あくまで個人的な試験対策メモです。実務で利用される際は信頼できる情報源をご確認ください。
また、一部Claudeに聞いたものを編集しています。
教師あり学習
線形回帰
線形回帰は、データポイント間の関係を直線(または高次元では平面)で表現する統計手法です。
この手法はデータの傾向を理解し、将来の値を予測するのに役立ちます。
線形回帰は「データの中に隠れている線形(直線的)な関係」を見つけることが目的です。
例えば、「勉強時間と成績の関係」や「広告費と売上の関係」など、一方が増えると他方も増える(または減る)ような関係を数式で表します。
解釈しやすく一見良さそうですが、限界もあります。
- 非線形関係の扱い: 実際のデータは直線では表現できないことが多い
- 外れ値の影響: 外れ値に敏感で、結果が大きく変わることがある
- 相関と因果: 相関関係を見つけるだけで、因果関係は示さない
線形最小二乗回帰モデル
線形最小二乗回帰モデルとは、入力変数(特徴量)と出力変数(予測したい値)の間に「直線的な関係」があると仮定して予測を行う統計モデルです。
簡単に言うと、「この特徴量が1単位増えると、予測値はX単位増える」という単純な関係を見つける方法です。
また、複数の特徴量がある場合は、それぞれの影響を足し合わせる
例えば、家の価格を予測する場合には以下のような形になります。
「家の価格 = a + b×広さ + c×築年数 + d×駅からの距離 + ...」(a, b, c, d,はモデルが学習する重み)
線形仮定
線形仮定とは、「入力変数と出力変数の関係は直線(または平面、超平面)で表せる」という前提です。
- 入力変数の変化に対して、出力変数は比例して変化する
- 各特徴量の効果は独立しており、単純に足し合わせることができる
- 予測は各特徴量の「重み付き合計+定数項」として表現できる
線形依存性とその問題
「2つの特性が互いに完全に線形に依存している」とは、一方の特徴量がもう一方の特徴量の単純な倍数になっている状態です。
- 具体例1:身長
- 特徴量1:「メートル単位での身長」(例:1.75m)
- 特徴量2:「センチメートル単位での身長」(例:175cm)
- 特徴量2は常に特徴量1の100倍になるため、これは完全な線形依存関係
- 具体例2:住宅価格の予測
- 家の広さ(平方メートル)
- 家の広さ(坪)
- 駅からの距離
- 築年数
- 「平方メートル」と「坪」は単位が違うだけで、常に一定の関係(1坪 ≈ 3.3平方メートル)がある(=完全な線形依存関係)
完全な線形依存関係がある場合、「多重共線性」という問題が発生します。
これは以下のような現象を引き起こします。
- モデルの解が一意に定まらない:どの特徴量にどれだけ重みを割り当てるべきか決定できない
- 係数の推定が不安定になる:わずかなデータの変化で係数が大きく変わる
- 計算上の問題:行列計算が不安定になり、エラーが発生する可能性がある
- 具体例:住宅価格の予測
- 「平米」と「坪」の両方を使うと、モデルは「広さ1平米の増加は価格にいくら影響するか」と「広さ1坪の増加は価格にいくら影響するか」を同時に決定できなくなる
- 例えば、「1平米あたり10万円」「1坪あたり0円」でも、「1平米あたり0円」「1坪あたり33万円」でも、予測結果は同じになってしまう
- 対処法
- 一方の特徴量を削除する:線形依存している特徴量のうち、一方だけを残す
- 正則化技術を使用する:リッジ回帰やLasso回帰のような方法を適用する主成分分析(PCA)などで次元削減:相関のある特徴量を新しい特徴量に変換する
ロジスティック回帰
1つ以上の入力に基づいてカテゴリ出力を予測します。
特に「はい/いいえ」のような2つのカテゴリのどちらに属するかを予測する統計手法です。
線形回帰は連続的な数値を予測し、ロジスティック回帰は確率を予測します。
その確率に基づいて分類を行うのがロジスティック回帰です。
具体例:大学入試の合否予測
過去の大学入試データから、勉強時間と合否の関係を分析します。
| 学生 | 1日の勉強時間 | 合否結果 |
|---|---|---|
| A | 2h | 不合格(0) |
| B | 3h | 不合格(0) |
| C | 5h | 合格(1) |
| D | 7h | 合格(1) |
| E | 4h | 不合格(0) |
| F | 6h | 合格(1) |
ロジスティック回帰では、S字型のロジスティック関数(シグモイド関数)を使って、勉強時間から合格確率を予測します。
例えば以下のような形です。
- 2時間勉強→合格確率10%
- 4時間勉強→合格確率50%
- 6時間勉強→合格確率90%
ニューラルネットワーク
ニューラルネットワークは、人間の脳の仕組みに着想を得た機械学習モデルです。
複雑なパターンを学習し、画像認識、自然言語処理、ゲームのプレイなど様々なタスクで人間に匹敵する(時には上回る)性能を発揮します。
- 構造
- 入力層: データを受け取る層(例:画像の各ピクセル)
- 隠れ層: 中間処理を行う層(1層〜数百層まで様々)
- 出力層: 最終的な予測や分類結果を出力する層
- 例:住宅価格予測
- 入力特徴量が6個
- 広さ(平方メートル)
- 築年数
- 最寄り駅からの距離(分)
- 部屋数
- 階数
- 地域コード
- ネットワーク構造
- 入力層:6ニューロン
- 隠れ層1:20ニューロン
- 隠れ層2:10ニューロン
- 出力層:1ニューロン(価格)
- これによって、例えば「築年数が古くても、リノベーションされていれば高価になる」といった非線形の関係性も学習できます
- 入力特徴量が6個
SVM(サポートベクターマシン)
SVMは、データを分類するための機械学習アルゴリズムです。
簡単に言うと、SVMは「データを最もきれいに分ける境界線を見つける」方法です。
- 例:犬と猫の写真を分類する場合を考えてみます
- 写真から「耳の形」と「顔の丸さ」という2つの特徴を抽出
- これらの特徴をグラフにプロット
- SVMはこの2つのグループを最もよく分ける線(境界線)を見つける
- SVMの特徴:最大マージン
- 単に線を引くのではなく、両方のグループのデータポイントからできるだけ離れた線を引く
- 新しいデータにも対応できるようにするため
線形SVMと非線形SVM
線形SVMとは、直線(または平面)でデータを分ける方法です。データが以下のように直線で分けられる場合に有効です。
○ ○ ○ | × × ×
○ ○ | × ×
○ ○ ○ | × × ×
一方、非線形SVMとは、直線では分けられないデータを扱います。以下の円形のパターンなどです。この場合、中心にあるグループと外側のグループは直線では分けられません。
× × × × × ×
× ○ ○ ○ ○ ×
× ○ ○ ○ ○ ×
× ○ ○ ○ ○ ×
× × × × × ×
カーネルトリック
非線形SVMで用いられている手法で、データを高次元空間に写像し、その空間では線形分離が可能になるというものです。
- データを高次元の空間に移動(変換)する
- その高次元空間では直線で分けられるようになる
- 元の空間に戻すと、円や曲線などの非線形な境界になる
- 具体例:テーブルの上のおもちゃ
- 前提
- 平らなテーブルの上に丸とバツの形をしたブロックがある
- 上記例のように、丸はテーブルの真ん中にある
- バツはテーブルの端っこにある
- この時、これらを直線で分けることはできない
- カーネルトリックを用いる
- テーブルの中央を押し上げてテーブルを変形させる(=高次元に変換)
- 丸は押し上げられた丘の上に移動し、バツは周りの低い部分に位置する
- この3D空間においてある高さで水平に切ると、丸とバツを分けることができる
(=直線で分ける)
非線形SVMでは、通常パターンを円形の境界線として学習し、その境界の外側にあるものを異常として検出することができる。
先程の図でいうと、丸が正常、バツが異常。
教師なし学習
クラスタリング
クラスタリングは、データの中から類似したグループ(クラスタ)を自動的に発見するための教師なし機械学習手法です。
「似たもの同士をグループ化する」という単純な原則に基づいています。
例えば、お客様の購買パターンが似ている人たちをグループ化して、それぞれのグループに適したマーケティング戦略を立てるといった使い方ができます。
アソシエーションルール学習
アソシエーションルール学習(または相関ルール学習)は、大量のデータから項目間の関連性やパターンを発見するためのデータマイニング手法です。
最も有名な応用例は「買い物かごの分析」で、「商品Aを購入した顧客は商品Bも購入する傾向がある」といった規則性を見つけ出します。
アソシエーションルールは通常「AならばB」(A→B)という形で表され、「前提条件(前件)」と「結論(後件)」から構成されます。
例えば「パンを買う人はバターも買う傾向がある」というルールは「パン→バター」と表現できます。
次元削減
次元削減は、データセット内の特徴数を減らす教師なし学習手法であり、高次元のデータを低次元に変換しながらできるだけ元の情報を保持する技術です。
私たちが扱うデータは多くの場合、たくさんの特徴量(変数)を持っています。
例えば、顧客データなら年齢、収入、購買履歴など多数の項目があります。
これらの特徴量は各々が「次元」を構成し、10の特徴量があれば10次元のデータということになります。
次元削減はこの高次元データを、重要な情報をできるだけ残しながら、より少ない次元に圧縮する技術です。
代表的な次元削減手法:主成分分析(PCA: Principal Component Analysis)
最も広く使われている次元削減手法で、データの分散が最大になる方向(主成分)を見つけます。
- 具体例:顔画像データの圧縮
- 前提条件
- 顔画像のデータセットがある
- 一枚の画像が100×100ピクセルだとすると、それは10,000次元のデータ(各ピクセルが1次元)
- PCAの適用
- 多数の顔画像から「平均顔」を計算
- 各顔が「平均顔」からどのように変化しているかを分析
- 最も変化が大きい方向(主成分)を特定
- 第1主成分:明るさの変化かもしれない
- 第2主成分:顔の幅の変化かもしれない
- 第3主成分:笑顔/真顔の違いかもしれない
- 結果
- 10,000次元→50次元に削減しても、顔の特徴をほぼ保持できる
- 各顔は50個の数値(主成分スコア)で表現可能に
- 元のサイズの0.5%まで圧縮しながら、顔の識別に必要な情報を保持
アルゴリズム
XGBoost(eXtreme Gradient Boosting)アルゴリズム
XGBoostは勾配ブースティングという機械学習の手法をより高速かつ効率的に行えるよう改良した教師あり学習アルゴリズムです。
勾配ブースティングとは、いくつもの弱い予測モデル(決定木など)を組み合わせて、強力な予測モデルを作り上げる技術です。
XGBoostの仕組みと流れ
XGBoostを理解するための例として、「住宅の価格予測」を考えてみます。
1. 決定木とは?
決定木(Decision Tree)とは、「もしこれなら、こう判断する」というルールを木の形で表したものです。
「家の広さが80㎡より大きい?」
|
├── はい → 「駅から徒歩10分以内?」
| |
| ├── はい → 予測価格: 5000万円
| └── いいえ → 予測価格: 4000万円
|
└── いいえ → 予測価格: 3000万円
2. 決定木の弱点
一つの決定木だけだと、複雑なパターンを捉えきれません。
たとえば上記の木では「築年数」や「日当たり」などの要素を考慮できていません。
3. ブースティングという解決策
XGBoostの「Boosting」とは、複数の決定木を順番に作っていく方法です。大事なポイントは以下の2点。
- 最初の木:基本的な予測をする
- 次の木以降:前の木が間違えた部分を重点的に修正する
例えば住宅価格の予測で考えると、
-
最初の木(Tree 1)
- 広さだけで予測
- ある家の実際の価格は4500万円だが、予測は4000万円(誤差500万円)
-
2つ目の木(Tree 2):
- 最初の木の誤差を修正することに集中
- 「日当たりが良い家は予測より+500万円高い」というルールを学習
-
3つ目の木(Tree 3):
- さらに残った誤差を修正
- 「築年数が10年未満なら+200万円」というルールを学習
-
最終予測:
- Tree 1 + Tree 2 + Tree 3 の予測を合計
= 4000万円 + 500万円 + 200万円 = 4700万円
(実際の4500万円により近くなった!)
- Tree 1 + Tree 2 + Tree 3 の予測を合計
XGBoostの特徴
- 徐々に改善していく(Gradient Boosting)
- 最初の予測を大まかに行い、次第に細かい誤差を修正していきます
- 絵を描く時に、最初は下書きをして、徐々に細部を加えていくようなイメージ
- とても速い(eXtreme)
- 通常のGradient Boostingより計算が速く、大きなデータでも効率的に学習できます
(これが「eXtreme」の由来)
- 通常のGradient Boostingより計算が速く、大きなデータでも効率的に学習できます
- 過学習を防ぐ機能がある
- 過学習:訓練データには合うが、新しいデータには合わないモデルになってしまう問題
- XGBoostには自動的に過学習を防ぐ仕組みがあります
- 欠損値に強い
- データに穴があっても(例:一部の家の築年数が不明など)、自動的に対処可能
実際の使用例
- 例1:クレジットカード審査
銀行がXGBoostを使って、クレジットカード申込者の審査を行うケース- 入力データ:年齢、収入、職業、過去の借入状況など
-
XGBoostの動作:
- Tree 1:収入で大まかに分類
- Tree 2:年齢と職業の組み合わせで修正
- Tree 3:過去の返済履歴で更に修正
- (以下続く...最終的に100個程度の木を組み合わせる)
- 出力:この人が返済できる確率は87%
==============
-
例2:オンラインショップのレコメンデーション
あるECサイトでXGBoostを使って商品をレコメンドするケース- 入力データ:ユーザーの過去の購入履歴、閲覧履歴、年齢層など
-
XGBoostの動作:
- Tree 1:類似ユーザーの購入傾向で大まかに予測
- Tree 2:季節要因を考慮して修正
- Tree 3:価格帯の好みで更に修正
- 出力:このユーザーがこの商品を購入する確率は65%
他のアルゴリズムとの比較
- 線形回帰:シンプルだが、複雑な関係を捉えられない
- 単一の決定木:解釈しやすいが、予測精度がXGBoostより低い
- ランダムフォレスト:複数の木を「並列」に作る(XGBoostは「順番」に作る)
- ニューラルネットワーク:より複雑なパターンを捉えられるが、大量のデータと計算リソースが必要
DeepARアルゴリズム
線形学習(Linear Learner)アルゴリズム
Linear Learner は Amazon SageMaker の組み込みアルゴリズムで、線形モデル(線形回帰やロジスティック回帰など)をトレーニングするためのアルゴリズムです。
具体例:サブスク解約予測モデルの作成
- 課題
- クラスの不均衡:解約する顧客が非常に少ない
- 特徴量間の強い相互依存性:カテゴリ特性と数値特性の間に強い関連がある
- Linear Learnerの特徴
- クラス不均衡へ対応できる
- 離脱予測では「解約する顧客」が少数派
- 例えば、顧客10,000人中、解約した顧客が500人(5%)とする
- このような不均衡データに対して、以下のような対応を取る
- 通常のアルゴリズム:全員が解約しないと予測→精度95%(ただし役に立たない)
- Linear Learner:クラス重み付け機能でバランスを自動調整→解約顧客も正しく予測
- 特徴量への相互依存性へ対応できる
- 例えば会員レベルと購入頻度に強い相互依存性があると仮定
- 会員レベルが高いと購入頻度が高く、レベルが低いと頻度も低い状態
- 相互依存性に対して、Linear LearnerはL1正則化(Lasso)を提供
- 通常の線形モデル:相互依存する特徴量が互いに干渉し、予測精度が下がる
- L1正則化:重要な特徴量だけを自動選択し、関連性の強い特徴間の問題を軽減
- 例えば会員レベルと購入頻度に強い相互依存性があると仮定
- 運用が容易
- 自動ハイパーパラメータ最適化:複数のハイパーパラメータ設定を並列試行
- 組み込みアルゴリズム:コンテナ準備や環境設定が不要
- スケーラビリティ:自動的に分散トレーニングが可能
- クラス不均衡へ対応できる
ランダムカットフォレスト(RCD)アルゴリズム
- ランダムカットフォレスト(RCF)は、異常検出に特化した教師なし学習アルゴリズム
- 「通常とは異なる挙動」を検出するのが得意で、Amazon SageMakerの組み込みアルゴリズムとして提供されています
- 使用例:IoTセンサーが異常な値を示しているときにそれを検出する
- センサーデータの性質に適している
- IoTセンサーから得られる温度・圧力・使用状況・エラー率などのデータは時系列データであり、正常時と異常時でパターンが変化する
- RFCは時系列データ内の異常パターンを検出するのに優れている
- 故障の前兆を捉える
- 通信機器が故障する前には、通常とは異なる振る舞いを示すことがよくある
- RFCは「通常と違う」パターンを、センサーが完全に故障する前に検出できる
- 例えば、温度の急上昇・エラー率の増加・不規則な圧力変動など
- 教師なし学習の利点を活かせる
- 故障データは非常に少ないことが多いため、教師あり学習が難しいケースもある
- RFCでは、正常データのみを学習すれば良い
- 明示的な故障ラベルが不要で、未知の種類の故障であっても検出が可能
- センサーデータの性質に適している
- 実際の適用例
- 学習フェーズ
- 過去6ヶ月の正常なネットワーク機器のセンサーデータを収集
- RCFモデルにこの「正常」データを学習させる
- モデルが「正常」の範囲やパターンを学習
- 予測フェーズ
- 現在のセンサーデータをリアルタイムでモデルに送信
- モデルが「異常度スコア」を計算
- 例:ある機器の温度とエラー率が徐々に上昇し、異常スコアが閾値を超えた場合、「48時間以内に故障の可能性あり」という警告が発生
- メンテナンス最適化:
- 異常検出の結果に基づいて優先順位を設定
- スコアが高い機器から点検・修理
- 計画外のダウンタイムを回避
- 学習フェーズ
K-means(K平均法)アルゴリズム
K-meansは、データ点をK個のクラスター(グループ)に分類する教師なし機械学習アルゴリズムです。
似た特徴を持つデータポイントをグループ化するのに役立ちます。
- 動作手順
- クラスター数(K)の指定
→いくつのグループに分けたいかを決めます(K=3なら3グループ) - 初期セントロイド(中心点)の配置
→ランダムにK個の点を初期中心点として選びます - クラスター割り当て
→各データ点を最も近い中心点を持つクラスターに割り当てます - 中心点の更新
→各クラスター内のデータ点の平均位置を計算し、中心点を更新します - 収束するまで繰り返し
→クラスター割り当てと中心点更新を、変化がなくなるまで繰り返します
- クラスター数(K)の指定
- 具体例:顧客のセグメンテーション
- 顧客を購買パターンでグループ分けしたいとします
- データとして、各顧客の「年間購入額」と「購入頻度」があります
- 顧客1: 年間購入額 $1500, 購入頻度 12回/年
- 顧客2: 年間購入額 $300, 購入頻度 3回/年
- 顧客3: 年間購入額 $2000, 購入頻度 24回/年
- 顧客4: 年間購入額 $500, 購入頻度 4回/年
- ...(他の顧客データ)
- K-meansを適用する(K=3と仮定)
- まず3つのランダムな点を初期中心点として選びます
- 各顧客データを最も近い中心点に割り当てます
- 各クラスターの中心点を更新します
- これを繰り返します
- 最終的に3つの顧客グループが得られます
- グループA: 「高額・頻繁購入」顧客(VIP客)
- グループB: 「中程度の金額・頻度」顧客(一般客)
- グループC: 「少額・稀な購入」顧客(低頻度客)
- 会社はこの情報を活用して、グループごとに異なるマーケティング戦略を立てることができます
ニューラルトピックモデル
モデルのトレーニング
振動問題とその対策
需要予測のRNNモデルにおいて、トレーニング中に損失値が振動し安定しないという問題が発生することがある。
これの解決には、「学習率を下げる」 ことが有効
- 振動問題の状況例
- トレーニング損失と検証損失が上昇
- 損失値が「下がる→上がる→下がる…」と振動
- 学習率とは?
- モデルがパラメータを更新する「歩幅」のようなもの
- 高い学習率…大きな歩幅で進む (速いが不安定になりやすい)
- 低い学習率…小さな歩幅で進む (遅いが安定しやすい)
- なぜ損失が振動するのか?
- 学習率が高いと、細かい修正が効かないため
- 例:学習率0.1の場合、損失値が上下する
エポック1: 損失 = 12500(スタート) エポック2: 損失 = 9000(大幅に改善) エポック3: 損失 = 10200(悪化!) エポック4: 損失 = 8800(改善) エポック5: 損失 = 9600(また悪化!)- 例:学習率0.01の場合、より小さな歩幅にすることで、改善が見込める
エポック1: 損失 = 12500(スタート) エポック2: 損失 = 11000(小幅に改善) エポック3: 損失 = 9800(さらに改善) エポック4: 損失 = 8900(さらに改善) エポック5: 損失 = 8200(安定して改善) - 学習率を下げるメリット
- 安定性の向上: 損失関数の値が安定して減少する
- 最適解への収束: 振動せずに最適解へ近づける
- オーバーシュートの防止: 最適解を行き過ぎるのを防ぐ
- 追加の対策例
- 学習率スケジューラの使用:トレーニングが進むにつれて学習率を自動で下げる
- モメンタムの追加: 過去の勾配情報を活用して安定化
損失値(Lost Value)
損失値は「モデルの予測がどれだけ間違っているか」を数値で表したものです。値が小さいほど予測が正確です。
- 例:電力需要予測
- 実際の電力需要:1000kW
- モデルの予測:1200kW
- 誤差:200kW
- 損失値:この誤差を二乗するなどして計算した値
- 代表的な損失関数
- 平均二乗誤差(MSE):(予測値 - 実際値)²の平均
- 平均絶対誤差(MAE):|予測値 - 実際値|の平均
- トレーニングでの役割
- 機械学習のトレーニングは「損失値を最小化する」ことが目標です。損失値が下がれば予測精度が向上します
RNN (リカレントニューラルネットワーク)
記憶力を持つニューラルネットワークのことで、過去に見たデータをメモリーに保存することで覚えておくことができる機能を持っている。
- 例:明日の電力需要予測
- 通常のNN:今日の気温と曜日から予測する
- RNN:過去1週間の電力使用パターンも考慮して予測する
確率的勾配降下法(SGD)
SGDは「モデルの損失値を最小化するためのパラメータ調整方法」です。
山を下る登山者のように、最も急な下り坂を少しずつ降りていきます。
- 例:電力需要予測モデルのトレーニング
- ランダムなパラメータで予測開始(山の頂上からスタート)
- 予測と実際の値を比較し損失値を計算
- 損失値が減る方向にパラメータを少し調整(少し下に降りる)
- 2と3を何度も繰り返す(山の底に到達するまで)
- SGDの特徴
- 確率的:全データではなく、一部のデータ(ミニバッチ)だけを使う
- 勾配:損失が最も急速に減少する方向
- 降下法:その方向にパラメータを更新
- RNNモデルをトレーニングする際の使用例
- モデルが電力需要を予測
- 予測と実際の値を比較して損失値を計算
- SGDが損失値を減らすようにRNNのパラメータを調整
- 学習率が高すぎると損失値が振動し、低いと安定するが遅くなる
機械学習のトレーニングは、この「予測→損失計算→パラメータ調整」のサイクルを何度も繰り返すことで進められます。
スタッキングによるパフォーマンス向上
スタッキングは、複数の異なる機械学習モデル(ベースモデル)の予測結果を組み合わせて、それらの上に「メタモデル」を構築する手法です。
金融の世界で例えると、複数のアナリストの意見を集めて、それぞれの得意分野を活かしながら最終決定をする「投資委員会」のようなものです。
- 具体例:金融サービス企業における信用リスク予測でのスタッキング
- 各ベースモデルを学習データで訓練する
- 交差検証で各モデルの予測値を生成する
- これらの予測値を新しい特徴量として、メタモデル(ランダムフォレストなど)を訓練する
- テストデータでは、各ベースモデルの予測結果をメタモデルに入力して最終予測を行う
- スタッキングの利点
- 多様な視点: 異なるアルゴリズムの強みを組み合わせる
(ロジスティック回帰の線形パターン認識と決定木の非線形パターン認識など) - 堅牢性の向上: 一つのモデルの誤りを他のモデルで補完できる
- 予測精度の向上: 複数のモデルの「集合知」により、より正確な予測が可能
- 多様な視点: 異なるアルゴリズムの強みを組み合わせる
- 他のアンサンブル手法との違い
-
バギング(例:ランダムフォレスト)
- 特徴: 同じアルゴリズムの複数モデルをデータのサブセットで訓練し、結果を平均化/多数決
- 目的: 分散を減らし、過学習を防ぐ
- 例: 10個の決定木をそれぞれ異なるデータサンプルで訓練
- スタッキングとの違い: バギングは同じタイプのモデルを使用、スタッキングは異なるタイプのモデルを組み合わせる
-
ブースティング(例:XGBoost、AdaBoost)
- 特徴: モデルを逐次的に構築し、各モデルは前のモデルの誤りに焦点
- 目的: バイアスを減らし、徐々に予測精度を向上
- 例: 最初の決定木の誤分類データに重みを増やして次の木を訓練
- スタッキングとの違い: ブースティングは逐次的、スタッキングは並列処理が可能
-
バギング(例:ランダムフォレスト)
スタッキングの具体例:クレジットカード審査システム
- 前提条件
- データ: 1万人分の過去の申込者データ(年齢、収入、借入履歴など10項目)と、実際に返済できたかどうか
- 目標: 新規申込者の返済リスクを正確に予測したい
ステップ1: 複数のベースモデルを訓練する
まず、それぞれ異なる性質を持つ3つの予測モデルを訓練します
訓練データ(8,000人分)
↓ ↓ ↓
モデルA: ロジスティック回帰(線形関係に強い)
モデルB: 決定木(「もし収入が30万以上かつ年齢が35歳以上なら...」といった条件分岐に強い)
モデルC: サポートベクターマシン(複雑なパターンに強い)
ステップ2: 交差検証で予測値を生成する
ここが少し複雑なポイントです。単純に訓練データに対する予測を使うと過学習するので、交差検証を使います
- 訓練データを5分割する(各1,600人ずつ)
- 4分割(6,400人)で各モデルを訓練し、残り1分割(1,600人)の予測を行う
- これを5回繰り返し、全8,000人分の予測値を得る
例えば:
分割1(1,600人)の予測値 ← モデルA(分割2〜5で訓練)
分割2(1,600人)の予測値 ← モデルA(分割1,3〜5で訓練)
...
分割5(1,600人)の予測値 ← モデルA(分割1〜4で訓練)
これにより、モデルA、B、Cそれぞれから8,000人分の予測値が得られます:
- モデルAの予測:「申込者1は返済確率85%、申込者2は返済確率62%...」
- モデルBの予測:「申込者1は返済確率78%、申込者2は返済確率70%...」
- モデルCの予測:「申込者1は返済確率82%、申込者2は返済確率58%...」
ステップ3: メタモデルを訓練する
各ベースモデルの予測値を新しい特徴量として、メタモデルを訓練します
新しい訓練データ:
- 特徴1: モデルAの予測値(返済確率)
- 特徴2: モデルBの予測値(返済確率)
- 特徴3: モデルCの予測値(返済確率)
- 目標変数: 実際に返済できたかどうか
このデータでメタモデル(ランダムフォレストなど)を訓練します
メタモデル学習:「もしモデルAが85%以上かつモデルCが80%以上なら返済可能性高い」といったルールを学習
ステップ4: テストデータで最終予測を行う
新しい申込者(テストデータ2,000人分)に対して、
- モデルA、B、Cそれぞれで予測を行う
- モデルA: 新規申込者Xは返済確率90%
- モデルB: 新規申込者Xは返済確率75%
- モデルC: 新規申込者Xは返済確率85%
- これらの予測値をメタモデルへの入力として使用
メタモデルへの入力: [0.90, 0.75, 0.85] - メタモデルが最終予測を行う
メタモデルの予測: 「返済確率88%」
実世界での具体例
クレジットカード会社でのリスク評価:
-
モデルA(ロジスティック回帰): 信用スコア、年齢、収入の線形関係を捉える
- 長所: 高収入・高信用スコアの人をうまく評価
- 短所: 複雑な関係(若いのに高収入など)を見逃す
-
モデルB(決定木): 「収入30万円以上+過去延滞なし→返済可能性高い」などのルールを学習
- 長所: 特定のルールベースの判断に強い
- 短所: 細かな変化に敏感すぎる
-
モデルC(SVM): 複雑な非線形パターンを捉える
- 長所: 普通では見つけられないパターンを発見
- 短所: なぜそう判断したか説明が難しい
メタモデル(ランダムフォレスト): 「モデルAが高リスクと判断しても、モデルBとCが低リスクなら承認」などの組み合わせルールを学習
現実の効果
- モデルA単独: 正確度75%
- モデルB単独: 正確度72%
- モデルC単独: 正確度78%
- スタッキング後: 正確度84%
上記のように、スタッキングを用いることで「人間の委員会」のように、各専門家(モデル)の意見を組み合わせることができ、より賢い判断を行えるように学習を進められます。
モデルの過学習(オーバーフィッティング)
オーバーフィッティングとは、機械学習モデルがトレーニングデータに対しては正確な予測をするが、新しいデータについては正確に予測しないという、望ましくない機械学習の動作のことです。
例えば、医療画像分類のディープラーニングモデルで考えると、以下のような状況です。
- トレーニングデータでは精度98%
- テストデータでは精度75%
- データセットが限られている(例:1,000枚の肺CT画像)
- モデルがトレーニングデータのノイズまで学習してしまう
- モデルが複雑(例:多くの層を持つCNN)
これはつまり、モデルがトレーニングデータの特徴を「暗記」してしまい、新しいデータに対応できていないような状況です。
人間でいうと、「テストで出た問題だけは完璧に解けるが、少し形式が変わると全く解けなくなる」状態です。
解決策1:データ拡張(Data Augmentation)
既存の画像を少し変化させて、新しいトレーニングデータを作り出します。
- 例:肺の病気(肺結節)に関する検出モデル
- 元のデータ:1,000枚の肺CT画像
- データ拡張の適用
- 画像を少し回転(±10度)
- 少しズームイン/アウト(±10%)
- 上下左右に少しずらす
- 明るさをわずかに変える
-
効果:
- 実質的なトレーニングデータが5倍以上に増加
- モデルは「結節の位置が少しずれても同じ診断」と学習
- 様々な条件(角度、明るさ)に対応できるようになる
解決策2:早期停止(Early Stopping)
モデルの学習をちょうど良いタイミングで止めることで、過学習を防ぎます。
先程の肺結節検出モデルの学習過程で考えると、過学習が発生する状況は以下のイメージです。
エポック 10: トレーニング精度 85%, 検証精度 82%
エポック 20: トレーニング精度 92%, 検証精度 86%
エポック 30: トレーニング精度 95%, 検証精度 88%
エポック 40: トレーニング精度 97%, 検証精度 87% ← 検証精度が下がり始めた
エポック 50: トレーニング精度 99%, 検証精度 83% ← 過学習が進行中
早期停止の実装により、以下の効果が得られます。
- 検証精度が最高だったエポック30のモデルを自動的に選択
- トレーニング精度95%、検証精度88%の「バランスの取れた」モデルが得られる
解決策3:アンサンブル(Ensemble)
複数の異なるモデルを組み合わせ、「多数決」や「平均」で最終予測を行います。
上記のスタッキングやバギング、ブースティングがこれに該当します。
- 例:肺結節検出において5つの異なるモデルを作成
- アンサンブルの構成
- モデルA:通常のCNN(ResNet50ベース)
- モデルB:別の構造のCNN(DenseNetベース)
- モデルC:モデルAと異なるランダムシードで初期化
- モデルD:少し浅いCNNモデル
- モデルE:少し深いCNNモデル
- 効果
- 個々のモデル精度:85-88%
- アンサンブル後の精度:91%
- モデルごとの異なる「得意・不得意」が互いに補完される
- アンサンブルの構成
これら3つの技術を組み合わせると、互いの長所を活かして短所を補います。
-
データ拡張:限られたデータを最大限活用し、多様性を生み出す
- 例:1,000枚のCT画像から実質的に5,000枚を生成
-
早期停止:各モデルの学習を最適なタイミングで止める
- 例:5つのモデルそれぞれがベストな段階で学習終了
-
アンサンブル:複数の視点からのセカンドオピニオンを得る
- 例:医師が複数の専門家の意見を参考にするように、5つのモデルの意見を統合
この組み合わせにより、限られたデータでも一般化性能の高い、信頼性のあるモデルを構築できます。これは特に医療画像のような「間違いが許されない」分野で重要です。
解決策4:正規化
上記以外にも解決策があります。
正規化とは、モデルが複雑になりすぎるのを防ぐ技術です。
- 正規化手法
- L1正規化とL2正規化がある
- 正規化の効果
- モデルが複雑すぎたり、パラメータが多すぎたりすることによる過学習を防ぐ
- モデルがあまりにも複雑な説明をしないように制約をかける
# 正規化なしのモデル(過学習しやすい) 「身長180cm以上、体重75kg以下、血圧135-138、年齢27-29歳の人は疾患リスクが高い」 # 正規化ありのモデル(より一般化されている) 「身長が高く、体重が軽めで、血圧が少し高い人は疾患リスクがやや高い」
解決策5:ドロップアウト
主にニューラルネットワークで使用される正規化技術の一種です。
トレーニング中、ランダムにニューロン(ノード)を無効化することで、モデルが特定のパターンに過度に依存するのを防ぎます。
- ドロップアウトの仕組み
- 各トレーニングステップで、ランダムに選ばれたニューロンを一時的に無効化(確率pで選択)
- 残ったニューロンだけでトレーニングを進める
- テスト時にはすべてのニューロンを使用するが、出力に(1-p)を掛けて調整
- ドロップアウトの効果
- モデルが特定のパターンへ過度に依存することによる過学習を防ぐ
- 属人化の排除取り組みに似ている
# ドロップアウトなし 「いつも同じメンバー5人で問題を解く」→一部のメンバーに依存、誰かが休むと機能しない # ドロップアウト導入 「毎回ランダムに2人休む状況で問題を解く」→全員が基本スキルを身につけ、誰が休んでも機能する
過学習を改善する:SageMaker Debugger
Debuggerは、モデルのトレーニング中に発生する様々な問題を検出し、可視化するツールです。
特に以下の問題を特定するのに役立ちます。
- オーバーフィッティング: トレーニングデータに過剰に適合し、新しいデータでの汎化性能が低下する問題
- 消失勾配: 深層ニューラルネットワークでよく見られる、勾配が非常に小さくなり学習が進まなくなる問題
- 飽和活性化関数: 活性化関数の出力が飽和状態になり、モデルの学習能力が低下する問題
特徴エンジニアリング
特徴量エンジニアリングとは、生のデータから機械学習アルゴリズムがより効果的に学習できる新しい特徴(変数)を作成するプロセスのことです。
料理に例えると、
- 生のデータ = 収穫したままの野菜や肉
- 特徴エンジニアリング = 野菜を切る、肉を適切な大きさに切る、下味をつける
- 良い特徴量 = 使いやすく、料理に適した状態の材料
特徴エンジニアリングの手法
- 特徴分割(Feature Splitting)
- 定義:1つの特徴(変数)を複数の特徴に分割する手法
- 「2025-03-31」という日付を「年=2025」、「月=03」、「日=31」の3つの特徴に分割
- 「東京都渋谷区」という住所を「都道府県=東京都」、「市区町村=渋谷区」に分割
- メリット
- 複合情報から個別の意味のある情報を抽出できる
- 各成分が持つ独自の影響をモデルが学習できる
- 定義:1つの特徴(変数)を複数の特徴に分割する手法
- ビニング(Binning)
- 定義:連続値を離散的なカテゴリ(ビン/区間)に変換する手法
- 年齢(連続値)を「若年層(18-30)」、「中年層(31-50)」、「高齢層(51以上)」にグループ化
- 建物面積を「小型(〜50m²)」、「中型(51-150m²)」、「大型(151m²〜)」に区分
- メリット
- ノイズの影響を減らせる
- 非線形関係をシンプルに捉えられる
- 外れ値の影響を軽減できる
- 定義:連続値を離散的なカテゴリ(ビン/区間)に変換する手法
- ワンホットエンコーディング(One-Hot Encoding)
- 定義:カテゴリカル変数を複数の二値特徴(0か1のみ)に変換する手法
- 「赤、青、緑」という色のカテゴリを「赤=[1,0,0]」、「青=[0,1,0]」、「緑=[0,0,1]」に変換
- 都市名「東京、大阪、名古屋」を「東京=[1,0,0]」、「大阪=[0,1,0]」、「名古屋=[0,0,1]」に変換
- メリット
- 数値に順序関係がないカテゴリデータを機械学習モデルで扱える形に変換
- 各カテゴリが独立した特徴として扱われる
- 定義:カテゴリカル変数を複数の二値特徴(0か1のみ)に変換する手法
- 標準化(Standardization)
- 定義:データを平均0、標準偏差1の分布に変換する手法
- 建物面積データ[50, 100, 200, 150]m²(平均125、標準偏差64.5)を標準化すると
[-1.16, -0.39, 1.16, 0.39]になる
- 建物面積データ[50, 100, 200, 150]m²(平均125、標準偏差64.5)を標準化すると
- メリット
- スケールの異なる特徴間の比較が容易になる
- 勾配降下法など多くの機械学習アルゴリズムの収束を早める
- 特徴間の重要度の偏りを減らす
- 定義:データを平均0、標準偏差1の分布に変換する手法
ドメイン固有の特徴エンジニアリング
ドメイン固有とは、その業界や分野に特化した知識を活用すること
- 例:信用リスク評価
- 基本データ
- 月収: 30万円
- 借入残高: 300万円
- 過去の支払い履歴: [遅延なし, 遅延なし, 5日遅延, 遅延なし, 遅延なし, 遅延なし]
- 勤続年数: 5年
- 住居形態: 賃貸
- ドメイン固有の特徴エンジニアリング
- 債務対所得比(DTI)の計算
- 公式: 借入残高 ÷ (月収 × 12)
- 計算例: 300万円 ÷ (30万円 × 12) = 0.83 (83%)
- 意味: 年収に対する借入の比率。高いほどリスクが大きい
- 支払い履歴の安定性スコア
- 計算例: 最近6ヶ月の遅延回数 = 1回、平均遅延日数 = 5日÷6 = 0.83日
- 新しい特徴量: 「支払い安定度」= 10 - (遅延回数 × 2 + 平均遅延日数) = 7.17
- 意味: 高いほど支払いが安定している
- 雇用安定性スコア
- 計算例: 勤続年数に基づくスコア = min(勤続年数, 10) = 5
- 意味: 勤続年数が長いほど収入が安定している可能性が高い
- 住居コスト推定
- 住居形態から月々のコスト推定(例:賃貸なら市場平均家賃)
- 意味: 住居コストは固定支出の大部分を占める
- 債務対所得比(DTI)の計算
SageMaker Clarify
Clarifyは、機械学習モデルの説明可能性・バイアス検出のためのツールです。
特に「どの特徴量がモデルの予測に重要か」を分析するのに役立ちます
- 使い方
- 設定:どの特徴量の重要度を知りたいか設定します
- 実行:モデルを分析して特徴量の重要度を計算します
- 結果:各特徴量がモデル予測にどれだけ影響しているかがわかります
- 結果の例
特徴量の重要度:
債務対所得比 (DTI): ■■■■■■■■■■■■■■■■ (32%)
支払い履歴の安定性: ■■■■■■■■■■■■■■ (28%)
過去の破産からの経過月数: ■■■■■■■ (15%)
最近の信用照会数: ■■■■■■ (12%)
雇用安定性スコア: ■■■■ (8%)
住居コスト推定: ■■ (5%)
上記のデータを以下のように活用することができます。
- 重要な特徴に集中:重要度の高い特徴(例:DTI)を更に改良する
例:DTIに加えて「自由に使える収入割合」という新しい特徴を作る - 新しい派生特徴の作成:重要な特徴を組み合わせる
例:「支払い履歴の安定性」と「DTI」を組み合わせた新しいリスクスコア - 効果の少ない特徴の見直し:重要度の低い特徴を削除または改良
例:単純な「住居形態」ではなく「住居費用の収入比」に変更 - 非線形変換:関係性をより明確にする数学的変換
例:重要な特徴の対数変換や二乗変換
プルーニング
モデルを小さくしつつ、性能をなるべく落としたくないという時に使う手法です。
トレーニングにほとんど貢献しない冗長パラメータを特定・削除します。
機械学習モデルの予測において役立っていない部分を削るイメージです。
- 具体例:猫の写真を認識するモデル
- プルーニング前
- 100個のフィルターが存在(目、耳、ヒゲなどの特徴を探すもの)
- そのうち30個のフィルターは殆ど使われていないことが明らかになった
- プルーニング後
- 重要な70個のフィルターのみを残す
- モデルが約30%軽量化され、モバイルデバイスなどでも利用しやすくなる
量子化
機械学習モデルでは重みという数値を使いますが、これらの数値を高精度(32ビット)から低精度(8ビット)に変換します。
人間で例えると、「体重が63.45678kg」と細かく表現するのではなく、「体重が63kg」と大まかに表現するようなもの。
- 具体例:物体検出モデル
- 量子化前
- モデルサイズ:100MB
- 1枚の写真の処理時間:0.5秒
- 量子化後
- モデルサイズ:25MB
- 1枚の写真の処理時間:0.2秒
プルーニングと量子化を合わせることで、精度をほとんど損なうことなく、サイズや処理時間を大幅に縮小することができます。
ハイパーバンド
ハイパーバンドは「early stopping(早期打ち切り)」のアイデアを取り入れたハイパーパラメータ最適化アルゴリズムです。
ディープラーニングにおいて、有望でないモデル設定を早期に識別して計算リソースを節約し、有望な設定により多くのリソースを割り当てます。
動作原理としては、以下のとおりです。
- 多数の候補を生成:様々なハイパーパラメータ設定をランダムに生成
- 少ないリソースでの評価:最初は全ての候補を少ないエポック数で訓練
- 絞り込み:パフォーマンスの低い候補を除外
- リソース増加と反復:残った候補により多くのエポックを割り当て
- 最終選択:最終的に最も良い結果を示した設定を選択
対数変換
対数変換とは、データの数値を「対数」という特別な計算を使って変換する方法です。
「大きすぎる数値」を「小さな数値」に変換します。
例えば、10→1、100→2、1000→3 のように変換します(10を底とした場合)。
- 対数変換の目的
- 大きな数値と小さな数値を一緒に扱いやすくする
- 例:貯金額データ
- ほとんどの人が1万円~10万円
- 一部の人が100万円~1000万円
- この状態だと、グラフを作っても小さい値が見えなくなる
- 対数変換すると全体を見やすくできる
- 例:貯金額データ
- 偏った分布を整える
- 収入や家の価格などのデータは、少数の高い値と多数の低い値があることが多い
- 対数変換すると、このような偏りが整って分析しやすくなる
- 大きな数値と小さな数値を一緒に扱いやすくする
モデルの評価
混同行列
混同行列は予測結果を4つのカテゴリに分類した表です:
| 予測:購入する | 予測:購入しない | |
|---|---|---|
| 実際:購入した | 真陽性(TP) | 偽陰性(FN) |
| 実際:購入しなかった | 偽陽性(FP) | 真陰性(TN) |
- 具体例:オンラインショップの購入予測
- あるファッションEコマースサイトにおける10,000人の訪問者データ
- 実際に購入した人:500人(5%)
- 購入しなかった人:9,500人(95%)
モデルの予測結果が以下の混同行列だったとします
| 予測:購入する | 予測:購入しない | |
|---|---|---|
| 実際:購入した | 300人(TP) | 200人(FN) |
| 実際:購入しなかった | 700人(FP) | 8,800人(TN) |
この混同行列から、モデルが以下のように予測していることがわかります。
- 実際に購入した500人のうち300人を正しく予測(残り200人は見逃し)
- 購入しなかった9,500人のうち700人を誤って「購入する」と予測
混同行列の利点
- 詳細な誤り分析:どのタイプの誤りが多いかを明確に把握できる
- ビジネスコストの評価:例えば、「購入する顧客を見逃す」コストと「購入しない顧客にマーケティングする」コストの比較
- 派生指標の計算基礎:精度、再現率、F1スコアなどを計算できる
精度と再現率
混同行列から計算される2つの重要な指標です。
特に、不均衡なデータセットにおいてこの2つの指標が非常に重要です。
-
精度(Precision):「購入すると予測した顧客のうち、実際に購入した割合」
- 計算式:TP ÷ (TP + FP)
- 偽陽性(購入しないのに購入すると予測)を減らすのに重要
-
再現率(Recall):「実際に購入した顧客のうち、正しく予測できた割合」
- 計算式:TP ÷ (TP + FN)
- 偽陰性(購入するのに購入しないと予測)を減らすのに重要
上記の例で計算してみます。
- 精度 = 300 ÷ (300 + 700) = 300 ÷ 1,000 = 0.30 = 30%
- 精度30%:購入すると予測した1,000人のうち、実際に購入したのは300人(30%)
- 再現率 = 300 ÷ (300 + 200) = 300 ÷ 500 = 0.60 = 60%
- 再現率60%:実際に購入した500人のうち、モデルが正しく予測できたのは300人(60%)
Eコマースにおける精度と再現率のバランス
ビジネス目標によって重視すべき指標が変わります。
-
限定的なマーケティング予算がある場合
- 精度重視:購入する可能性が高い顧客だけにリソースを集中
- 例:高額クーポンを送る顧客を厳選したい場合
-
潜在的な購入者を見逃したくない場合
- 再現率重視:購入する可能性のある顧客をできるだけ多く捕捉
- 例:新商品の認知度を高めたいキャンペーン
-
バランスを取りたい場合
- F1スコア(精度と再現率の調和平均)を使用
- 計算式:2 × (精度 × 再現率) ÷ (精度 + 再現率)
なぜこれらの評価手法が最適なのか
- 不均衡データに強い
購入率が5%程度というのはEコマースでは一般的ですがこの場合に、「全員が購入しない」と予測するだけで95%の精度が出てしまうようなモデルでは意味がありません。
精度と再現率は少数クラス(購入する顧客)の予測性能を正確に評価できます。 - ビジネス意思決定に直結
例えば以下のようなことが見えてきます。- 精度が低い:マーケティングコストの無駄が多い
- 再現率が低い:見込み顧客の取りこぼしが多い
- モデル改善の方向性を示す
混同行列を分析することで、モデル改善の方向性がわかります。- 偽陽性が多い → 予測の閾値を上げる、特徴量を追加する
- 偽陰性が多い → 少数クラスの重み付けを強くする、より多くのデータを集める
PR曲線(Precision-Recall曲線)
PR曲線は、異なる分類閾値における「適合率(Precision)」と「再現率(Recall)」のトレードオフを示すグラフです。
- 適合率(Precision):True予測のうち、実際にTrueだった割合
- Precision = TP / (TP + FP)
- 値が高いほど、Trueと判定した場合の信頼性が高い
- 再現率(Recall):実際にTrueだった件数のうち、正しく検出できた割合(=真陽性率)
- Recall = TP / (TP + FN)
- 値が高いほど、実際のTrueをより多く捕捉できる
PR曲線の具体例として、不正検知モデルの閾値を変えながらPRを計算してみます。
| 閾値 | Precision | Recall |
|---|---|---|
| 0.9 | 0.98 | 0.35 |
| 0.8 | 0.95 | 0.42 |
| 0.7 | 0.92 | 0.51 |
| 0.6 | 0.88 | 0.63 |
| 0.5 | 0.82 | 0.75 |
| 0.4 | 0.75 | 0.85 |
| 0.3 | 0.65 | 0.91 |
| 0.2 | 0.48 | 0.95 |
| 0.1 | 0.30 | 0.99 |
これをグラフにするとPR曲線を得られます。
通常、閾値を下げると以下のようになります。
・Recallは増加(より多くの不正を検出)
・Precisionは減少(誤検知も増加)
PR曲線下面積(Area Under the Precision-Recall Curve)
PR曲線下面積は、モデルの全体的な性能を単一の数値で表します。
AUPRC値が高いほど、モデルは様々な閾値設定で優れた性能を発揮します。
不均衡データにおいて過度に楽観的な評価を下すことがあるROC曲線に対し、PR曲線は少数クラスの検出性能に焦点を当てている。
残差・残差プロット
残差とは、実際の観測値 と モデルによる予測値 の差です。
残差 = 実際の値 - 予測値
残差プロットは、X軸に予測値(または説明変数)、Y軸に残差をプロットしたグラフです。
このグラフを分析することで、モデルが過大評価または過小評価する傾向があるかどうかを視覚的に判断できます。
理想的な残差プロットでは、残差がゼロを中心にランダム分布し、明確なパターンが見られません。
これはモデルが偏りなく予測していることを示します。
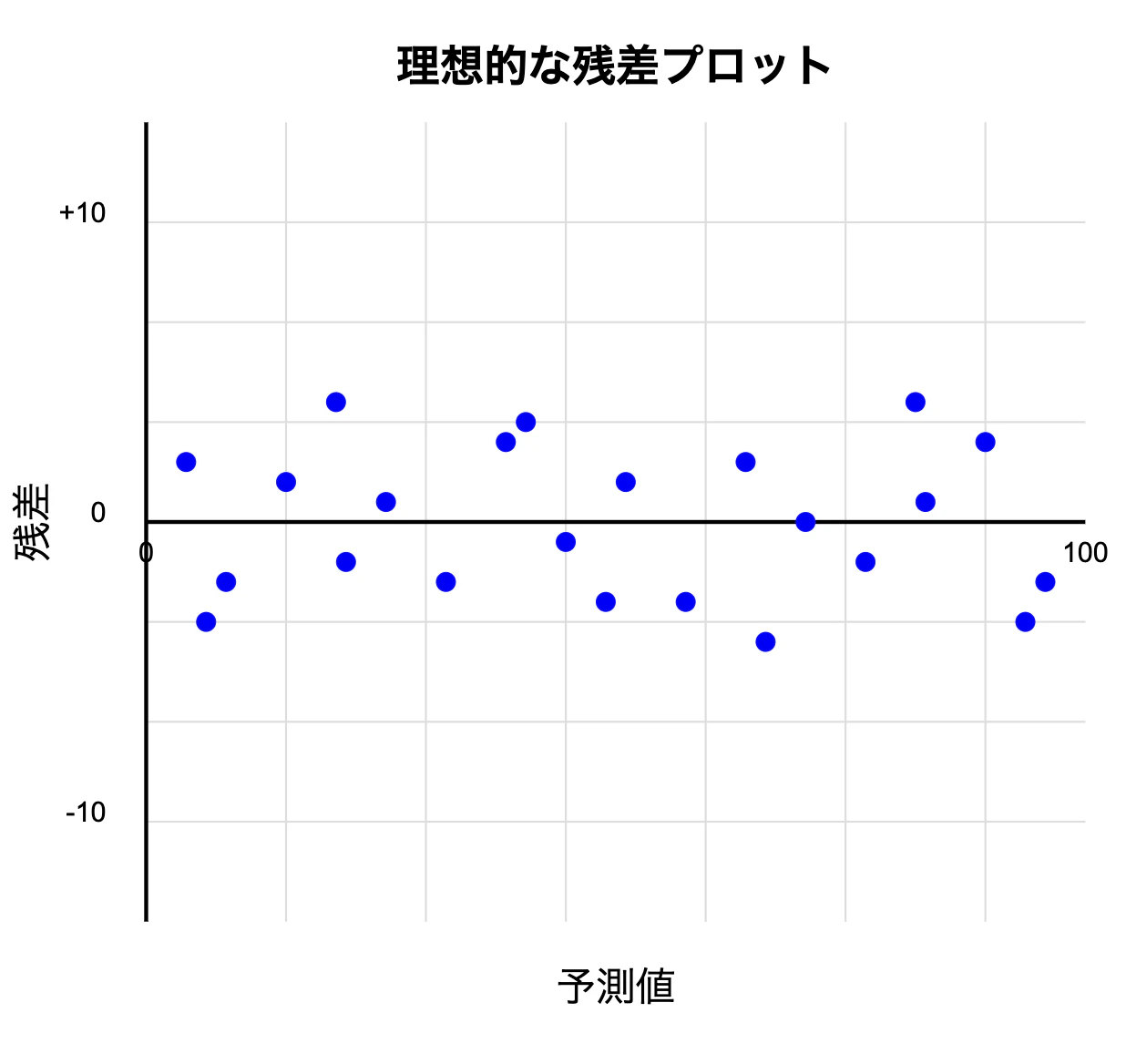
過大評価・過小評価の見分け方としては、以下のようになります。
-
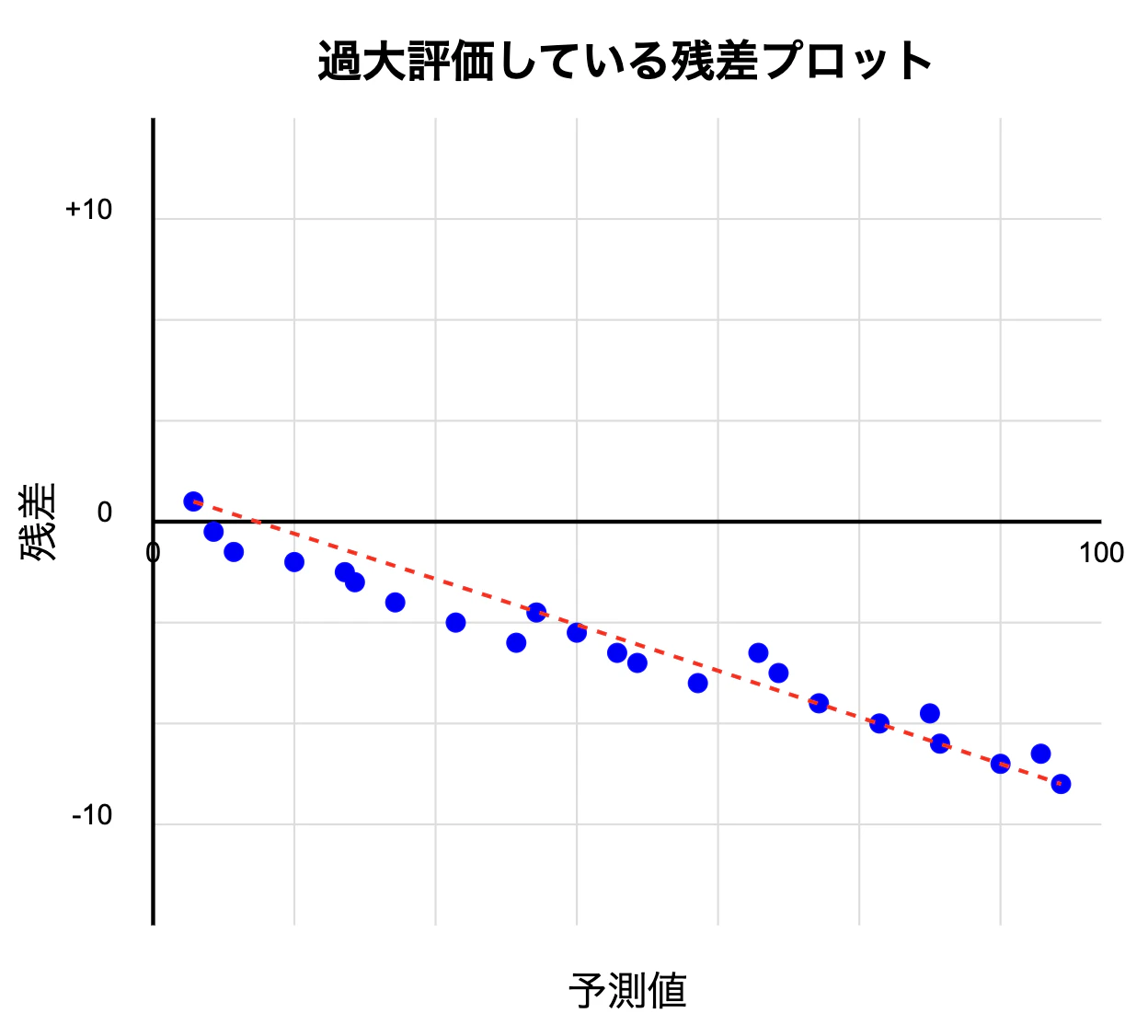
系統的な過大評価: 残差プロットで多くの点が負の値にある場合、モデルは実際の値より大きい値を予測しています(過大評価)
→住宅価格予測モデルを例にすると、高額物件ほど過大評価(高く予測する)してしまう
-
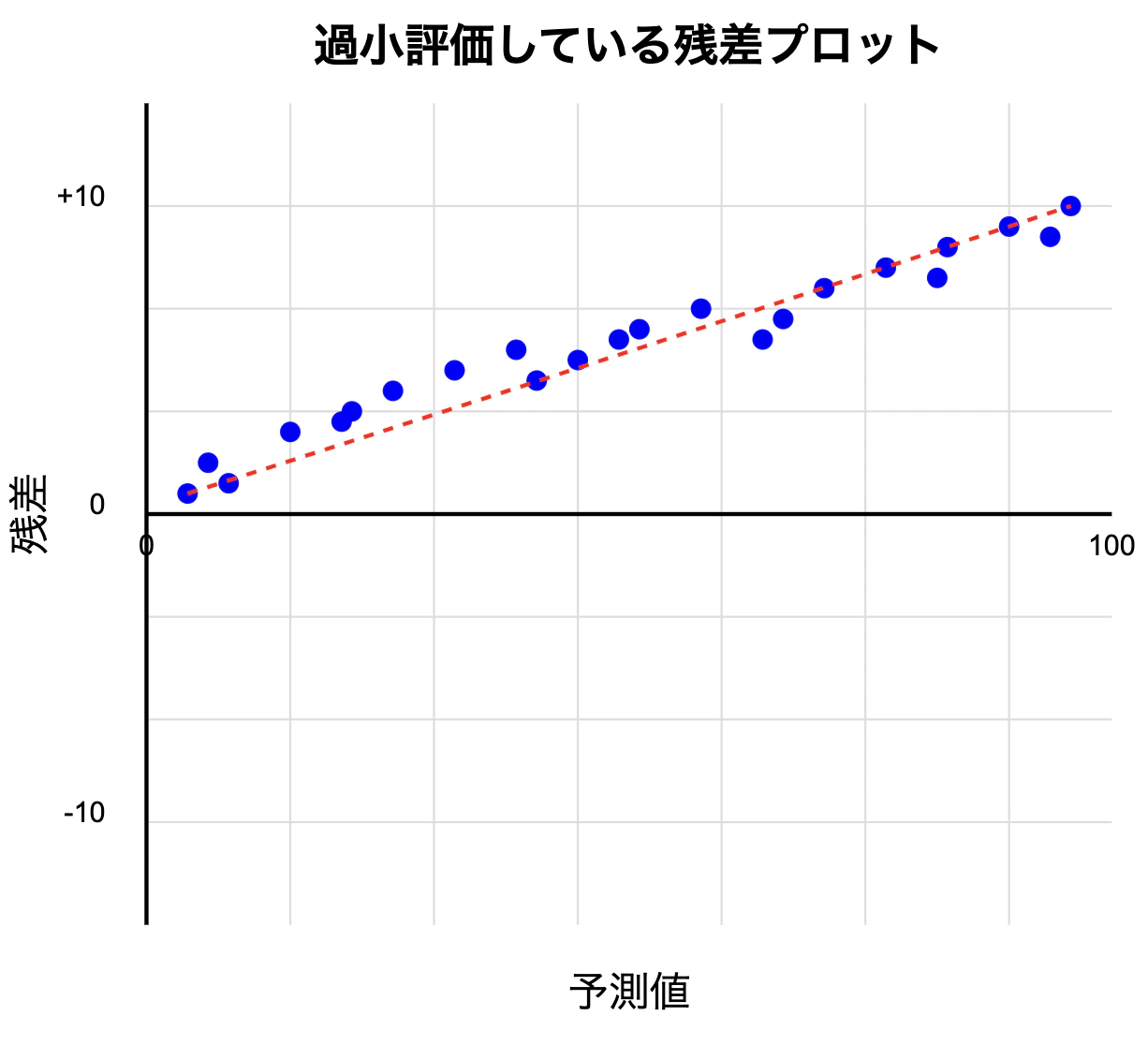
系統的な過小評価: 残差プロットで多くの点が正の値にある場合、モデルは実際の値より小さい値を予測しています(過小評価)
→住宅価格予測モデルを例にすると、高額物件ほど過小評価(安く予測する)してしまう
-
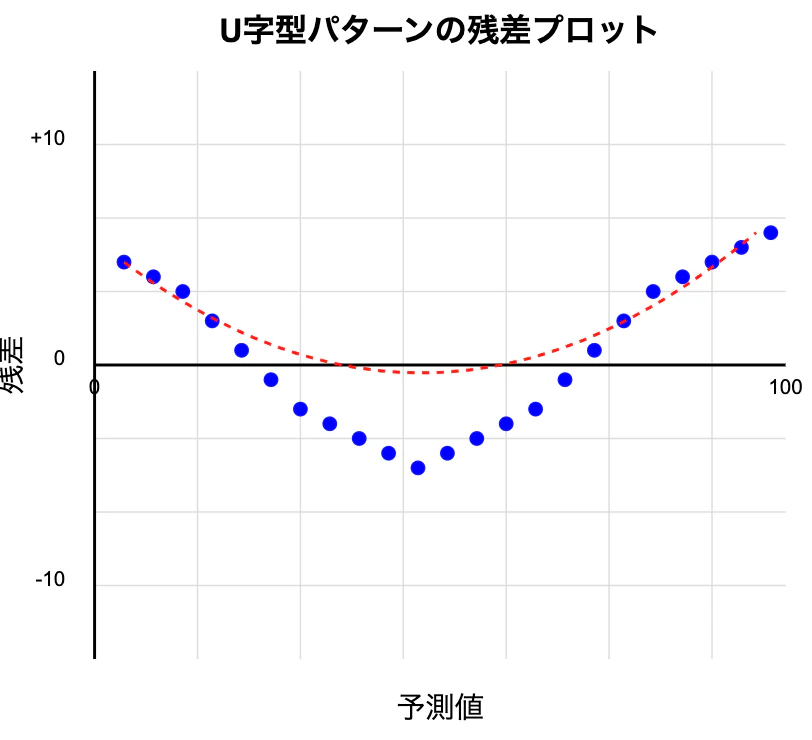
パターンの存在: 残差に明確なパターン(例:U字型)がある場合、モデルは特定の範囲で過大評価または過小評価しています
→住宅価格予測モデルを例にすると、中間価格帯の物件で残差が負の値に偏っている
→このモデルは中間価格帯の物件を課題評価する傾向がある()
平均平方根誤差(RMSE)
平均平方根誤差は、予測モデルの精度を評価するための指標の一つです。
簡単に言うと、「予測値と実際の値の差(誤差)を二乗して平均を取り、その平方根を計算したもの」です。
数式で表すと以下の感じです(Σは合計、nはデータ点の数)
RMSE = √[(Σ(予測値 - 実際の値)²) / n]
- 特徴
- 単位が元のデータと同じ
- 二乗した後に平方根を取るので、元のデータと同じ単位で誤差を表現できます
- 大きな誤差に敏感
- 誤差を二乗するため、大きな誤差がある場合にはそれが強調されます
- 1単位の誤差10個よりも、10単位の誤差1個の方がRMSEは大きくなります
- 常に正の値: 平方根を取るため、常に正の値になります
- 単位が元のデータと同じ
使用例として、住宅価格予測モデルの評価を考えてみます。
| 実際の価格 | 予測価格 | 誤差 | 誤差の2乗 | 平均 | 平方根 |
|---|---|---|---|---|---|
| 200万 | 210万 | 10万 | 100 | (100+400+400)/3 =300 |
√300=17.3 |
| 250万 | 230万 | -20万 | 400 | 同上 | 同上 |
| 300万 | 320万 | 20万 | 400 | 同上 | 同上 |
以上より、このモデルのRMSEは約17.3万円となります。
RMSEはモデルのパフォーマンスを評価する際によく用いられ、特に回帰問題や時系列予測において重要な指標です。
RMSEが小さいほど、モデルの予測精度が高いことを示しています。
MLOps
データドリフト(特徴量ドリフト)
入力データの分布自体が変化する現象。入力データそのものの特徴が変わること。
- 例:アイスクリームの売上予測
- 学習時:気温データが20~30度の範囲だった
- 運用時:異常気象で35~40度のデータが多くなった
- データ自体の範囲や分布が変化していることがわかる
- モデルが見たことのない範囲のデータが増える
- ただし、モデルが学んだルールは正しいまま
データドリフトの検出と対策
- 検出方法
- 入力特徴の統計的分布を監視(平均、分散、分位数など)
- KL発散やJSダイバージェンスなどの分布比較メトリクス
- 対策
- 特徴の正規化、ロバストな特徴エンジニアリング
コンセプトドリフト
データと結果の関係性自体が変わること。
- 例:オンラインショッピングの不正検知
- 学習時: 「短時間に多数の購入」は不正行為の兆候だった
- 運用時: コロナ禍で自宅時間が増え、短時間に多数の正当な購入をする人が増えた
- 「短期間に多数の購入」というパターン(入力データ)に対して、以前は不正を意味していたが、今は正常を意味するようになった
- データの特徴は同じだが、その意味が変わったため、予測結果も変わるべき状態
- モデルが学んだルールが時代遅れになる
コンセプトドリフトの検出と対策
- 検出方法
- モデルの予測パフォーマンス(精度、再現率など)を継続的に監視
- 予測と実際の結果の乖離を分析
- 対策
- モデルの定期的な再トレーニング、オンライン学習の導入
ROC曲線(Receiver Operating Characteristic curve)
ROC曲線とは、分類モデルの性能を様々な閾値で評価するグラフのこと。
例:ローン滞納者予測のROC曲線
X軸:偽陽性率(FPR)- 実際は返済するのに「滞納する」と誤って予測した割合
Y軸:真陽性率(TPR)- 実際に滞納する人を正しく「滞納する」と予測した割合
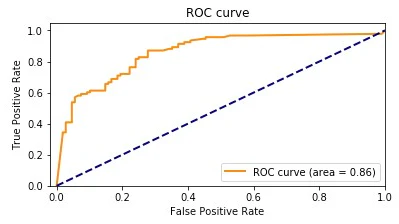
- 各顧客に対して滞納確率を0~1の間で出力する
- 山田さん:滞納確率 0.85
- 鈴木さん:滞納確率 0.30
- 佐藤さん:滞納確率 0.60
- ここでの問題:どの確率以上なら滞納すると判断するか、という閾値の設定
- 閾値 0.7の場合:山田さんのみ「滞納する」と予測
- 閾値 0.5の場合:山田さんと佐藤さんを「滞納する」と予測
- 閾値 0.2の場合:全員を「滞納する」と予測
- ROC曲線は、この閾値を様々に変えたときの「真陽性率」と「偽陽性率」のトレードオフを描いたグラフ
AUC(Area Under the Curve)
AUCは、ROC曲線の下の面積を表す
- AUC = 1.0:完璧なモデル(滞納者と非滞納者を100%正確に区別できる)
- AUC = 0.5:ランダム予測と同等(コイントスで予測しているのと変わらない)
- AUC = 0.0:完全に逆の予測(基本的にあり得ないが、予測を逆にすれば完璧なモデルになる)
ACUの解釈:なぜ1.0に近いと優れた識別力があるといえるのか
ACUの値は、ランダムに選んだ滞納者がランダムに選んだ額納車よりも高いスコアを得る確率、と解釈できます。
例えば、銀行に10人の顧客がいて以下のような状況だったとします。
| 顧客 | モデルの予測確率 | 実際の状況 |
|---|---|---|
| A | 0.95 | 滞納する |
| B | 0.15 | 滞納しない |
| C | 0.25 | 滞納しない |
| D | 0.85 | 滞納する |
| E | 0.30 | 滞納しない |
| F | 0.10 | 滞納しない |
| G | 0.20 | 滞納しない |
| H | 0.45 | 滞納しない |
| I | 0.05 | 滞納しない |
| J | 0.75 | 滞納する |
実際に滞納した顧客(A, D, J)の予測確率は0.95, 0.85, 0.75です。
実際に滞納しなかった顧客(B, C, E, F, G, H, I)の予測確率は0.45, 0.30, 0.25, 0.20, 0.15, 0.10, 0.05です。
このモデルのAUCを計算するために、すべての滞納者と非滞納者のペア(3×7=21ペア)を考え、滞納者のスコアが非滞納者より大きい割合を求めます。
- 滞納者A(0.95) > すべての非滞納者(7人)
- 滞納者D(0.85) > すべての非滞納者(7人)
- 滞納者J(0.75) > すべての非滞納者(7人)
つまり、21ペアすべてで滞納者のスコアが非滞納者より高くなっています(21/21 = 1.0)。
このモデルのAUCは1.0で、完璧な識別能力を持っていることを示しています。
より現実的な例としては、以下のような状況が考えられます。
| 顧客 | モデルの予測確率 | 実際の状況 | 補足 |
|---|---|---|---|
| A | 0.65 | 滞納する | |
| B | 0.15 | 滞納しない | |
| C | 0.55 | 滞納しない | ←高スコアの非滞納者 |
| D | 0.85 | 滞納する | |
| E | 0.30 | 滞納しない | |
| F | 0.10 | 滞納しない | |
| G | 0.20 | 滞納しない | |
| H | 0.45 | 滞納しない | |
| I | 0.05 | 滞納しない | |
| J | 0.40 | 滞納する | ←低スコアの滞納者 |
この場合、顧客Cは滞納しないのに高いスコア、顧客Jは滞納するのに低いスコアを得ています。
21ペアのうち18ペアで滞納者のスコアが非滞納者より高く、3ペアではそうではありません(AUC = 18/21 ≈ 0.86)。
これは良い識別能力を持つモデルと言えますが、完璧ではありません。
AUCの評価基準
0.9〜1.0:非常に優れたモデル
0.8〜0.9:良いモデル
0.7〜0.8:普通のモデル
0.6〜0.7:あまり良くないモデル
0.5〜0.6:ほとんど役に立たないモデル
ROC-AUCのメリット
- 不均衡データに強い:滞納者が少なくても公平に評価できる
- 閾値に依存しない:様々な意思決定閾値での性能を包括的に評価
- 直感的な解釈:「モデルの識別能力」を直接表す
- コスト考慮可能:後で最適な閾値を業務コスト(滞納見逃しのコストvs融資機会損失)に基づいて選べる
条件付き人口統計的格差 (CDD: Conditional Demographic Disparity)
CDDは、特定の条件(例:収入レベル)を考慮した上で、異なる人口統計グループ(例:年齢層、性別、人種など)間での予測結果の差を測定します。
- 単純な統計的格差: グループAとグループBで異なる予測結果が出ているか
- 条件付き統計的格差: 同じような条件(収入など)を持つ人たちの中で、グループAとグループBで異なる予測結果が出ているか
例として、保険金不正請求の可能性を予測するモデルについて考えてみます。
- 前提条件:データには以下の情報が含まれる
- 人口統計情報: 年齢、性別、地域など
- 請求情報: 請求額、損害の種類、請求頻度など
- 保険契約者情報: 保険加入期間、過去の請求歴など
- 社会経済的要因: 収入レベル、職業など
- 単純な分析:年齢別に不正請求の予測結果を集計
- 若年層(18-30歳): 8.5%
- 中年層(31-50歳): 4.2%
- 高齢層(51歳以上): 3.1%
- 一見すると若年層は不正請求をする可能性が高いと予測されている
- CDD:収入レベルを条件として分析
- 低収入層の中での不正請求の予測率
- 若年層(18-30歳): 8.2%
- 中年層(31-50歳): 7.9%
- 高齢層(51歳以上): 7.8%
- 中収入層の中での不正請求の予測率
- 若年層(18-30歳): 4.3%
- 中年層(31-50歳): 4.1%
- 高齢層(51歳以上): 4.0%
- 高収入層の中での不正請求の予測率
- 年層(18-30歳): 3.0%
- 中年層(31-50歳): 2.9%
- 高齢層(51歳以上): 2.8%
- 同じ収入レベルにおいては、年齢層による予測率の差がほとんどない
- 若年層の予測率が高いのは、若年層に低収入者が多いためであり、年齢自体がバイアス要因ではないことがわかる
- 低収入層の中での不正請求の予測率
- CDDの計算結果
- CDD値が0に近い
- 条件を考慮したうえで、人口統計グループ間の予測差がほとんどない(望ましい状態)
- CDD値が大きい(正または負)
- 条件を考慮しても、人口統計グループ間の予測差が残る(潜在的なバイアスがある可能性)
- CDD値が0に近い
Shapley値
Shapley値は、個々の特徴(変数)がある特定のケースの予測結果にどれだけ貢献したかを数値化する手法です。
特徴としては以下のとおりです。
- ローカルな説明: 個別の予測結果について説明する
- 個人レベルの分析: 予測結果に対する疑問へ答える
- 例:なぜこの顧客Aはローン拒否という予測結果になったのか?
- 特徴の貢献度: 各特徴がどれだけ予測結果を押し上げたか、または押し下げたかを定量化する
具体例としてローンの不履行を予測する機械学習モデルについて考えてみます。
Aさんがローン申請をし、モデルが「デフォルト確率75%」と予測したとします。このときのShapley値を計算すると、
ベースライン(平均的な申請者のデフォルト確率): 20%
収入: -5%(リスクを5%下げる要因)
返済履歴: +30%(リスクを30%上げる要因)
雇用期間: -3%(リスクを3%下げる要因)
負債比率: +18%(リスクを18%上げる要因)
信用照会回数: +15%(リスクを15%上げる要因)
合計:20% + (-5%) + 30% + (-3%) + 18% + 15% = 75%
という形になりました。
この結果から、Aさんのケースでは「返済履歴」と「負債比率」が特に高リスク判定の主な要因であることがわかります。
以上より、Shapley値とは個別の顧客に対する判断を説明し、規制要件(説明する権利など)を満たすのに役立ちます。
部分依存プロット(PDP)とは?
部分依存プロットは、特定の特徴(変数)の値が変化したとき、モデルの予測結果がどのように変化するかを示すグラフです。
特徴としては以下のとおりです。
- グローバルな説明: モデル全体の傾向について説明する
- データセットレベルの分析: 「一般的に収入はどのようにリスク評価に影響するのか?」という疑問に答える
- 限界効果: 特徴の値の変化がモデル予測に与える影響を視覚化する
具体例として、PDPを用いて年収とデフォルト確率の関係を分析すると、以下のような傾向がわかりました。
年収300万円: デフォルト確率 35%
年収500万円: デフォルト確率 25%
年収700万円: デフォルト確率 18%
年収900万円: デフォルト確率 15%
年収1100万円以上: デフォルト確率 12%で横ばい
このPDPからは、年収が増えるにつれてデフォルト確率が下がるが、約1100万円を超えると効果が薄れることがわかります。
以上より、PDPはモデル全体の挙動を理解し、ビジネス戦略の策定やモデル改善に役立ちます。
Shapley値とPDPの違いと組み合わせ
| 特性 | Shapley値 | 部分依存プロット(PDP) |
|---|---|---|
| 分析レベル | ローカル(個別ケース) | グローバル(モデル全体) |
| 回答する質問 | なぜこの顧客がこの結果になったのか? | この特徴は全体的にどう影響するのか? |
| 使用状況 | 個々の決定の説明・正当化 | モデルの全体的な挙動の理解 |
| 出力形式 | 各特徴の貢献度数値 | 特徴値と予測結果の関係を示すグラフ |
| 計算コスト | 通常は高い | 比較的低い |
ただしこの2つは相反するものではなく、相補的なツールです。
したがって最も効果的なアプローチは、Shapley値とPDPを組み合わせて使うことです。
- PDP(グローバル分析)でモデル全体の傾向を把握
- どの特徴が一般的に重要か
- 特徴値の変化がどのように予測に影響するか
- Shapley値(ローカル分析)で個別ケースを説明
- なぜこの特定の顧客が高/低リスクと判断されたのか
- どの特徴がこの判断に最も寄与しているか