本記事では Spark アプリケーションのメモリエラーに関するログを表示します。メモリエラーによるトラウマを抱えている方/日々寝れない生活をされている方は注意しながら読み進めてください。
はじめに
AWS ブログ が出した記事「Amazon EMR で Apache Spark アプリケーションのメモリをうまく管理するためのベストプラクティス」で、メモリ不足エラーを回避するための Spark パラメータのチューニング方法を紹介しました。
WARN TaskSetManager: Loss was due to
java.lang.OutOfMemoryError
java.lang.OutOfMemoryError: Java heap space
何度もお世話になっている記事ですが、インスタンスタイプや台数を変えるたび、パラメータを再計算するのに時間がかかります。そこで、AWS が紹介した計算ロジックを Python 関数でまとめようと思ったのが、本記事の背景になります。
最適化されたSparkパラメータを計算する関数
EMRのワークロードに必要なコンピュートリソースを特定してから、EC2のダッシュボードや外部のまとめサイトからマスター/コアノードのインスタンスタイプとその数を決めます。

以下の関数に必要な情報を入力すると、AWS のブログ記事に紹介された方法で最適化された Spark パラメータを計算します。引数は3つあります。
| パラメータ名 | 意味 | 例 |
|---|---|---|
| cores_per_instance | コアノードのvCPU | r5.xlarge だと「4」 |
| memory_gb_per_instance | コアノードのメモリ(Gb) | r5.xlarge だと「32」 |
| number_of_core_instances | コアノード数 | 1マスター、3コア構成だと「3」 |
import math
def get_memory_optimized_spark_config(
cores_per_instance: int, memory_gb_per_instance: int, number_of_core_instances: int
):
"""
AWS の以下のブログ記事で紹介された方法に則って最適化された Spark パラメータを計算する
Amazon EMR で Apache Spark アプリケーションのメモリをうまく管理するためのベストプラクティス
https://aws.amazon.com/jp/blogs/news/best-practices-for-successfully-managing-memory-for-apache-spark-applications-on-amazon-emr/
Parameters
----------
cores_per_instance: int
コアノードのvCPU (例: r5.xlargeだと4)
memory_gb_per_instance: int
コアノードのメモリ(Gb) (例: r5.xlargeだと32)
number_of_core_instances: int
コアノード数(1マスタのみの場合は「1」を指定してください)
"""
extra_java_options = (
"-XX:+UseG1GC "
"-XX:+UnlockDiagnosticVMOptions "
"-XX:+G1SummarizeConcMark "
"-XX:InitiatingHeapOccupancyPercent=35 "
"-verbose:gc "
"-XX:+PrintGCDetails "
"-XX:+PrintGCDateStamps "
"-XX:OnOutOfMemoryError='kill -9 %p'"
)
config = {
"spark.executor.cores": 5,
"spark.driver.cores": 5,
"spark.memory.fraction": 0.8,
"spark.memory.storageFraction": 0.3,
"spark.dynamicAllocation.enabled": "false",
"spark.shuffle.compress": "true",
"spark.shuffle.spill.compress": "true",
"spark.rdd.compress": "true",
"spark.executor.extraJavaOptions": extra_java_options,
"spark.driver.extraJavaOptions": extra_java_options,
}
# Number of executors per instance =
# (total number of virtual cores per instance - 1) / spark.executors.cores
executors_per_instance = max(
1, math.floor((cores_per_instance - 1) / config["spark.executor.cores"])
)
# Total executor memory =
# (total RAM per instance - 1gb) / number of executors per instance
total_executor_memory = math.floor(
(memory_gb_per_instance - 1) / executors_per_instance
)
config["spark.executor.memory"] = str(math.floor(total_executor_memory * 0.9)) + "g"
config["spark.driver.memory"] = config["spark.executor.memory"]
config["spark.executor.memoryOverhead"] = (
str(math.ceil(total_executor_memory * 0.1)) + "g"
)
config["spark.driver.memoryOverhead"] = config["spark.executor.memoryOverhead"]
# (number of executors per instance * number of core instances) minus 1 for the driver
config["spark.executor.instances"] = max(
1, (executors_per_instance * number_of_core_instances) - 1
)
config["spark.default.parallelism"] = (
config["spark.executor.instances"] * config["spark.executor.cores"] * 2
)
config["spark.sql.shuffle.partitions"] = config["spark.default.parallelism"]
config_string_values = {k: str(v) for k, v in config.items()}
return config_string_values
使ってみる
小さいクラスター
| ノード | インスタンスタイプ | 台数 |
|---|---|---|
| マスター | m5.xlarge | 1 |
| コア | r5.xlarge | 1 |
get_memory_optimized_spark_config(
cores_per_instance=4,
memory_gb_per_instance=32,
number_of_core_instances=1
)
{
"spark.executor.cores": "5",
"spark.driver.cores": "5",
"spark.memory.fraction": "0.8",
"spark.memory.storageFraction": "0.3",
"spark.dynamicAllocation.enabled": "false",
"spark.shuffle.compress": "true",
"spark.shuffle.spill.compress": "true",
"spark.rdd.compress": "true",
"spark.executor.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.driver.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.executor.memory": "27g",
"spark.driver.memory": "27g",
"spark.executor.memoryOverhead": "4g",
"spark.driver.memoryOverhead": "4g",
"spark.executor.instances": "1",
"spark.default.parallelism": "10",
"spark.sql.shuffle.partitions": "10"
}
大きいクラスター
| ノード | インスタンスタイプ | 台数 |
|---|---|---|
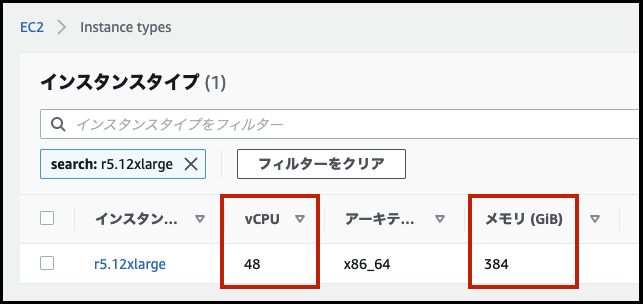
| マスター | r5.12xlarge | 1 |
| コア | r5.12xlarge | 19 |
get_memory_optimized_spark_config(
cores_per_instance=48,
memory_gb_per_instance=384,
number_of_core_instances=19
)
{
"spark.executor.cores": "5",
"spark.driver.cores": "5",
"spark.memory.fraction": "0.8",
"spark.memory.storageFraction": "0.3",
"spark.dynamicAllocation.enabled": "false",
"spark.shuffle.compress": "true",
"spark.shuffle.spill.compress": "true",
"spark.rdd.compress": "true",
"spark.executor.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.driver.extraJavaOptions": "-XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.executor.memory": "37g",
"spark.driver.memory": "37g",
"spark.executor.memoryOverhead": "5g",
"spark.driver.memoryOverhead": "5g",
"spark.executor.instances": "170",
"spark.default.parallelism": "1700",
"spark.sql.shuffle.partitions": "1700"
}
参考に