はじめに
この記事はBeeX Advent Calendar 2022の7日目の記事です。
え?今何日目か数えてみろよって?(投稿日12/9)
インフル罹って寝込んでましたごめんなさい
それはともかく、先月の話ですがAmazon AppFlowでGlue DataCatalogとの統合をサポートするアップデートが発表されてました。
このリリースが出る前までは、一度AppFlowでS3に出力した後に別途Glue Crawlerを動かさないとAthenaなどからクエリできなかったのが、このリリースが出ることでGlue Crawlerが不要になりましたので、検証がてら試してみることにします。
検証内容
前提条件
個人的都合から一番使いやすい以下のデータで検証を行いました。
Salesforce環境及び出力先のS3バケットについては事前に作成済みです。
- データ送信元:Salesforce
- データ送信先:S3
通常実行
まずはコンソールの指示に従って、フローを作成・実行させてみます。
フロー作成・実行
Salesforceオブジェクトはデフォルトで存在している「取引先」を指定します。
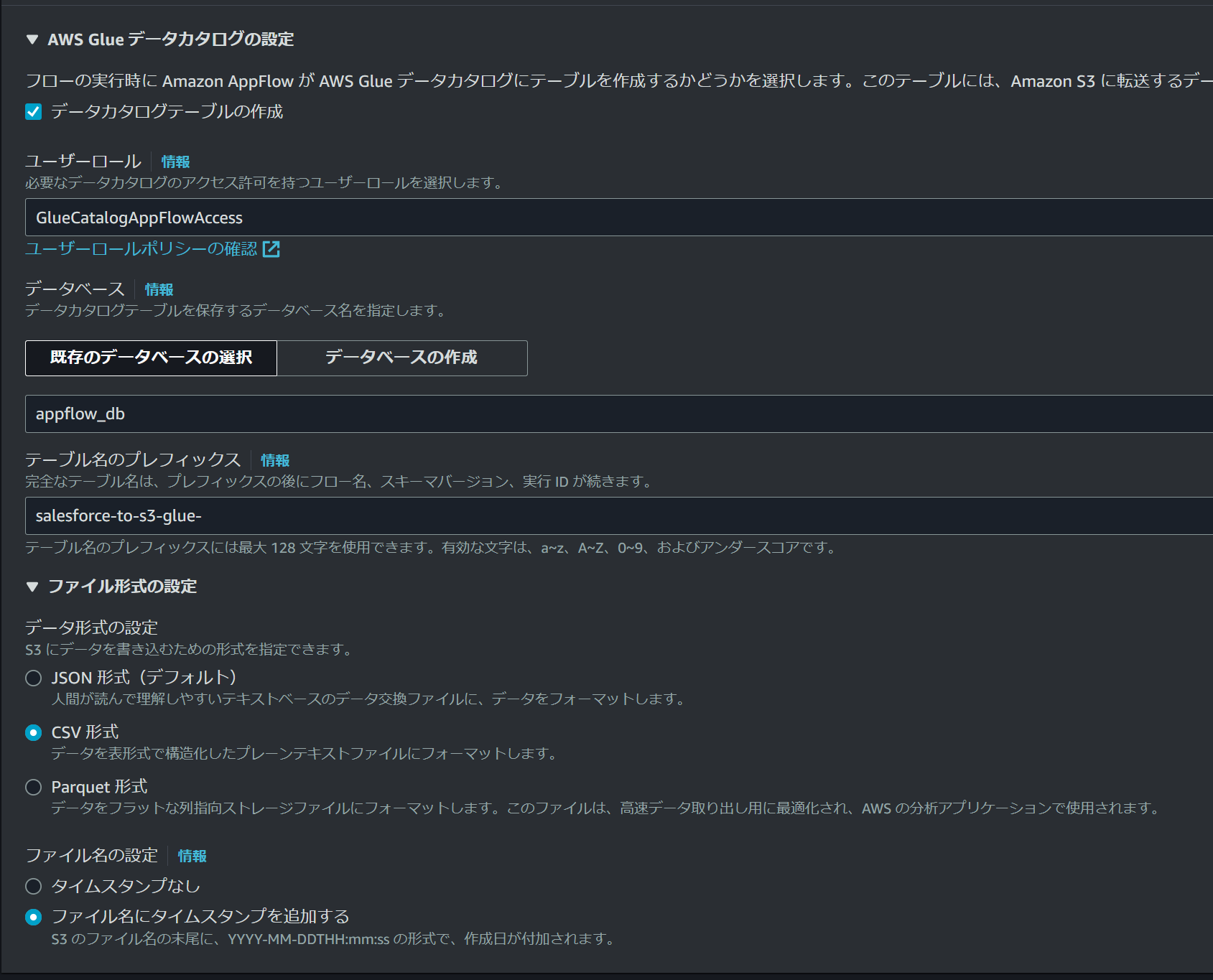
送信先にS3を指定すると「AWS Glue データカタログの設定」が表示されるようになっています。
ここをチェック入れると
- ユーザーロール
- データベース(Glue)
- テーブル名のプレフィックス
を入力する項目が出てきますので、それぞれ必要な情報を入力します。
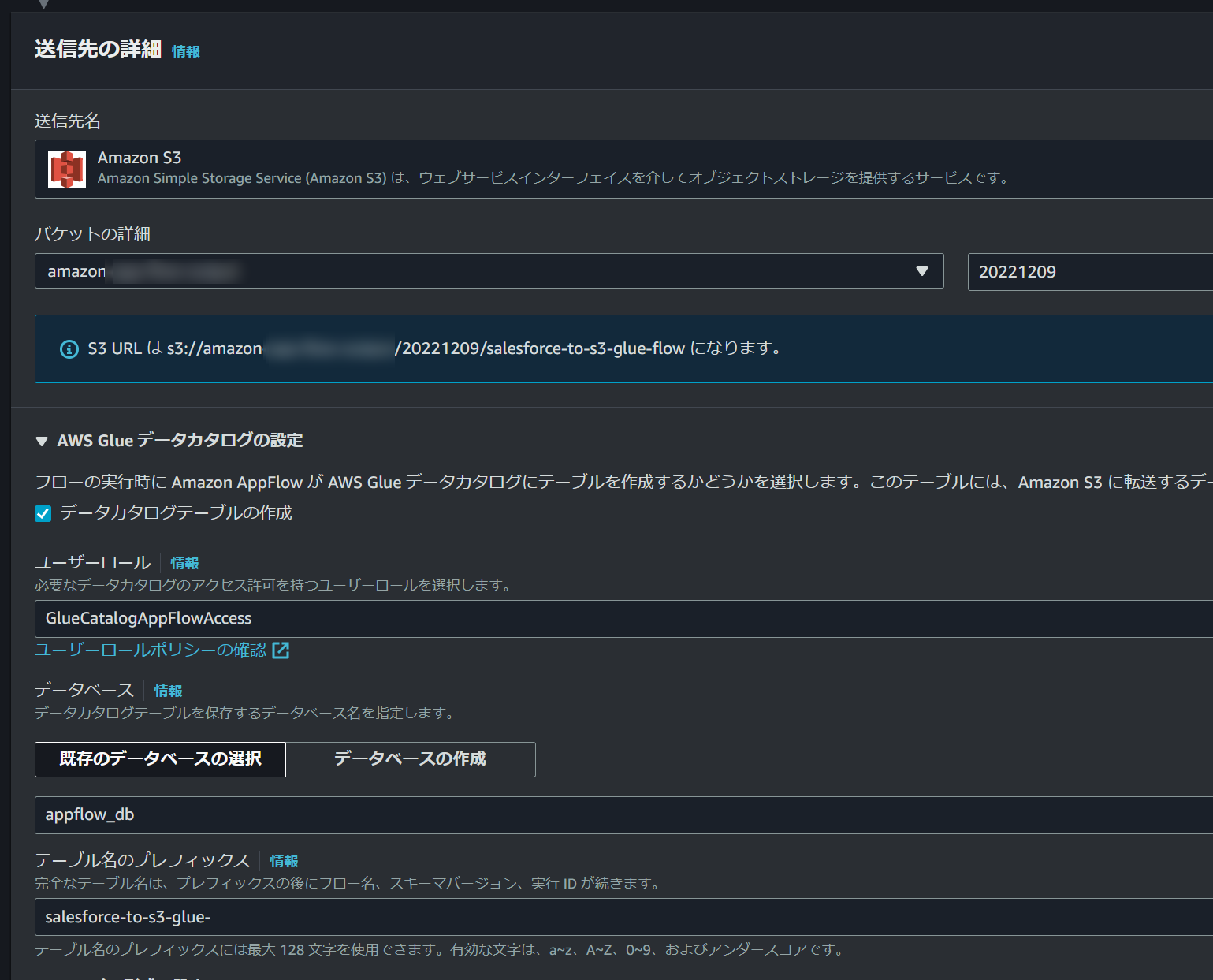
ユーザーロールの権限については以下のURLにあるポリシーを参考にしました。
https://docs.aws.amazon.com/appflow/latest/userguide/security_iam_id-based-policy-examples.html
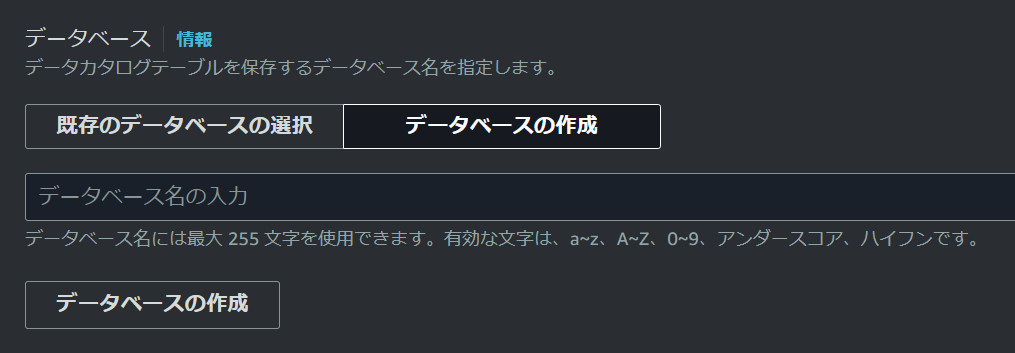
Glue DataCatalogのデータベース名を指定する箇所もありますが、AppFlowの画面上から作成することも可能になっています。
テーブル名にはプレフィックスを付けることができます。
といいますか、このプレフィックスは必須項目なので、何かしらの名前を先頭に付ける必要があります。

今回はフィールドマッピングはさほど重要じゃないので、その下の「パーティションと集約の設定」を開きます。
細かくパーティションの設定は可能ですが、それは後ほど試すのでここでは設定を変更せずに次に行きます。
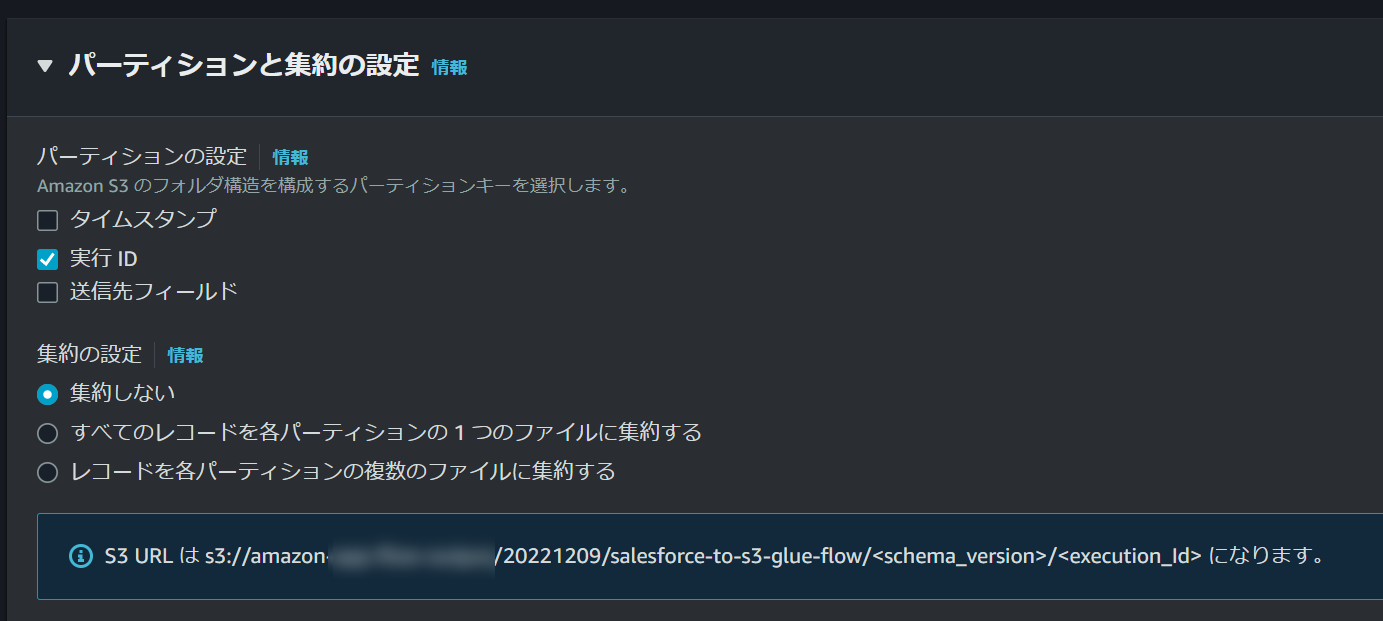
以降は特に設定するものもないので、そのまま作成して実行してみます。
Glue Crawlerが裏で動いているからか前よりも時間がかかってる気がしますが、正常終了すると以下のように表示されます。
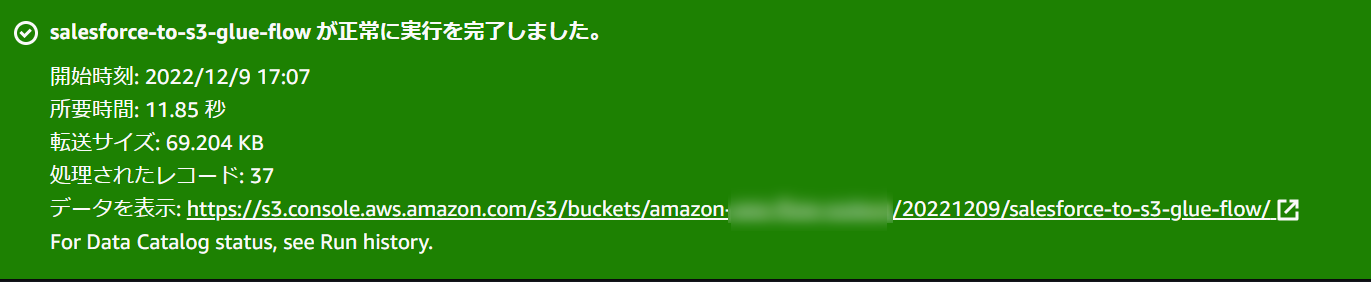
結果確認
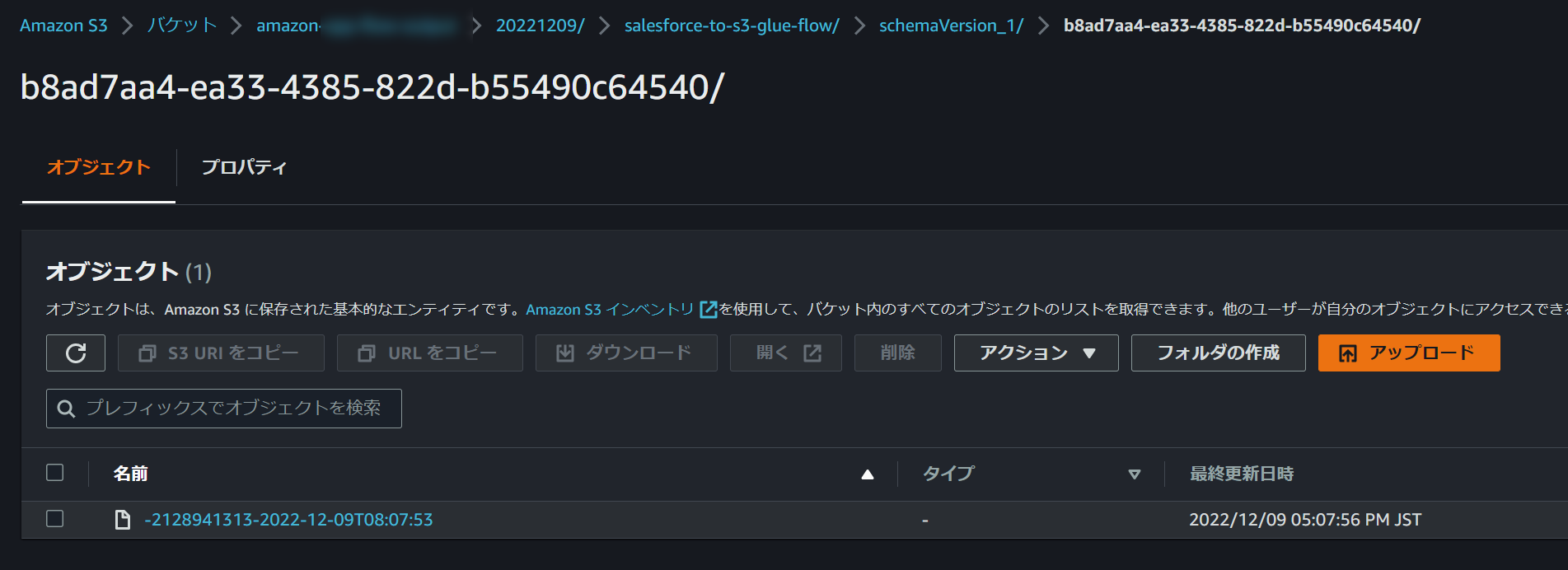
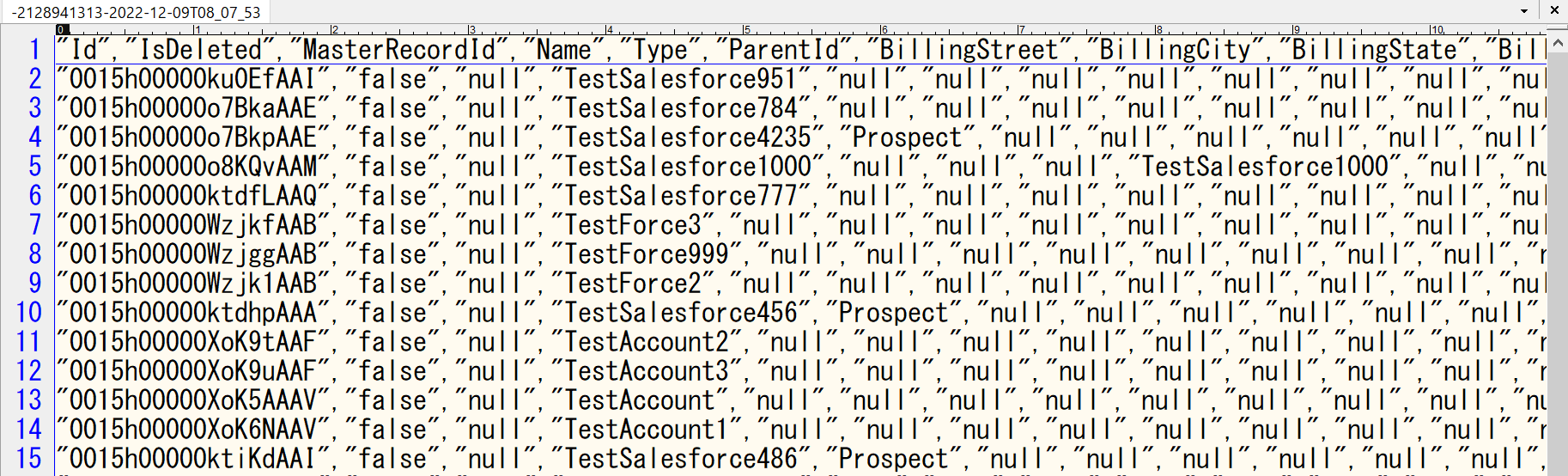
S3バケットから出力を確認してみます。
「S3バケット名>指定したプレフィックス>フロー名>スキーマバージョン>実行ID」配下にファイルが出力されており、拡張子はないですが、ダウンロードして開いてみるとCSVでデータが入っていることが確認できます。
GlueのData Catalogから確認してみます。
ちゃんとテーブルは登録されているようですが、1回しか実行していないのに何故かテーブルは2つ作成されていました。
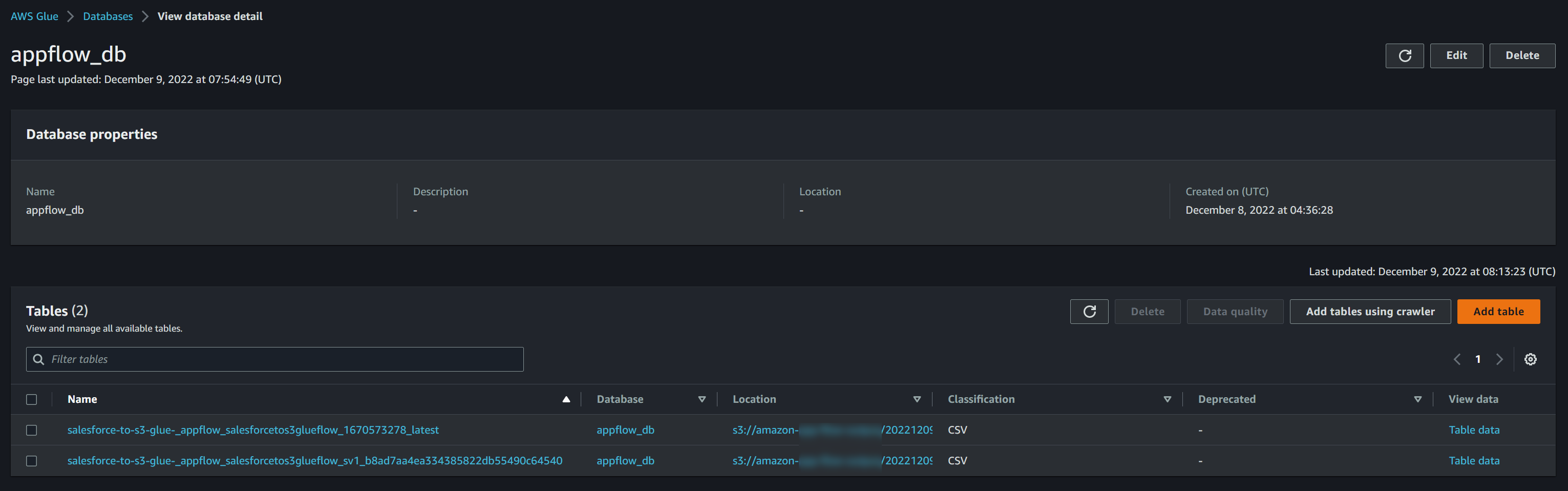
比較してみましたが、名前以外は全く同じで、同じデータソースをクローリングしているように見えます。
この後試してみればわかることだとは思いますが、恐らくlatestテーブルは常に最新のデータの情報が登録されるようになっており、古いデータを見たい場合はlatestが付いていないテーブルを直接参照することができるようになっているのだと思われます。
(もしかしてデータベース1つに対してlatestは1つしか持てないとかある...?)
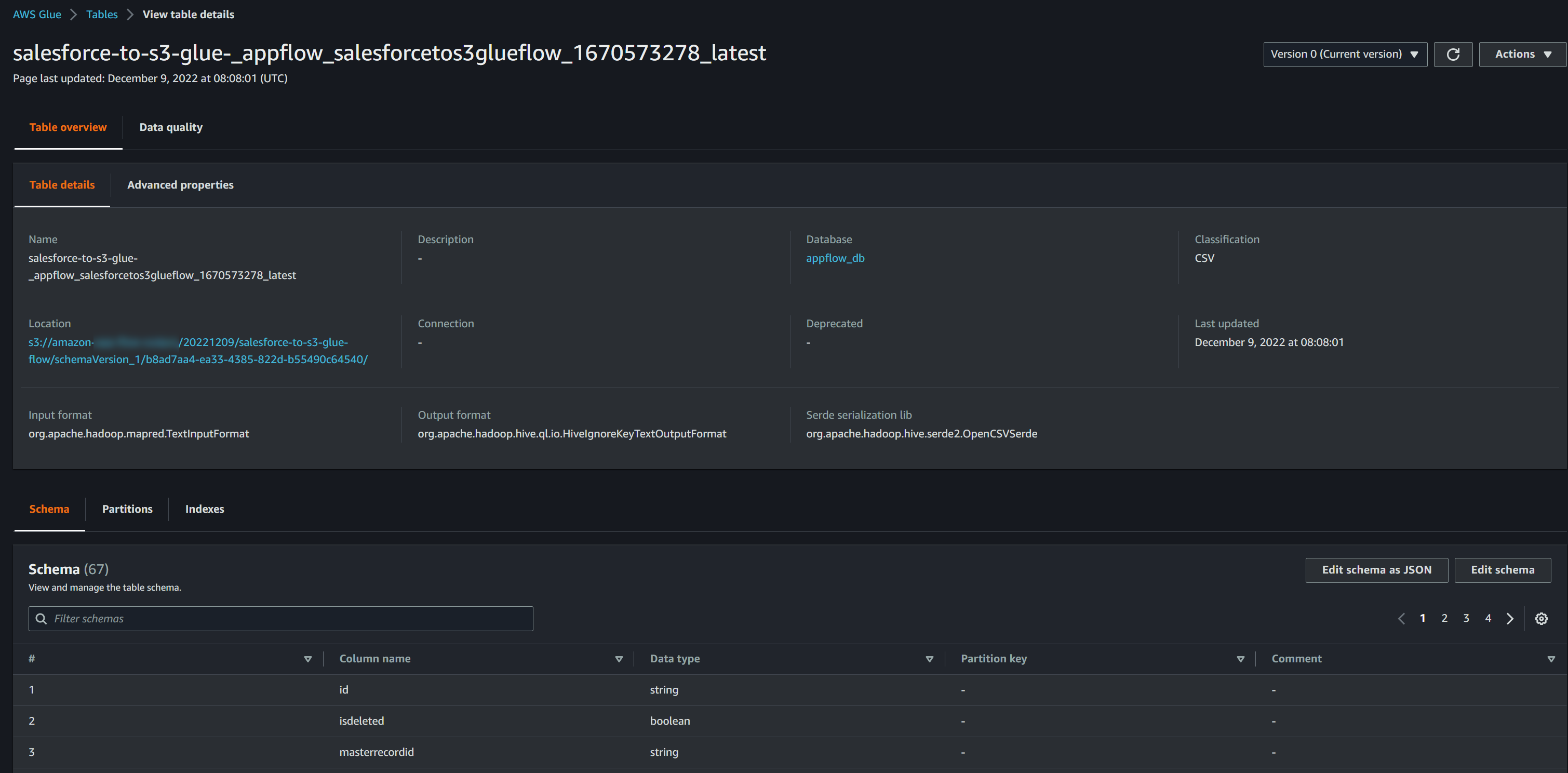
-
latestが付いているテーブル
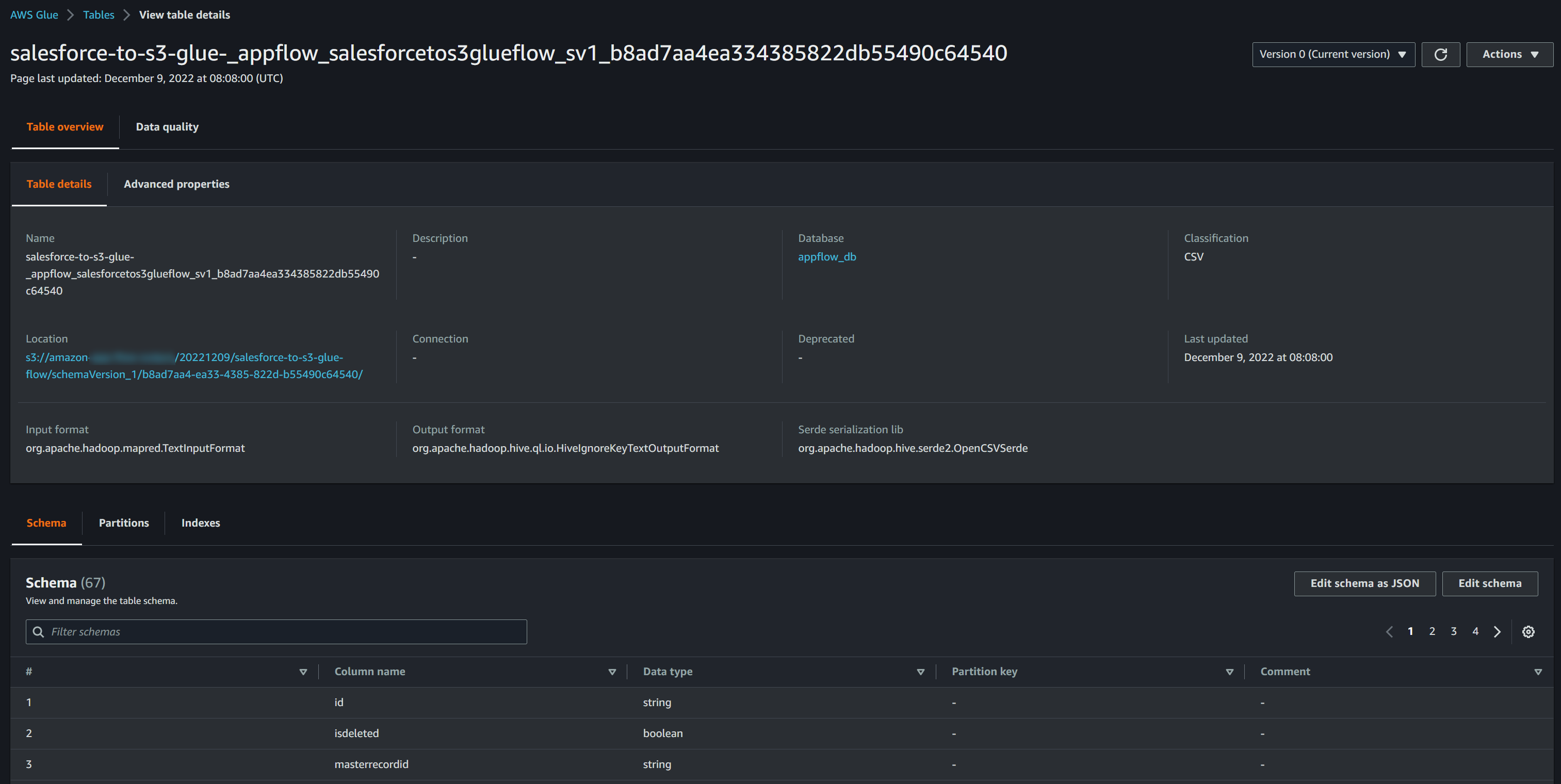
-
latestが付いていないテーブル
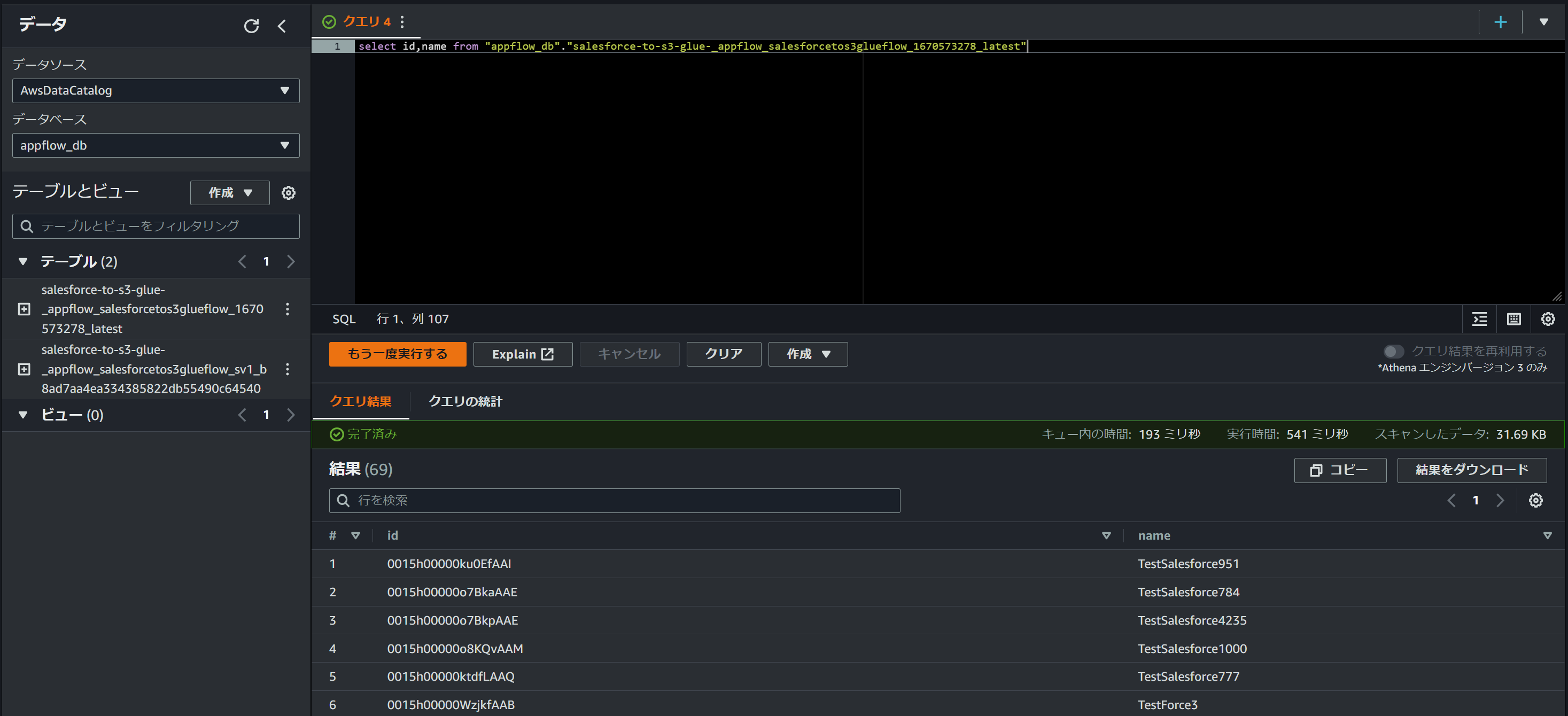
Athenaからもクエリすることができました。
※ただ「select *」すると一部カラムでエラーになるので、きれいに変換できていないものもあるのかもしれません
パーティション指定実行
次はパーティションを作成するように設定して実行してみます。
また、フローも新規で作成してみて、同一データベース内にlatestを複数持つことができるのかも合わせて確認します。
尚、連携元のオブジェクトは同じものを使用します。
フロー作成・実行
Glue Data Catalogの設定は先ほどと同じように設定します。
(そういえばプレフィクスの有効文字にハイフンないけどエラーチェックされてない...バグかな?)
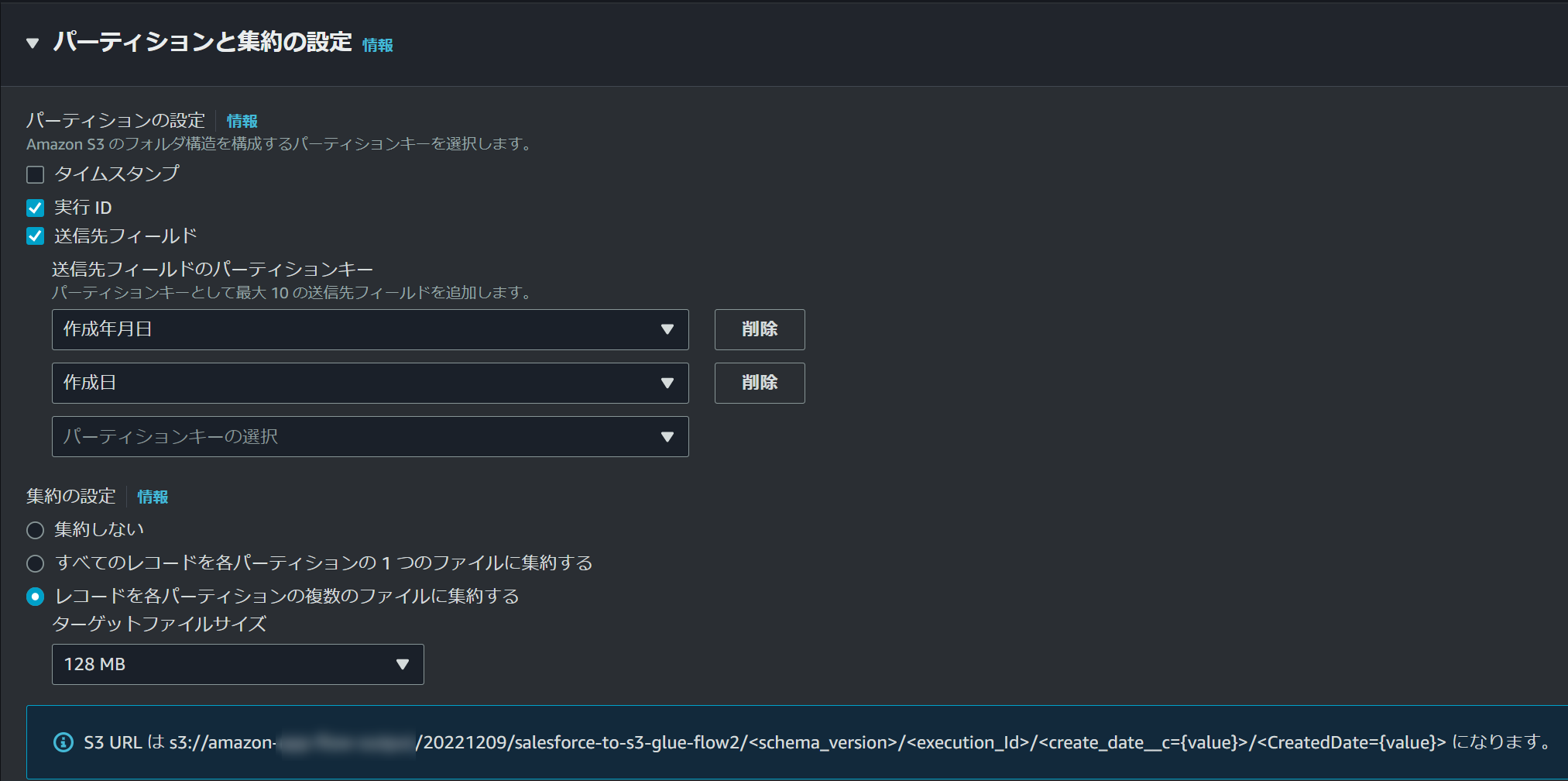
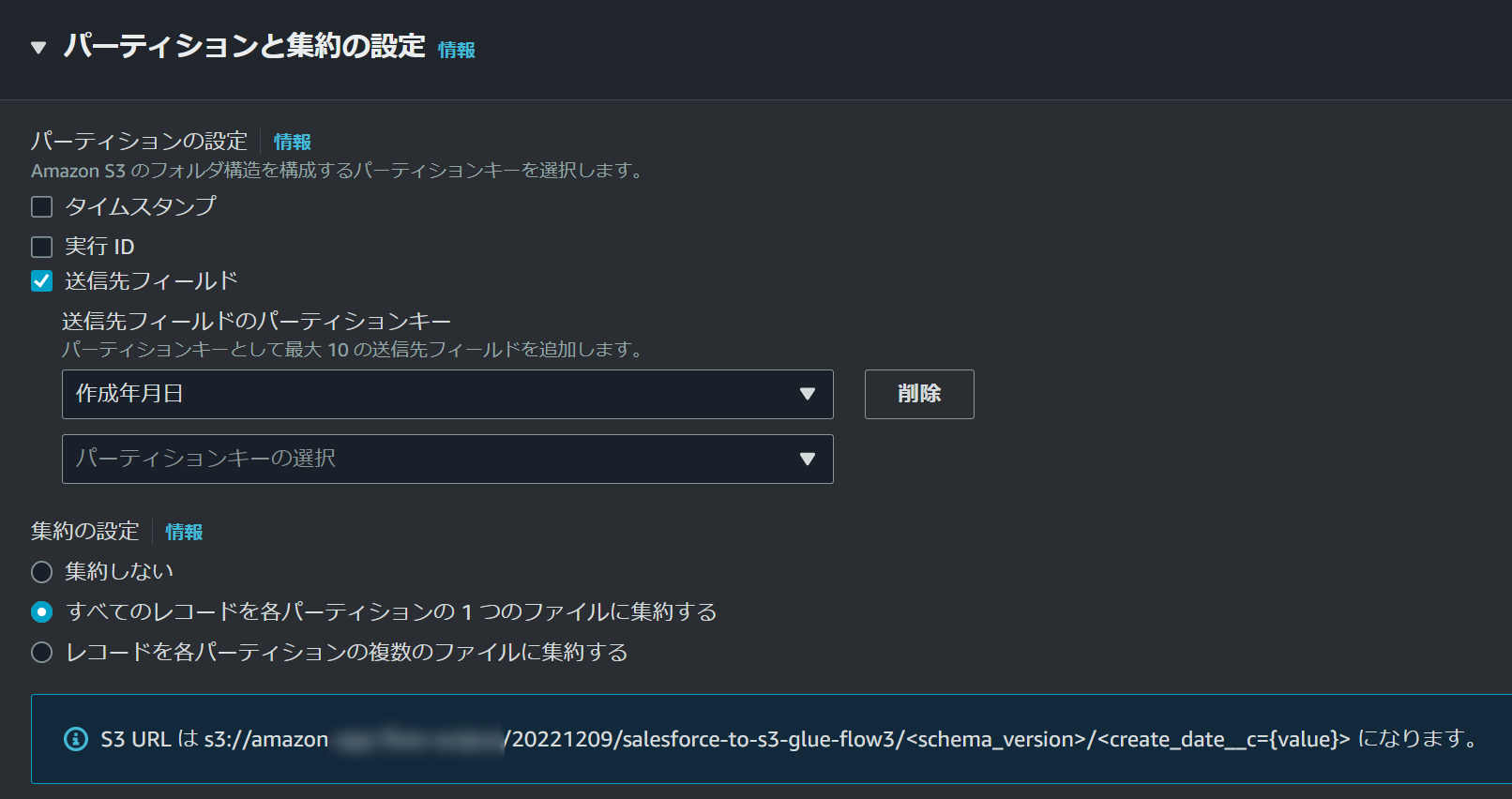
先ほどデフォルトのまま設定したパーティション設定で、送信先フィールドにチェックして、パーティションキーとして設定するフィールドを選択します。
今回はレコードの作成日時を指定したいと思いますが、以下の「作成日」フィールドは時分秒込み、「作成年月日」フィールドは時分秒なしとなっており、時分秒が含まれているフィールドが選択された場合エラーとなる現象を既に確認しています。
そのため、時分秒なしの「作成年月日」フィールドのみパーティションに設定します。
※以下のように時分秒に含まれるコロン( : )が原因で実行エラーが発生していました。
メッセージ内容からAWS側も想定していないエラーのような気もしますが、、

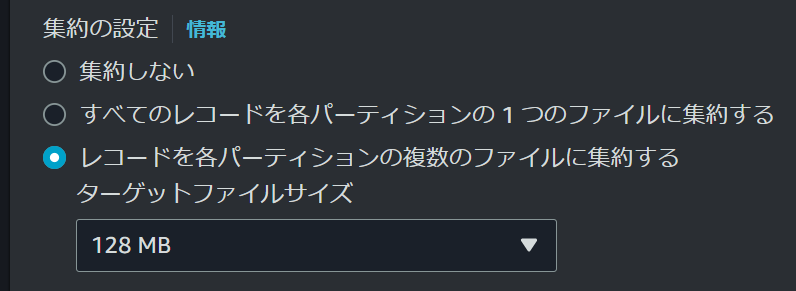
集約の設定は複数のファイルに集約するように設定します。
尚、ターゲットファイルサイズは128MB~600MBの範囲で決まったサイズを指定することができますが、理由としてこちらのページにあるようにファイルサイズが小さいことで発生する余分な時間を発生させないためのようです。
正常終了したので結果を見てみます。

結果確認
S3バケットを確認してみるとちゃんとパーティションとして認識される形でフォルダが作成されていました。
作成年月日を入れていたデータは1レコードだけだったので、想定通り出力されているようです。
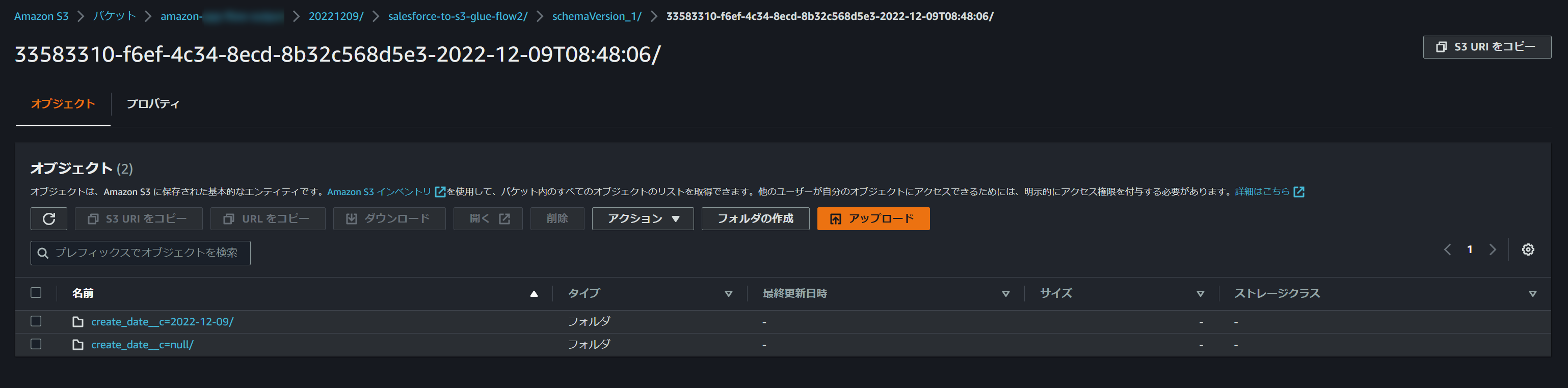
続いてGlueのData Catalogから確認してみました。
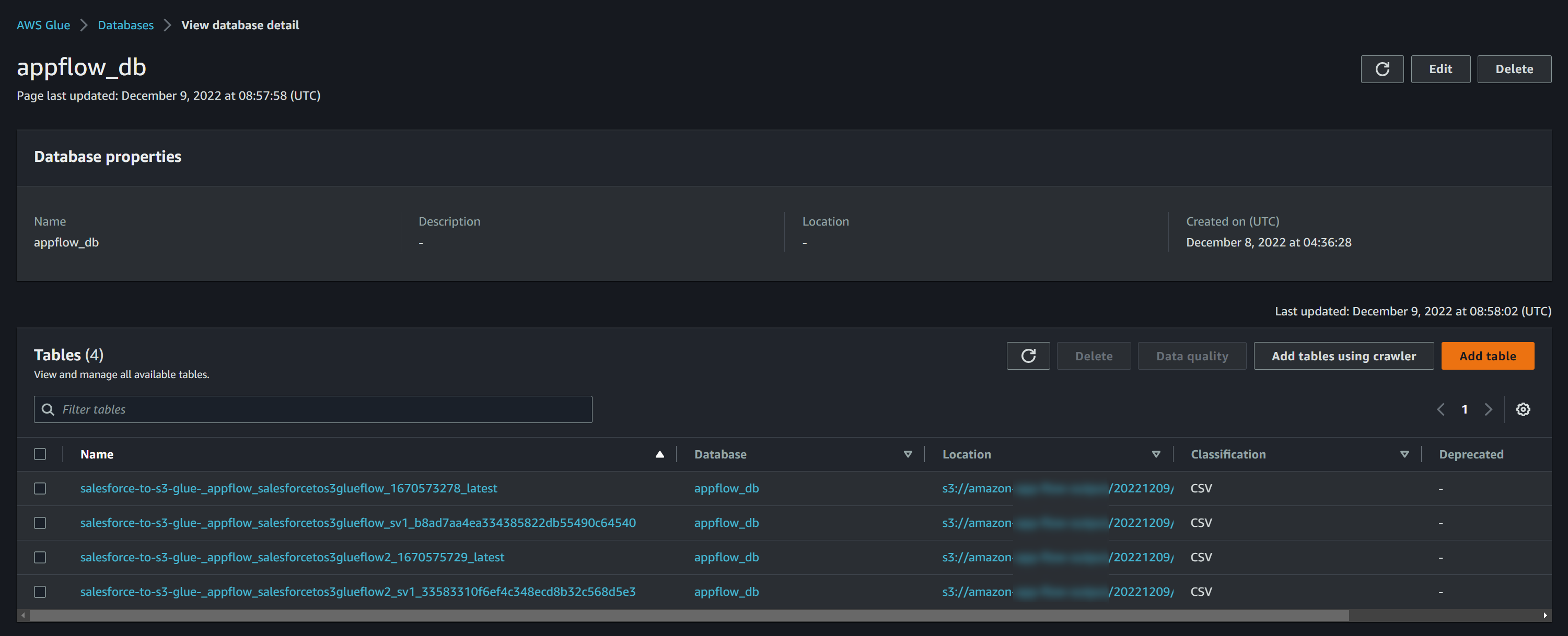
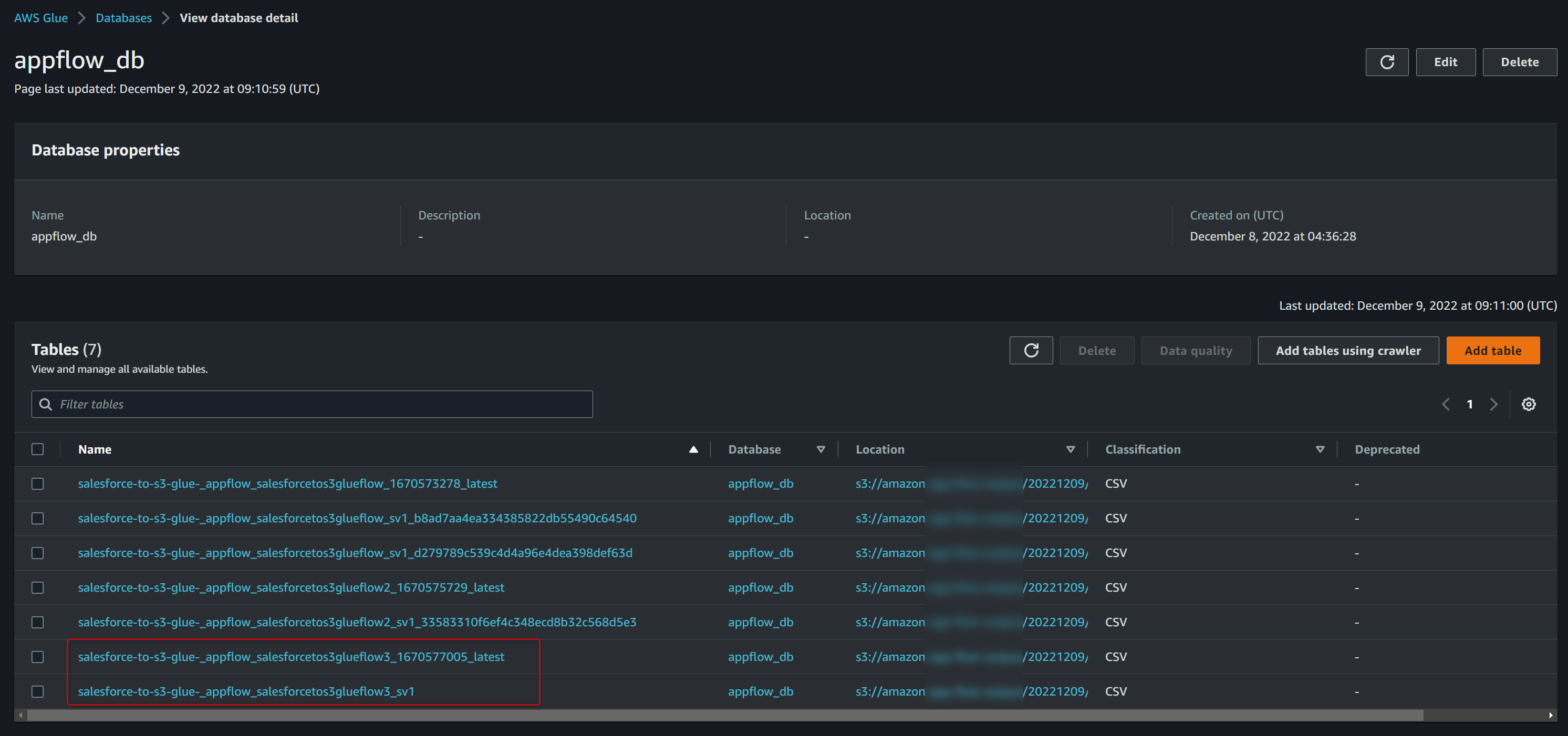
latestが付いているテーブルが複数あることから、latestテーブルはAppFlowのフロー毎に定義されるようになっているみたいです。
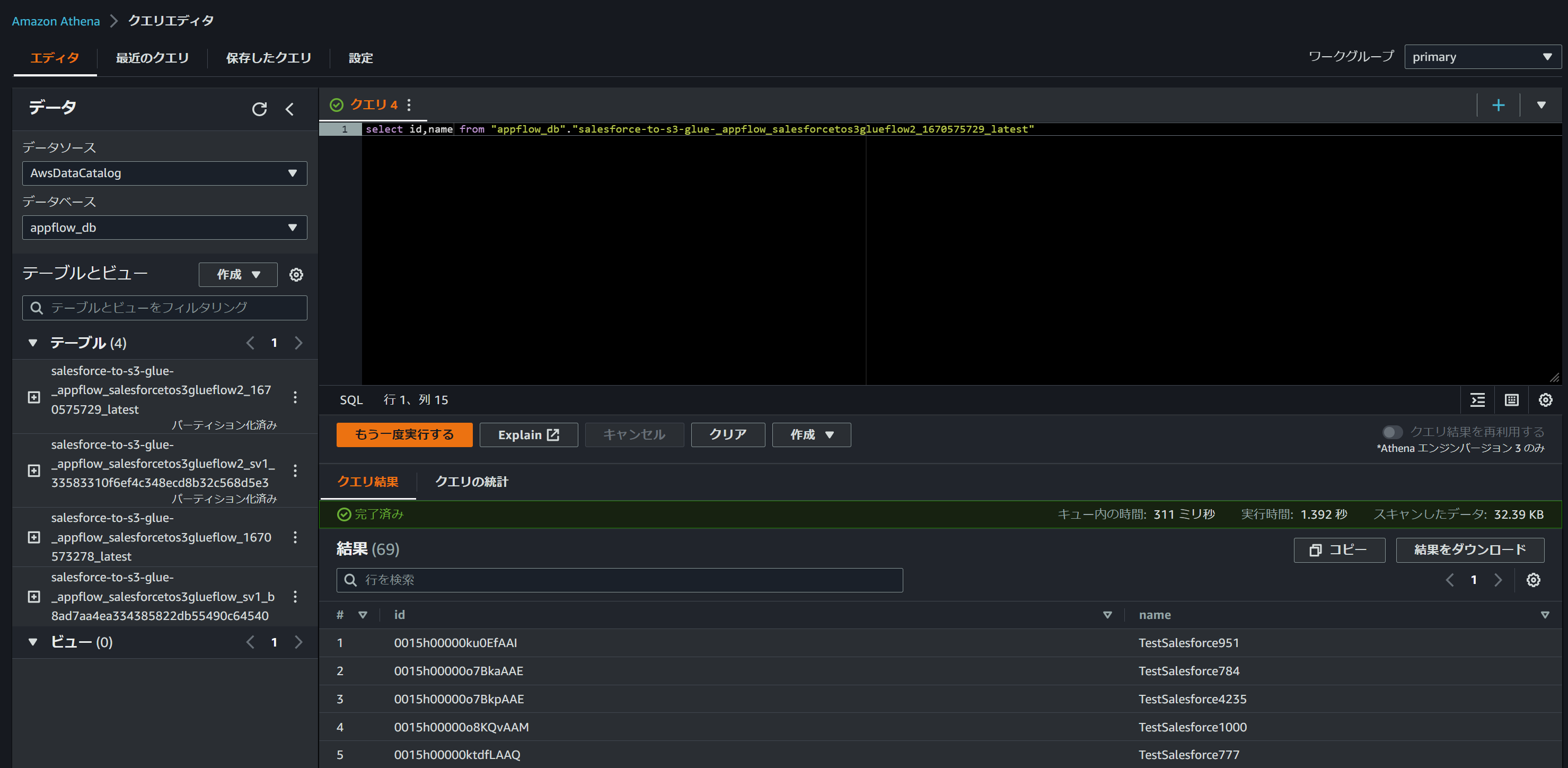
Athenaからも正常にクエリすることができました。
おまけ1:同じフローを複数回実行するとGlueテーブルはどうなるのか?
試しに同じフローを複数回実行してみると、新しい実行IDのテーブルが1つ増えてました。
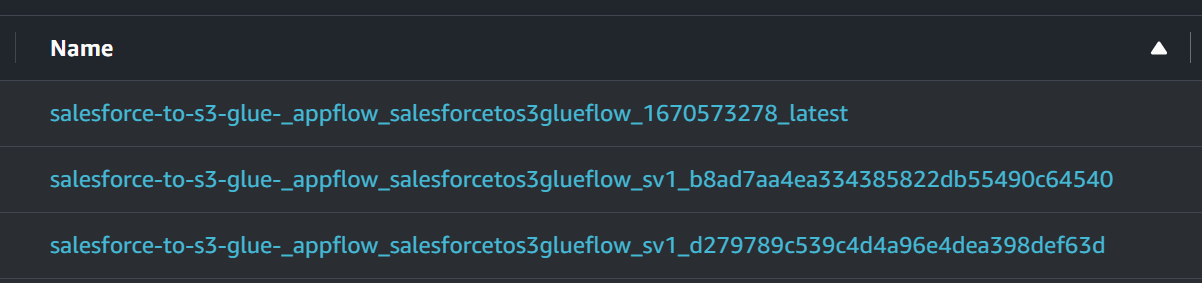
latest付きのテーブルを見てみると、LocationのS3パスが最後に実行された実行IDを指していたので、1回目のGlue結果のところで記載した以下の内容は正しそうです。
恐らくlatestテーブルは常に最新のデータの情報が登録されるようになっており、古いデータを見たい場合はlatestが付いていないテーブルを直接参照することができるようになっているのだと思われます
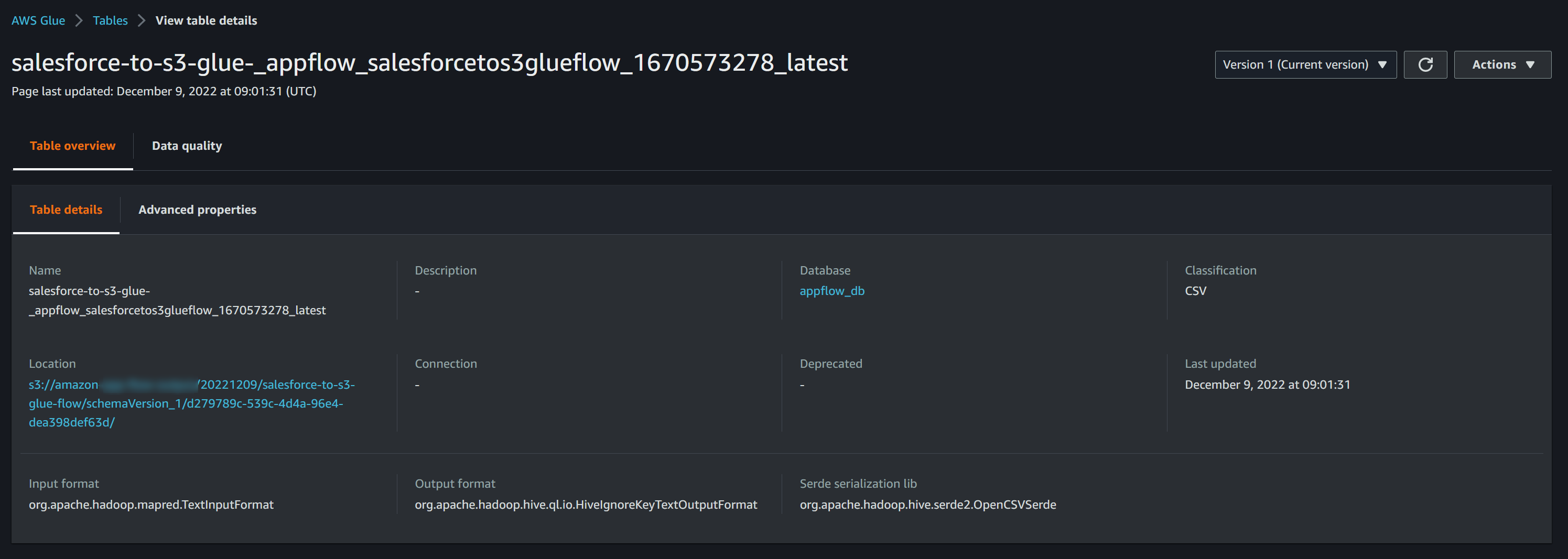
おまけ2:実行IDを指定しないとき、S3パスとGlueのテーブル名はどうなるのか?
以下の設定で実行IDのチェックを外してフローを実行してみます。
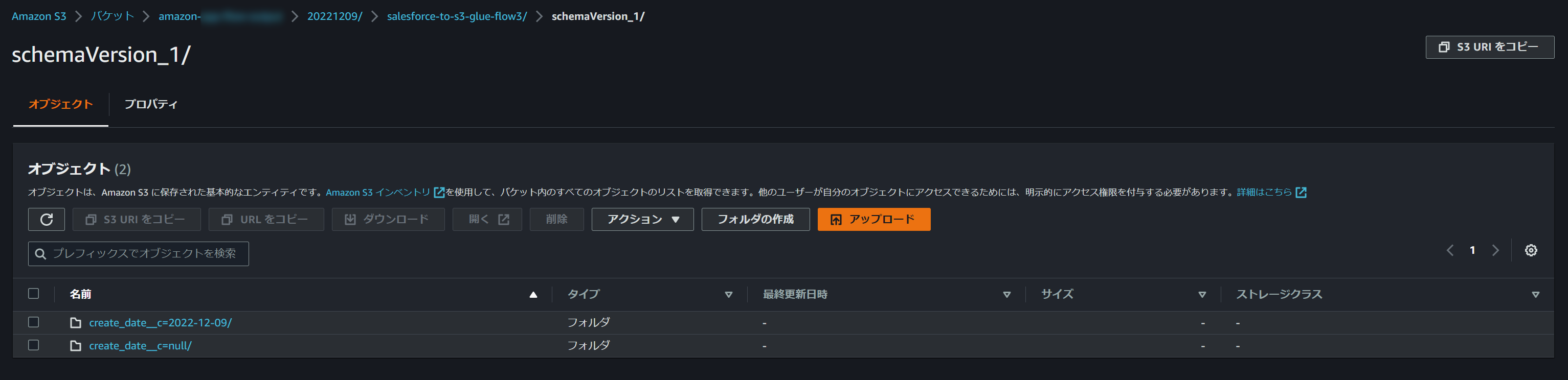
S3パスからは実行IDがなくなりました。
Glueのテーブル名からも実行IDがなくなりました。
この場合、実行する度にクローリングされるS3パスが変わらないため、フローを実行する度に実行IDが含まれたGlueのテーブルが増えていくということはなくなります。
ただ、AppFlowフロー側で差分連携をするように設定されておらず、毎実行で全データを連携するようになっている場合、S3バケット上にはファイル上書きではなく別名で保存されるため、クローリングされた先のGlue/Athenaでクエリする際に同じデータが重複表示されるため注意が必要です。(以下同じデータが別ファイルで格納される例)
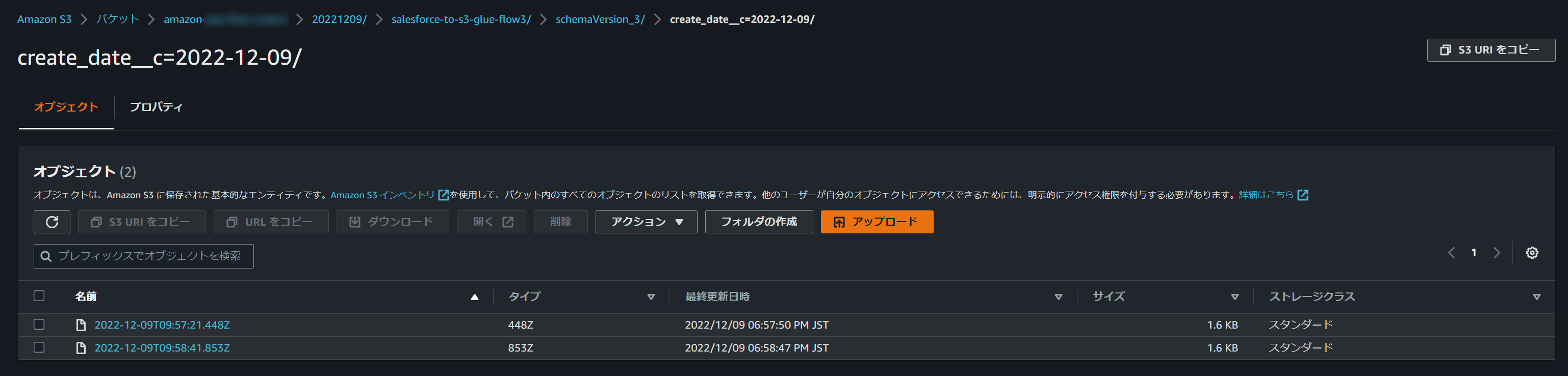
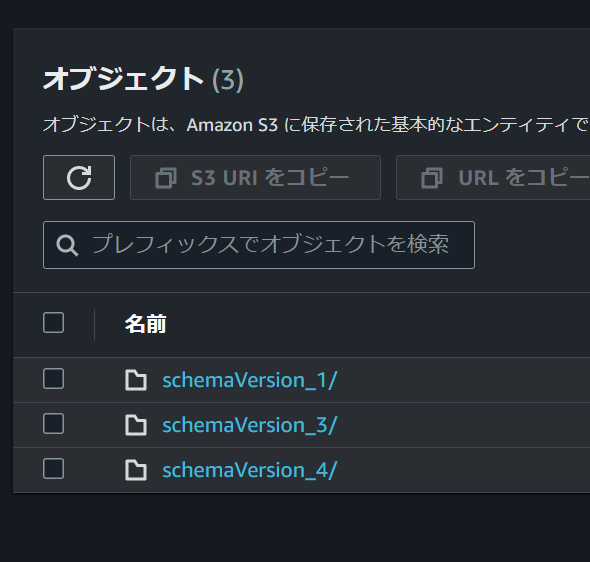
実行ID以外にもGlueのテーブル名にはスキーマバージョン名(sv1やsv2など)も含まれており、AppFlowのフローのフィールドマッピングを更新した場合などに自動でカウントアップされるため、その際はGlueのテーブルが増えていくような動きになっています。
おわりに
最初このアップデートを見たときはかなりいいアップデートが来たんじゃないかと思ってましたが、実際使ってみるとちょっと癖がありそうなので、利用ケースが少し限定されそうな気がしました。
マネージドサービスなので当たり前なのですが、AppFlow内の変換処理の内容がわからないので、AppFlowで変換されたけどGlue/Athena側でカラムを正しく認識できない、といったことがある可能性があります。(記事には書いてないですがありました)
簡単にデータ連携できると思ったら実はできなかった、ということがありそうなので、過去に検証した、AppFlow出力データをGlueDataBrewで変換する方法なども含めて構成を検討できると良いのではないかなと思いました。
ちなみに、GlueDataBrewで変換した際もフィールド値をパーティション設定することができるのですが、そちらでは時分秒の間のコロン( : )が原因で失敗するということはなく、エラーが出ないように自動で変換されてました。
仕組み的には近い気がするのけど、ロジックは違うみたい。。