この記事について
この記事はdatatech-jp Advent Calendar 2024の12月7日分として記載しています
はじめに
私たちは、マーケティング施策や新規機能開発など、業務の中で多くの施策を実行しています。
施策を打つには多くのリソースを使うため、筋の良い施策だけを実行したいですよね。
事前に施策効果を見積もることで、施策ごとやユーザー群ごとの効果を比較可能にし、インパクトの大きいものを選び出すことができます。
例えば、ある会社には、同じユーザーを対象とする異なる3つのプロダクトA,B,Cの3つがあるとします。
Cの利用を促すクロスセルのマーケティング施策を打つために、AのユーザーとBのユーザーどちらを狙うべきか考えます。
以下のデータがある場合、AのユーザーとBのユーザーどちらに施策を打つべきだと思いますか?
| 検討プロダクト | C未利用ユーザー数 |
|---|---|
| A | 1万人 |
| B | 5,000人 |
Aのユーザーにクロスセルの施策を打った方が、より多くのユーザーを獲得できるかもしれません。
では、売上を考慮するとどうなるでしょうか?
| 検討プロダクト | C未利用ユーザー数 | C利用ユーザーの平均売上 | 市場開拓余地 |
|---|---|---|---|
| A | 1万人 | 1,000円 | 1000万円(1万人×1,000円) |
| B | 5,000人 | 5,000円 | 2500万円(5,000人×5,000円) |
Bのユーザーに施策を打った方が、人数規模は小さいが売上につながりそうだという見立てを得ることができます。
もちろん、実際はAとBを両方使うユーザーを考慮する必要がありますし、施策の実行しやすさなど他の要因を考える必要もあります。とはいえ、定量的な分析でわかることは事前に調べておいた方が、不確実性を下げ、施策の打率を高めることができます。
そこで、このような集計を行うためのデータ分析のパターンを紹介します。
やり方
以下の3ステップです。
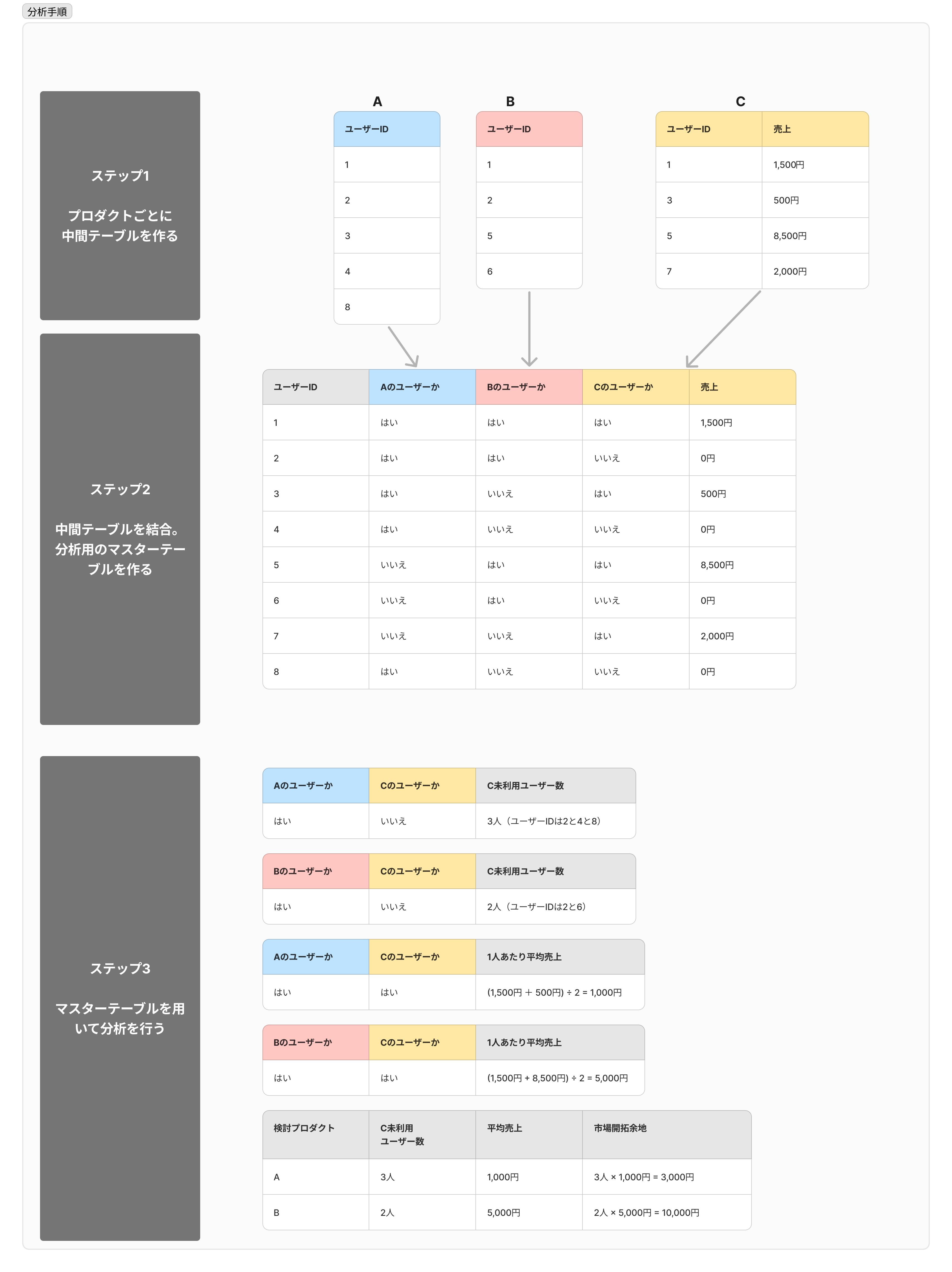
ステップ1:プロダクトごとに、ユーザーIDの粒度で中間テーブルを作る
ステップ2:ユーザーIDをキーにして、プロダクトごとの中間テーブルを結合。分析用のマスターテーブルを作る
ステップ3:マスターテーブルを用いて分析。ユーザー群ごとに「ユーザー数」「平均売上」といった指標を計算し、比較する
順番に解説します。
ステップ1:プロダクトごとに中間テーブルを作る
まずは、プロダクトごとにユーザーIDの粒度で中間テーブルを作ります。
市場開拓余地を計算するため、C についてはユーザーごとの売上も計算しておきます。
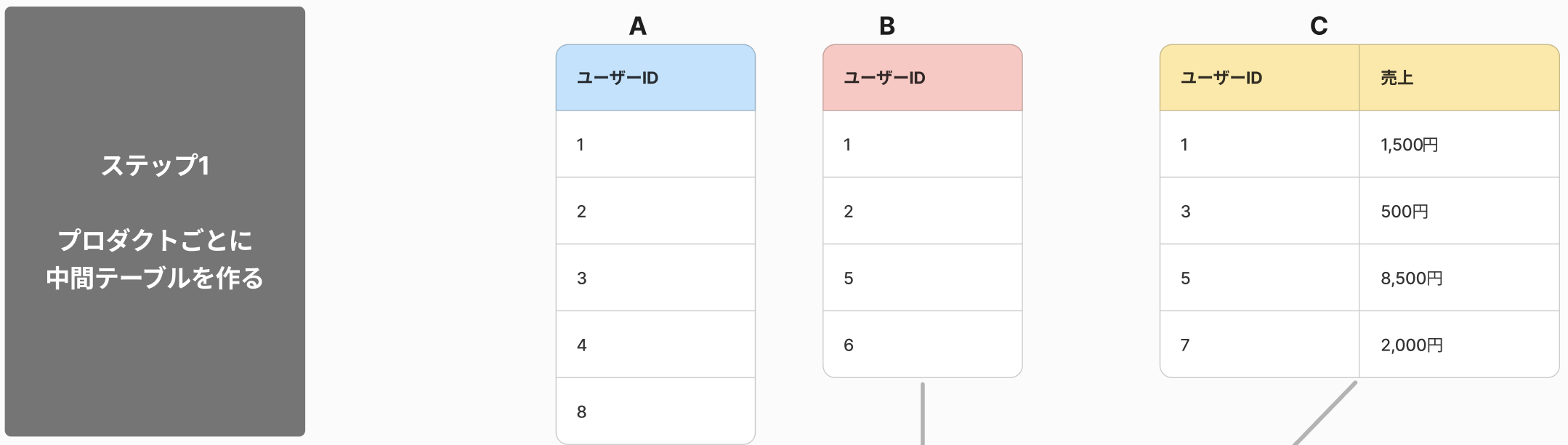
ステップ2:中間テーブルを結合。分析用のマスターテーブルを作る
プロダクトごとに計算した中間テーブルを、1つに結合します。
それぞれのプロダクトを利用するユーザーのユーザーIDの総和が取られていることがわかります。
C 未利用のユーザーの売上は存在しないため、0円としています。
SQL クエリは以下のようになります。full joinとcoalesceを使います。
with A_users as (select user_id from ...),
B_users as (select user_id from ...),
C_users as (select user_id, revenue from ...)
select
coalesce(A.user_id, B.user_id, C.user_id) as user_id,
A.user_id is not null as is_A_user,
B.user_id is not null as is_B_user,
C.user_id is not null as is_C_user,
C.revenue as C_revenue
from A_users as A
full join B_users as B using(user_id)
full join C_users as C using(user_id)
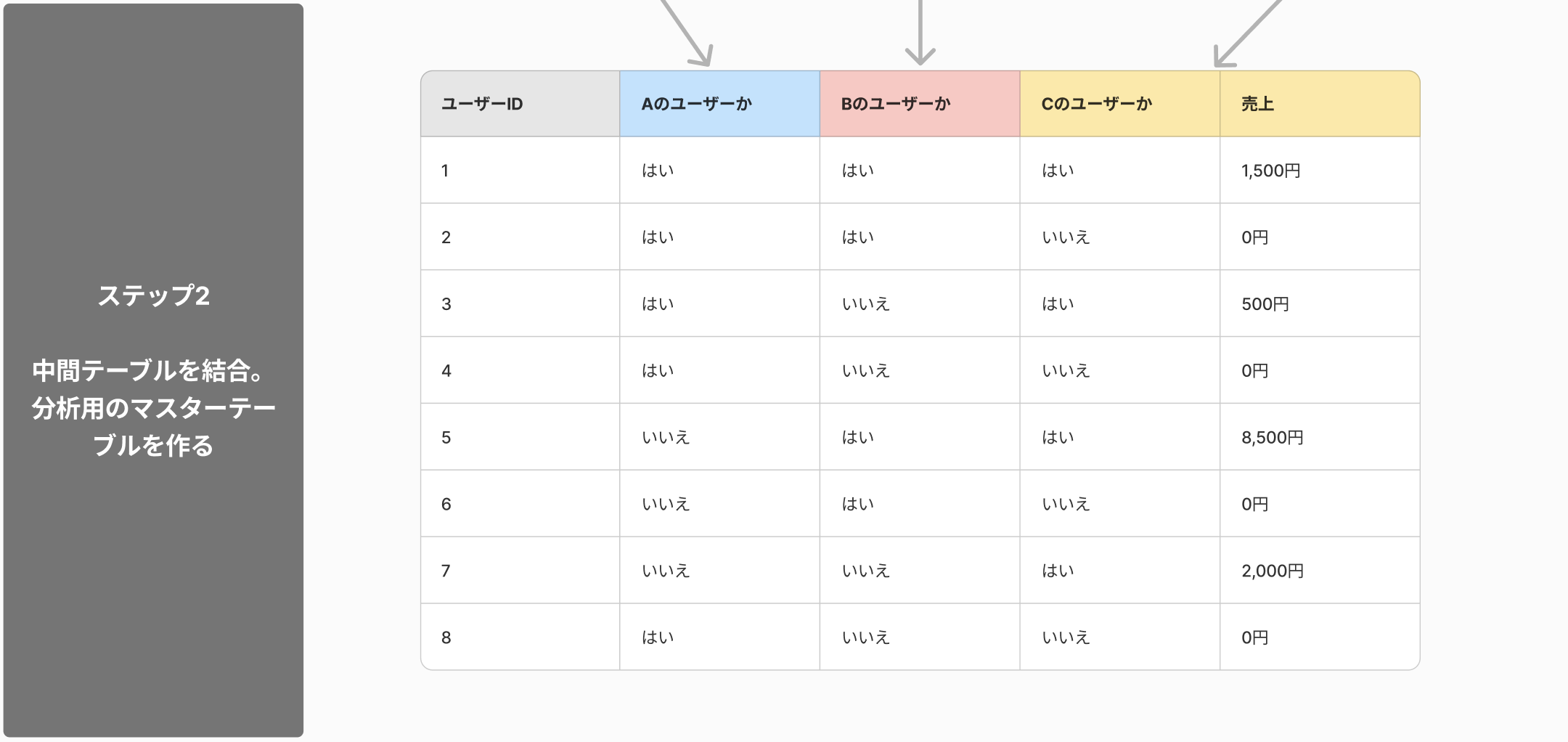
ステップ3:マスターテーブルに対して分析を行う
分析用のマスターテーブルが出来れば、あとは簡単です。これを用いて自由に分析を行いましょう。

上の図では、Aを使うユーザーとBを使うユーザーについて、ユーザー数と1人あたり平均売上を計算しています。
-- ① A を使っていて C を使っていないユーザー数
select
count(*) as count_user
from
master_table
where
is_A_user and not is_C_user;
-- ② B を使っていて C を使っていないユーザー数
select
count(*) as count_user
from
master_table
where
is_B_user and not is_C_user;
-- ③ A を使っていて C を使っているユーザーの1人あたり平均売上
select
avg(C_revenue) as avg_revenue
from
master_table
where
is_A_user and is_C_user;
-- ④ B を使っていて C を使っているユーザーの1人あたり平均売上
select
avg(C_revenue) as avg_revenue
from
master_table
where
is_B_user and is_C_user;
事前にマスターテーブルを作ったおかげで、分析用のSQLクエリはとても簡単になっていますね。
分析結果をまとめて、以下の表を作成します。
| 検討プロダクト | C未利用ユーザー数 | C利用ユーザーの平均売上 | 市場開拓余地 |
|---|---|---|---|
| A | ①の count_user | ③の avg_revenue | ① × ③ |
| B | ②の count_user | ④ の avg_revenue | ② × ④ |
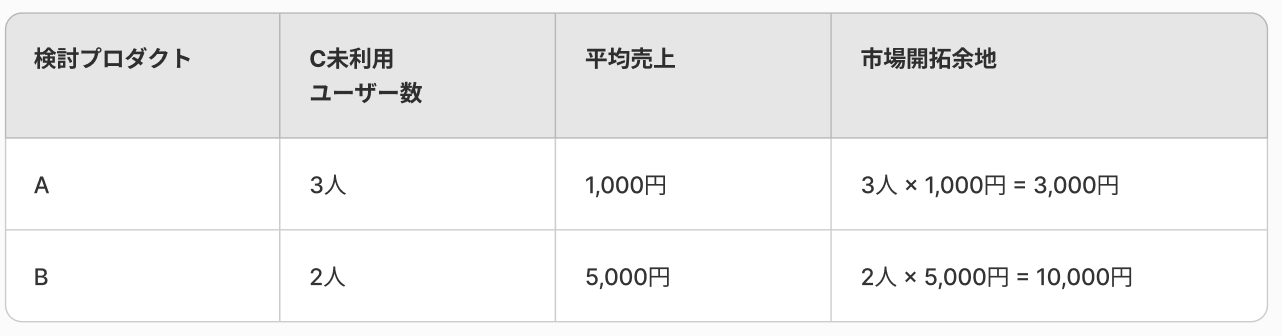
上の図では、Bのユーザーに対してクロスセル施策を打った方が売上の増加が見込める、という結果になりました。
おわりに
ユーザーIDの粒度で中間テーブルを作り、分析用のマスターテーブルを作るアプローチは、日々の業務における多くの場面で役に立ちます。覚えておくと便利です。
ディメンショナルモデリングの世界では、このような手法を「ドリルアクロス(Drilling Across)」と呼びます。A,B,Cという異なるプロダクトのファクトを適合ディメンションである「ユーザーID」で事前集計することで、プロダクトをまたいだ分析ができるようになります。
https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/drilling-across/
「ユーザー数」「売上」といった汎用性の高い指標については、全社共通でこのような中間テーブルをメンテナンスし、分析者が気軽に使える状態にしておくと、プロダクトや部署をまたいだデータの利活用を促せるでしょう。