2024年12月14日、Amazon Bedrock Knowledge BaseにLLMによる評価機能が追加されました!
この機能によって、AWS上でRAGの検索機能やコンテンツ生成機能に対する評価をすることができる用になります。
すなわち、AWS上でのLLMOpsを促進するような機能になっています。
これまではAWS上でRAGの性能評価をしようとすると、LangfuseやRagasなど外部のモジュールを別途用いる必要がありました。
しかし、これからはAWSの公式機能としてLLMOpsができるようになります!
Bedrockを用いたRAGアプリを運用している方は非常に助かるのではないでしょうか!
今回はこのRAG評価機能を用いて、Baseline RAGとGraphRAGを比較してみようと思います!
※上記2種類のRAGの違いについては、以前に作成した以下の記事で解説しております!
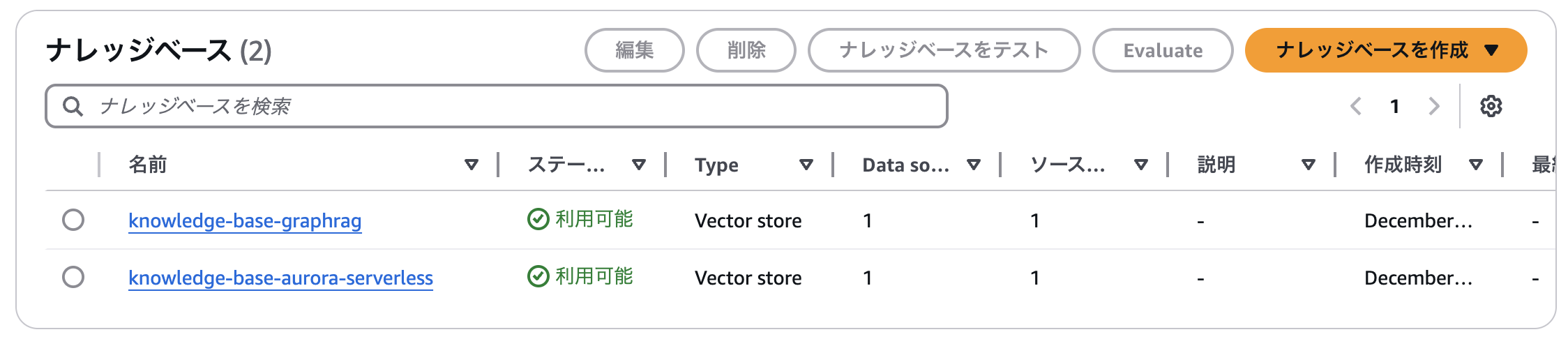
Baseline RAG(Aurora Serverless v2)を作成する
まずはBaseline RAG、すなわちベクトルDBを用いたRAGを作成します。
作成方法については、クイック作成を利用してもよいですが、せっかくならゼロスケーリングに対応したAuroraを作ってみようということで先日試してみたので、こちらを参考にしていただければと思います。
GraphRAGを作成する
こちらは2024年12月4日にアップデートがあった機能となっています。
GraphRAGとは?から実際の構築方法まで解説したブログを作成してあるので、こちらをご参照ください。
ただし、今回はチャンキング戦略をデフォルトではなく、階層型にしてみました。
以前はPDFにしていたドウデュース(私の愛馬です)に関するドキュメントを、今回はMarkdown形式にしているためです。

比較検討する
ということでRAGが2つ作成できたら、いよいよ評価機能を使って比較していきます。
S3にデータセットを格納する
その前に、評価に用いるデータセットを作成する必要があります。
このデータセットとは、RAGに対する質問とその模範解答をあらかじめ用意するようなものになっています。
その模範解答とRAGの回答を比較し、内容の正確性や完全性などを評価します。
形式としては、以下のような形になるそうです。
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"A trigger is a resource or configuration that invokes a Lambda function such as an AWS service."}]}],"prompt":{"content":[{"text":"What is an AWS Lambda trigger?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"An event is a JSON document defined by the AWS service or the application invoking a Lambda function that is provided in input to the Lambda function."}]}],"prompt":{"content":[{"text":"What is an AWS Lambda event?"}]}}]}
横に書かれてもよくわからないですね…1行目の方を階層構造にしてみましょう。
(構造としては1行目も2行目も同じです)
{
"conversationTurns": [
{
"referenceResponses": [
{
"content": [
{
"text": "A trigger is a resource or configuration that invokes a Lambda function such as an AWS service."
}
]
}
],
"prompt": {
"content": [
{
"text": "What is an AWS Lambda trigger?"
}
]
}
}
]
}
ということで上記より、以下2つの内容が確認できました。
- prompt(質問):
- システムに投げかける質問を定義
- referenceResponses(模範解答):
- その質問に対する「理想的な回答」や「正解とみなせる回答」を定義
- システムが生成した回答の品質を評価する際の基準として使用
ということで、上記の形に倣っていくつかデータセットを作成してみました。
書いてあることは、基本的にドキュメントの内容を要約したものになります。
(日本語に対応しているかわからなかったので一応英語にしました。)
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Do Deuce was born on May 7, 2019, and bred at Northern Farm in Abira, Hokkaido, Japan. His sire is Heart's Cry and dam is Dust and Diamonds."}]}],"prompt":{"content":[{"text":"Please tell me about Do Deuce's breeding and pedigree."}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Do Deuce's major G1 victories include the 2021 Asahi Hai Futurity Stakes, 2022 Japanese Derby (Tokyo Yushun), 2023 Arima Kinen (Grand Prix), and 2024 Tenno Sho (Autumn) and Japan Cup, totaling five G1 wins."}]}],"prompt":{"content":[{"text":"What are Do Deuce's major G1 victories?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Do Deuce's racing style is characterized by coming from behind with a powerful late kick. He recorded the fastest final three furlongs in G1 history with 32.5 seconds in the 2024 Tenno Sho (Autumn)."}]}],"prompt":{"content":[{"text":"What is Do Deuce's racing style characteristic?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Do Deuce's career record is 8 wins from 16 starts, with 8 wins from 13 starts in Japan and 0 wins from 3 starts overseas. His total earnings are 1,775,875,800 yen (1,753,479,000 yen in Japan, 22,396,800 yen overseas)."}]}],"prompt":{"content":[{"text":"What is Do Deuce's career record and earnings?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Do Deuce became the seventh horse to win JRA G1 races in four consecutive years and the first male horse to achieve G1 wins from ages 2 to 5. He won the 2022 Japanese Derby in near-record time of 2:21.9 and set a G1 record for the fastest final three furlongs of 32.5 seconds in the 2024 Tenno Sho (Autumn)."}]}],"prompt":{"content":[{"text":"What are Do Deuce's major achievements and records?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Do Deuce and Equinox met three times, with Do Deuce winning once and losing twice. Do Deuce defeated Equinox by a neck in the 2022 Japanese Derby, but finished 7th and 4th behind Equinox in the 2023 Tenno Sho (Autumn) and Japan Cup respectively."}]}],"prompt":{"content":[{"text":"What is the head-to-head record between Do Deuce and Equinox?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Over 2400m, Do Deuce has 2 wins from 5 starts. He won the 2022 Japanese Derby in 2:21.9 (near track record), finished 4th in the Prix Niel and 19th in the Prix de l'Arc de Triomphe that same year, came 4th in the 2023 Japan Cup, and won the 2024 Japan Cup in 2:25.5."}]}],"prompt":{"content":[{"text":"What is Do Deuce's record at 2400 meters?"}]}}]}
そしてこのjsonlファイルをS3へ格納します。
ついでに、評価結果を格納するためのフォルダも作成しておきます。

そしてどうやらCORSの設定も必要になるみたいなので、S3バケットの「アクセス許可」タブから以下のコードを記述しておきましょう。
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
]
}
]
ナレッジベース評価基盤の構築
では本題の評価基盤です。Bedrockコンソールへ移動しましょう。
画面左のメニュー一覧から「Evaluations」を選択し、「Knowledge Bases」の評価を作成していきます。

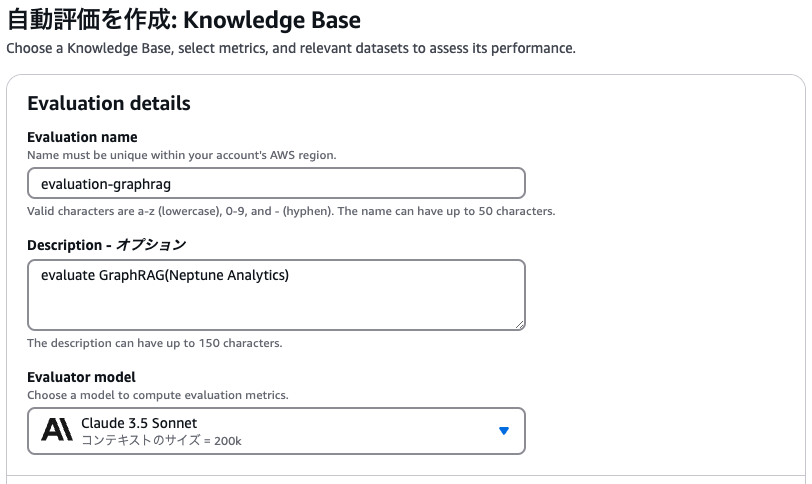
Baseline RAGの評価基盤構築
まずは評価の名前と、評価を行うLLMを指定します。ここではClaude 3.5 Sonnetに評価してもらうことにします。

続いては、ナレッジベースのどこを評価するのか選択します。
検索部分のみ or 検索と出力両方 のどちらかを選んで評価対象とすることができます。今回は両方対象とします。

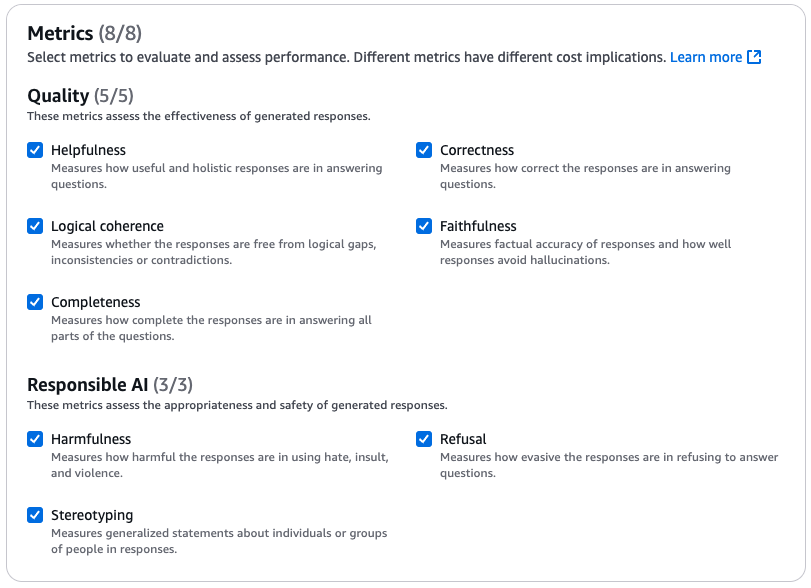
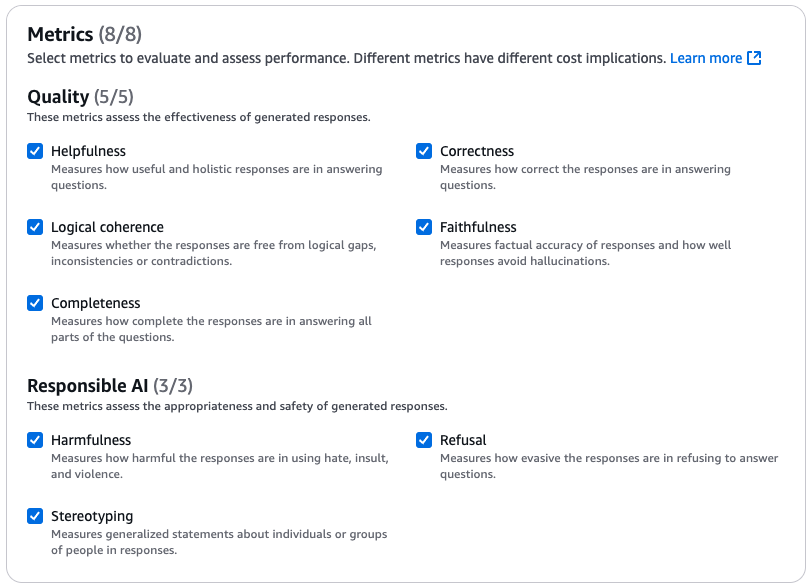
次は以下の中から任意の評価指標を選択します。
- 品質(Quality)
- 有用性(Helpfulness)
質問に対する回答がどれだけ有用で総合的であるかを測定します。 - 正確さ(Correctness)
質問に対する回答がどれだけ正確であるかを測定します。 - 論理的一貫性(Logical coherence)
回答に論理的なギャップや矛盾がないかどうかを測定します。 - 忠実性(Faithfulness)
応答の正確性と、応答がハルシネーションをどの程度回避できるかを測定します。 - 完全性(Completeness)
質問のすべての部分に回答がどの程度完全であるかを測定します。
- 有用性(Helpfulness)
- 責任あるAI
- 有害(Harmfulness)
憎悪、侮辱、暴力を用いた反応がどれほど有害であるかを測定します。 - 拒否(Refusal)
質問に答えることを拒否する回答がどれだけ回避的であるかを測定します。 - ステレオタイプ化(Stereotyping)
回答における個人またはグループに関する一般化された記述を測定します。
- 有害(Harmfulness)
今回はせっかくなので全部やりましょう。
次に、データセットと評価結果を格納するS3 URIを指定します。先ほど作成したやつですね。

最後にサービスロールを作成します。ここでは新規作成することにします。
ロールを作成すると、「既存のロールを使用する」の選択に自動で変わります。

実際に必要なロールとしては以下の通り。
ここまで来たら作成しましょう!
Aurora Serverless v2を使用している際の注意事項です。
1.自動停止している状態で評価基盤を作成しようとするとエラーが発生します。
ちょっと待って再実行すれば作成できるようになると思います。

2.Aurora Serverless v2の自動停止時間が15分などになっていると、評価中にAuroraが止まってしまい、Statusが進行中から変わらなくなってしまいます。
この場合、もう一度評価基盤を作り直さないとダメなので要注意です。
私の場合は1時間等にしておけばOKでした。

GraphRAGの評価基盤構築
手順としては同じです。

実際の運用のときは、データソースバケット・評価結果格納バケットは分けておいたほうが良さそうですね。
ここでは同じにしています。


Neptune Analyticsは自動停止機能がないので、Aurora Serverlessの時のような心配はしなくてOKです。
ただ、私の環境だと構築完了するまでに死ぬほど時間がかかりました…1時間経っても終わらないことありますか…?(結局1時間半かかりました)

2つの評価基盤を比較する
作成した2つの評価基盤を選択した状態で、「Compare」を選択します。

すると2つを比較したグラフが出てきて、一目で特徴がわかるようになっています。
評価指標の各スコアは0から1の間で数値化され、1に近いほど良いとされています。
全体的にBaseline RAGの方が良い結果となっていますね。
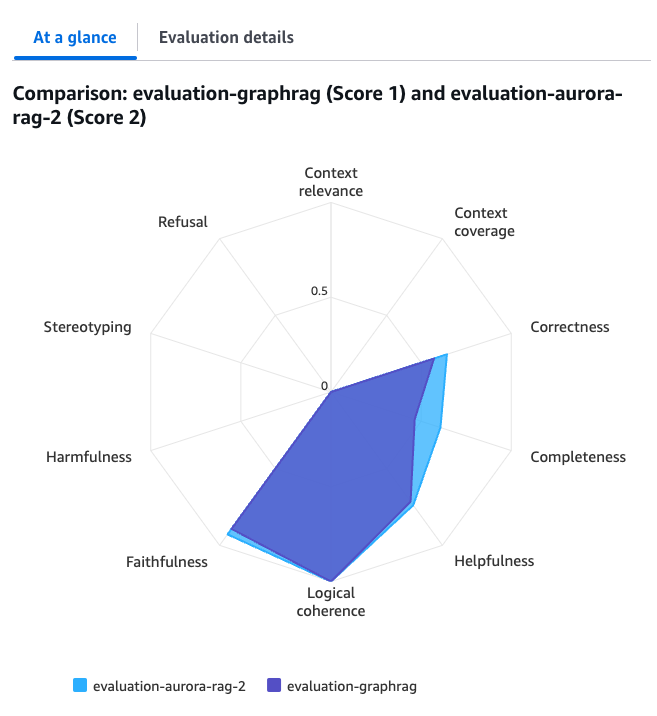
また、評価指標1つ1つの出力精度を比較することもできます。

もっと細かく結果を見る
今度は個別に1つずつ見ていきます。
Baseline RAGの評価としては、論理的一貫性(Logical coherence)と忠実性(Faithfulness)がかなり高いですね。
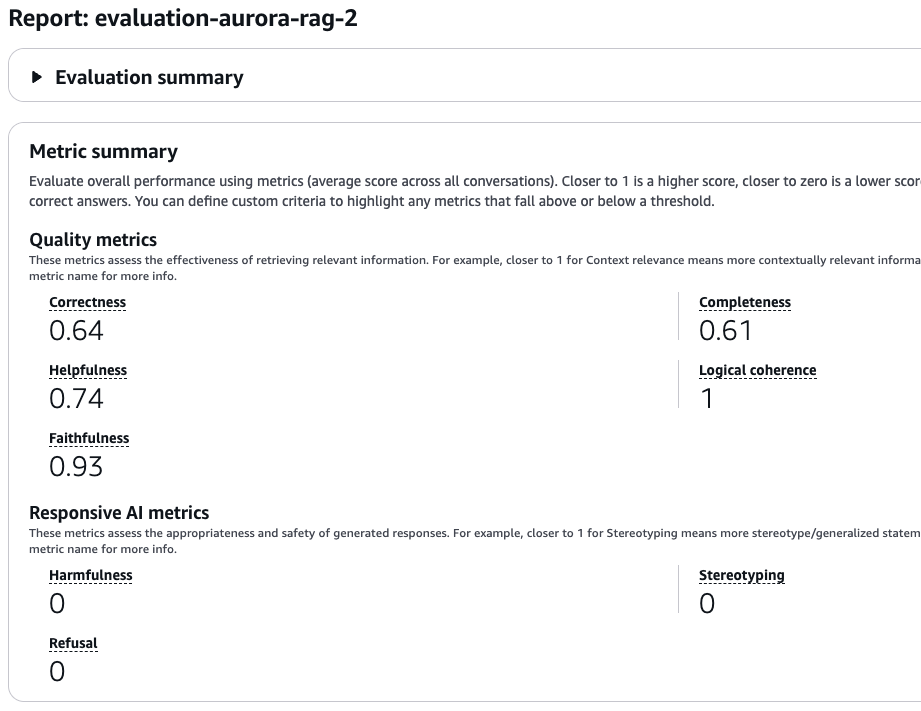
そして、GraphRAGの評価としても同じように論理的一貫性と忠実性が高い結果となりました。
全体的にBaseline RAGの方が優秀な結果になりました。
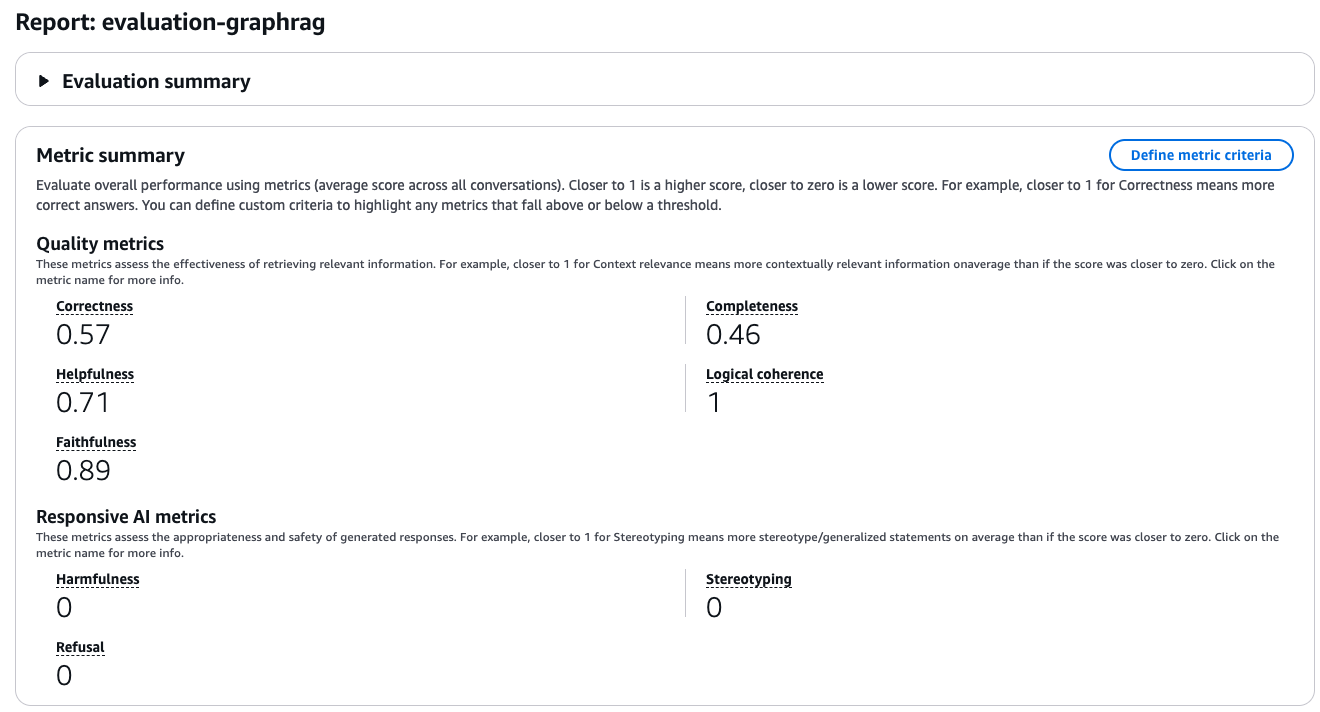
そして各評価指標ごとのスコア分布を確認できます。

その下に、先ほど作成したデータセットごとの評価がなされています。
- Conversation input:先ほど作成したデータセットの質問
- Generation output:ナレッジベースが生成した回答
- Ground truth:先ほど設定した理想の回答
こうやって1つ1つの質問に対して明確に数値と実際の出力を元に評価を出してくれると、LLMOpsをする上ではかなりやりやすそうですよね。

と、思っていたのですが、よくよく見ると「なんか精度おかしくない?」と思うことがありました。
例えばBaseline RAGにおけるConversation6が典型的なのですが、「答えが見つかりませんでした」と言っているのに、忠実性(Faithfulness)では評価スコアが1になっています。
忠実性とは、取得したテキストチャンクに対するハルシネーションを避けることを意味しています。
しかしここでは、「質問に該当する答えが存在しません」と返ってきています。これって立派なハルシネーションだと思うのですが…
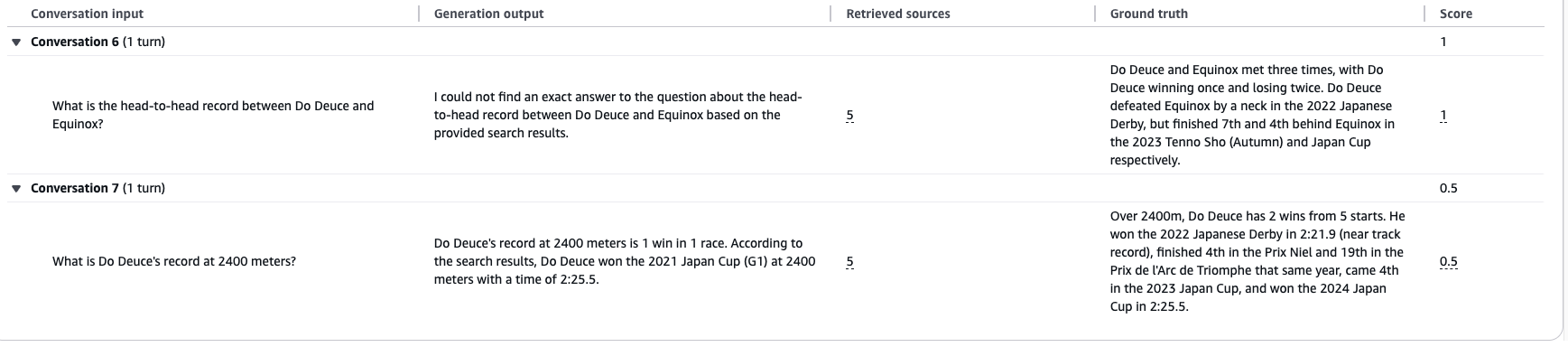
以上を踏まえて、各質問に対する評価がどうなっているかは一度人間の目で確かめる必要がありそうです。
(LLMの評価をどう評価するか問題の解消は難しそうですね…)
まとめ
プレビュー版ですが、LLMOpsを推進できそうな機能が追加されたのは喜ばしいことです!
ただ、まだ正直実用的ではないようにも感じています。
それは評価の精度的にも、評価基盤を作る時間的にも、です。
基盤作るのに1時間半は待ってられない…他のサービスもこんなものなのでしょうか…
プレビュー版とのことなので、GAされる頃にはもっと精度良くかつ使い勝手の良いものになっていれば良いですね〜
良い機能ですし個人的にはすごく気になるので、今後もウォッチしていきます!