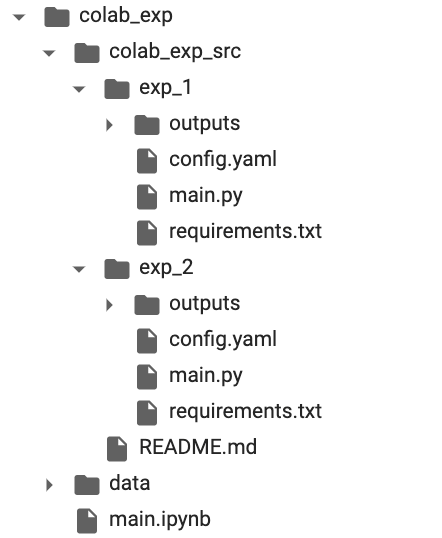
各パラメータは以下のようになります。
CWD = "/content/drive/MyDrive/colab_exp"
SRC = "colab_exp_src"
EXP = "exp_2"
以上で終了です!!!
実際に実験を行ってみる
ここでは実際に実験を行ってみましょう。
livedoorのtext分類をlearning rateを変更して行います。
- exp_01ではlr:0.01
- exp_02ではlr:0.001
なお以下のレポジトリとgoogle driveから再現することができます。
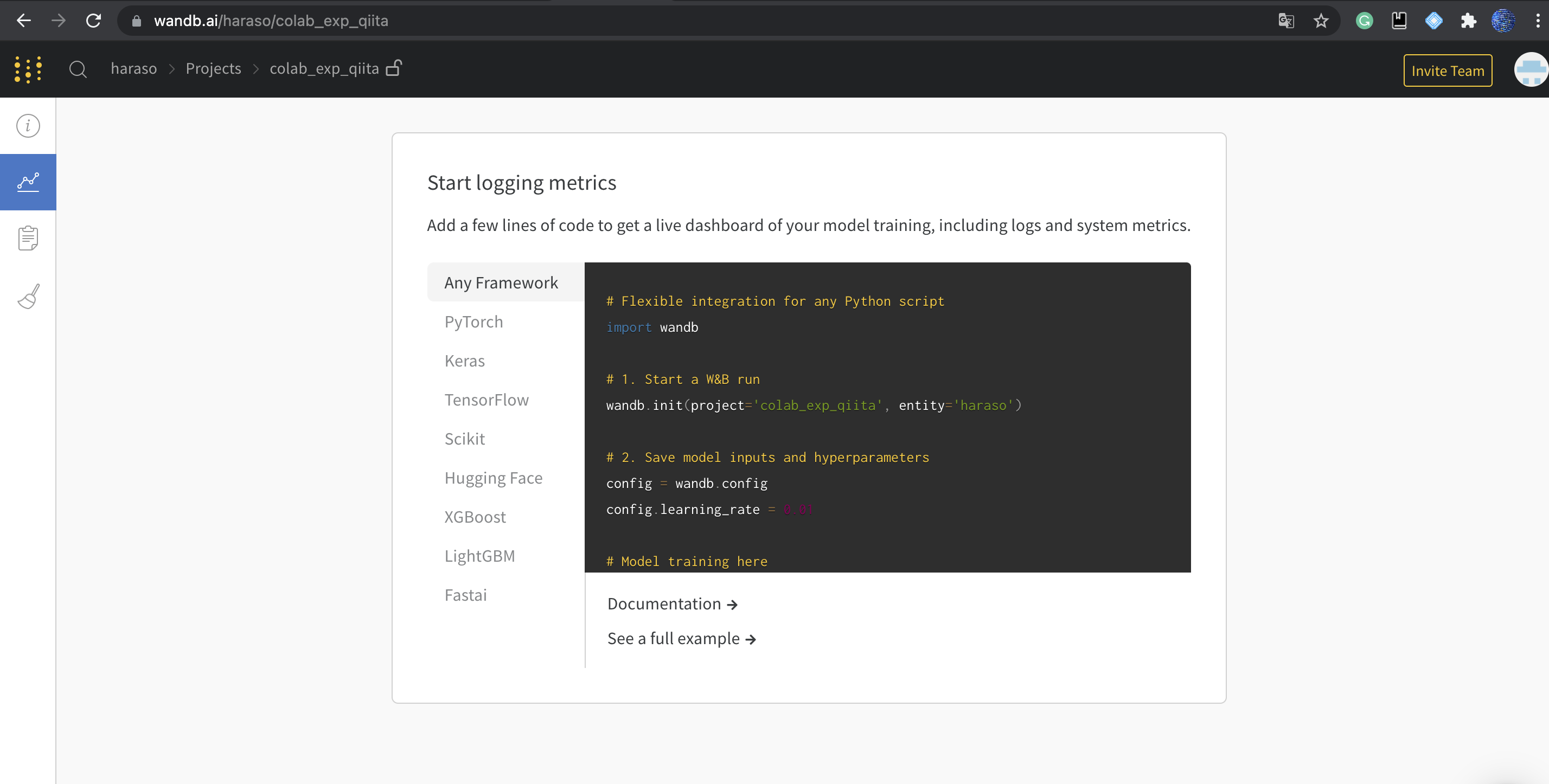
1 wandbでアカウント作成&プロジェクト作成
wandb(url)にアクセスし、アカウント作成
その後新規プロジェクトを作成し、以下のような画面になればOKです。
2 実験コードを作成
github上でレポジトリを作成して、実験コードを作成します。
ここでconfig.yamlには先ほど設定したwandbのプロジェクト名を書いておきます。
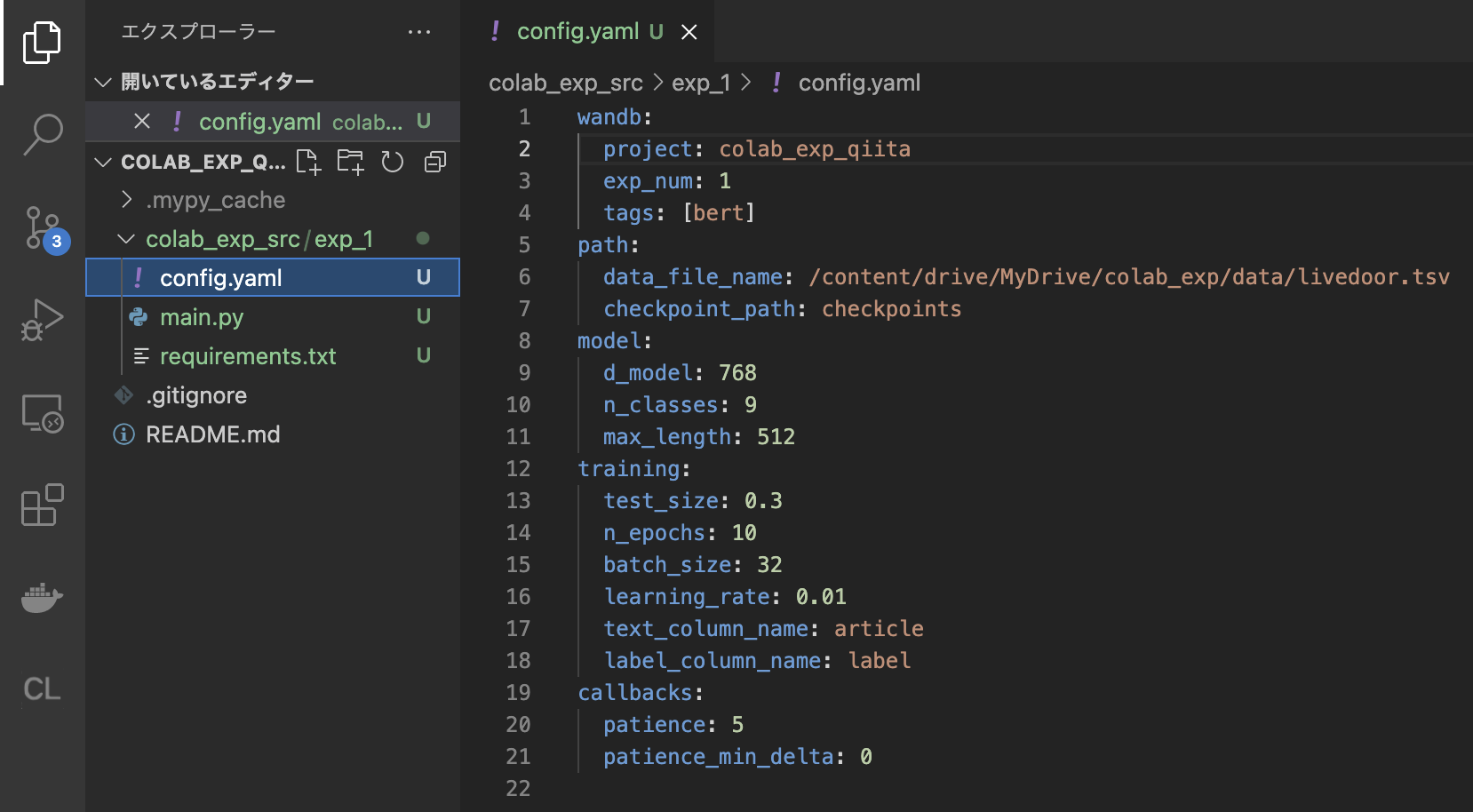
今回は以下のようなコードを作成しました。
3 google dirve上でディレクトリを構成しcolabで実行
以下のように構成したのち、main.ipynbを前述の通り編集します。(コピペして、大文字の変数だけカスタムしてください)
colab_exp
├── data
│ └── train.csv
└── maim.ipynb
一応サンプルのnotebookを貼り付けておきます。
後は実行すれば完了です。
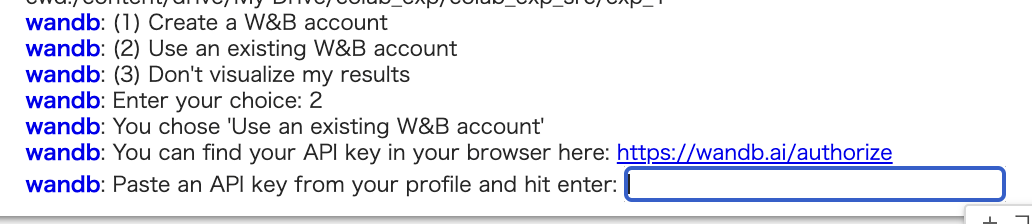
wandbに関して以下のような表示が出ますが、2を選択し、指示されたkeyを貼り付ければOKです。

4 次の実験へ(実験コード)
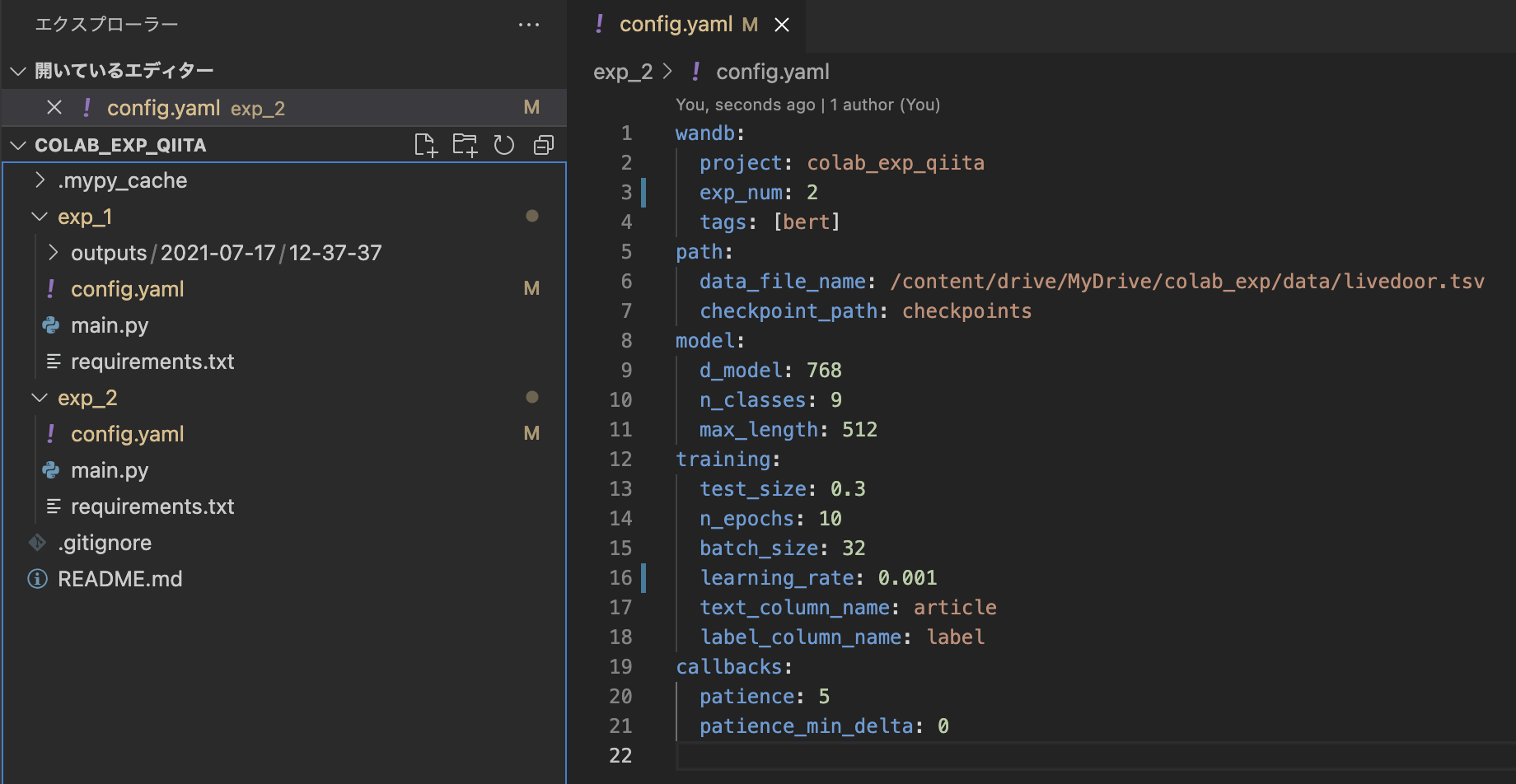
次はgit pullした後新たにexp_02というフォルダを作成し、そこに実験コードを作成していきます。
ここでconfig.ymalのnameと学習率を変更しておきます。
5 次の実験へ(colab)
main.ipynbの
EXP = "exp_1"
を
EXP = "exp_2"
に変更して実行すれば完了です!
6 実験結果の確認
以下のように実験結果を確認することができます。
また、モデルも保存されています。
終わりに
今回はcolaboratoryで動くgit+Pytorch-lightning+hydra+wandbの1実験1スクリプト実験環境を作成しました。
正直colabがインタラクティブな操作を期待しているので、かなり黒魔術色が濃い記事になってしまったと思います。が、それを踏まえてもcolab proのコスパは魅力的ですので、もしよければ試してみてください。
改善点等多々あると思いますので、是非コメントにて指摘してくださると非常に助かります。
参考文献