
数年前からやっている Donkeycar を使った自律走行カーですが、もうすこし機能を拡張しようかなと、音声で相手の接近を検知できないかを試してみました。
音声を考えたのは現在使っている Donkeycar のカメラが前にしか向いていないので、後方からの追い抜きをブロックしたら ウケる おもしろいのではないか..というのが最初の動機です。
とりあえずはいきなりDonkeycarに実装しないで、単体のRaspberry Piにマイクをつけて試してみました(今回の記事はこの段階までの試行内容を書いています、Donkeycarパーツ化は要望があれば..)。

なお、今回紹介する内容の Python コードは以下のGitHubリポジトリにおいてあります。
環境構築
Raspberry Pi は4B/8GB を使用してます。
近年すっかり手に入りにくくなったRaspberry Pi、一瞬 スパコンもどき で使用していたRaspberry Piを使おいかと思ったのですが、たまたまスイッチサイエンスで1箱買うことができたので、壊さずにすみました..
Raspberry Pi OSは当時最新(今でもかな) Bullseye 64bitを使っています。
今回使用したのは Amazonでみつけてきたこの 安いUSBマイク 。選択の理由は、自分の車体はちょうど後方にRaspberry PiのUSBコネクタが向いているので、この小ささならアクセサリのじゃまにならず欲しい方向に設置できるからです。
必要なライブラリのインストール
DonkeycarはそもそもPythonベースで、Donkeycarのフレームワーク上に組み込むにはPythonでPartクラスを作成することになります。
sudo apt-get install -y build-essential python3 python3-dev python3-pip python3-virtualenv python3-numpy python3-pandas python3-pillow
Donkeycar アプリケーションはvirtualenv環境下で作成するので、実際には環境を作ってその中でライブラリをセットアップしました。
また音声異常検知にはRaspberry Pi用のTensorFlow 2.8.0を使っています。whlファイルは こちら からダウンロードしました。
:
sudo apt-get install -y libhdf5-dev libc-ares-dev libeigen3-dev gcc gfortran libgfortran5 libatlas3-base libatlas-base-dev libopenblas-dev libopenblas-base libblas-dev liblapack-dev git cython3 openmpi-bin libopenmpi-dev
:
pip install keras_applications==1.0.8 --no-deps
pip install keras_preprocessing==1.1.0 --no-deps
pip install numpy==1.22.1 -U
pip install h5py==3.6.0
pip install pybind11
pip install python_speech_features
pip install six wheel mock -U
pip install sklearn
:
wget "https://raw.githubusercontent.com/PINTO0309/Tensorflow-bin/main/previous_versions/download_tensorflow-2.8.0-cp39-none-linux_aarch64_numpy1221.sh"
chmod +x ./download_tensorflow-2.8.0-cp39-none-linux_aarch64_numpy1221.sh
./download_tensorflow-2.8.0-cp39-none-linux_aarch64_numpy1221.sh
pip install tensorflow-2.8.0-cp39-none-linux_aarch64.whl
:
Pythonからこのマイクを操作できないと意味がありません。マイクから音声データを取得するPythonライブラリは PyAudio を使いました。
PyAudioは内部でPortAudioを使用しているので、こちらもインストールします。
sudo apt-get install -y libportaudio2 libportaudiocpp0 portaudio19-dev
USBマイクの検出
PyAudioからUSBマイクを操作するには、まず搭載したUSBマウスのインデックス番号を知らないといけません。
USBマウスを挿した状態で、以下のプログラムを実行して表示内容からUSBマイクの番号をメモします。
import pyaudio
audio = pyaudio.PyAudio()
for i in range(audio.get_device_count()):
print(audio.get_device_info_by_index(i))
先のUSBマイクではありませんが、Sound Blasterを指した状態だと次のような表示がでてきます。
aultHighOutputLatency': 0.034829931972789115, 'defaultSampleRate': 44100.0}
{'index': 1, 'structVersion': 2, 'name': 'Sound Blaster Play! 3: USB Audio (hw:1,0)', 'hostApi': 0, 'maxInputChannels': 2, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.008684807256235827, 'defaultLowOutputLatency': 0.008684807256235827, 'defaultHighInputLatency': 0.034829931972789115, 'defaultHighOutputLatency': 0.034829931972789115, 'defaultSampleRate': 44100.0}
:
上記の表示ならインデックス番号は 1 であることがわかります。
録音
まず、対象音源を録音する必要がありますが、今回はwav形式で音声データを取得しました。
定期的にwavファイルを所定のディレクトリに保管するプログラムを別プロセスで実行しておき、音声異常検知は別のプロセスが保管先の最新音声ファイルを使って判断するしくみでつくりました。
import wave
import pyaudio
:
# 配列frames データをwavファイルにして保存
wavefile = wave.open('test_10.wav','wb')
wavefile.setnchannels(1) # チャネル:1
wavefile.setsampwidth(audio.get_sample_size(pyaudio.paInt16)) # ビットレート:int16ビット
wavefile.setframerate(44100) # サンプリングレート:44100kHz
チャネルの1はモノラルです。ステレオにするには2とします。
サンプリングレートはCDと同等の音質とものの本にはかかれている 44100 kHz にしています。
ビットレートは、wavファイルに格納される要素1つのサイズですが今回はint16ビットを使用しています(参考にしたコードもこの値だったので..)。
# PyAudio インスタンス化
audio = pyaudio.PyAudio()
# 引数情報に従って、PyAudio ストリーム生成
stream = audio.open(
format=pyaudio.paInt16, # ビットレート:int16ビット,
rate = 44100, # サンプリングレート:44100kHz
channels = 1, # チャネル:1
input_device_index = 1, # デバイスインデックス番号:1 ← 検出した数字
input = True,
frames_per_buffer=4096) # チャンク:4096
# 録音秒数
record_secs = 10
# 指定秒数の音声をchunkサイズごとに取得し、配列framesへ追加
max_count = int((44100 / 4096) * record_secs)
for i in range(0, max_count):
frames = []
# IOError対策 exception_on_overflow=False
frames.append(stream.read(chunk, exception_on_overflow=False))
wavefile.writeframes(b''.join(frames))
if i != 0 and i % 100 == 0 and debug:
print(f'wrote {i}/{max_count} frame(s).')
# ストリームの停止およびクロース
stream.stop_stream()
stream.close()
# PyAudioインスタンスの停止
audio.terminate()
上記コードでは10秒の音声を録音しています。
長時間録音するとIOErrorがたまに出てとまるので無視して続けるようにexception_on_overflow=Falseを指定しています。
音声異常検知
初めて車に乗ったのはたしか4歳、40ウン年前でした。親が運転する車が高速に入り、追い越し車線にのると、しばらくして「ビーッビーッ」というブザー音がでて驚いた記憶があります。100キロをコストブザーがなる機能を40年前の一般車でも搭載されていました。
きちんといつから..かは調べてはいませんが、人はシステムに音を発生させ異常があることを認識するシステムを昔からずっと開発・運用し続けています。
この場合は音声により人が異常発生を認識していますが、これを機械化できないかというアイディアはそれこそ昔からありました。
音声異常検知は、古くから研究されている領域です。なので方法もある程度先人の方が考えてくれています。
以下の表は日本音響学会の学会誌より一部引用したものです。
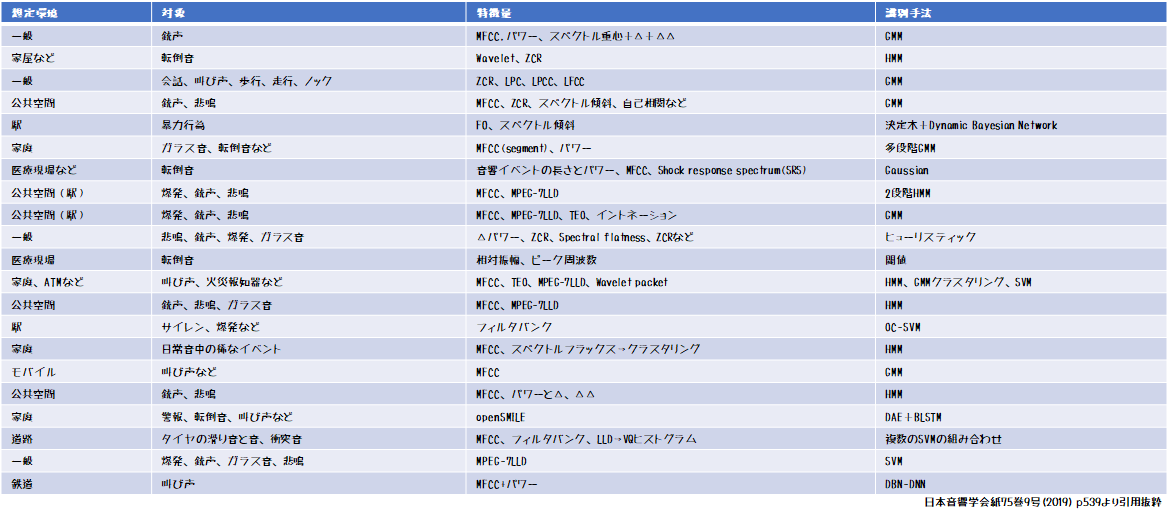
ここにある「特徴量」とは音響特徴量のことです。
音声データは時系列データであり時間がたつとどんどん際限なく増えていくので、コンピュータリソースがけずられてしまいます。
なのでどう間引いて特徴ある部分だけを切り出しておけないかという事前処理「特徴抽出」をおこなうわけです。
そしてその「特徴量」を入力として目的である結果を得るための「分類器」にかけますが、その実現手段が表左端の「識別手法」です。
表をうっすら長い目にして眺めると「特徴量」にはいろんなバリエーションがありますが、対して「識別手法」は選択肢はやや少なめにみえるとおもいます。
ざっくりまとめると、どこで(想定環境)どういう異常(対象)を検知するかというバリエーションを「特徴抽出」を変えることで補っていると言えると思います。
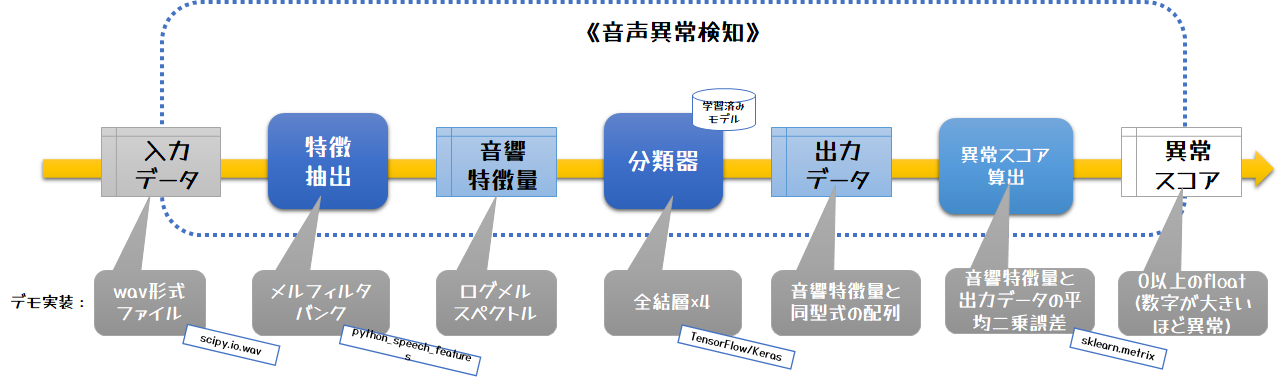
今回のデモプログラムは、以下の方法で実装しています。これを順番に解説します。
- 特徴抽出:ログフィルタバンク
- 分類器:全結合4層機械学習モデル
特徴抽出
まず、音声データを音響特徴量というデータに加工します。
これにより巨大な音声データを検出したい特徴をなるべくそこなわないようにかつある程度操作しやすいサイズにしています。
検知したい対象に合わせて音響特徴量のアルゴリズムを変えますが、今回はログフィルタバンクを使用しました。
フィルタバンクというのは音響学ではよく使われる用語で、元の音声にフィルタバンク行列のドット積をとり特徴を損なわないように次元を下げる方法です。
ログフィルタバンク処理は python_speech_features の logfbank を使用しました。
from python_speech_features import logfbank
:
(rate,sig) = wav.read(eval_path) # wavファイルを読み込む
input_data = logfbank(sig,44100,winlen=0.01,nfilt=20) # フィルタサイズ20
上記処理により20×N(音声データの長さにより変わる)の行列に変換されます。
これが分類器の入力データとなります。
分類器
分類器は、音響特徴量をもとに正常か異常かを判定する機能です。
むかしはOCSVNなどの数理最適化で使用されたアルゴリズムを使用していましたが、最近は深層学習モデルを使うようになってきました。
コンピュータリソース自体の自由度が増えたこともあり、昔は音響特徴量でがんばって削っていましたが、今はそれほど削らないでも処理できるようになりました。
ただ..今回はRaspberry Pi上であり、自律走行システムは基本スタンドアロンでの動作が望ましいこともあり、コンピュータリソースをできるだけ削らないモデルを選択しました。
今回は全結合4層で真ん中で半分の次元に落としている簡単なエンコーダデコーダ型のモデルを使いました。
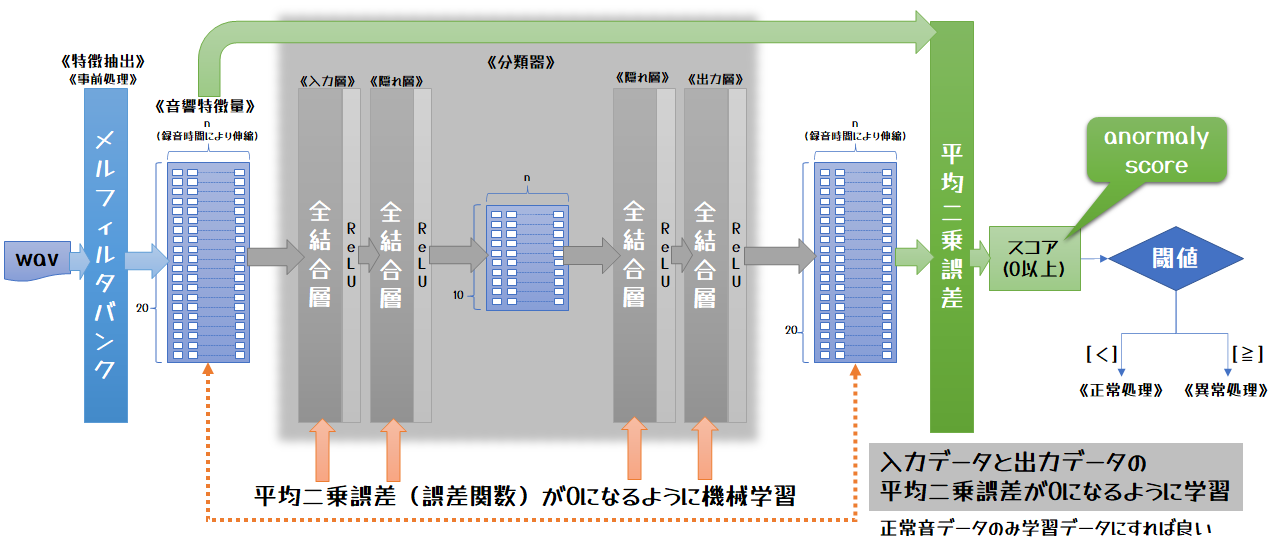
このモデルは入力データと出力データが同じ形式で、入力データをそのまま復元するように学習 させます。
なので真ん中で絞らないとすぐに収束してしまいます。
ですが個のモデルでは真ん中で半分のサイズになるので、情報損失が必ず発生して完全にもとには戻せません。
なので他のモデル同様トレーニング時間は長くはないですが短くないです(私のPCだと10秒データで5~10分くらい)。
このモデルのメリットは、トレーニング用の学習データとして異常音声データをわざわざ収集しなくても良い ところです。
工場とかの実際にシビアに使用される現場だと異常音を録音する機会はなかなかめぐってこないとおもいます。
先人の方々はよく考えておられます。
ちなみに テストのためには異常音声データは必要 です。正常データのみで学習している以上、テストで異常かどうかを評価してしきい値(後述)を決定する必要があり、すべての異常バリエーションの音声データが必要になります。
未知の異常検知もおそらく可能だとは思いますが、実際の異常が発生してきちんと判別するかは出たとこ勝負になります。企業内で使用する異常検知には怖くて使えません。
だから、IT企業のソリューションとして音声異常検知を掲げているところで、正常音声だけでできますとうたっている会社もありますが、テストデータとしての異常データも不要なのかどうかをベンダ側に問い合わせて確認したほうがよいと思います。
モデルの実装はTensorFlow.. というかほぼ keras ですね。
from keras.layers import Dense, BatchNormalization, Activation
from keras.models import Sequential, load_model
:
input_size = 20
:
model = Sequential()
model.add(Dense(input_size,input_shape=(input_size,)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(int(input_size/2)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(input_size))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(input_size))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
損失関数
機械学習におけるトレーニングの目的は損失関数の答えが0に近づけることです。
今回使用しているモデルは、出力データが入力データにいかに近い値なのかを示す損失関数を指定する必要があります。
損失関数はどうするかというと、入力データとモデル出力データの距離(平均二乗誤差)をとります。
距離が0に近い、つまり入力データとほぼ同じ音響特徴量である、ということです。
算出された距離にしきい値を設けて、その値より小さい場合は「正常」、そうでない場合は「異常」と判断させます。
今回はsklearn.metricsのmean_squared_errorを使用しています(トレーニング処理は、上記コード下から2行目に記載)。
from sklearn.metrics import mean_squared_error
:
# 異常判定スコア計算
score = mean_squared_error(input_data, output_data)
学習データ
今回学習データとして10秒間の音声データ(wav形式)を使用しています。
10秒としたのは、私の都合です。
厳密に所有しているPCでトレーニング処理を動かし続けて私の忍耐の上限時間にマッチしたのが10秒だったのです。
トレーニング用学習データの録音プログラムは既述のコードを確認してください。
これはあえて書かなくてもわかると思いますが..wavファイルならどこで取ったものでもトレーニング用のデータとして使えますが、本番と同じ環境で収集したものが望ましいのはいうまでもありません。
評価データ
学習データは10秒だったのですが、評価は2秒データにしています。
Donkeycarはデフォルトで1秒間に20回ループが回るようになっています。なので音声データを2秒間取り続けるわけには行きません。なので別プロセスで音声を収集していて、Donkeycarアプリ側は最新の2秒データを評価しています。
なのでループの40回くらいは同じ音声データの結果で判断してしまいます。このあたりはしきい値を緩めて早めに検知するようにして対応することになりますね。
テスト
Donkeycarに実装せずにテストしたかったので、タミヤの高速・低速ギア変更可能な2輪駆動バギーをつかってテストしました。
今回はデモ目的なので、テストには確実に異常データを発生させることができるケースでなくてはなりません。なので、簡単に正常・異常が目の前で実現できる以下のケースでためしてみました。
- 単独バギーの接近検知
- バギーのギア変速検知(高速→低速)
- チューニングの違うバギーを聞き分け
定期的に録音した音声の異常検知スコアをFlaskでグラフ化するWebアプリを別途動かしておき、音源を近づけたり遠ざけたりしてテストとしました。これでしきい値の設定も目視で決めることができます。
単独バギーの接近検知
タミヤの2輪駆動バギーをマイクに近づけたり遠ざけたりして異常スコアの動向を確認しました。
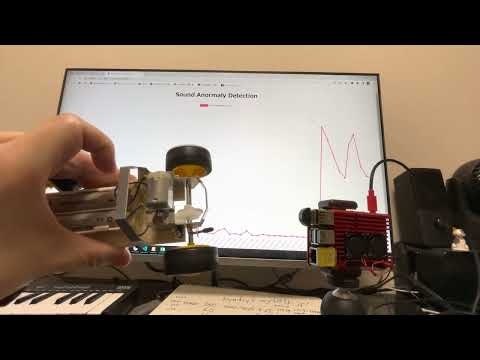
動画でも分かる通り、明確に判別できることが確認できると思います。
バギーのギア変速検知(高速→低速)
タミヤの2輪駆動バギーには変速器がついていて、動作中も高速・低速を選択できるようになっています。
このギア比の変化を聞き分けられるかをためしました。
こちらも動画からしきい値設定は可能そうだということがわかるとおもいます。
チューニングの違うバギーを聞き分け
2輪駆動バギーの設定を細かく変えたものを3台用意して、違いを判別できないかというものです。

しきい値設定はシビアで精度は上述2件より落ちますが、なんとかできそうです。
二輪駆動四輪駆動の聞き分け
タミヤの四輪駆動車という別の種類の音源を持ってきて、違いを判別できるかというものです。

こちらは、音の違いが比較的わかりやすく高速・低速判定よりわかりやすかったです。
まとめ
まとめると、上記の動画では、どれも判別できている様子がわかるとおもいます。
..が、実は上記のモデルのうち「二輪駆動四輪駆動の聞き分け」で使用した分類器以外の3つのユースケースの学習データは、何も動いていない無音声データを使っています。
わざわざ機械学習モデルなんぞつかわなくてもwavファイルをそのまま評価するだけで、無音→音ありはすぐに判別できるのです。
音声異常検知モデルは、デモ検証ではいい成績を残すことが多いですが、実際の現場のデータの場合はそうはいきません。
Donkeycarレースであっても、参加者が徐々に増えるなど現場の環境音が常時変化する場合はそのたび学習し直すことになります。
現場に合わせて音響特徴量を磨く作業が必要になります。
結論を言うと、音声異常検知はDonkeycarレースのような常に環境音に変化のある場合は難しいのです。

超音波の送受信で距離をはかるセンサなども安く手に入るので、後方に向けて設置して於けばいいだけの話なのです。
(きちんと計測してませんが)そのほうがRaspberry Piのコンピュータリソースを食わないとおもいます。
Adbent Calendar 2022 初日の記事が、こんなしょぼい結論に終わってしまい、スミマセン..
次の担当の方は、きっと素晴らしい記事を投稿されると思いますので、震えて期待しましょう(丸投げ御免)。