2024年12月4日、Amazon Bedrock Knowledge basesがGraphRAGをサポートするようになったというアップデートがありました!
ただ私はGraphRAGと言われてもあまりピンとこなかったので、この期にキャッチアップしてみました!
当ブログでは、
- 「ベクトル」を用いたRAG → Baseline RAG
- 「グラフ」を用いたRAG → GraphRAG
と記載します。
そもそもRAGとは?
GraphRAGについて学ぶ前に、まずはRAGについておさらいしておきます。
RAGとは、Retrieval-Augmented Generationの略語です。
1語ずつ翻訳すると、
- Retrieval:検索
- Augmented:増加した、増強した
- Generation:生成
となり、日本語でいうと検索拡張生成となります。
検索拡張とはどういうことかというと、生成AI(以降、ここではLLMと記述)が事前学習していない外部情報を検索して取得することを指します。
したがって検索拡張生成とは、LLMが事前学習していない外部情報を検索して情報を取得し、その情報も用いて回答を生成する機能、ということになります。
すなわち、開発者はLLMに再度学習トレーニングを実施することなく、LLMの知識や機能を拡張できる、ということです。
では、この検索拡張生成がなぜ必要なのでしょうか。
通常のLLMを活用する場合と、RAGを用いたLLMを活用する場合で比較してみましょう。
通常のLLMは、自身がすでに学習したデータに基づいて回答を生成します。
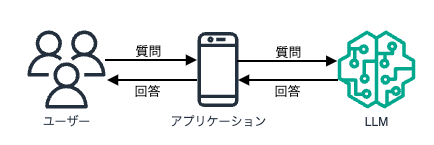
しかし、LLMには最新のデータが学習されていない場合もあります。
例えば、LLMに「現在の日本の首相は?」と聞くと、以下のような答えが返ってきました。

ここから、最新のデータが学習されているわけではないということがわかります。
しかし、上記の回答が間違っていることは事実です。
LLMに事前学習範囲外の質問をすると、ハルシネーション(もっともらしい嘘)を起こしてしまうことがあります。
その一方で、RAGを用いたLLMの場合、質問が来た際に外部情報を検索したうえで回答を生成します。
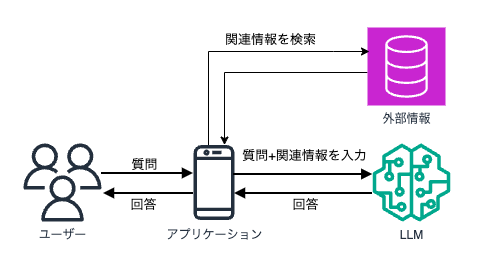
仮にこの外部情報に、日本の歴代の首相名と任期が記載されていれば、先程のようなハルシネーションは起こらなくなるでしょう。
また、LLMは基本的にインターネットなどで公開されている情報しか学習していません。
すなわち、会社の内部だけで共有されているドキュメントの情報などは持ち合わせていません。
そのような時にも、外部情報として社内のドキュメントを入れておけば、それを元にLLMが適切な回答を出力してくれるようになります。
このようにして、検索によってLLMの能力を拡張した上で回答を生成してもらう機能。それがRAGです。
そしてこの機能をAWS上で簡単に実装できるのが、Amazon Bedrock Knowledge basesです。
※Amazon Kendraも同様に検索機能を提供しますが、当記事ではAmazon Bedrock Knowledge bases(以下、ナレッジベースと記載)を中心に話を進めます。
検索を可能にする仕組み
先ほど、外部情報を取得したうえで回答を生成するのがRAGだとご説明しました。
ただ、その外部情報がたくさんある場合を想像してみてください。
アプリケーションからすると、どの情報を取得すればいいのかがわからなくなりそうですよね。
ここで、どのように検索をして、質問と関連する情報をどのように見つけるのかについて見ていきます。
埋め込み(Embedding)
Baseline RAGでは、埋め込み(Embedding)という手法を用いて、情報を見つけやすくしています。
埋め込みとは、テキスト(や画像)のデータを「ベクトル」に変換する手法です。
ドキュメントに掲載されているテキストや画像のデータは、人間が読みやすい形のものであって、コンピュータが読みやすいものにはなっていません。
それらのデータを、コンピュータやLLMが理解・処理しやすい数値ベクトルという表現に変換します。
その際、意味的に似た単語や文章同士を空間的に近い数値ベクトルへと変換します。
ベクトル化によって、似たような言葉は近くに、そうでない言葉は遠くに位置するようになります。
その結果、意味的に似た言葉や文章を「近いベクトル」として比較できるようになり、結果として意味に基づいた検索を行えるようになります。
言葉で説明されてもよくわからないですよね。
ということで以下の図をご覧ください。

引用:https://atmarkit.itmedia.co.jp/ait/articles/2401/18/news023.html
まずはそれぞれの単語や文章を数値ベクトルへと変換します。
自然言語をベクトル化すると、実数値が並べられた配列となり、その配列の要素数が「次元」と表現されます。
例えば、ベクトル化した際に100個の数値が並んでいれば、「100次元」と表現されます。
この数値が多ければ多いほど、言葉の細かいニュアンスまで表現できるので、より正確になりやすい、と理解してもらえば良さそうです。
上記は単語の例でしたが、文章ももちろん埋め込みを行うことが出来ます。
この時、ドキュメント全体を1つのベクトル化するのは非常に難しいです。
会社のドキュメントを思い浮かべてほしいのですが、そのドキュメントに書かれている情報って限りなく膨大ですよね。それを1つのベクトルで表現するのは無理があります。また、LLMの回答精度が下がる原因にも繋がりそうです。
そこで、文章の埋め込みを行う際は、意味ごとの塊に分けてベクトル化します。
この塊のことをチャンクといいます。
したがって文章においては、このチャンクごとに配列化され、空間の中に配置されるということになります。
ただし、このチャンクがあまりにも大きい塊でできていると、これもまたベクトル化出来ないということに繋がりかねないので、注意が必要です。
ベクトルデータベースに保存する
生成されたベクトル情報は、ベクトルデータベース(以降、ベクトルDB)に格納されます。
このベクトルDBはベクトルの保存に対応したDBです。
先程の図でいうと、「外部情報」と表現していたものがベクトルDBにあたります。
アプリケーションはここに情報を取得しに行くわけですね。
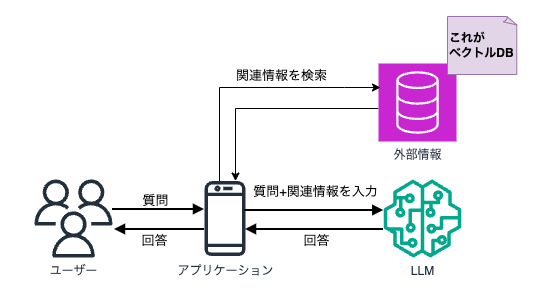
AWS上で利用可能なベクトルDBは以下の通りです(2024年12月8日現在)。
- Amazon OpenSearch Serverless
- Amazon Aurora PostgreSQL Serverless
- Pinecone
- Redis Enterprise Cloud
- Amazon Neptune Analytics (GraphRAG) ※後述します
ここまでで埋め込みとベクトルDBについて少しご理解いただけたと思います。
では、実際にベクトルをベクトルDBに格納するためには何が必要なのか、どうすればよいのか。
それは、埋め込み用のLLM(以下、埋め込みモデル)を用いる必要があります。
埋め込みモデルによって、単語や文章をベクトル化することができます。
ドキュメントを例にすると、以下のような形で埋め込みが行われます。
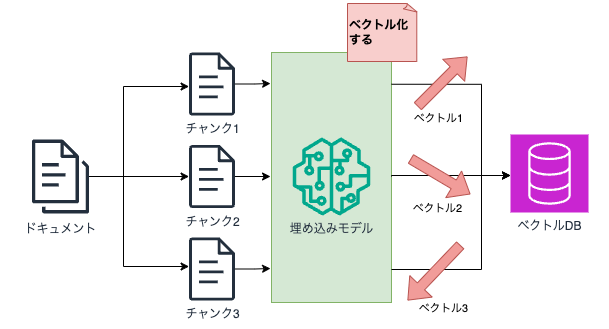
AWS上で使用できるのは以下の埋め込みモデルです(2024年12月8日現在)。
- Titan Text Enbeddings v2
- Titan Enbeddings G1 - Text v1.2
- Embed English v3
- Embed Multilingual v3
上記のモデルを用いて、埋込みとデータ格納を行うことができます。
ベクトル検索
埋め込みという作業によって、人間の言葉がベクトル化され、コンピュータやLLMが理解しやすい形に変換されました。
そしてそれらのベクトルは、埋め込みモデルを用いることでベクトルDBへ格納されました。
では続いて、それらのベクトルをどのようにして検索するのか。
その方法は、コサインという三角関数を用いて計算します。
簡単に言うと、言葉と言葉の角度を調べることで、両者がどれだけ似ているかがわかります。

引用:https://atmarkit.itmedia.co.jp/ait/articles/2401/18/news023.html
この2つのベクトルがどのくらい似ているか、というのを参考にして、関連する情報を見つけ出すことができるようになります。
これがベクトル検索です。
細かい解説は、以下のブログが非常に参考になりました。
これをアプリケーション上に当てはめるとどうなるかというと、ユーザーからの質問とベクトルDB内のベクトルを比較するという作業が行われることになります。

まず、手順①でユーザーの質問をベクトルに変換します。
そして、手順②で質問のベクトルとベクトルDB内のベクトルを比較し、ベクトル検索を行います。
これによって類似情報を取得したうえで、手順③でLLMが回答を生成できます。
このような流れで、外部情報を取得したうえでLLMが回答を生成することができます。
Baseline RAGの強み
非構造化データを処理することに強みがあります。
例えば、MarkdownやWord、PDFで書かれた社内ドキュメントを用いて、Baseline RAGを構築することができます。
構造化されていないドキュメントに対しても、高次元のベクトル化を用いることでベクトルDBに保存することができるため、ユーザー側が必要以上に情報を整形する必要がない、という大きな強みがあります。
ここまでが、Baseline RAGのお話でした。
(参考:『Amazon Bedrock 生成AIアプリ開発入門 [AWS深掘りガイド])
GraphRAGとは?
ここから、ナレッジベースに追加された機能である、GraphRAGについて見ていきましょう。
GraphRAGでは、読んで字の如く、単語や文章をグラフ化して保存します。
ベクトルではなく、グラフにするというところがBaseline RAGと大きく違うところです。
「グラフ」とは?
GraphRAGで扱う「グラフ」とは、データを node と edge として整理し、それぞれに property を付与したものを指します。
- node(頂点):データそのものの置き場を定義する
→具体的なモノから、抽象的な概念まで定義可能 - edge(辺):データ同士の関係性を定義する
- property(属性):各nodeやedgeが持つ値を定義する
イメージとしてはこんな感じです。
丸がnode、矢印がedge、文字列がpropertyを指します。

引用:https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
このようなグラフを「ナレッジグラフ(Knowledge Graph)」と言います。
それぞれのデータがどのような関係性を持っているかに着目することで、データを構造化して表現・保存できるようになっています。
※数学の世界における「グラフ理論」のグラフと近いようです。
ここでいうグラフは、ノード(節点)とエッジ(辺)の集合として構成されるものを指しています。
構図としてはGraphRAGのグラフと同じです。
https://ja.wikipedia.org/wiki/%E3%82%B0%E3%83%A9%E3%83%95%E7%90%86%E8%AB%96
GraphRAGのプロセス
Microsoftが公開している以下のGitHubのドキュメントを参考に、どのような流れでGraphRAGが実装されているのかを読み解いていきましょう。
インデックス作成
インデックスとは、索引のこと。すなわち、情報を効率的に検索・アクセスするために作成される構造化されたデータのことです。
もっと言うと、ナレッジグラフのことです。
ナレッジグラフを作成するための手順としては大きく4つです。
- テキストの分割
→与えられたドキュメントなどを、TextUnitsとして小さく分割します。
→このTextUnitsは、後から分析可能なものとして使用します。 - 情報の抽出
→LLMを使用して、node・edge・propertyなどに用いるための情報(エンティティ)を抽出します。 - 階層的クラスタリング
→Leidenアルゴリズムを用いて情報をグループ化します。
→そして関連する情報同士を纏めたコミュニティを形成します。 - サマリー生成
→各コミュニティの要約を作成し、下位層から上位層へと階層的に情報を集約します。


引用:https://internet.watch.impress.co.jp/docs/column/shimizu/1608736.html
まとめると、ナレッジグラフとはこのような形になります。
クエリ時の検索方法
作成したインデックス(ナレッジグラフ)に対して、情報の検索を行う方法は大きく3通りあります。
- グローバル検索
→コミュニティの要約を活用して、ドキュメント全体に対する包括的な質問に対応します。 - ローカル検索
→特定のエンティティに対し、近い位置にあるエンティティと関連概念に展開して推論を行います。 - ドリフト検索
→ローカル検索にコミュニティ情報の文脈を追加します。
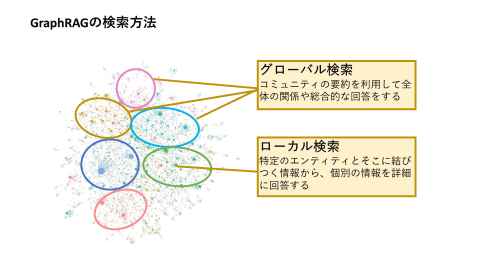
引用:https://internet.watch.impress.co.jp/docs/column/shimizu/1608736.html
具体的に検索手法について比較するとこのようになります。
グラフデータベース
ここではデータを格納するためにベクトルDBではなく、グラフデータベース(以下、グラフDB)を用います。
AWS上で利用可能なグラフDBは以下の通りです(2024年12月8日現在)。
- Amazon Neptune Database
- Amazon Neptune Analytics (GraphRAG)
NeptuneシリーズのBlackBeltは以下です。
https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon%20Neptune_0730_v1.pdf
ただし、Amazon Bedrock Knowledge bases上で使用する際は、後者のNeptune Analyticsを使用します。
GraphRAGの強み
データをナレッジグラフ化することで、色々なデータタイプにわたる複雑な関係や属性を簡単に取得することができるようになります。
特に、ドキュメントなどの複雑になりがちなデータにおいても、その中で記載されているモノや事象同士の様々な関係性を表現できるということが大きな強みです。
また、Baseline RAGと異なる点は、文脈の理解度でしょう。
Baseline RAGでは、チャンクごとに区切ってベクトル化するため、その前後の文脈を理解することなく答えが出力されます。
したがって、チャンクの区切り方が悪いと、ハルシネーションが起こってしまう可能性があります。
例えば、「労働時間規則:当社のコアタイムは9:00~18:00です。ただし、フレックス勤務が認められている者はこの限りではありません。」という文章があります。
これを、
「労働時間規則:当社のコアタイムは9:00~18:00です。」と
「ただし、フレックス勤務が認められている者はこの限りではありません。」
でチャンクを区切ってしまったとしましょう。
この時、ユーザーが「時短勤務者の労働時間規則を教えて」と質問した際に、LLMはBaseline RAGからの出力を踏まえ、「9:00~18:00です」と回答してしまう可能性があります。
このように、前後の文脈を一切考慮せずに出力されてしまうケースがあります。
上記は極端な例でしたが、このようなことが起こる可能性があります。
その一方で、GraphRAGでは、関係性がそれぞれつながっているということで、文脈などを考慮したうえでLLMが回答を出力することができます。

作られるナレッジグラフのイメージとしてはこのような形でしょうか。
これだと、下がきちんと出力されそうですね。
ここはBaseline RAGとは異なる点であり、優位な箇所となっています。
ただし、Baseline RAGとGraphRAGは対立関係にあるわけではなく、むしろ互いに回答精度を向上させ合うためのものであることに注意が必要です。
LangChainのブログ内に、
「グラフ検索拡張生成 ( Graph RAG ) は勢いを増しており、従来のベクトル検索方法に強力な追加機能として登場しています。」
と記載されています。
https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
以上がGraphRAGの詳細説明でした。
ここからは、実際にAWS上でGraphRAGを作成してみます。
やってみた
※GraphRAGは2024年12月8日現在、プレビューでの提供です。今後変更されるおそれがあるので、最新情報をキャッチアップすることをおすすめします。
GraphRAGは、ナレッジベースとAmazon Neptune Analyticsの両方が利用可能なリージョンのみの対応です。
迷ったら東京リージョンでやりましょう。
事前準備として、以下のBedrockモデルアクセスを有効化しておきましょう。
前者は埋め込み用、後者は回答生成用として設定します。
- Amazon: Titan Embedding G1 - Text
- Anthropic: Claude 3 Haiku


S3を作成する
ナレッジベースでデータソースとして利用するS3バケットを作成します。
リージョンは任意ですが、この後ナレッジベースを作成するのと同じリージョンで作成しましょう。
バケットが作成できたら、好きなドキュメントをPDF化して格納します。
ここでは、私の愛馬であるドウデュースのWikipediaページをPDF化して格納します。
※Wikipediaは、画面上部の「ツール」ボタンからPDFをダウンロードできます。
※S3に格納するデータは、以下のフォーマットである必要があります。
また、1オブジェクトあたり50MBまでです。
ファイルの中に図や写真などが入っていても問題ありません。
| フォーマット | 拡張子 |
|---|---|
| プレーンテキスト(ASCIIのみ) | .txt |
| マークダウン | .md |
| HyperText Markup Lamnguage | .html |
| Wordドキュメント | .doc/.docs |
| Comma-separated values | .csv |
| Excelスプレッドシート | .xls/.xlsx |
| Portable Document Format |
ナレッジべースを作成する
ナレッジベースを作成する中で、グラフDBなども作成できるので、簡単に試すことができます。
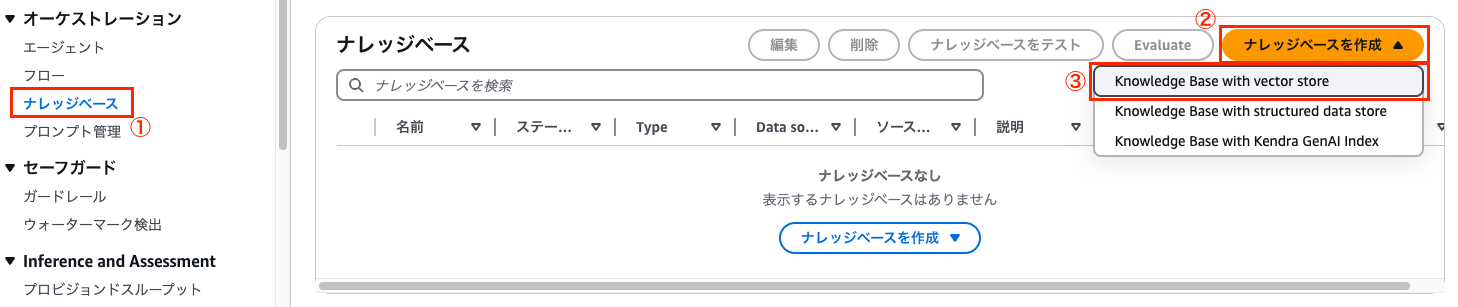
まずはBedrockコンソールから、
①「ナレッジベース」を選択します
②「ナレッジベースを作成」を選択します
③「Knowledge Base with vector store」を選択します
実際にこれから作成したいのはグラフDBなのですが、ここではベクトルストアと書かれているものを選択します。
続いて名前やIAMロールを設定します。
データリソースはS3を選択。GraphRAGはプレビュー期間なので、S3のみの対応です。
(そういえばre:InventでここのプレビューくんたちはGAされなかったですね…)

お好みでログの配信先を設定し、「次へ」をクリック。
続いて、データソースの設定を行います。
S3のURIには、先ほど作成したバケットを指定します。
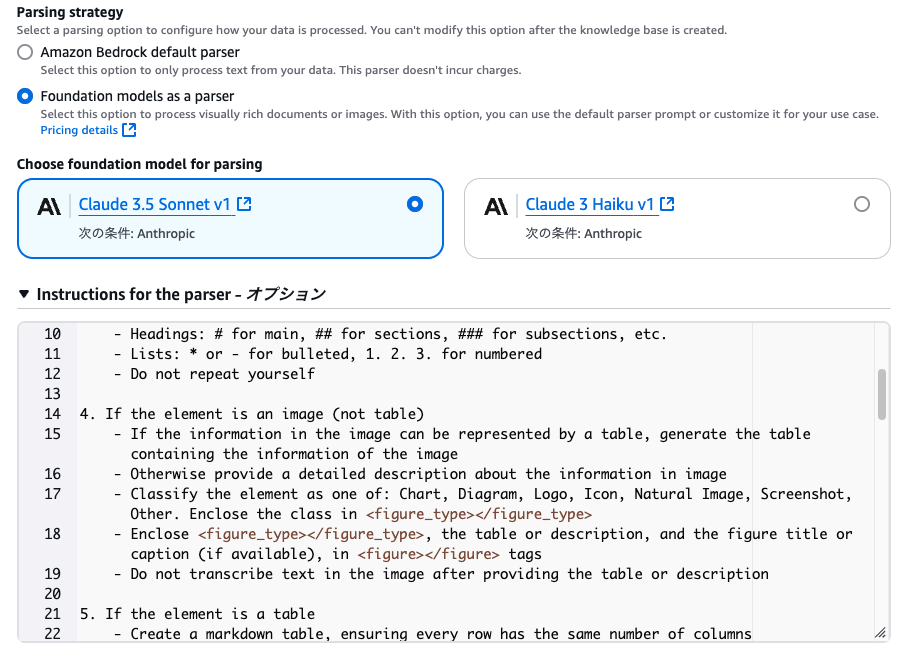
続いてParsing Strategy、すなわち解析手法について決定します。
デフォルトパーサー(上の方)だと、データからテキストのみを処理します。また、料金もかかりません。今回はこちらを使います。

※基盤モデルを用いたパーサー(下の方)だと、テキストに加え、画像も処理できます。
こちらは基盤モデルすなわちLLMを用いて、ドキュメントを解析してくれる手法です。
チャンキング戦略で、チャンクをどういう風に区切るかが設定できます。
ここではデフォルト設定にして、「次へ」を選択。

細かいチャンキングの手法については、以下のブログがわかりやすく纏まっていました。
そして、埋め込みモデルを選択します。
あらかじめ有効化しておいたTitan Embedding G1 - Text1.2を選択します。
ベクトルDBの設定では、「新しいベクトルストアをクイック作成」から、
「Amazon Neptune Analytics (GraphRAG) - Preview」を選択します。
これで、ナレッジベースの作成と同時にNeptune Analyticsも作成されます。
※現状、利用できる基盤モデルはClaude 3 Haikuのみのようです。最初にHaikuを有効化しておいたのはこのためでした。

そしてこの設定で良ければ、「ナレッジベースを作成」します。
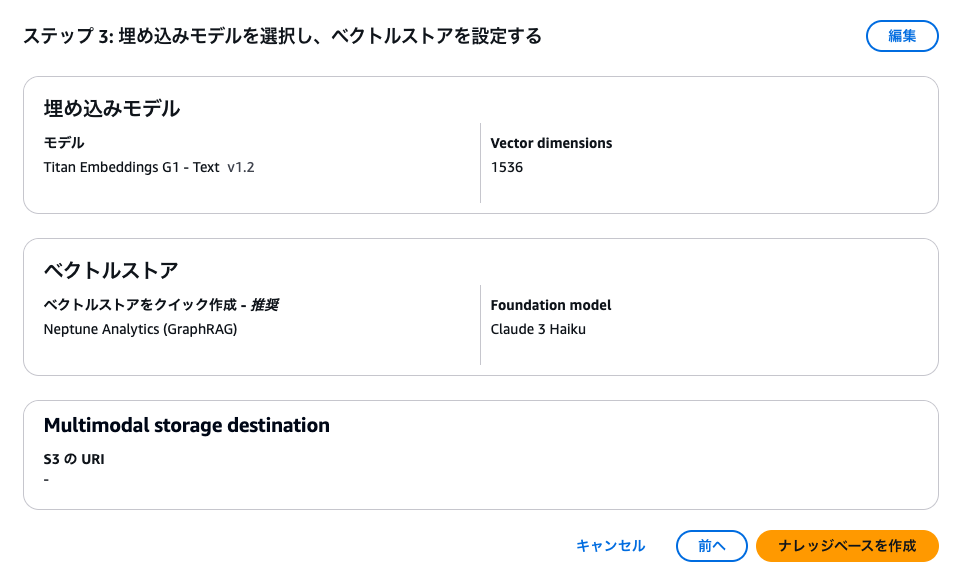
すると、こんな感じで進捗が表示されます。しばらく待ちます。

Neptune Analyticsのコンソールを開くと、作成されているのが見えます。
(データベースの方ではなく、Analyticsの方です)

10分〜15分程度待つと、ナレッジベースが完成しました!
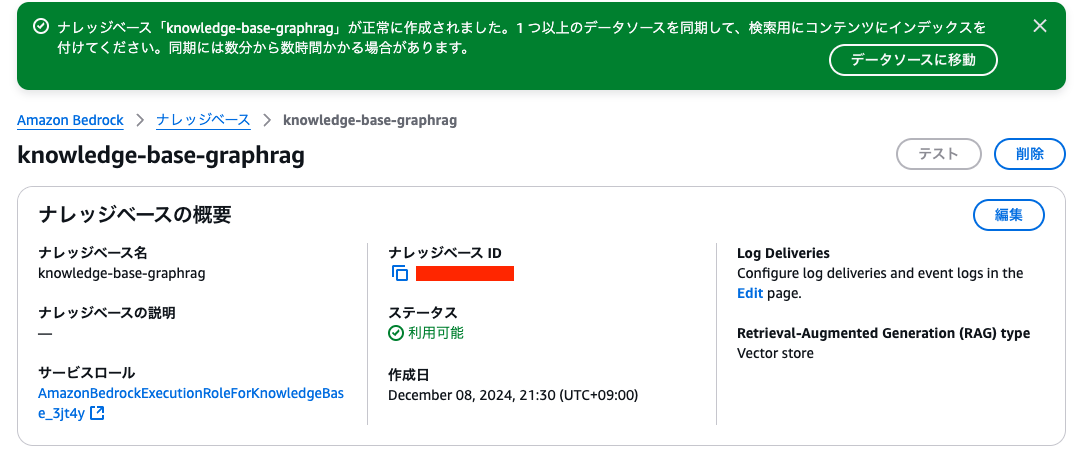
Neptune Analyticsも利用可能に。
ただ、まだデータの同期ができていないので、データソースから「同期」をクリックします。
これで準備完了です。

試してみる
同期が完了したら、テストしてみます。

えー、両方バツです。
チャンキング設定サボったからか、それともHaikuだからきちんと理解してくれていないのか、わかりませんが、今のところあまり精度は高くありませんでした。
(多分チャンキング設定ちゃんとしてないから、というのはある気がします。
ソースチャンクを確認するとなかなか酷い区切り方になっていたので…)

あとこのNeptune Analyticsの欠点として、ナレッジグラフが視覚化されないというのがあります。
コンソール上のどこを見てもその設定が見当たらないので、内部でどんな感じになっているのかが全くわかりません。

というのも、普通のNeptune Databaseを用いてGraphRAGを作成した場合は、これが見られるみたいなんですよね…(以下のブログ参照)
実際のユースケースで使うかはさておき、これ見られる方が楽しそうなので実装してほしかったです。
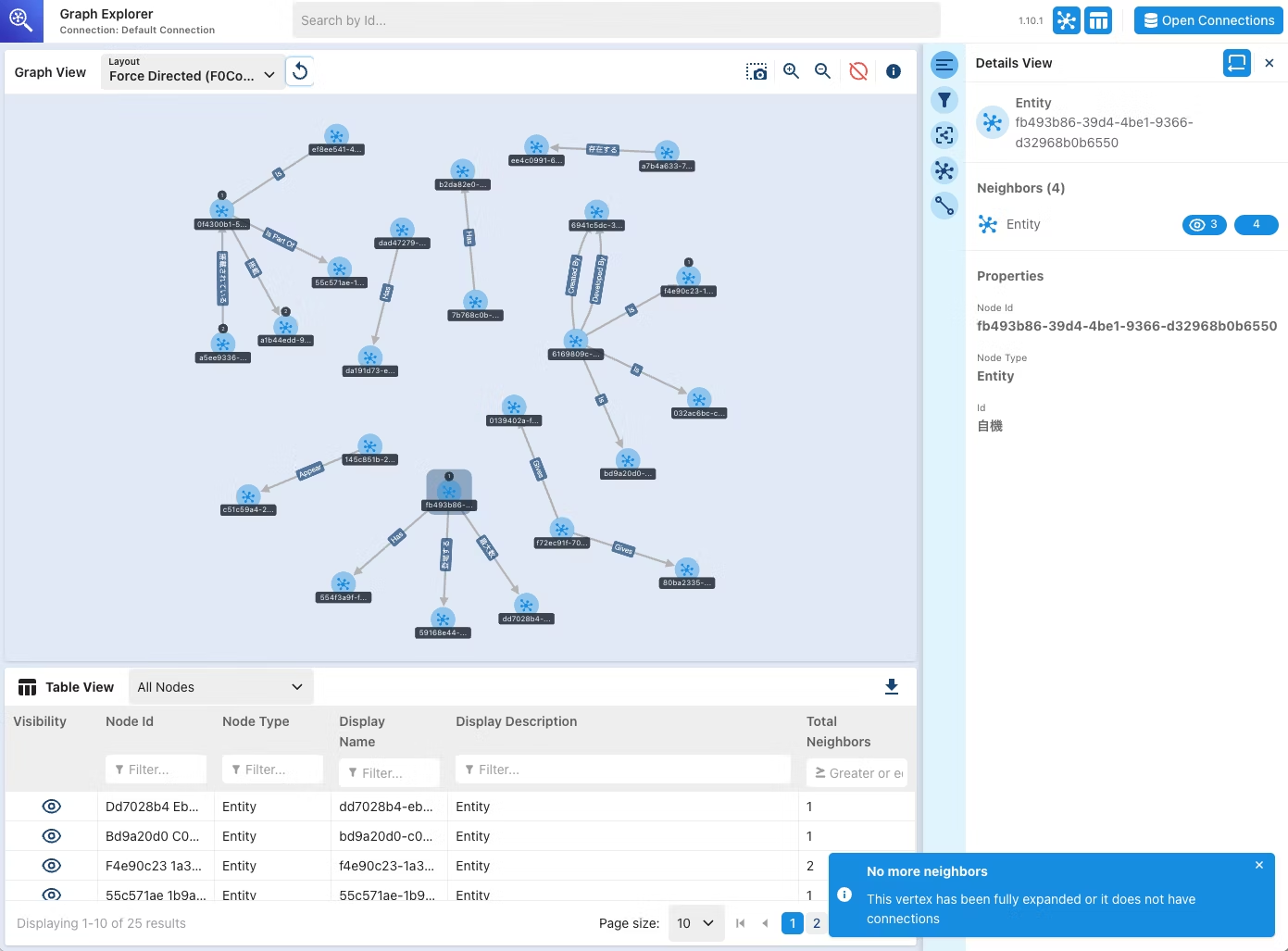
私の作り方の問題もあるかも知れませんが、GAされる頃にはアップデートされていると嬉しいな…と思いました(ナレッジベースに責任丸投げ…笑)。
ナレッジベースの精度を向上させる方法、ありました!(2025/1/18追記)
私の不勉強で申し訳ありません…
追加で遊んで調査していたところ、精度を向上させる方法がありました!
大きく2つの手法があります。
1. 解析戦略(Parsing Strategy)を変更する
解析(Parsing)とは、「ドキュメントとその意味のあるコンポーネントを解釈すること」です。
文章に加えて、画像などのコンポーネントも噛み砕いた上でベクトル化・グラフ化してくれるようです。
解析の手法としては3通りあります。
- デフォルトパーサー:
ドキュメント内のテキストのみを解析します(無料) - Amazon Bedrock Data Automation (プレビュー):
追加のプロンプトを提供する必要なく、テキストと画像の両方を含むマルチモーダルデータを効果的に処理するフルマネージドサービス
(2025/01/18時点ではオレゴンリージョンのみ対応) - Foundation models:
基盤モデルまたは推論プロファイルを使用して、テキストと画像の両方を含むマルチモーダルデータを処理します
※データ抽出に使用するプロンプトをカスタマイズするオプションが必要です
画像などが含まれているのであれば、2.や3.を選択しておくのが良さそうです!
2.チャンキング戦略を変更する
チャンキング戦略では、前述したチャンクの分割をどのように行うか設定します。
以下の5種類がサポートされています。
- デフォルトチャンキング:
1チャンク最大300トークンで自動的に分割します - 固定サイズのチャンキング:
開発者が指定したサイズに分割します - 階層型チャンキング(Hierarchical chunking):
情報を子チャンクと親チャンクのネスト構造に整理します
検索時は子チャンク、生成時は親チャンクを用いることで、精度向上が見込める - セマンティックチャンキング:
テキストを意味のあるチャンクに分割し理解と情報検索を強化する自然言語処理技術
構文構造だけでなく意味内容に焦点を当てることで、検索精度を向上させる - チャンキングなし:
ドキュメントがすでに上手く分割されている時に使用する
どちらも変更してみた
試しに、どちらもデフォルトから変更してみました。

すると精度が向上しました!
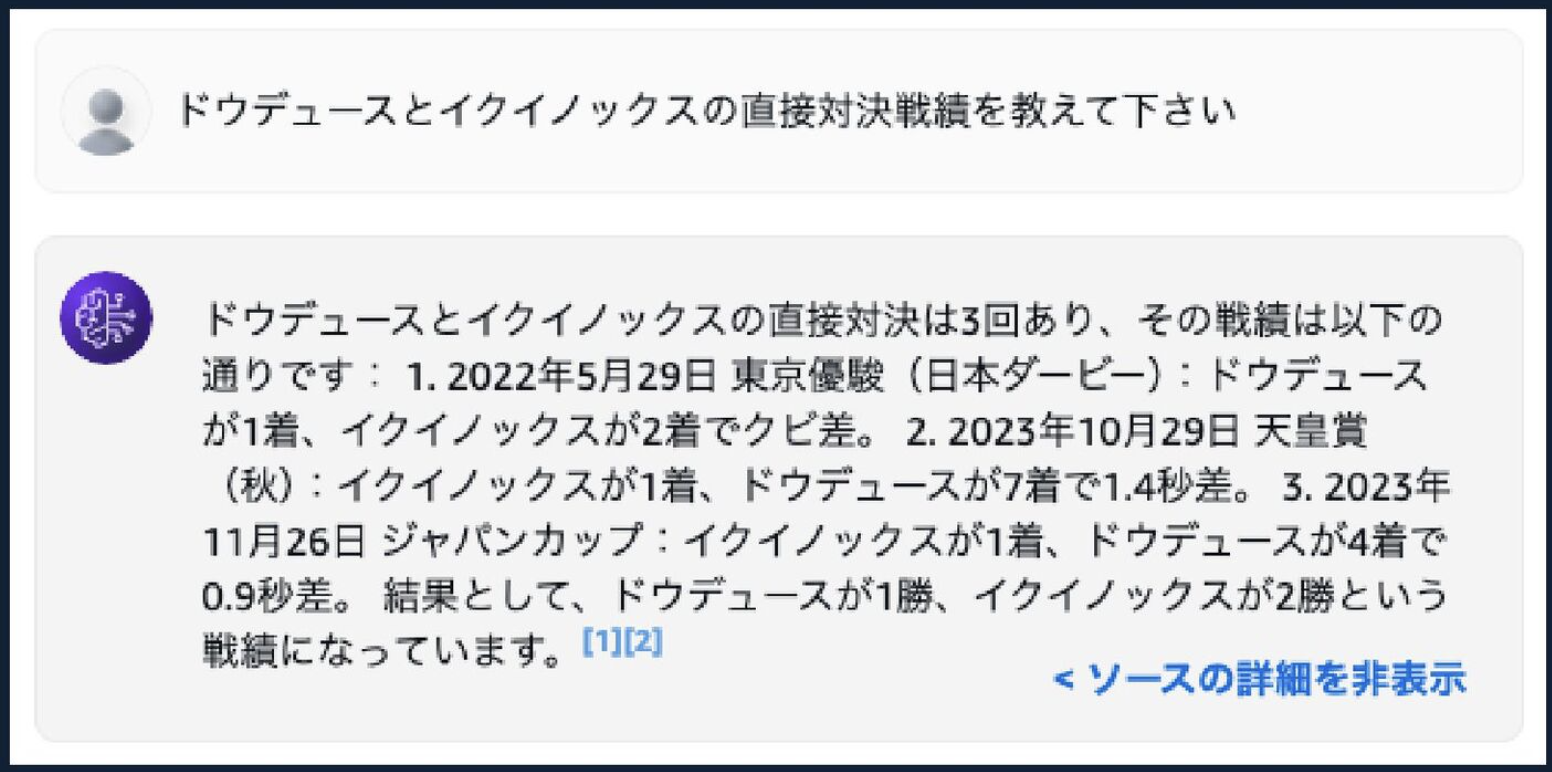
この経験から、ナレッジベースの設定を行う際には解析戦略とチャンキング戦略をきちんと設定してチューニングすることが重要だと理解しました!
GraphRAGに限らず、RAGを構築する際には検討する必要がある箇所だと思います!
良ければこちらの登壇資料も御覧ください!
まとめ
GraphRAG自体は、非常に最先端の技術領域であり、キャッチアップ必須な感じになりつつあると思います。
ただ、ナレッジベース上で作成するのはまだもう一歩?な印象を受けました。
解析戦略やチャンキング戦略をきちんと設定しましょう!精度が大きく変わります!!
それと同時に、利用者側も概念を理解して、実装までできるようにしておく必要があります。
どれだけAIやAWSの機能が進化しても、使い手である人間が追いつけていないと使いこなせません。それを実感するような結果となりました。
次は1から手動でGraphRAGを作ってみて、今回のナレッジベースと精度を比較してみます!