はじめに
前回記事:Databricks利用時にかかる費用から、Databricksのクラスター設定値を模索する
前回はDatabricks利用時にかかる料金とクラスター設定値についてまとめました。
しかし、こういった内容を全員に浸透させるのは難しい部分もあったりするかと思います。
今回はそういった場合向けに管理者側でクラスター設定値に縛りを入れることのできる「Databricksのクラスターポリシー設定・権限設定」についてまとめます。
誤り、見落とし等ありましたらご指摘いただければと思います。
また、本機能はパブリックプレビューということもあり内容が変わる可能性もあるので、自力でもアップデートかけていきますがもし見つけた際はご指摘いただけると助かります。
UIについては2022/5/30時点のもので、言語設定を日本語にしています。
利用するクラウド環境はAWSとします。(Azureについてもドキュメントの範囲でまとめます。)
※GCPについては公式ドキュメントに設定項目一覧や推奨設定が項目名しかなく存在しないため一旦省きます。
参考にしたサイト
クラスターポリシーの管理(Databricks公式ドキュメント)
AWS:https://docs.databricks.com/administration-guide/clusters/policies.html
GCP:https://docs.gcp.databricks.com/administration-guide/clusters/policies.html
Azure:https://docs.microsoft.com/ja-jp/azure/databricks/administration-guide/clusters/policies
Takaaki Yayoi様によるAWS公式ドキュメントの抄訳:Databricksクラスターポリシーの管理
その他関連する公式ドキュメント
Clusters API 2.0
Cluster access control
1.クラスターポリシーの設定方法について
各設定方法の説明については、上記参考サイトにてTakaaki Yayoi様がされているので、本記事では実際のUI上での見え方について記載していこうと思います。
なお、各項目の値についてはUI上の右上の「JSON」をクリックすることでUIから設定しようとしている値を見ることができます。
許可リストを作る際の実際の値については公式ドキュメントには見当たらなかったので、ここから確認するのが正確そうです。
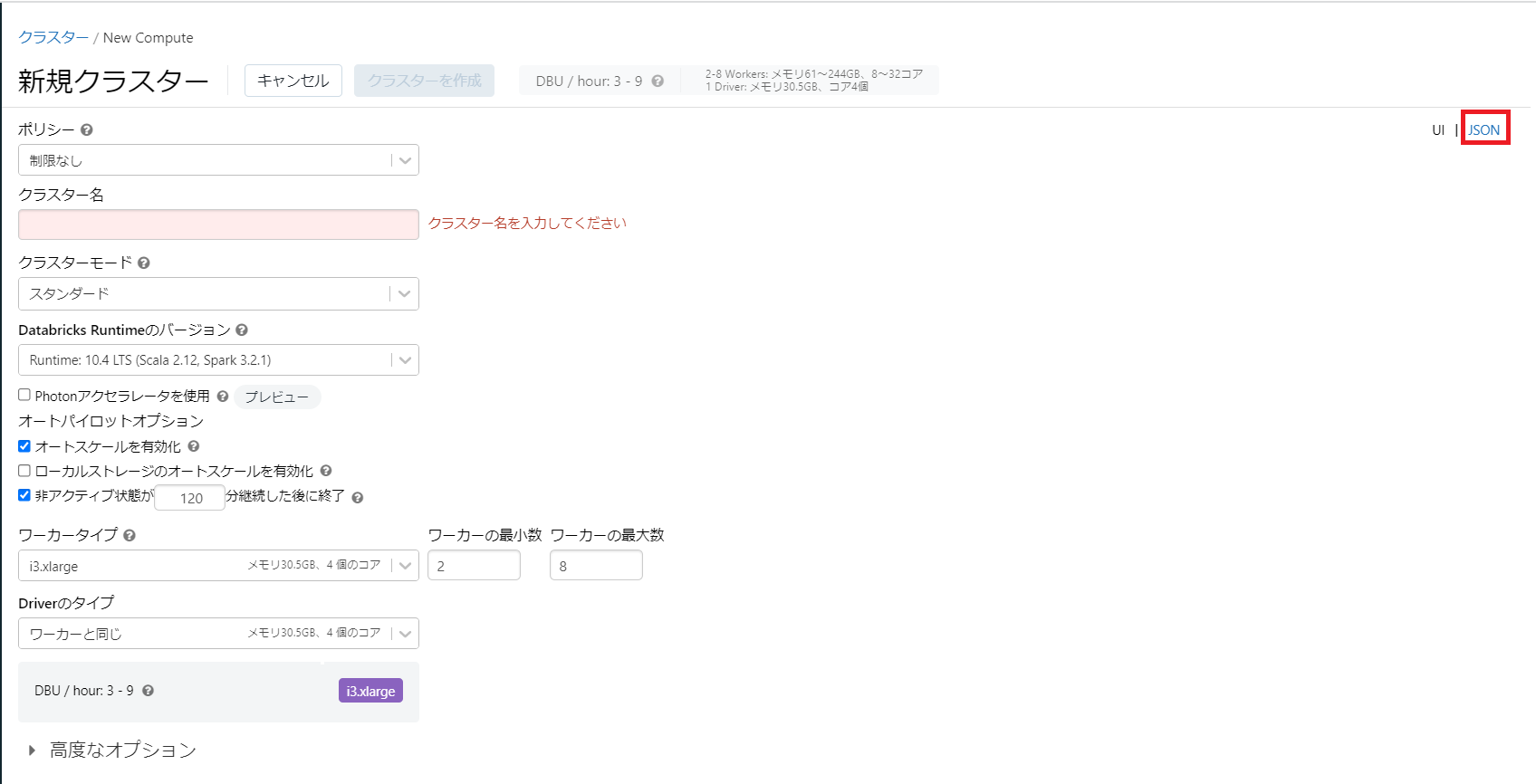
↓
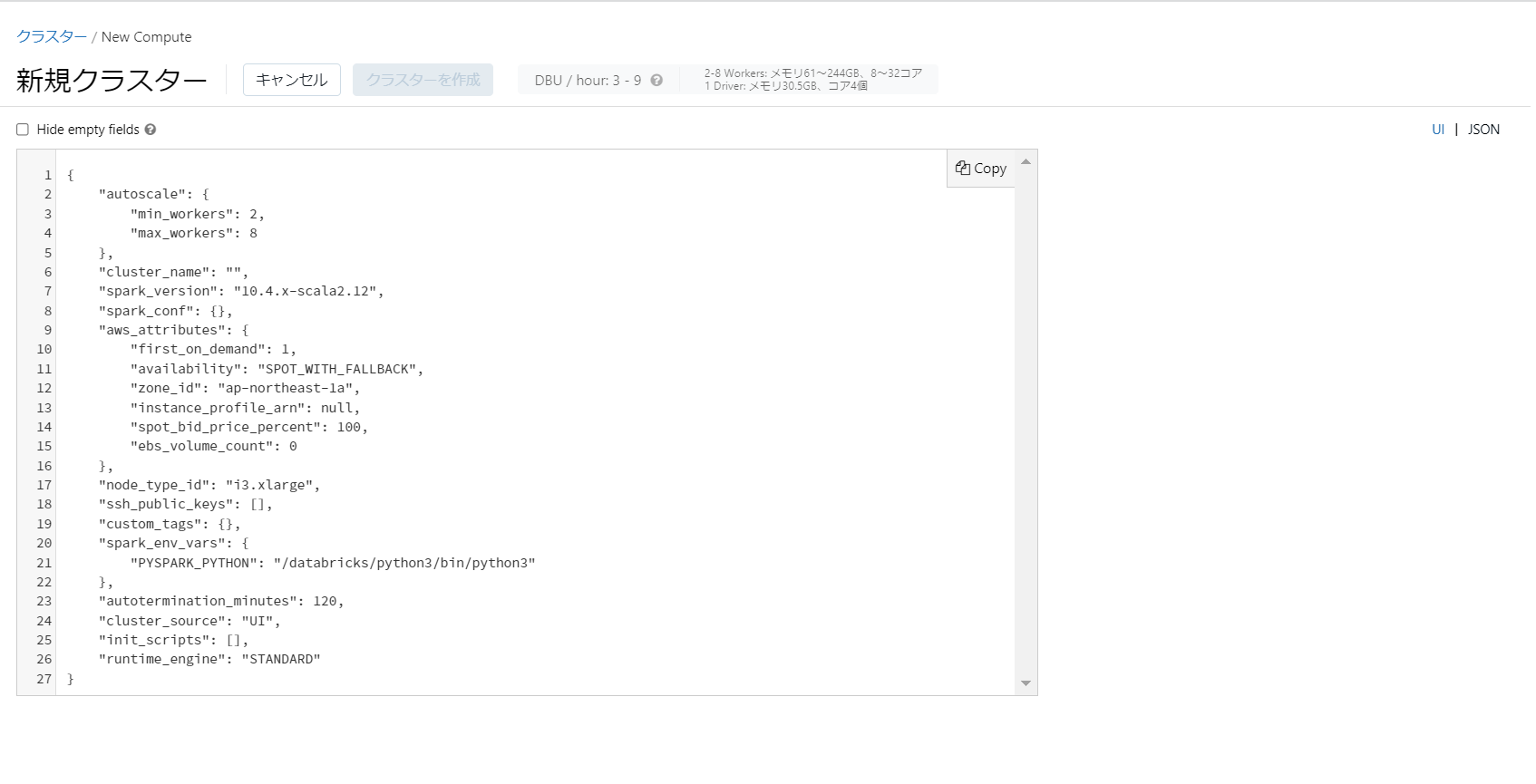
- 固定ポリシー
値を設定値で固定します。
{
"spark_version": {
"type": "fixed",
"value": "7.3.x-scala2.12",
"hidden": false
},
"driver_node_type_id": {
"type": "fixed",
"value": "i3.2xlarge",
"hidden": true
}
}
見え方
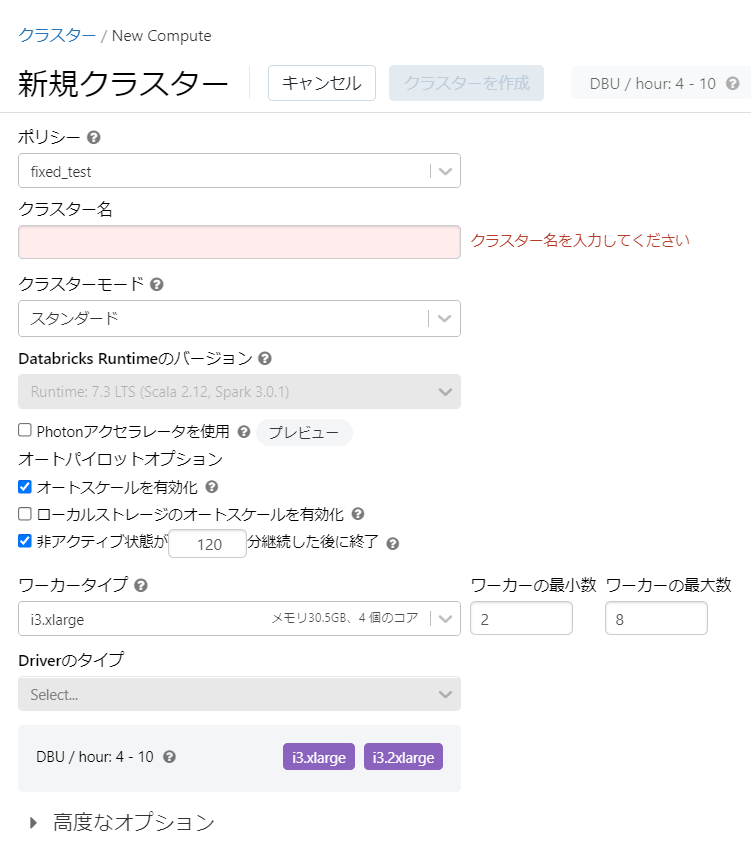
Driverタイプのhiddenをtrueにした際に項目がSelectになっていますが、すぐ下のDBU計算結果を見るにi3.2xlargeが設定されているように見受けられます。
- 禁止ポリシー
値を使用不能にします。
{
"enable_elastic_disk": {
"type": "forbidden"
}
}
見え方
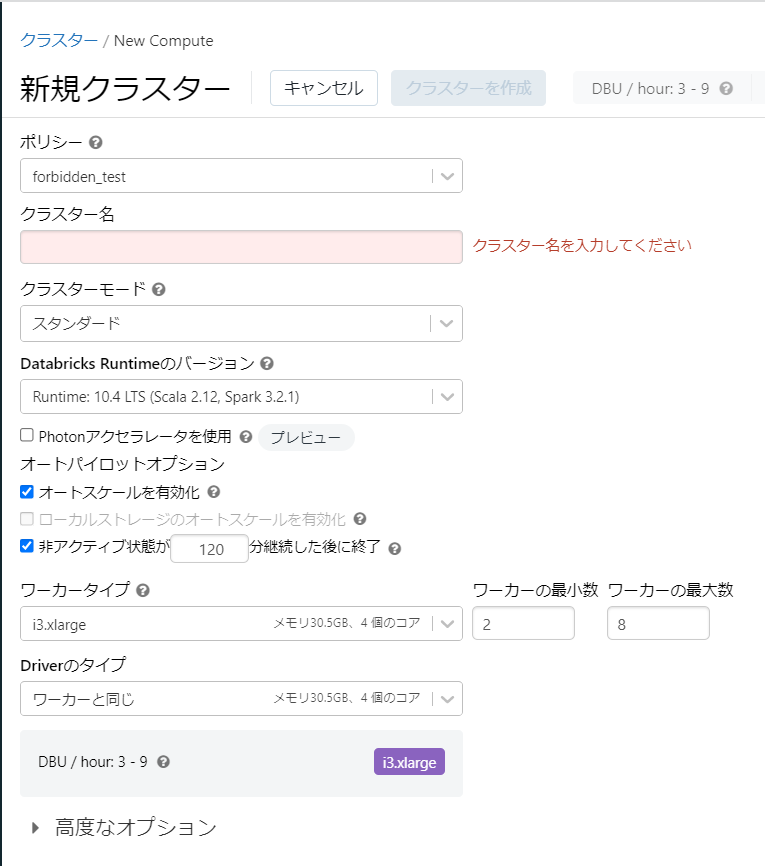
必須項目等、項目によってはこれを設定するとクラスター作成が不能になります。
- 制限ポリシー:共通フィールド
値に初期値をセットします。
{
"instance_pool_id": {
"type": "unlimited",
"isOptional": true,
"defaultValue": "********"
}
}
※上記例のdefaultValueはプールの「構成」タブ下部の「タグ」内の「DatabricksInstancePoolId」を使用。
見え方
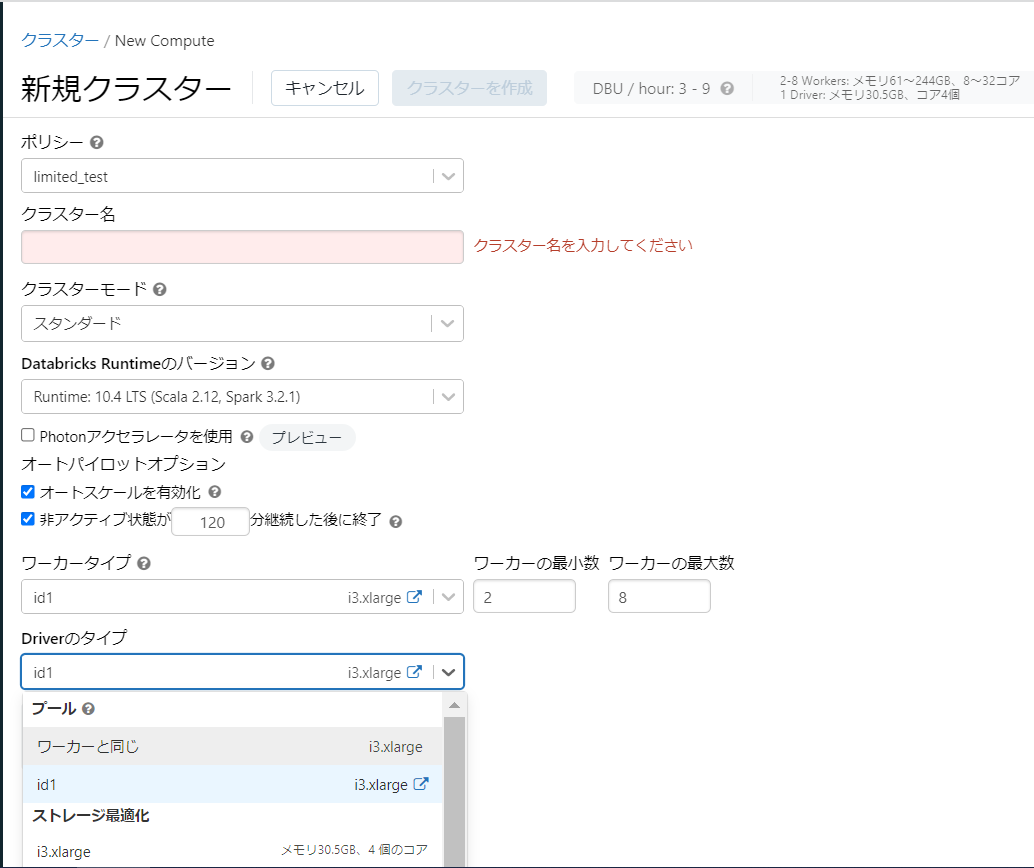
初期値を設定し、かつ変更可能になっています。
- 許可リストポリシー
選択可能な値のリストを生成します。
{
"spark_version": {
"type": "allowlist",
"values": [
"10.4.x-scala2.12",
"7.3.x-scala2.12"
]
}
}
見え方
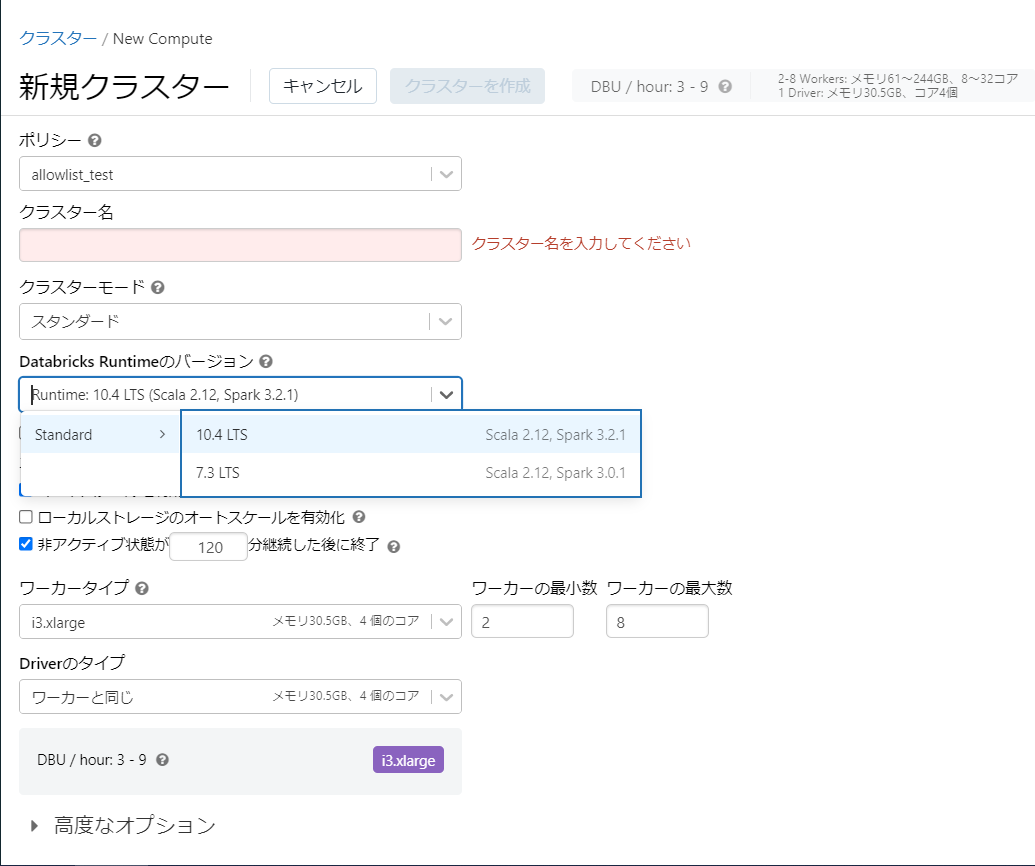
Sparkのバージョンがリスト指定したもののみ選択可能になります。
- ブロックリストポリシー
使用できない値を定義します。
{
"spark_version": {
"type": "blocklist",
"values": [
"7.3.x-scala2.12"
]
}
}
見え方
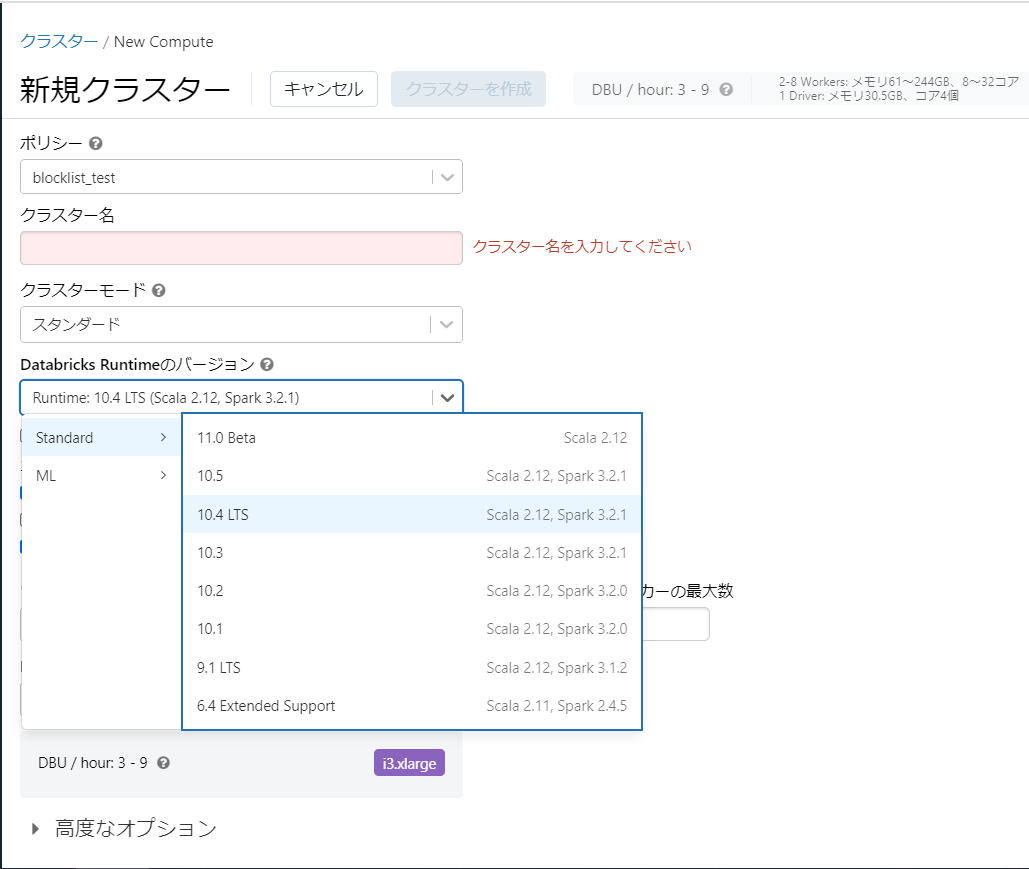
ブロックリストに指定した7.3のみリストから消えている事が確認できます。
- 正規表現ポリシー
値を正規表現で制限します。
{
"spark_version": {
"type": "regex",
"pattern": "10.[1-9].*"
}
}
見え方
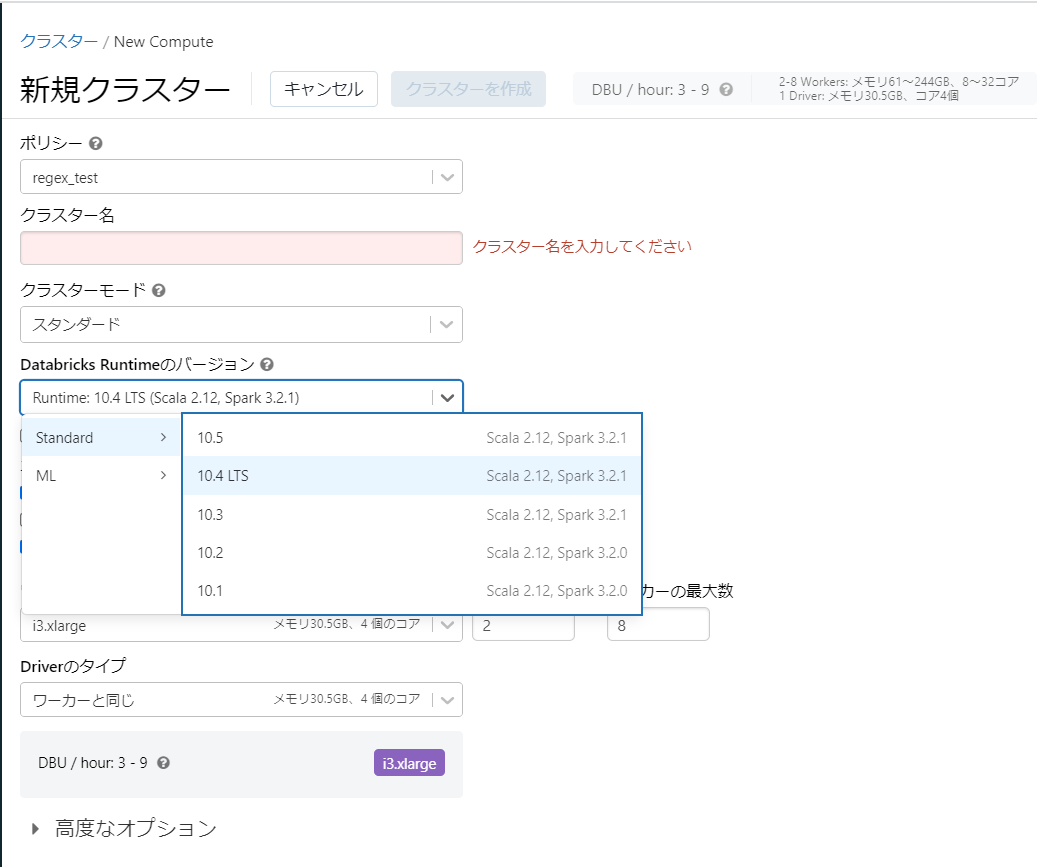
選択可能な値が正規表現で定義した値で縛られていることが確認できます。
- レンジポリシー
値を数値の範囲で制限します。
{
"num_workers": {
"type": "range",
"minValue": 5,
"maxValue": 10
}
}
見え方
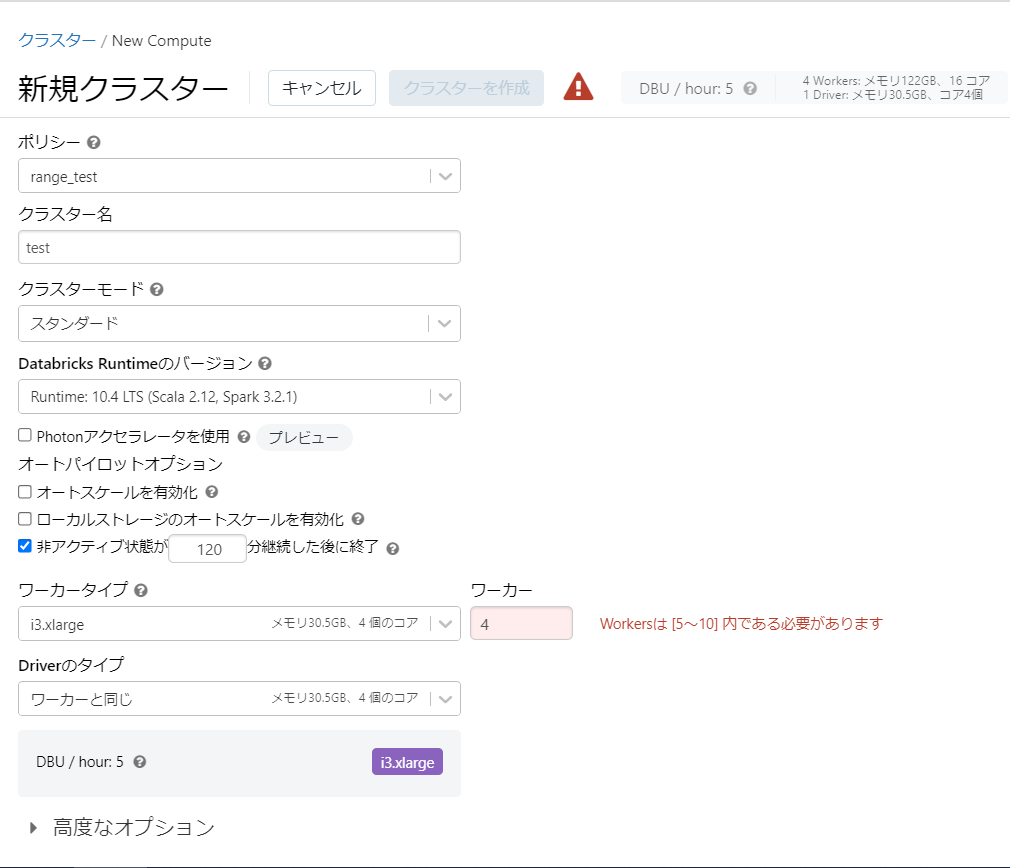
値を範囲外に設定しようとしたところエラーとなって「クラスターを作成」が非活性になっています。
- 無制限ポリシー
値を制限しません。
設定例では「値は制限しないが、何らかの値の設定が必要な項目の指定」という形で利用されています。
作成理由やコミットコメント等のような使い方に利用できそうです。
{
"custom_tags.COST_BUCKET": { "type": "unlimited" }
}
見え方
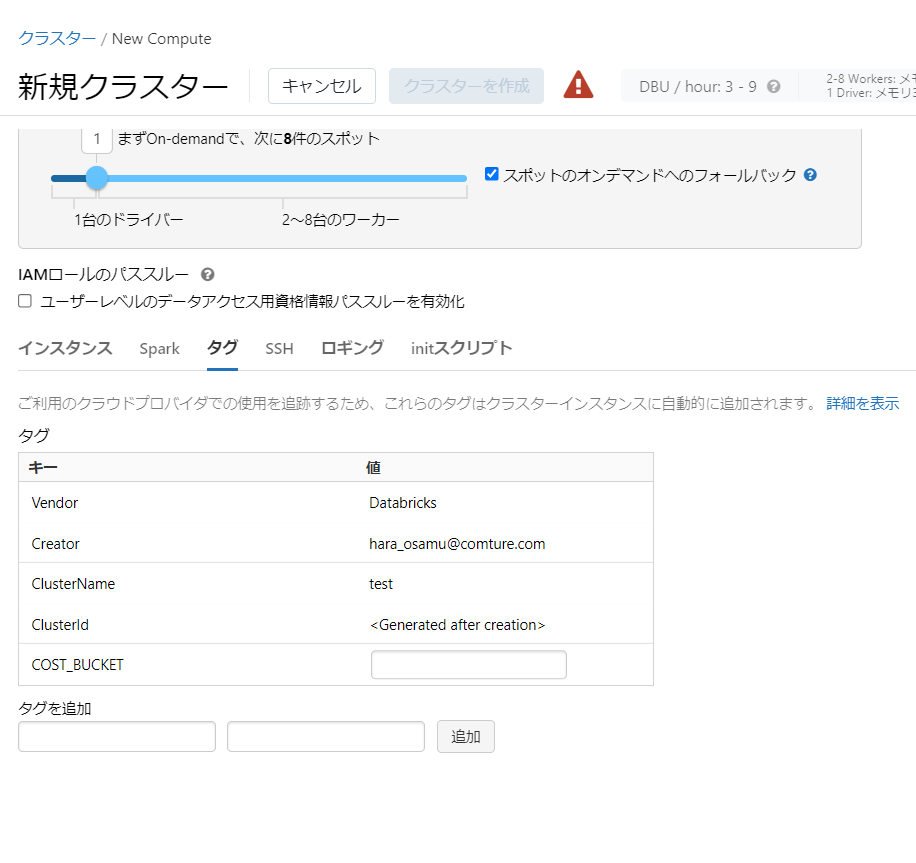
2.各設定項目とUIの対応・ポリシー例の設定値
各設定項目の説明については、設定方法と同様に上記参考サイトにてTakaaki Yayoi様がされているので、本記事では実際のUI上でどの設定項目に該当するか記載していこうと思います。
また、クラスターポリシー例の設定値も併せて記載します。
-
autoscale.min_workers,autoscale.max_workers
一般的なクラスターポリシー:min=1 max=5
シンプルな中サイズのポリシー:min=1 max=10
「ワーカーの最小数」「ワーカーの最大数」 -
autotermination_minutes
一般的なクラスターポリシー:30
シンプルな中サイズのポリシー:60
シングルノードのポリシー:120
「非アクティブ状態がxxx分継続した後に終了」のxxx -
aws_attributes.availability
高度なオプション内の「On-demand/Spotの構成」
利用可能な値はSPOT,ON_DEMAND,SPOT_WITH_FALLBACKの3つ。
参考:Clusters API 2.0#awsavailability
「On-demand/Spotの構成」が下記のようになります。
SPOT:first_on_demandの数分だけON_DEMANDインスタンスになります。
ON_DEMAND:全てON_DEMANDインスタンスになります。
SPOT_WITH_FALLBACK:first_on_demandの数分だけON_DEMANDインスタンスとし、「スポットのオンデマンドへのフォールバック」にチェックが入ります。 -
aws_attributes.ebs_volume_count
高度なオプション内「インスタンス」タブのEBSボリューム数 -
aws_attributes.ebs_volume_size
高度なオプション内「インスタンス」タブのEBSボリュームサイズ(GB) -
aws_attributes.ebs_volume_type
高度なオプション内「インスタンス」タブのEBSボリュームのタイプ
利用可能な値はGENERAL_PURPOSE_SSD,THROUGHPUT_OPTIMIZED_HDDの2つ。
参考:Clusters API 2.0#ebsvolumetype
詳細:「Amazon EBS の特徴」 -
aws_attributes.first_on_demand
高度なオプション内の「On-demand/Spotの構成」
「xxまずOn-demandで、次にyy件のスポット」のxx -
aws_attributes.instance_profile_arn
高度なオプション内「インスタンス」タブのインスタンスプロファイル -
aws_attributes.spot_bid_price_percent
高度なオプション内「インスタンス」タブの最大スポット価格 -
aws_attributes.zone_id
高度なオプション内「インスタンス」タブのアベイラビリティゾーン -
cluster_log_conf.path
高度なオプション内「ロギング」タブのクラスターログのパス -
cluster_log_conf.region
高度なオプション内「ロギング」タブのリージョン -
cluster_log_conf.type
高度なオプション内「ロギング」タブの配信先
利用可能な値はDBFS,S3,NONEの3つ。 -
cluster_name
クラスター名。fixedにしても変更可能。 -
custom_tags.*
一般的なクラスターポリシー:custom_tags.team="product"
シンプルな中サイズのポリシー:custom_tags.team="product"
ジョブオンリーのポリシー:custom_tags.team="product"
ハイコンカレンシーパススルーのポリシー:custom_tags.ResourceClass="Serverless"
高度なオプション内「タグ」タブに指定したタグと値のセットを追加する。 -
docker_image.basic_auth.password
「自分のDockerコンテナを使用する」内のパスワード
※利用するには管理コンソール内のワークスペース設定でContainer ServicesをEnabledにする必要あり。 -
docker_image.basic_auth.username
「自分のDockerコンテナを使用する」内のユーザー名 -
docker_image.url
シングルノードのポリシー:"forbidden"
シングルノードのジョブポリシー:"forbidden"
「自分のDockerコンテナを使用する」内のDockerイメージURL -
driver_node_type_id
一般的なクラスターポリシー:i3.2xlarge(AWS),Standard_L16s_v2(Azure)
シンプルな中サイズのポリシー:i3.xlarge(AWS),Standard_L8s_v2(Azure)
ジョブオンリーのポリシー:正規表現
[rmci][3-5][rnad]*.[0-8]{0,1}xlarge (AWS)
Standard_[DLS]*[1-6]{1,2}_v[2,3] (Azure)
「Driverのタイプ」のインスタンスタイプ設定 -
enable_elastic_disk
一般的なクラスターポリシー:true(AWSのみ)
シンプルな中サイズのポリシー:false(AWSのみ)
「ローカルストレージのオートスケールを有効化」のチェック -
enable_local_disk_encryption
クラスターローカルにアタッチされるディスクの暗号化設定
UI上には存在しないと思われる。 -
init_scripts.*.s3.destination
高度なオプション内「initスクリプト」のファイルパス(タイプがS3に設定される。) -
init_scripts.*.dbfs.destination
高度なオプション内「initスクリプト」のファイルパス(タイプがDBFSに設定される。) -
init_scripts.*.file.destination
高度なオプション内「initスクリプト」のファイルパス(タイプがFILEに設定される。UIからはFILEには設定不可。) -
init_scripts.*.s3.region
高度なオプション内「initスクリプト」のリージョン(タイプがS3に設定される) -
instance_pool_id
一般的なクラスターポリシー:"forbidden"
シンプルな中サイズのポリシー:"forbidden"
ジョブオンリーのポリシー:"forbidden"
シングルノードのポリシー:"singleNodePoolId1"
シングルノードのジョブポリシー:"singleNodePoolId1"
「ワーカータイプ」に紐づけるプールのID
driver_instance_pool_idが指定されていない場合は「Driverのタイプ」もこの値を引き継ぐ。 -
driver_instance_pool_id
「Driverのタイプ」に紐づけるプールのID -
node_type_id
一般的なクラスターポリシー:許可リスト
i3.xlarge,i3.2xlarge,i3.4xlarge (AWS)
Standard_L4s,Standard_L8s,Standard_L16s (Azure)
シンプルな中サイズのポリシー:i3.xlarge(AWS),Standard_L8s_v2(Azure)
ジョブオンリーのポリシー:正規表現
[rmci][3-5][rnad]*.[0-8]{0,1}xlarge (AWS)
Standard_[DLS]*[1-6]{1,2}_v[2,3] (Azure)
「ワーカータイプ」のインスタンスタイプ設定 -
num_workers
ジョブオンリーのポリシー:1~
シングルノードのポリシー:0
シングルノードのジョブポリシー:0
「ワーカータイプ」のワーカー数
オートスケールが有効でない場合の設定項目のため、これをfixedで定義するとオートスケール有効化のチェックが効かなくなる。 -
single_user_name
高度なオプション内の「ユーザーレベルのデータアクセス用資格情報パススルーを有効化」チェック時の「シングルユーザーアクセス」 -
spark_conf.*
一般的なクラスターポリシー:spark_conf.spark.databricks.cluster.profile="serverless"
シンプルな中サイズのポリシー:spark_conf.spark.databricks.cluster.profile="forbidden"
シングルノードのポリシー:spark_conf.spark.databricks.cluster.profile="singleNode"
シングルノードのジョブポリシー:spark_conf.spark.databricks.cluster.profile="singleNode"
ハイコンカレンシーパススルーのポリシー:
spark_conf.spark.databricks.passthrough.enabled="true"
spark_conf.spark.databricks.repl.allowedLanguages="python,sql"
spark_conf.spark.databricks.cluster.profile="serverless"
spark_conf.spark.databricks.pyspark.enableProcessIsolation="true"
外部メタストアのポリシー:
spark_conf.spark.hadoop.javax.jdo.option.ConnectionURL="jdbc:sqlserver://<jdbc-url>"
spark_conf.spark.hadoop.javax.jdo.option.ConnectionDriverName="com.microsoft.sqlserver.jdbc.SQLServerDriver"
spark_conf.spark.databricks.delta.preview.enabled="true"
spark_conf.spark.hadoop.javax.jdo.option.ConnectionUserName="<metastore-user>"
spark_conf.spark.hadoop.javax.jdo.option.ConnectionPassword="<metastore-password>"
高度なオプション内「Spark」タブの「Spark構成」
profileを指定すると上部のクラスターモードに影響する。 -
spark_env_vars.*
高度なオプション内「Spark」タブの「環境変数」 -
spark_version
一般的なクラスターポリシー:正規表現 "7\.[0-9]+\.x-scala.*"
シンプルな中サイズのポリシー:7.3.x-scala2.12
ジョブオンリーのポリシー:正規表現 "7\.[0-9]+\.x-scala.*"
シングルノードのポリシー:7.3.x-cpu-ml-scala2.12
シングルノードのジョブポリシー:7.3.x-cpu-ml-scala2.12
「Databricks Runtimeのバージョン」の設定値。 -
ssh_public_keys.*
高度なオプション内「SSH」タブの「SSH公開鍵」 -
dbus_per_hour
ジョブオンリーのポリシー:~100
type:rangeで利用。
「DBU/hour」の値に制約を加える。 -
cluster_type
ジョブオンリーのポリシー:job
シングルノードのジョブポリシー:job
作成できるクラスターのタイプ。
利用可能な値はall-purpose,job,dltの3つ。
ここにない場合にはその種類のクラスターにポリシーを適用不可。
3.Databricks公式ドキュメント内のポリシー例における設定値の一覧
各項目でも記載しましたが、ポリシー例に設定値があるものを一覧化しました。
| 項目名\設定例名 | 一般的なクラスターポリシー | シンプルな中サイズのポリシー | ジョブオンリーのポリシー | シングルノードのポリシー | シングルノードのジョブポリシー | ハイコンカレンシーパススルーのポリシー | 外部メタストアのポリシー |
|---|---|---|---|---|---|---|---|
| autoscale.max_workers | "type": "range", "maxValue": 25, "defaultValue": 5 |
"type": "fixed", "value": 10, "hidden": true |
|||||
| autoscale.min_workers | "type": "fixed", "value": 1, "hidden": true |
"type": "fixed", "value": 1, "hidden": true |
|||||
| autotermination_minutes | "type": "fixed", "value": 30, "hidden": true |
"type": "fixed", "value": 60, "hidden": true |
"type": "fixed", "value": 120, "hidden": true |
||||
| custom_tags.* | "custom_tags.team": { "type": "fixed", "value": "product" } |
"custom_tags.team": { "type": "fixed", "value": "product" } |
"custom_tags.team": { "type": "fixed", "value": "product" } |
"custom_tags.ResourceClass": { "type": "fixed", "value": "Serverless" } |
|||
| docker_image.url | "type": "forbidden", "hidden": true |
"type": "forbidden", "hidden": true |
|||||
| driver_node_type_id | "type": "fixed", (AWS)"value": "i3.2xlarge", (Azure)"value": "Standard_L16s_v2", "hidden": true |
"type": "fixed", (AWS)"value": "i3.xlarge", (Azure)"value": "Standard_L8s_v2", "hidden": true |
"type": "regex", (AWS)"pattern": "[rmci][3-5][rnad]*.[0-8]{0,1}xlarge" (Azure)"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]" |
||||
| enable_elastic_disk (AWSのみ) |
"type": "fixed", "value": "true", "hidden": true |
"type": "fixed", "value": false, "hidden": true |
|||||
| instance_pool_id | "type": "forbidden", "hidden": true |
"type": "forbidden", "hidden": true |
"type": "forbidden", "hidden": "true" |
"type": "fixed", "value": "singleNodePoolId1", "hidden": true |
"type": "fixed", "value": "singleNodePoolId1", "hidden": true |
||
| node_type_id | "type": "allowlist", (AWS) "values": [ "i3.xlarge", "i3.2xlarge", "i3.4xlarge" ], "defaultValue": "i3.2xlarge" (Azure) "values": [ "Standard_L4s", "Standard_L8s", "Standard_L16s" ], "defaultValue": "Standard_L16s_v2" |
"type": "fixed", (AWS)"value": "i3.xlarge", (Azure)"value": "Standard_L8s_v2", "hidden": true |
"type": "regex", (AWS)"pattern": "[rmci][3-5][rnad]*.[0-8]{0,1}xlarge" (Azure)"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]" |
||||
| num_workers | "type": "range", "minValue": 1 |
"type": "fixed", "value": 0, "hidden": true |
"type": "fixed", "value": 0, "hidden": true |
||||
| single_user_name | |||||||
| spark_conf.* | "spark_conf.spark.databricks.cluster.profile": { "type": "fixed", "value": "serverless", "hidden": true }, |
"spark_conf.spark.databricks.cluster.profile": { "type": "forbidden", "hidden": true }, |
"spark_conf.spark.databricks.cluster.profile": { "type": "fixed", "value": "singleNode", "hidden": true }, |
"spark_conf.spark.databricks.cluster.profile": { "type": "fixed", "value": "singleNode", "hidden": true }, |
"spark_conf.spark.databricks.passthrough.enabled": { "type": "fixed", "value": "true" }, "spark_conf.spark.databricks.repl.allowedLanguages": { "type": "fixed", "value": "python,sql" }, "spark_conf.spark.databricks.cluster.profile": { "type": "fixed", "value": "serverless" }, "spark_conf.spark.databricks.pyspark.enableProcessIsolation": { "type": "fixed", "value": "true" }, |
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionURL": { "type": "fixed", "value": "jdbc:sqlserver://" }, "spark_conf.spark.hadoop.javax.jdo.option.ConnectionDriverName": { "type": "fixed", "value": "com.microsoft.sqlserver.jdbc.SQLServerDriver" }, "spark_conf.spark.databricks.delta.preview.enabled": { "type": "fixed", "value": "true" }, "spark_conf.spark.hadoop.javax.jdo.option.ConnectionUserName": { "type": "fixed", "value": "" }, "spark_conf.spark.hadoop.javax.jdo.option.ConnectionPassword": { "type": "fixed", "value": "" } |
|
| spark_version | "type": "regex", "pattern": "7\.[0-9]+\.x-scala.*" |
"type": "fixed", "value": "7.3.x-scala2.12", "hidden": true |
"type": "regex", "pattern": "7\.[0-9]+\.x-scala.*" |
"type": "fixed", "value": "7.3.x-cpu-ml-scala2.12", "hidden": true |
"type": "fixed", "value": "7.3.x-cpu-ml-scala2.12", "hidden": true |
||
| dbus_per_hour | "type": "range", "maxValue": 100 |
||||||
| cluster_type | "type": "fixed", "value": "job" |
"type": "fixed", "value": "job" |
4.クラスターの権限設定
既存のクラスターについては、クラスター単位で権限設定が可能。
ユーザーに作成権限を与えずに、クラスターのノートブックへの接続や起動のみできるようにするといった管理ができます。
各権限の詳細については下記参考ページ参照。
参考:Cluster access control#cluster-level-permissions