GPTの歴史
ここ数年でその名前が世界的に普及したChatGPT。その前にはGPT-1、GPT-2、GPT-3といった進化を遂げてきました。本記事では、GPT-1、2、3それぞれの元論文をもとに、GPTの進化の過程をざっくりと解説します。
1. GPTとは
GPTとは、Transformerベースの学習済み大規模言語モデルで、教師なし学習と教師あり学習を組み合わせた半教師あり学習を使用しています。

1.1 教師なし学習フェーズ
教師なし学習フェーズでは、大量のテキストコーパスから得たトークン列に対して、マルチヘッドセルフアテンション機構を持つTransformerデコーダにより、次に続く単語の出現確率が最大になるように学習を進めます。
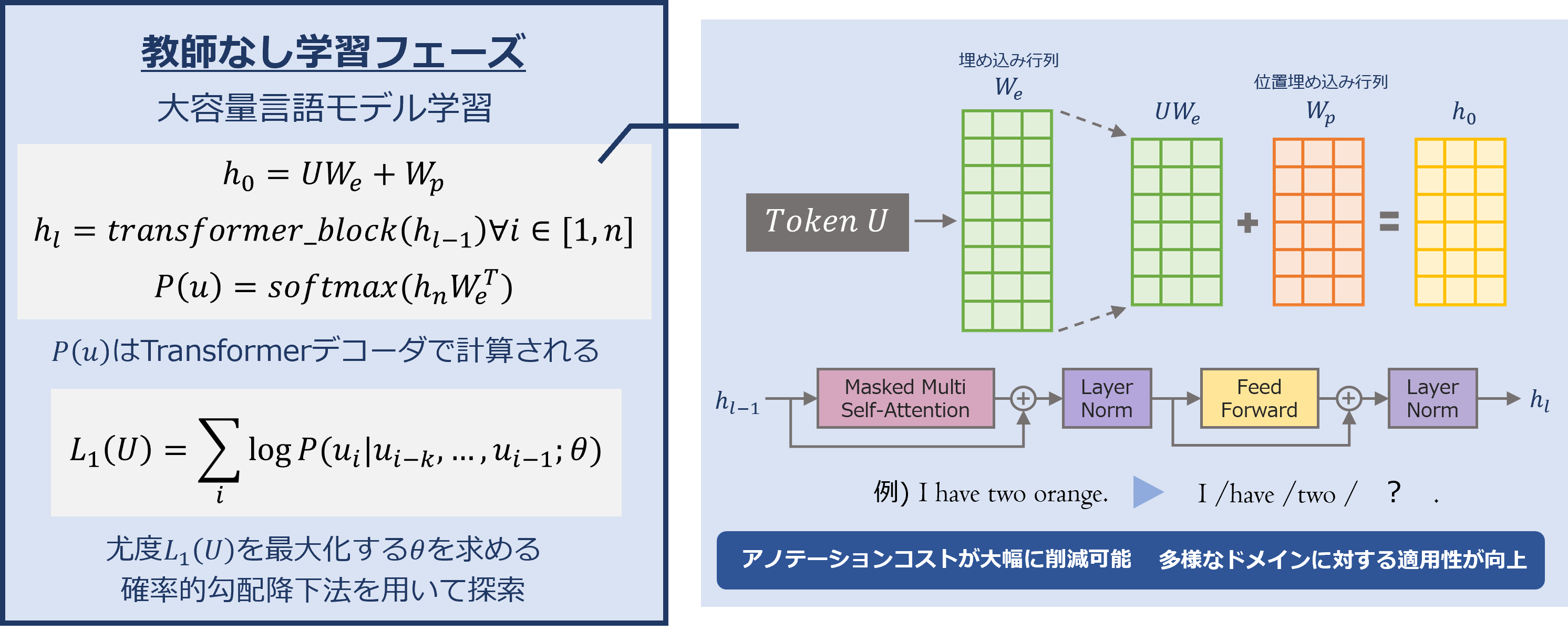
1.1.1 事前学習用データセットについて
事前学習には、Smashwordsと呼ばれる無料小説本(11,038冊)を含む大規模テキストコーパス(約4.5GB)を用い、登場人物の心情変化やストーリーの状況変化などを学習させています。
- 前処理:ffty2.0によるUnicord問題の修正、SpaCy3.0を用いたトークナイズ処理を実施。
1.2 教師あり学習フェーズ
教師なしフェーズで学習したモデルを、解きたいタスクに応じてファインチューニングします。汎用性を高めるため、ファインチューニング時のアーキテクチャはタスクごとに同質の構造を持てるよう工夫されています。
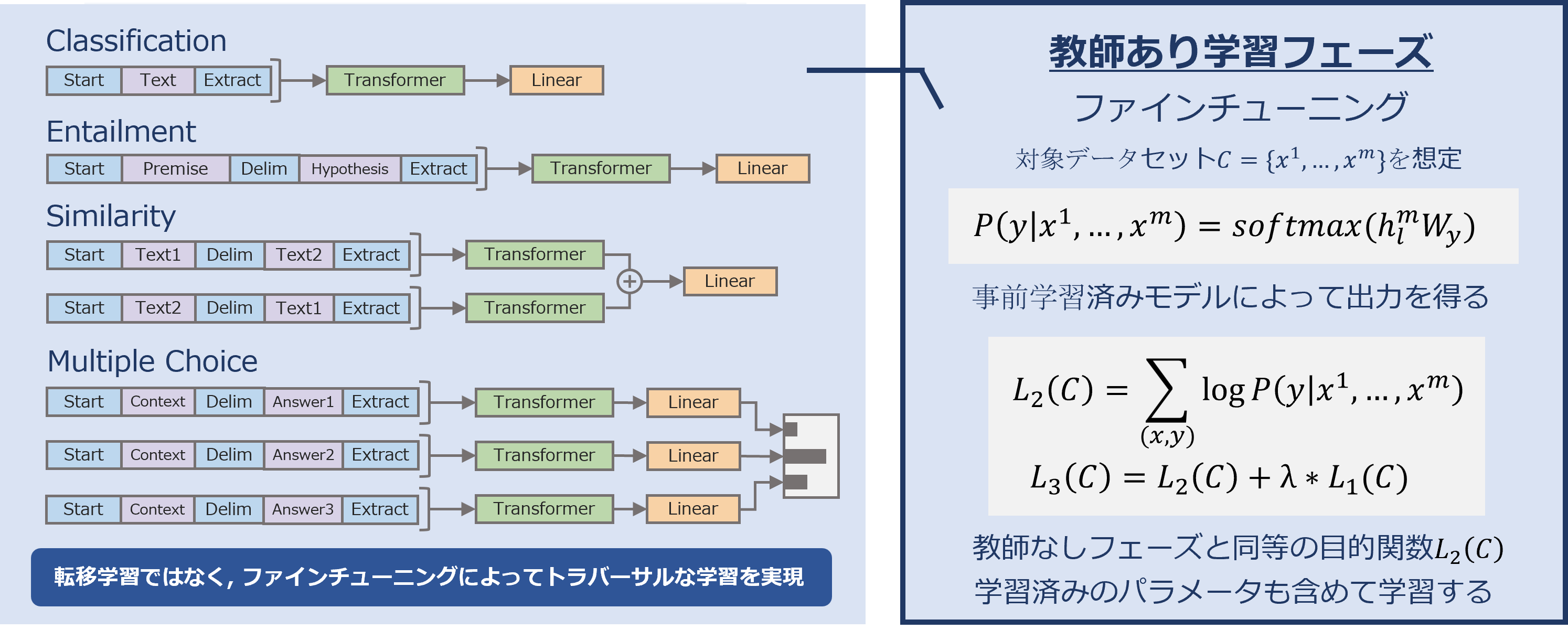
1.3 GPT-1の性能評価
GPT-1は次のタスクで評価されています。
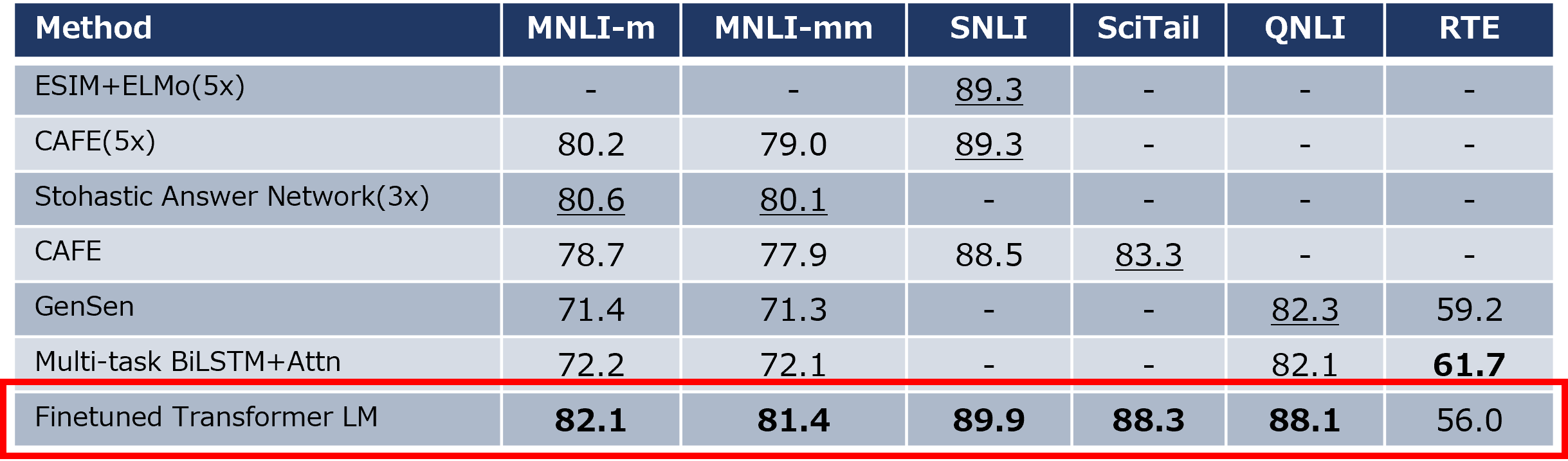
1.3.1 自然言語推論 (NLI) タスク
5つのデータセットで評価され、4つで当時の言語モデルを超える精度を達成しました。これにより、複合文の合理的推論や言語的曖昧性の処理能力が示されました。
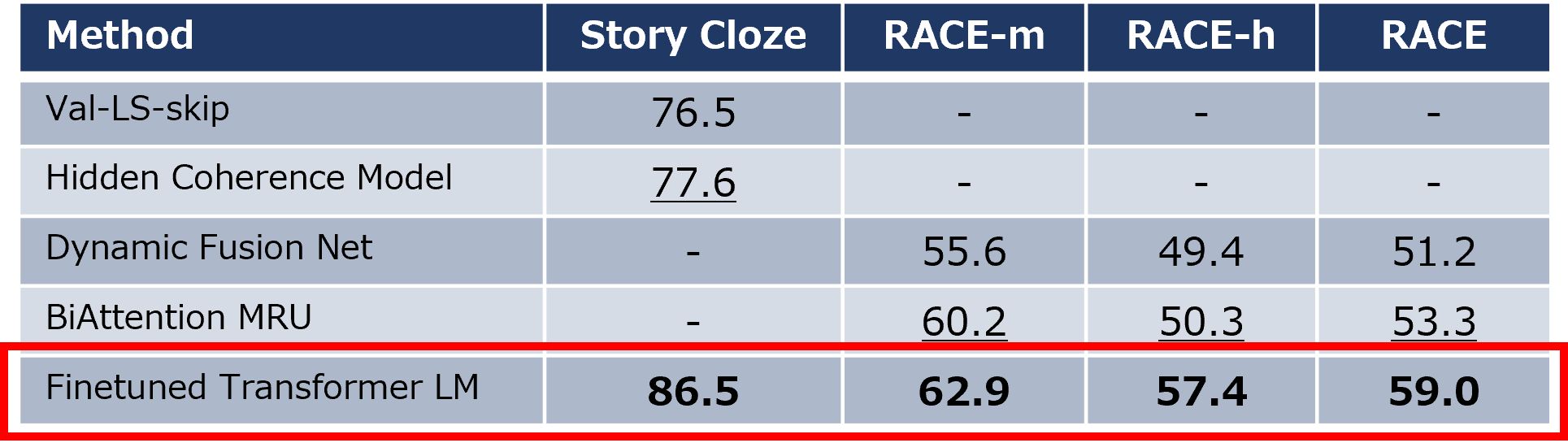
1.3.2 質問応答 (QA) タスク
質問文に対する回答タスクでは、2つのデータセットで評価され、すべてのデータセットで当時の最高精度を達成しました。長文の文脈を効果的に捉える能力が評価されました。
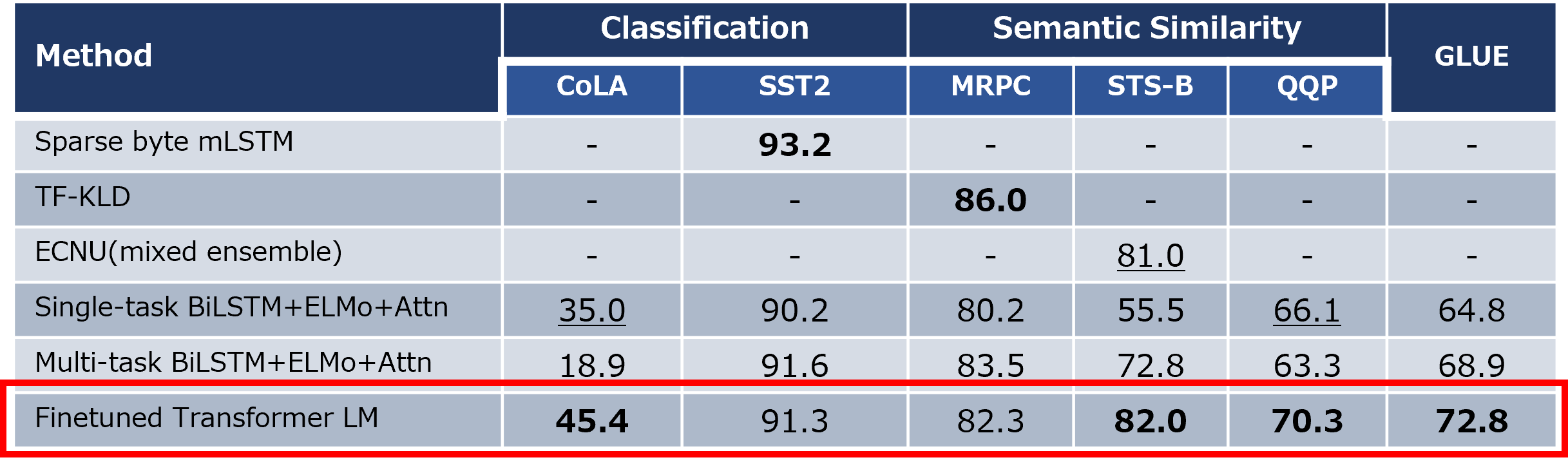
1.3.3 テキスト分類・意味的類似性タスク
テキスト類似性判別タスクでは、5つのデータセットで評価され、3つのデータセットで従来より大幅な改善が実現しました。
2. GPT-2への進化
GPT-2では、より多様なタスクに対応可能な汎用的な言語モデルを目指しました。構造自体はほぼ同じですが、学習データの増加に伴い、モデルのパラメータも増加しています。
2.1 GPT-2のZero-Shot学習用データ
redditと呼ばれる掲示板型SNSをクローリングし、**独自の学習データセット(約40GB)を作成しました。また、学習データの圧縮にはBPE(Byte Pair Encoding)**を用いてコストを低減しています。
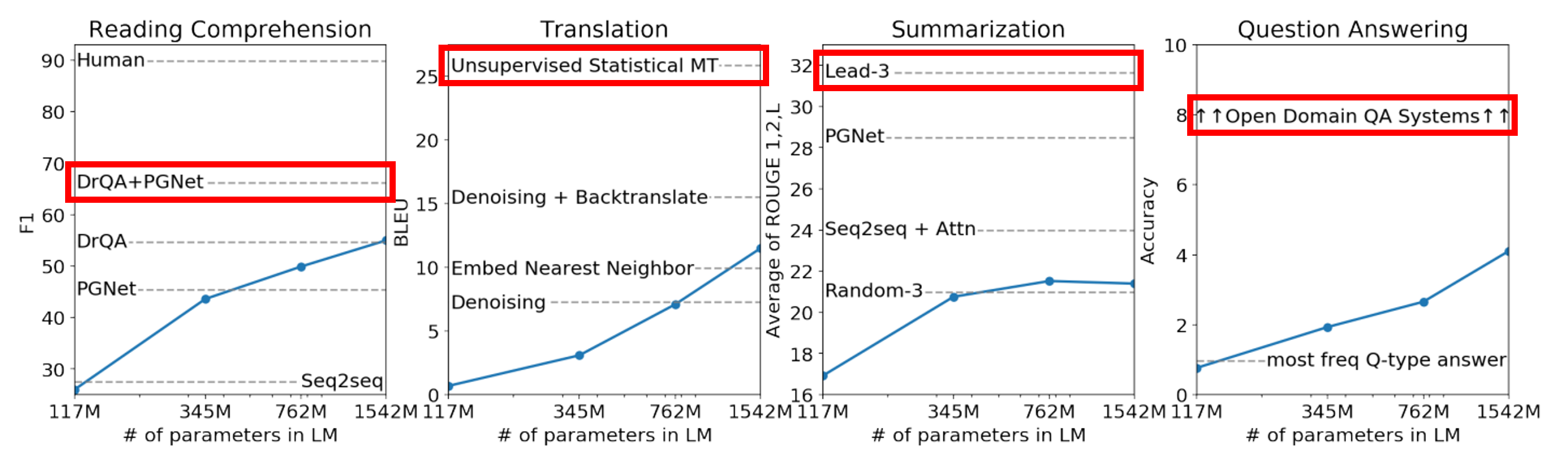
2.2 GPT-2の性能評価
各タスクのデータセットで読解、翻訳、要約、質疑応答タスクを評価しましたが、Zero-Shotモデルとしては高い性能を示しつつも、特化モデルには精度面で劣る結果となりました。
3. GPT-3への進化
GPT-3では、さらに多くのデータ(約570GB)を使用し、大規模なモデルによる精度向上を図りました。特化型モデルよりも精度の高い汎用モデルの実現を目指しています。
3.1 GPT-3の性能評価
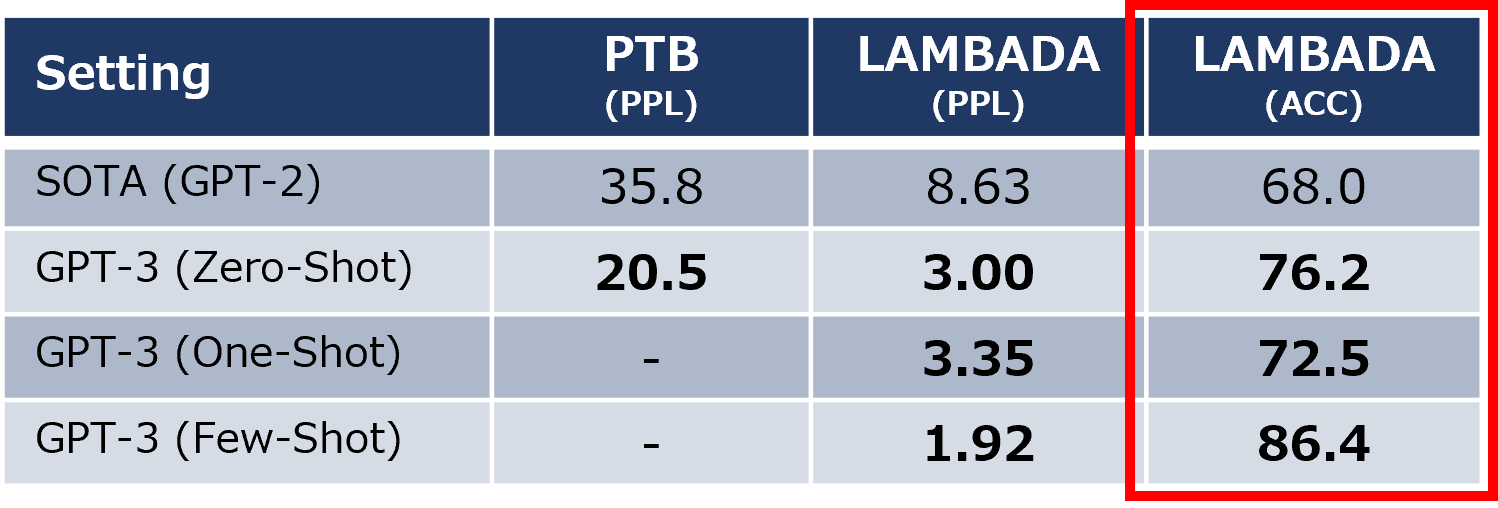
3.1.1 単語予測タスク
任意の文の最後の単語を予測するタスクで、2つのデータセットで当時のSOTAを達成しました。これは、データ量の増加による効果です。
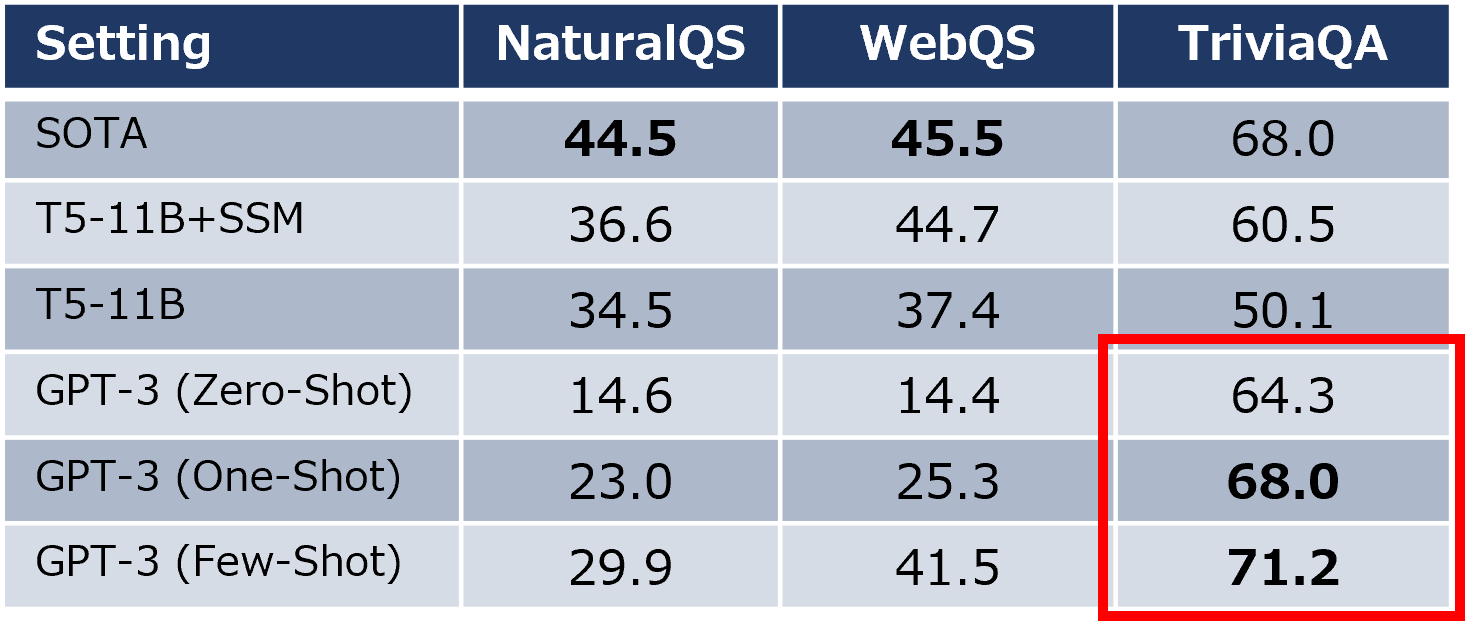
3.1.2 質問応答タスク
TriviaQAデータセットでSOTAを達成し、質問応答に特化したモデルを上回る性能を示しました。
3.1.3 翻訳タスク
フランス語・ドイツ語から英語への翻訳でSOTAを達成。単語の確率的出現を用いるだけで翻訳タスクに対応できることを示しました。
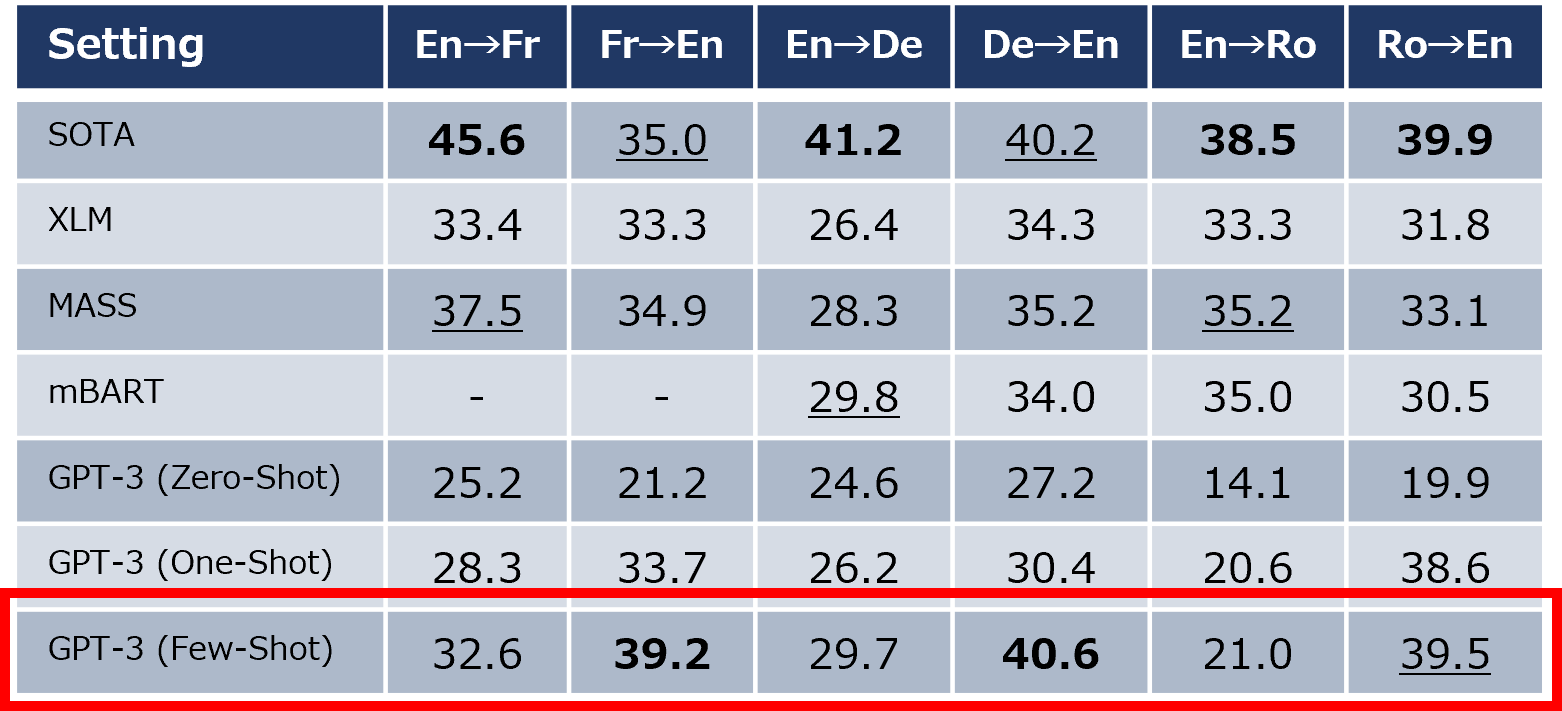
この後、UIの改善や強化学習(RLHF)、画像とのマルチモーダル学習により、GPT-3.5やGPT-4といった進化が続きます。
参考文献
- RADFORD, Alec, et al. Improving language understanding by generative pre-training. 2018.
- RADFORD, Alec, et al. Language models are unsupervised multitask learners. OpenAI blog, 2019, 1.8: 9.
- Brown, Tom, et al. Language models are few-shot learners. Advances in neural information processing systems 33 (2020): 1877-1901.
マイページ紹介