はじめに
プログラミングとはなんぞや...という状態から3ヶ月でデータ分析コンペであるKaggleに初挑戦した結果と感想です。
参加したコンペはOptiver Realized Volatility Predictionというコンペでして、取り扱ったデータはテーブルデータでした。
データ数は計算すると約1億ほどあり、メモリが何回かやられました。笑
実際に参加した期間は終わりの約二週間です。時間余ると思ってましたが、全く足りませんでした。
コンペの簡単な詳細は以前書いたこちらを参照してください。
[https://qiita.com/hannnari0918/items/7c38f35d20c96691bc13]
コンペサイトはこちら
[https://www.kaggle.com/c/optiver-realized-volatility-prediction]
Kaggleのメダルについて
もっていると転職やキャリアアップに有利だといわれるKaggleのメダルですが、実は4種類のメダルがあります。
私も1種類しかないとおもっており、実際にコンペに参加して存在を知りました。
Competitions Contributor メダル
いわゆるブログやTwitter等によく書いてあるメダル取れました!というのはこのメダルのことになります。
このメダルは与えられたデータに対して、最も精度の良いモデルを作成した方から順に獲得できるメダルになります。
| 0-99 Teams | 100-249 Teams | 250-999 Teams | 1000+ Teams | |
|---|---|---|---|---|
| Bronze | Top 40% | Top 40% | Top 100 | Top 10% |
| Silver | Top 20% | Top 20% | Top 50 | Top 5% |
| Gold | Top 10% | Top 10 | Top 10 + 0.2%* | Top 10 + 0.2%* |
今回は約4000チームが参加されており、上位400番以内に入れればメダルがもらえるといったコンペでした。
私もこのメダルを狙っていましたが、なかなか順位が上がらず壁は厚いなぁと実感させられました。
Notebook Medals
実はKaggleは自分が使用したコードを公開する事ができます。また、そのコードに対して他の参加者からUpVote(いいね)やコメントをいただくことができます。
自分で考えたIdeaや効率的なコードをわかりやすく他人が読めるようにまとめる事で、UpVoteをいただくことができます。
初心者にもわかりやすくコメントアウトやコードの解説をしてくださっているNoteBookが多数あり、私も大変勉強になりました。
実際にいいスコアを出している方々の考え方を知ることができ、そのコードを実際に動かせるというのは他の場所ではできない事でしたので、そう言った知識や考え方を得れたのが一番参加してみて大きな収穫でした。
出回っているコードはほぼほぼ読み尽くしたかと思います。笑
| 0-99 Teams | |
|---|---|
| Bronze | 5 Vote |
| Silver | 20 Vote |
| Gold | 50 Vote |
実際に私も初心者ながら、何個か解説入りコードを公開したところメダルを獲得することができました。
非常に拙いコードでしたが、いいねやコメントがつくとやはりモチベーションアップに繋がりますし非常にいい制度だと実感しました。
Dataset Medals
このメダルは自分が作成したデータセットに対して与えられるメダルになります。
今回は特にデータセットを公開していないので、あまり関係性はありませんでした。
| 0-99 Teams | |
|---|---|
| Bronze | 5 Vote |
| Silver | 20 Vote |
| Gold | 50 Vote |
Discussion Medals
KaggleのコンペにはDiscussionという機能があり、実際にコンペに参加されている方々が掲示板のように使用して自分の考えや疑問を他人と共有することができます。私も実行中にエラーを吐いてしまった際に掲示板検索すると同様のエラーの解決策を述べてくださる方がいて、非常に助かりました。
また、ここでも自分になかった考え方を得れるので非常に参考になりました。
| 0-99 Teams | |
|---|---|
| Bronze | 1 Vote |
| Silver | 5 Vote |
| Gold | 10 Vote |
参加してみて
プログラミング始める前から、名前だけはしっていたKaggleですが敷居が高く自分には関係のない話だと思っていました。
しかしながら、ただ順位が出るだけではなく実際のプロの方々のコードや考え方を学ぶことが出来、非常に勉強になりました。
私自身の考え方ですが、初心者こそKaggleに参加するべきだという感想になりました。
また、今回のコンペホストの方がコンペの解説をしてくださるみたく、参加させていただく予定です。 (英語聞き取れるかはおいといて)
正式な順位は2021/1に公開されるらしく、公開されたらまた追記しようと思います。
今回のコンペで学習できた事、今後のコンペで使えそうな事
ここからは今回のコンペを通じて実際に自分が学習できたことを記します。
自分用の記事になってしまいますが、参考になればと思います。
特徴量作成について
株の知識が全くなかったので、公開されているnotebookをかなり参考にしました。
どんな特徴量が精度を向上させるのかは、わからないのでとりあえず思いつく限りの特徴量をコードではなくて文字で大量に書き連ねました。
また作成するだけではなく、さまざまな方法を用いて拡張して使用されていました。
Groupby
作成した特徴量を分類できそうな事柄毎にまとめてしまうやり方。
今回のコンペだと
- 銘柄毎
- 時間毎
にgroupbyを行い、その統計指標(max, min等)を新たなる特徴量として追加するという手法がとられていました。
他にも月毎や男性女性等幅広く使える手法だと思います。
例
def get_time_agg_lgbm(df):
gcols=['book_log_return1_realized_volatility']
gcols+=['book_log_return1_realized_volatility_150win_150']
gcols+=['book_log_return2_realized_volatility_150win_300']
# Group by the stock id
df_time_id = df.groupby('time_id')[gcols].agg(['mean', 'std', 'max', 'min']).reset_index()
# Rename columns joining suffix
df_time_id.columns = ['_'.join(col) for col in df_time_id.columns]
df_time_id = df_time_id.add_suffix('_' + 'time')
# Merge with original dataframe
df_time_id = df_time_id.rename(columns={'time_id__time':'time_id'})
#########################
# 特徴量削減
drop_list_time = ['book_log_return1_realized_volatility_max_time',
'book_depth_sum_150win_150_max_time']
df_time_id = df_time_id.drop(drop_list_time, axis=1)
return df_time_id, [col for col in df_time_id if col not in ['time_id']]
データ量削減
データの量が多すぎるので、今回の600秒のデータの全てを使用するのではなく
- 0~600
- 50~600
のように、適当に区切りその区間の統計指標を新しく特徴量として使用するやり方。
もともとあった600秒を新しくtime_idと置き直して、そのサンプルがもつ特徴量として使用するやり方。
最初は1億のデータをどう扱っていいのか全くわからず苦しみましたが、このやり方をしって40万ほどのデータにすることが出来ました。
def book_preprocessor(file_path):
df = pd.read_parquet(file_path)
df = df.groupby(['time_id','seconds_in_bucket']).mean().reset_index()
# Calculate prices
df['wap1'] = calc_wap1(df)
df['wap2'] = calc_wap2(df)
# Calculate log returns
df['log_return1'] = df.groupby('time_id')['wap1'].apply(log_return)
df['log_return2'] = df.groupby('time_id')['wap2'].apply(log_return)
# Dict for aggregations
create_feature_dict = {
'log_return1': [realized_volatility, realized_absvar],
'log_return2': [realized_volatility, realized_absvar],
}
create_feature_dict_bins = {
'log_return1': [realized_volatility, realized_absvar],
'log_return2': [realized_volatility, realized_absvar]
}
# Get the stats for different windows
df_feature_0 = get_stats_bins(df, create_feature_dict, 0)
df_feature_w4 = get_stats_window(df, create_feature_dict_bins, 150)
# Merge all
df_feature_0 = df_feature_0.merge(df_feature_w4, how = 'left', on = 'time_id')
df_feature_0 = df_feature_0.add_prefix('book_')
stock_id = file_path.split('=')[1]
df_feature_0['row_id'] = df_feature_0['book_time_id'].apply(lambda x:f'{stock_id}-{x}')
df_feature_0.drop(['book_time_id'], axis = 1, inplace = True)
return df_feature_0
クラスタリング
同じような目的変数の分布をするサンプルをクラスターとしてまとめて、新しく特徴量を作成するやり方。
目的変数だけでなく、さまざまな特徴量に対して使用できる方法になります。
また、私はそのクラスター毎に学習を行わせて効率的な学習をできるようなモデルを作成しました。
非常に誤差を減らせますが、クラスターによってはサンプル数が足りずうまく学習ができないクラスターも存在してしまうことになりましたが、方法の一つとして覚えといて損はないと思いました。
from sklearn.cluster import KMeans
# making agg features
train_p = pd.read_csv('train.csv')
train_p = train_p.pivot(index='time_id', columns='stock_id', values='target')
corr = train_p.corr()
ids = corr.index
kmeans = KMeans(n_clusters=7, random_state=0).fit(corr.values)
print(kmeans.labels_)
l = []
for n in range(7):
l.append ( [ (x-1) for x in ( (ids+1)*(kmeans.labels_ == n)) if x > 0] )
mat = []
matTest = []
n = 0
for ind in l:
print(ind)
newDf = train.loc[train['stock_id'].isin(ind) ]
newDf = newDf.groupby(['time_id']).agg(np.nanmean)
newDf.loc[:,'stock_id'] = str(n)+'c1'
mat.append ( newDf )
n+=1
mat1 = pd.concat(mat).reset_index()
mat1.drop(columns=['target'],inplace=True)
mat1 = mat1.pivot(index='time_id', columns='stock_id')
mat1.columns = ["_".join(x) for x in mat1.columns.ravel()]
mat1.reset_index(inplace=True)
nnn = ['time_id',
'book_log_return1_realized_volatility_0c1',
'book_log_return1_realized_volatility_1c1',
'book_log_return1_realized_volatility_2c1',
'book_log_return1_realized_volatility_3c1',
'book_log_return1_realized_volatility_4c1',
]
train = pd.merge(train,mat1[nnn],how='left',on='time_id')
test = pd.merge(test,mat2[nnn],how='left',on='time_id')
特徴量削減
大量に作成された特徴量を削るやり方。
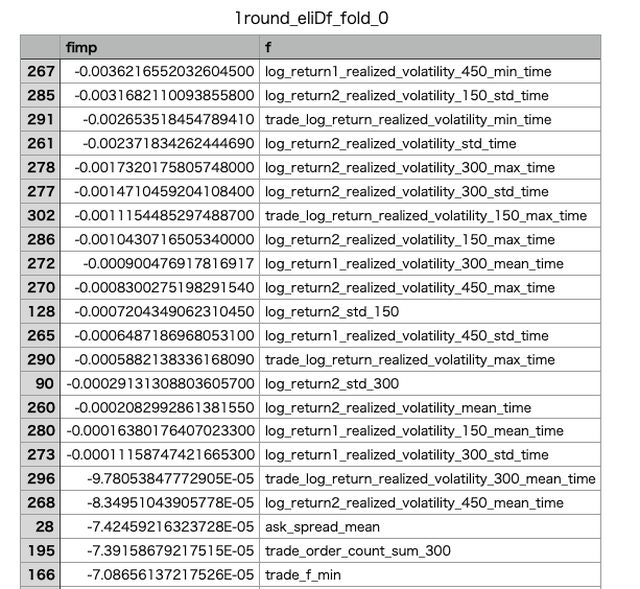
- Feature Importance
- Purmutation Importance
ただ、あくまで手持ちのデータの中の評価で削ることになるので未知データに対して有用な特徴量を消してしまう可能性はあります。
実際に削ってスコアが上がることが多かったが、削りすぎてしまいスコアが悪くなってしまうこともたびたび生じました。
Permutation Importanceについてはまた記事をまとめたいと思います。
このコンペで一番得れたものだと思います。
リーク(情報漏洩について)
一番頭を悩ませました。Discussionの中でも非常に意見が分かれており、回避するべきか、しないべきかで迷いました。
今回求める目的変数は各時間、各株の次の10分感のボラティリティです。
では何がリークかというと上で述べたgroupbyによる時間事の統計指標です。
サンプル数はtime_id * stock_idできまっていますが、groupbyによる統計指標は複数のサンプルに跨っている特徴量です。
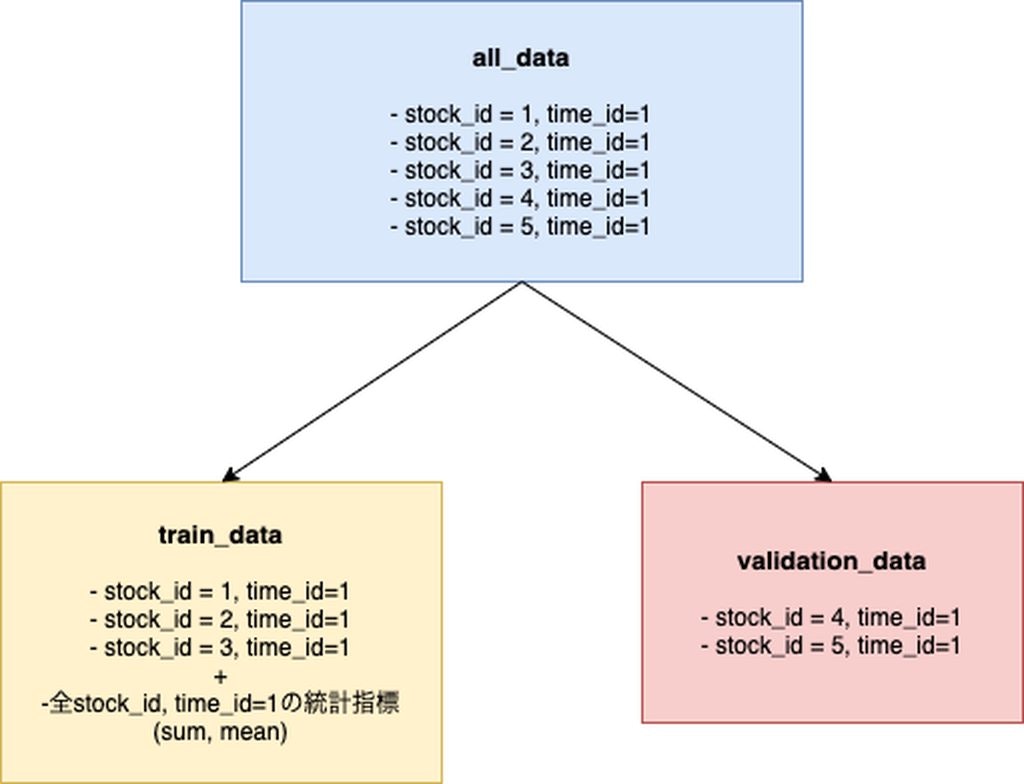
当然ですが訓練データが検証データの情報を持っている状態でモデルが学習されてしまうので、過学習が著しく発生します。
実際にKflodにてモデル作成を行なったものはかなりCVは下がっていましたがLBとの差が0.02ほど発生しました。
GloupKflodについて
ここで新しい交差検証の方法としてGloupKflodを使用しました。
サンプル数はいじらずtime_id * stock_idのままですが、time_idを元に割り振りを行う交差検証です。
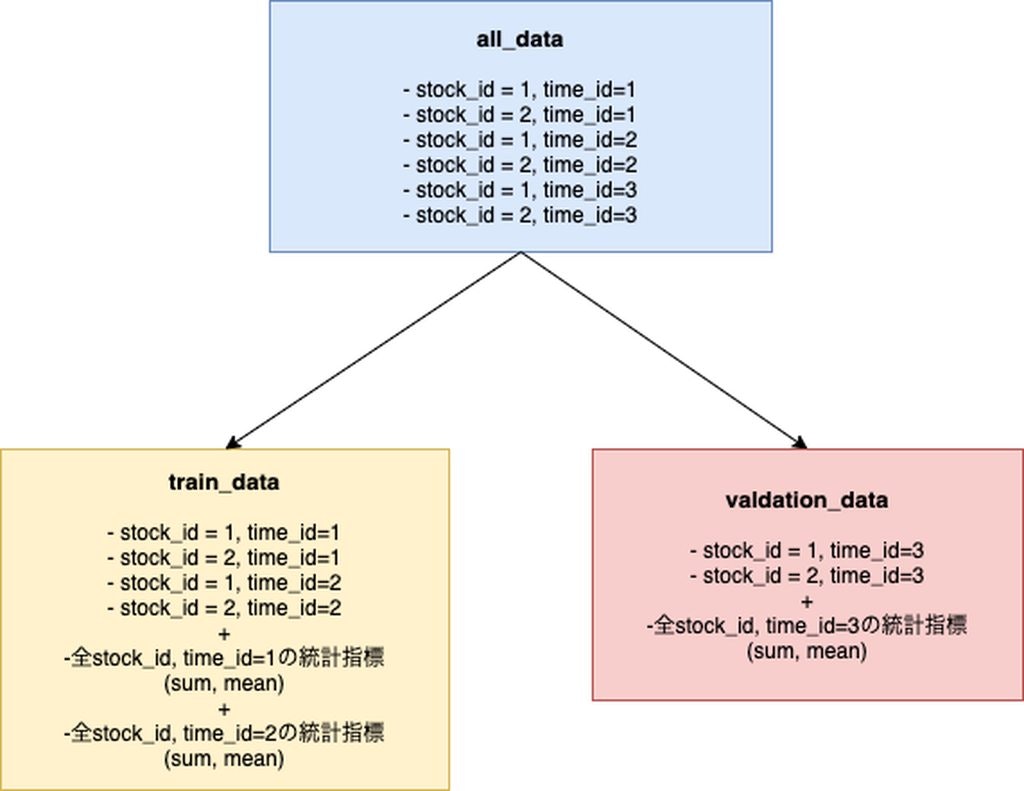
この方法を取ることによって、CVとLBの差を軽減する事ができました。
(それでも未知データであるLBに対してなぜかKfoldの方がスコアが良かったのは謎、たまたまだとおもうが...)
公開されているノートは基本的にKflodで書かれていたため、GloupKflodを使用した方はかなり少なかったのかなと思います。
しかしながら、上位の方もこちらを使われていたので今後は交差検証にも目を向ける必要があると感じました。
最終的に
私はNN60%, LGBM20%, stock_id毎のLGBM20%のアンサンブル学習にGloupKflodを使った物を提出しました。
実際の予測に使われるのは全くの未知データになるので、過学習を抑えられるよう3モデルを混ぜて提出してみました。
大変でしたが、学ぶことも多かったと感じております。
最終的な順位が発表されたらまた更新します。