2024年12月3日、Amazon Aurora DSQL(プレビュー版)が発表されました!
DSQLとは、Distributed SQLという意味であり、日本語にすると「分散SQL」という意味になります。
要するに、アクティブ/アクティブの高可用性を備えた新しいサーバーレス分散SQLデータベースです。
ちなみにですが、読み方は「ディー・エスキューエル」ではなく、「ディー・シークウェル」だそうです。
前置き
以前にDSQLの立ち上げ方についてはご説明したので、今回はDSQLに接続し、操作していく内容となっています!
※以降、DSQLのマルチリージョンリンククラスターが作成されているという前提で話を進めます。
クラスター作成方法についてはこちら↓
CloudShellでAurora DSQLクラスター(バージニア北部リージョン)に接続する
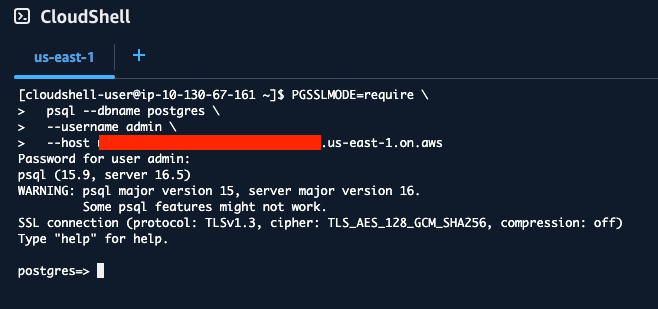
まず、接続するクラスターを選択し、「connect」を選択します。
そして、クラスターのエンドポイントをコピーします。

続いて、バージニア北部リージョンでCloudShellを立ち上げ、以下のコマンドを実行します。
PGSSLMODE=require \
psql --dbname postgres \
--username admin \
--host <先ほどコピーしたエンドポイントをここに貼り付け>
すると、管理者権限でログインするためのパスワードが求められます。

先ほどの「connect」の画面に戻りましょう。
認証トークン(Authentication Token)が「Connect as admin」なのを確認し、コピーします。
これがパスワードの代わりになります。

CloudShellの画面に戻り、パスワードを貼り付けてエンターキーを押します。
※パスワードは貼り付けても画面上には表示されません。
すると、以下のような表示になり、DSQLへのログインが成功しました!
アクセス拒否エラーが出た場合は、恐らくIAMに dsql:DbConnectAdmin 権限が不足しています。
SQLコマンドを実行しデータを格納する
続いて、実際にコマンドを入力してみます。
1.exampleという名前のスキーマを作成します。
CREATE SCHEMA example;
PostgreSQLにおける「スキーマ」とは、1つのデータベースの中に複数設定可能な名前空間のことを指すそうです。
2.自動的に生成されたUUIDを主キーとして利用する請求書テーブルを作成します。
CREATE TABLE example.invoice(id UUID PRIMARY KEY DEFAULT gen_random_uuid(), created timestamp, purchaser int, amount float);
3.空のテーブルを使用するせカンダリインデックスを作成します。
CREATE INDEX invoice_created_idx on example.invoice(created);
4.部門テーブルを作成します。
CREATE TABLE example.department(id INT PRIMARY KEY UNIQUE, name text, email text);
ここまでの実行結果はこんな感じ。

5.下記のGitHubリポジトリから、`department-insert-multirow.sql` と `invoice.csv` ファイルをダウンロードしておきます。
6.「アクション」から、「ファイルのアップロード」を選択し、先ほどダウンロードした2つのファイルをCloudShell上にアップロードします。

↓


7.アップロードしたスクリプトを実行します。
\include /home/cloudshell-user/department-insert-multirow.sql
(実行環境次第では、パスが異なります。)
\includeコマンドは、ファイルに含まれるSQLスクリプトを読み込んで実行するコマンドです。
引数には /path/path/script.sql のような形で、パスとスクリプト名を指定します。
8.アップロードしたファイルを元に、サンプルデータをデータベースに挿入します。
\copy example.invoice(created, purchaser, amount) from /home/cloudshell-user/invoice.csv csv
(実行環境次第では、パスが異なります。)
\copyコマンドは、データをインポート/エクスポートするために使用するコマンドです。
構文としては、
\copy table_name [ ( column_list ) ] {FROM | TO} source [ WITH ( option [, ...] ) ]
という感じになります。
インポートする場合は FROM, エクスポートする場合は TOを用います。
2つのコマンド実行結果は以下の感じです。
これでdepartmentテーブルと、invoiceテーブルが作成されました。

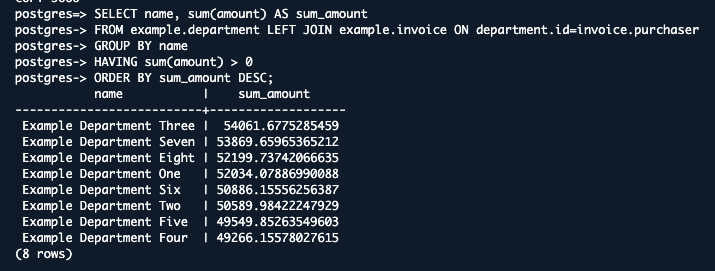
9.最後に、部門を売上高順に並べ替えて表示させます。
SELECT name, sum(amount) AS sum_amount
FROM useast1.department
LEFT JOIN useast1.invoice ON department.id=invoice.purchaser
GROUP BY name
HAVING sum(amount) > 0
ORDER BY sum_amount DESC;
こんな感じのが表示されるはずです!
というところで、ドキュメントに記載されていたサンプルの手順は終わりです。
当たり前ですが、普通にSQLコマンド使えましたね!
オハイオリージョンでデータを確認する
バージニア北部リージョンで格納したデータが反映されているかを確認してみましょう。
先ほど同様に、オハイオリージョンでCloudShellを開き、Aurora DSQLに接続します。
この時、オハイオリージョンのエンドポイントに接続しましょう。

↓

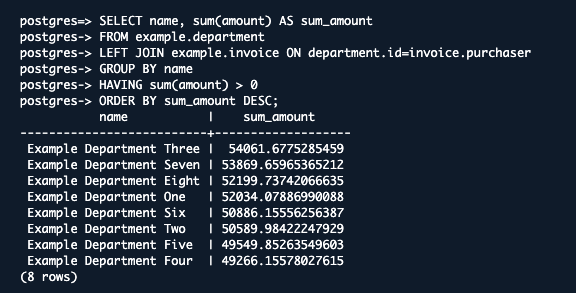
そして、以下のコマンドを実行します。先ほどの9.と同じコマンドです。
SELECT name, sum(amount) AS sum_amount
FROM example.department
LEFT JOIN example.invoice ON department.id=invoice.purchaser
GROUP BY name
HAVING sum(amount) > 0
ORDER BY sum_amount DESC;
同じ出力が返ってきました!
バージニア北部リージョンで書き込んだデータがオハイオリージョンでも反映されているのがわかりますね!
ついでに、他の情報も色々確認してみましょう。
1.データベースの一覧を表示:
\l

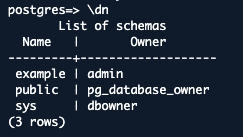
2.全てのスキーマを表示:
\dn
3.exampleスキーマ内のテーブルの一覧を表示:
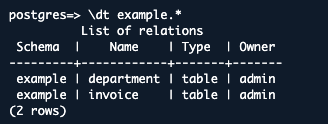
\dt example.*
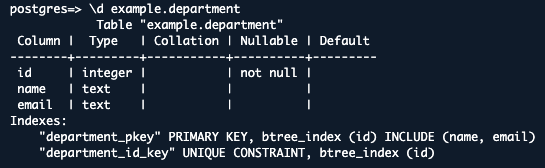
4.作成した2つのテーブルの構造(カラム情報)を表示:
\d example.department
\d example.invoice

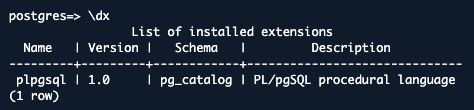
5.インストールされている拡張機能を表示:
\dx
6.ユーザー(ロール)の一覧を表示:
\du

7.現在の接続情報を確認する
\conninfo

ということで、オハイオリージョンのデータも確認できました!
大体何秒くらいでデータが反映されるのか?
ここで1つ気になるのは、データ書き込みがどのくらいの速度で反映されているのか。
実際の挙動で確認してみます!
実験方法としては、
- バージニア北部リージョンで新しいスキーマ「us-east-1」を作成する
- オハイオリージョンでスキーマを確認しまくる
というパワースタイルでいきます。
上記の動画を見て貰えば分かる通り、1秒以内に書き込まれていました!
まとめ
Aurora DSQLのデータ一貫性の一端に触れることができました!
次はLambdaなどからアクセスしてみます!