はじめに
本投稿は前投稿後コードを見て改善したいと思ったところが
いくつかあったので改善したいと考え、
コードの修繕をすることにしました。
なお、改悪している気はしないのですが、
改悪になっていることもありますので、ご了承ください。
開発環境
OS:Windows10 64bit 1903
CPU/Memory:i5-7200U/8GB
python 3.6.8 64bit版
エディター(?):VSCode version 1.38.1
コードの復習
前回の完成品のコードを再度ここにかいておきます。
from pixivpy3 import *
from time import sleep
import json
import os
# folder check
if not os.path.exists("./pixiv_images"):
os.mkdir("./pixiv_images")
if not os.path.exists("./pixiv_images/bookmark"):
os.mkdir("./pixiv_images/bookmark")
# api login
aapi=AppPixivAPI()
aapi.login("Mail", "Pass")
# main
bookmark_count=input("your bookmark count number please.\n only public bookmark:")
bookmark_count=int(bookmark_count)//30+1
json_user_collect = aapi.user_bookmarks_illust("user-id", restrict='public')
while bookmark_count > 0:
print("#"+str(bookmark_count))
num=len(json_user_collect.illusts)
bookmark_count=bookmark_count-1
for illust in json_user_collect.illusts[:num]:
writer=illust.user.name.replace("/","-")
if not os.path.exists("./pixiv_images/bookmark/"+writer):
os.mkdir("./pixiv_images/bookmark/"+writer)
savepath="./pixiv_images/bookmark/"+writer
aapi.download(illust.image_urls.large,path=savepath,name=str(illust.title.replace("/","-"))+".png")
print("#"+str(writer)+":"+str(illust.title))
sleep(1)
if bookmark_count>0:
next_url=json_user_collect.next_url
next_qs=aapi.parse_qs(next_url)
json_user_collect=aapi.user_bookmarks_illust(**next_qs)
print("終了しました。")
こんな風ですが今回修繕する箇所は
- import周り
- ログイン周り
- json取得時のエラー処理
- download処理のエラー処理
この4つを考えていきます。
第一ラウンド-importの修繕
まずはコードを見てみましょう
from pixivpy3 import *
from time import sleep
import json
import os
前から気になっていた
from pixivpy3 import *
このコードではワイルドカードを用いてpixivpy3から、
importしているわけなのですが、
このワイルドカードを使ったimportは
正直よろしくない
というのを聞いたことがあったので、
ここを直そうと思います。
あの頃はfrom ~ import * の意味を知らなかったし、
普通にimportだけではどうにもできなかったので使っていましたが、
コレ自体で、
pixivpyのすべてのAPIをimportしていることがわかりました。
それを知ったのは、Vscodeの機能の一つ、
定義へ移動
です。
多分他のソフトにもあると思いますが一応使い方を記しておきます。
1.該当箇所にカーソルを合わせて右クリック
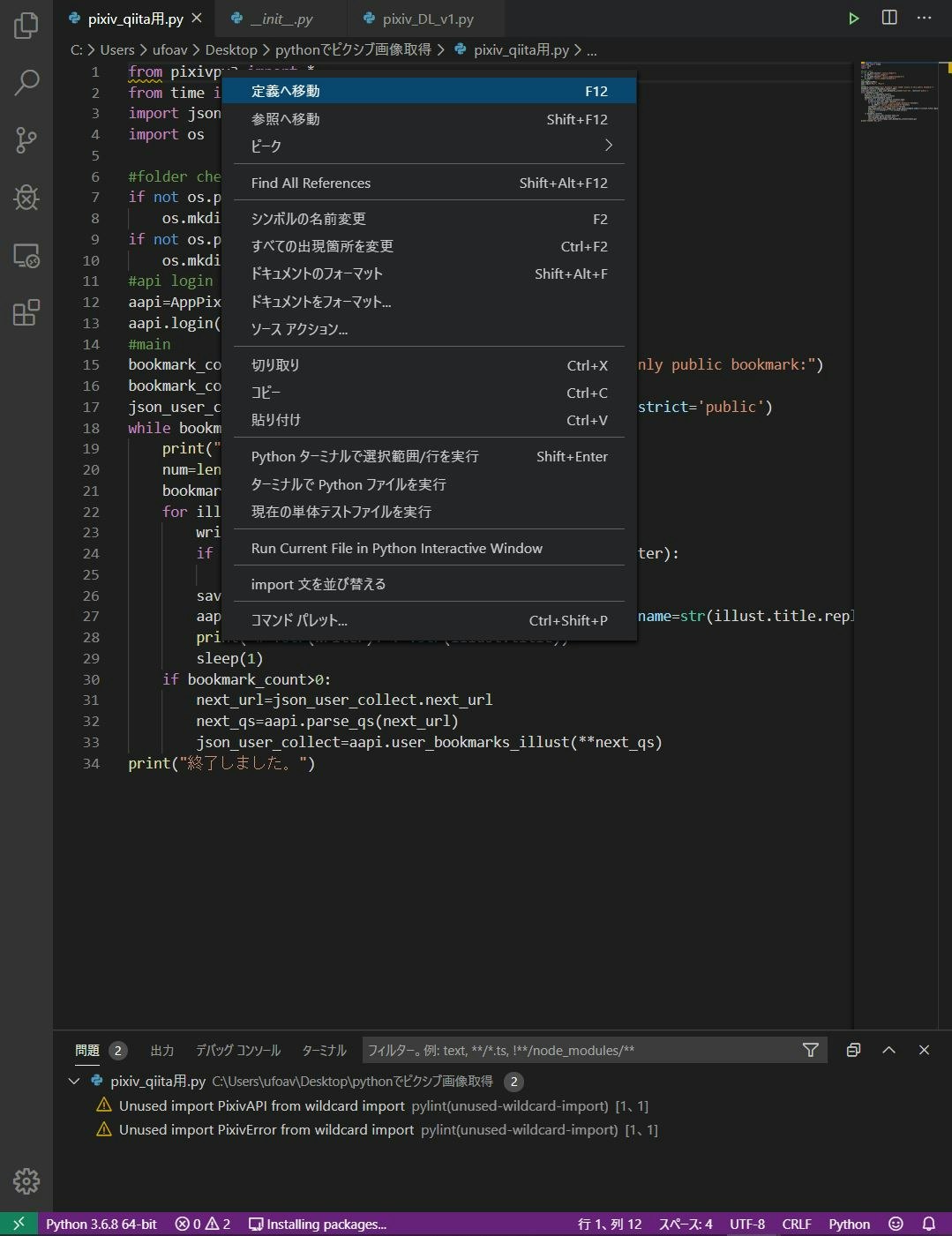
2.”定義へ移動”を押す
3.見れる
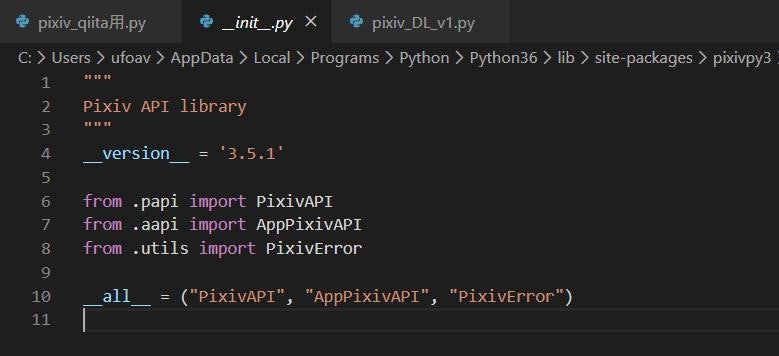
ここで気づいたのは、
__all__ = ("PixivAPI", "AppPixivAPI", "PixivError")
これ全部をimportしてるのでは?
ということに気づいたのでコードを
from pixivpy3 import *
から
from pixivpy3 import PixivAPI
from pixivpy3 import AppPixivAPI
from pixivpy3 import PixivError
へと変更してみました。
するとこれで実行できてしまいました。
成功です。
第2ラウンド-ログイン周り
パスワードを平文でコード上に書くと事故りそうなので、
とりあえずは、手入力を毎回求める仕組みにします。
aapi=AppPixivAPI()
aapi.login("Mail", "Pass")
これを
inputでも使って、
mail=input("APIログインのために\npixivのmailアドレスを入力:")
password=input("pixivのパスワードを入力")
aapi=AppPixivAPI()
aapi.login(mail, password)
無難ですね。
第3ラウンド~json部分のエラー処理
こちらも無難に行きましょう。
改変前
json_user_collect = aapi.user_bookmarks_illust("user-id", restrict='public')
おっと、これよく見たら、useridも自分でコードを書き換えないと行けないみたいですね。
APIのデータを使って置き換えておきます。
さて、
エラー処理には、tryとexceptを使いますが、
使い方をあんまり理解していないので、簡単なものでなんとかします。
今回はとりあえずエラーかどうかさえ分かればいいので、
myself_user_id=int(aapi.user_id)
try:
json_user_collect = aapi.user_bookmarks_illust(myself_user_id, restrict=bookmark_type)
except:
print("error")
sleep(10)
quit()
一行目でAPIから取得したユーザーのIDを変数に代入しておきます。
あとはtryでごまかしておきました。
第4ラウンド~download処理のエラー処理
一番の鬼門、というかダウンロードの際一番障害になりやすいとこですね。
何故そうなのかは、下に説明をざっくりかいておきます。
理由
改変前コード
aapi.download(illust.image_urls.large,path=savepath,name=str(illust.title.replace("/","-"))+".png")
こちらもtryとexceptと更に、continueを使っていきます。
改変後
try:
aapi.download(illust.image_urls.large,path=savepath,name=str(illust.title.replace("/","-"))+".png")
except:
print("error")
print("#"+str(writer)+":"+str(illust.title))
sleep(1)
continue
tryとexceptを使って、それっぽくなりました。
本当ならCSVにでも出力したいとこですが、今回はやめておきます。
終わりに
閲覧いただきありがとうございました。
今回は修繕というとこで、主に異常系を中心に見ていきました。
今後は、ランキングの取得や、エラーだった作品の情報のCSV出力、
更には機械学習などをやっていきたいと思います。
機械学習とかは初心者には厳しい予感しかしませんが、
頑張っていきますので、ご指南のほど宜しくおねがいします。
最後にコード全体を見ておしまいです。
コード全体
from pixivpy3 import PixivAPI
from pixivpy3 import AppPixivAPI
from pixivpy3 import PixivError
from time import sleep
import json
import os
# folder check
if not os.path.exists("./pixiv_images"):
os.mkdir("./pixiv_images")
if not os.path.exists("./pixiv_images/bookmark"):
os.mkdir("./pixiv_images/bookmark")
# api login
mail=input("APIログインのために\npixivのmailアドレスを入力:")
password=input("pixivのパスワードを入力")
aapi=AppPixivAPI()
aapi.login("Mail", "Pass")
# main
bookmark_count=input("your bookmark count number please.\n only public bookmark:")
bookmark_count=int(bookmark_count)//30+1
myself_user_id=int(aapi.user_id)
try:
json_user_collect = aapi.user_bookmarks_illust(myself_user_id, restrict=bookmark_type)
except:
print("error")
sleep(10)
quit()
while bookmark_count > 0:
print("#"+str(bookmark_count))
num=len(json_user_collect.illusts)
bookmark_count=bookmark_count-1
for illust in json_user_collect.illusts[:num]:
writer=illust.user.name.replace("/","-")
if not os.path.exists("./pixiv_images/bookmark/"+writer):
os.mkdir("./pixiv_images/bookmark/"+writer)
savepath="./pixiv_images/bookmark/"+writer
try:
aapi.download(illust.image_urls.large,path=savepath,name=str(illust.title.replace("/","-"))+".png")
except:
print("error")
print("#"+str(writer)+":"+str(illust.title))
sleep(1)
continue
print("#"+str(writer)+":"+str(illust.title))
sleep(1)
if bookmark_count>0:
next_url=json_user_collect.next_url
next_qs=aapi.parse_qs(next_url)
json_user_collect=aapi.user_bookmarks_illust(**next_qs)
print("終了しました。")
おしまい。