はじめに
この記事は BeeX Advent Calendar 2020 の12/21の記事です。
==
今回は11/13に発表されたAWS Glue DataBrewを試していきます。
AWS公式の以下ドキュメントを元にして進めます。
AWS Glue DataBrewとは
AWS公式には、Glue DataBrewとは「コードを記述せずにデータをクリーンアップおよび正規化できるビジュアルデータ準備ツール」と記載されています。
簡単に言うと、今までデータ分析などで行っていた前処理をノーコードで行うことができ、かつサーバレス構成でインフラの管理もAWSに任せてしまえるサービスになります。
便利。
今回のゴール
- Glue DataBrewの操作方法が何となくでも理解できること
- チュートリアルを元に構築ができること
実際の作業
プロジェクトの作成
コンソールからプロジェクトの作成を行います。

プロジェクト名とレシピ名を入力します。
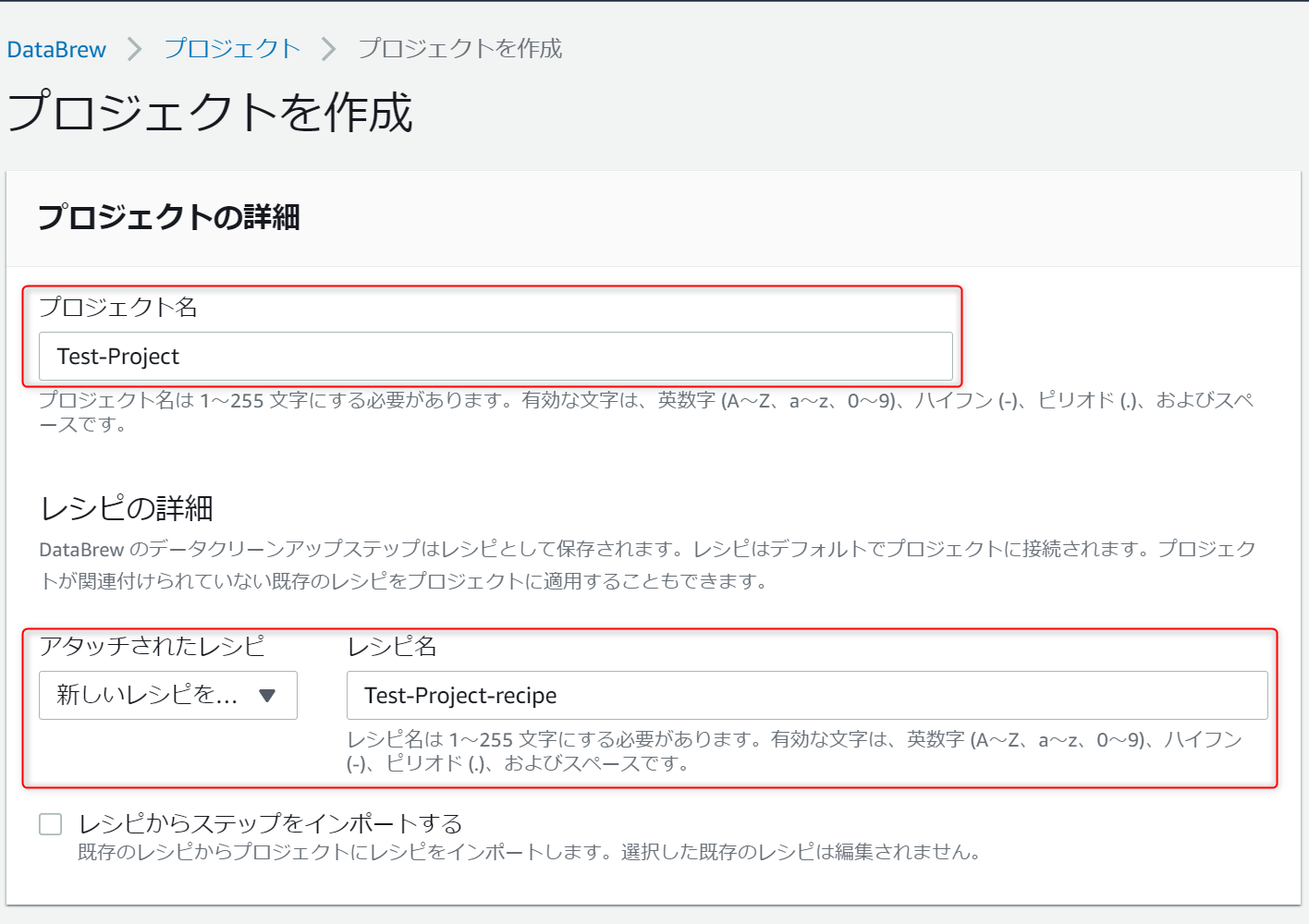
データセットは事前に準備されているサンプルファイルセットを選択します。
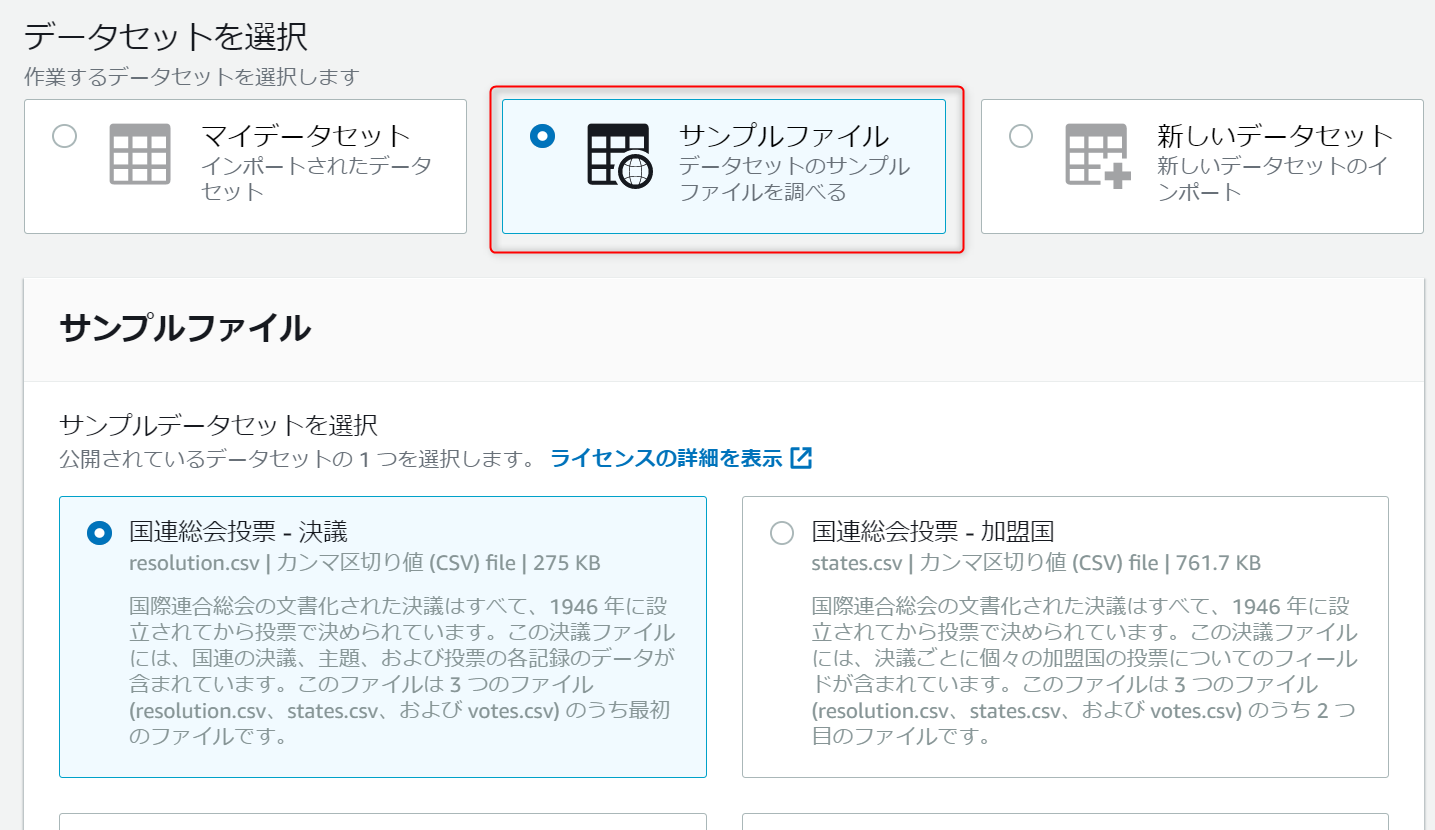
サンプルファイルは全部で7つ選択可能です。

今回は「有名なチェスゲームの動き」を使用します。
データセット名はサンプルを選択したら設定されていました。

IAMロールは事前に作っておいたものを設定し、プロジェクトを作成します。
オプションは未設定状態にしておきます。
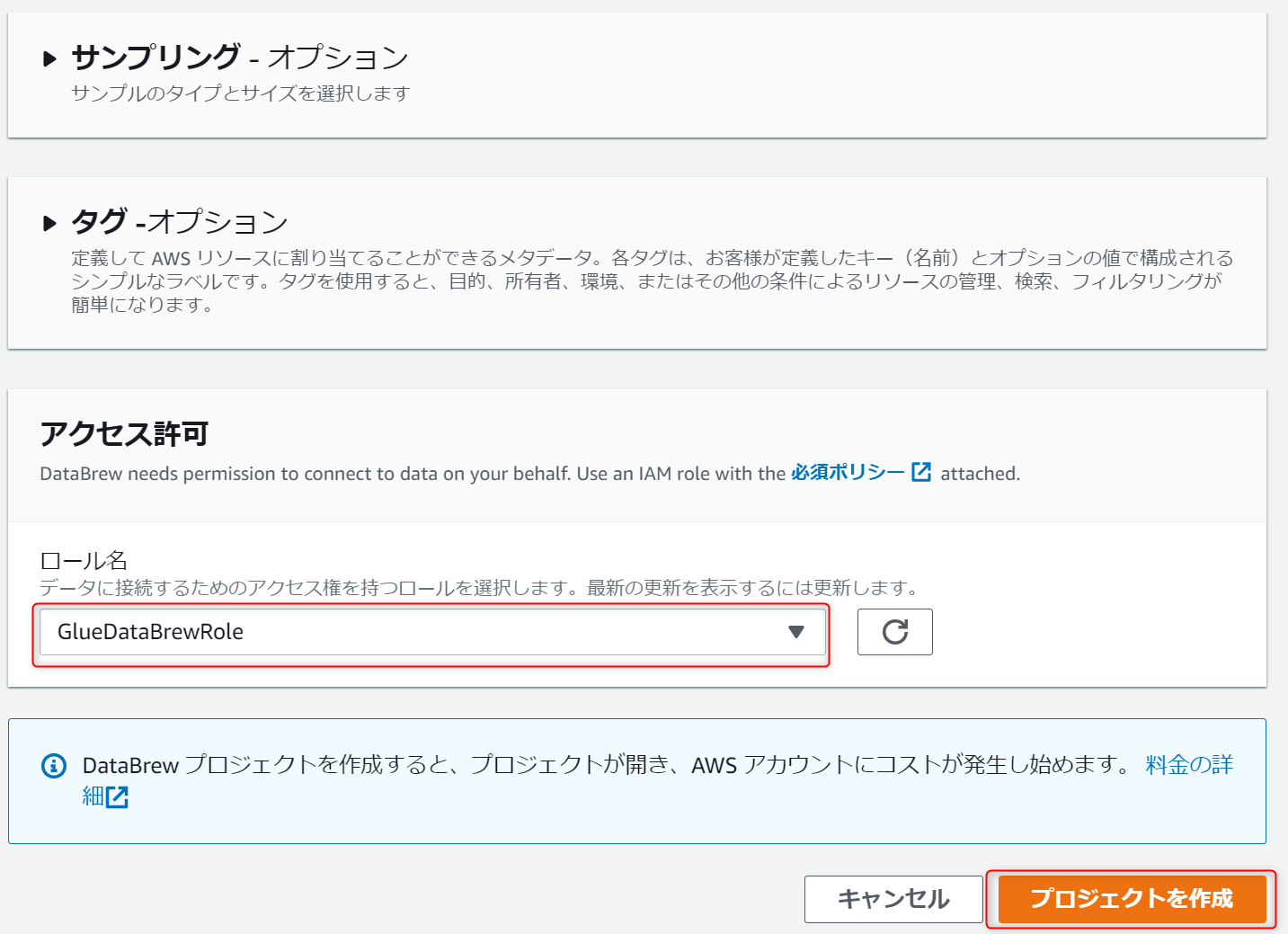
アクセス許可で設定しているIAMロールの権限はこちらです。
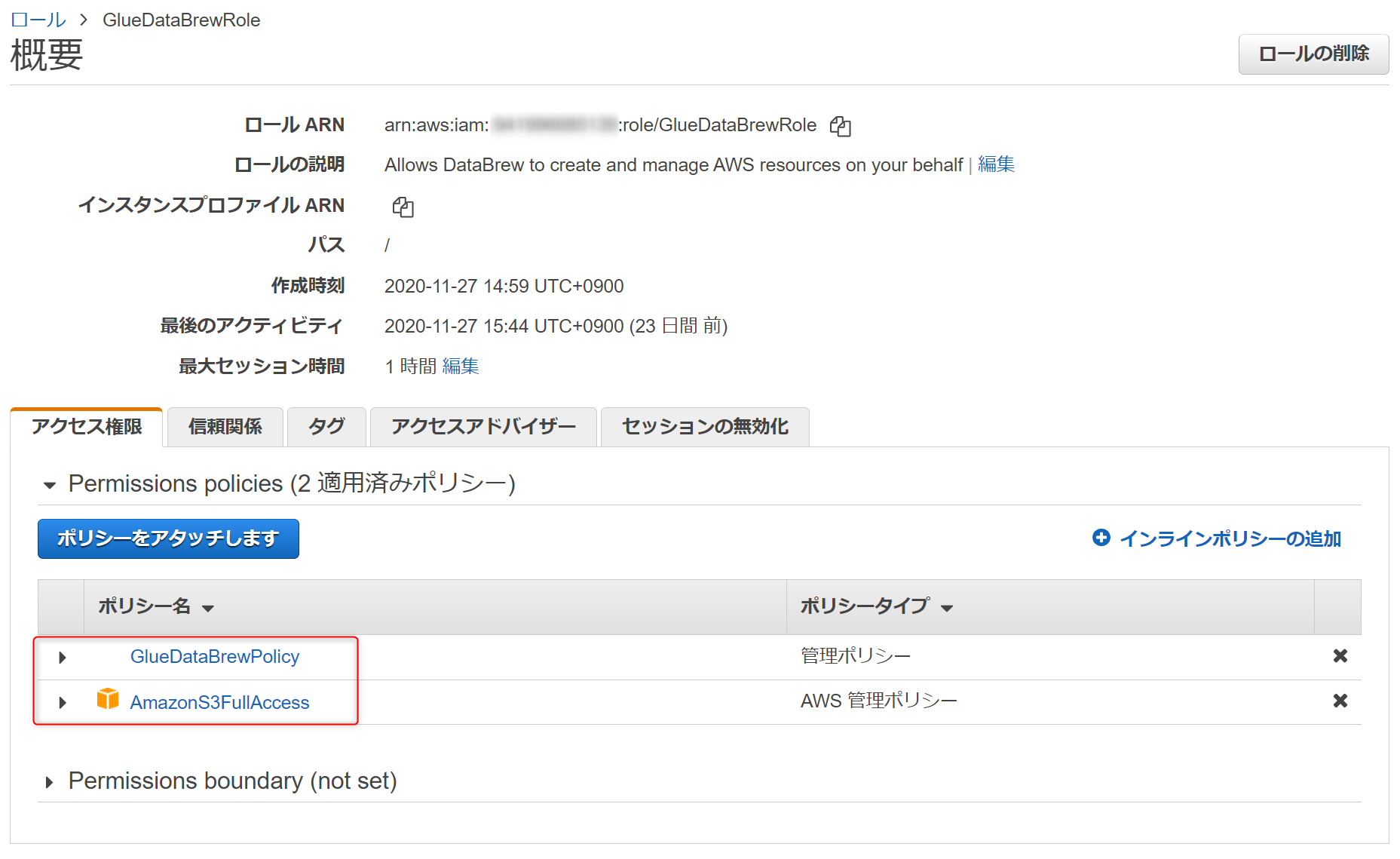
権限は以下を参照して作成しています。
作成確認
プロジェクトを作成するとプロビジョニングが開始されます。
プロビジョニングが完了するとサンプルデータが表示されます。
データの要約
サンプルプロジェクトができたらDataBrewレシピを作成します。
このレシピとは、元となるデータセットに対して適用可能な変換処理がまとめられたもので、作成後公開することで使用することができます。
公式では以下のような条件になるように設定します。
このチュートリアルでは、両方のプレイヤーがクラス A のゲームのみに焦点を当て、その評価が 1800 以上であることを意味します。
この評価というものがどういうものかはよくわかっていないですが、以下のWikiを見る限り「Rating range」が1800~1999の場合がクラスAになるようです。
Chess rating system
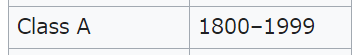
フィルタ設定
まずはデータのフィルタを行っていきます。
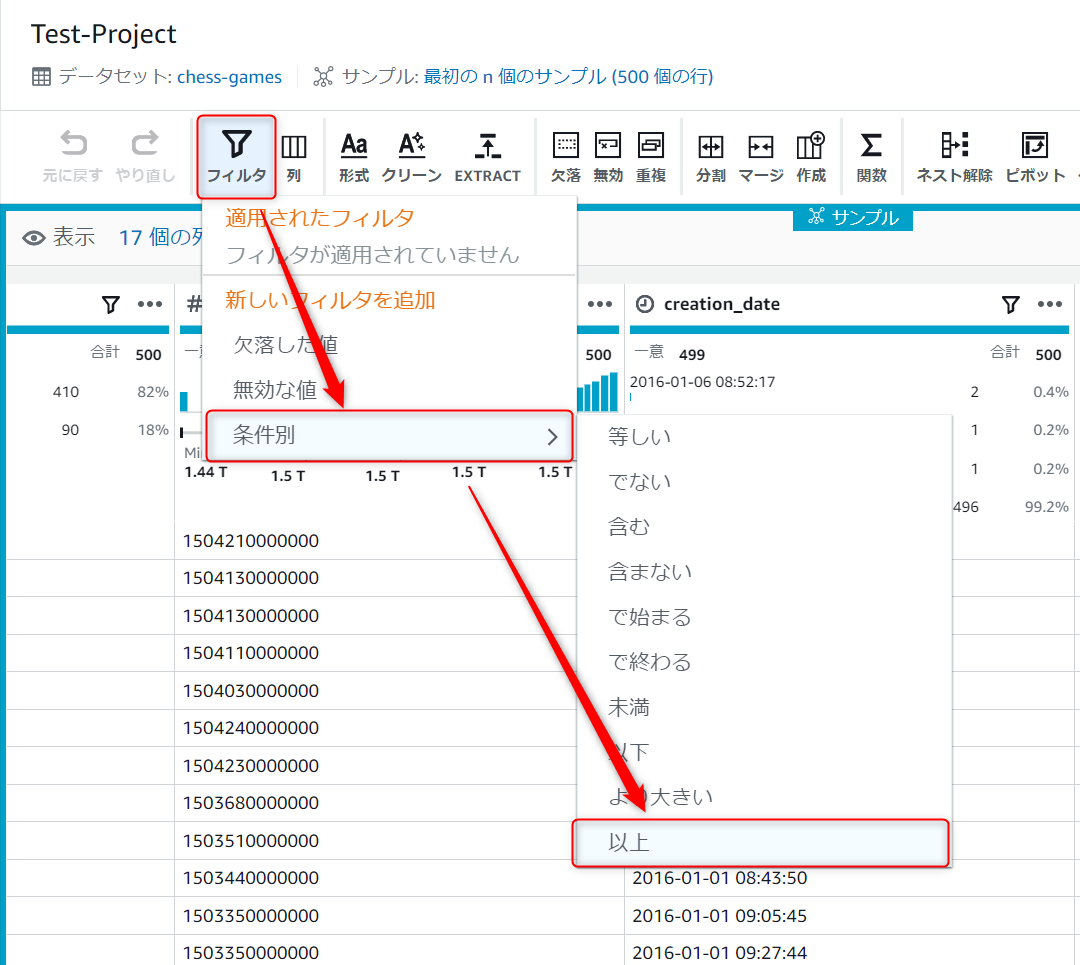
[フィルタ]→[条件別]→[以上]を選択します。
その後右側に詳細を入力する画面が表示されるので、ソース列に[white_rating]、フィルタ条件に[1800]を入力して適用ボタンを押下します。
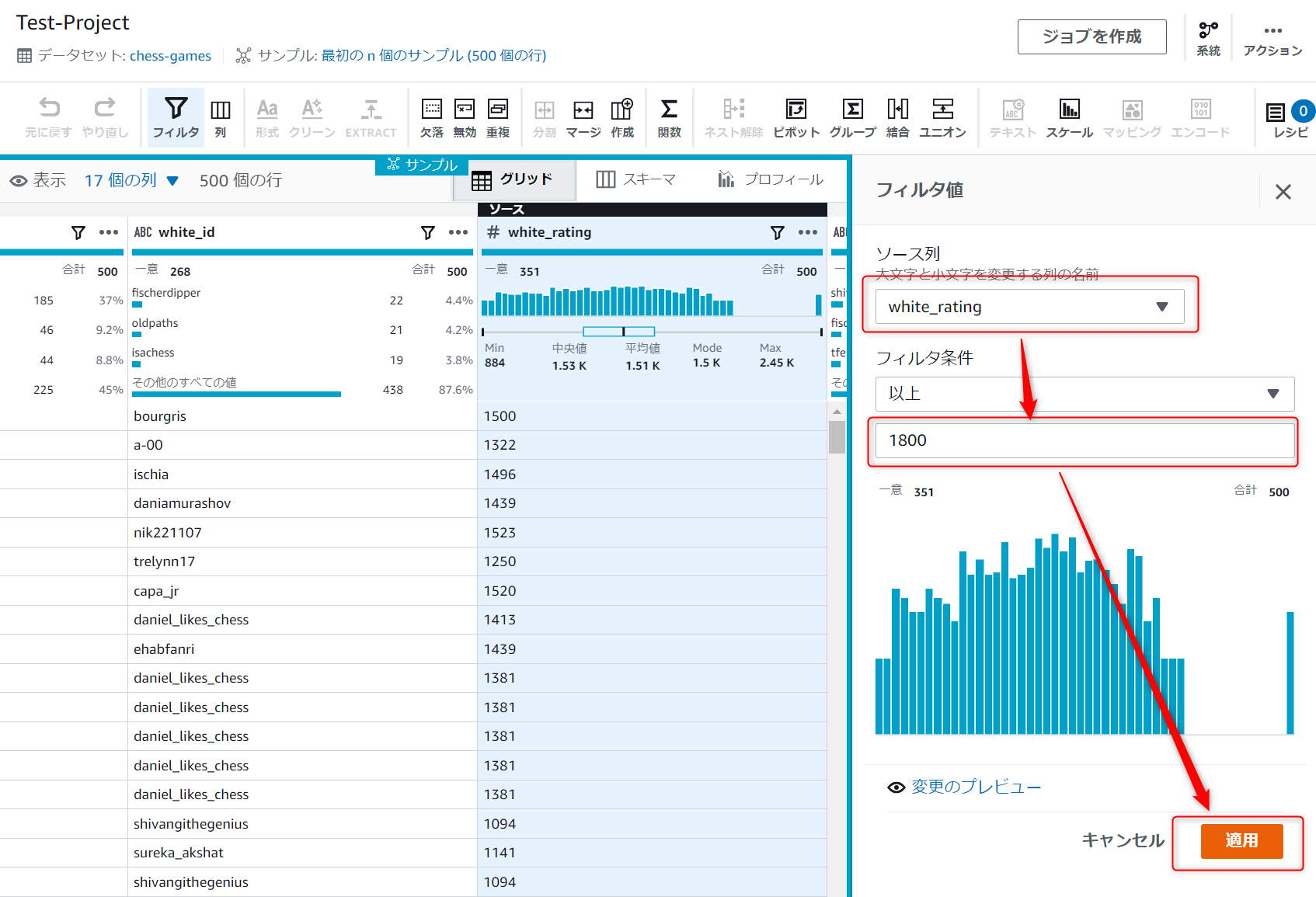
各カラムごとの値の分布を表すグラフがフィルタ条件によって少し変わりました。
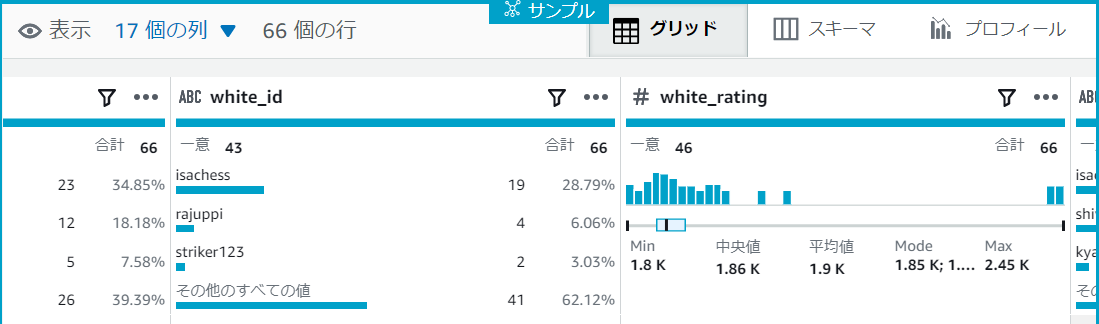
同じ手順でソース列に[black_rating]、フィルタ条件に[1800]を入力し適用ボタンを押下します。
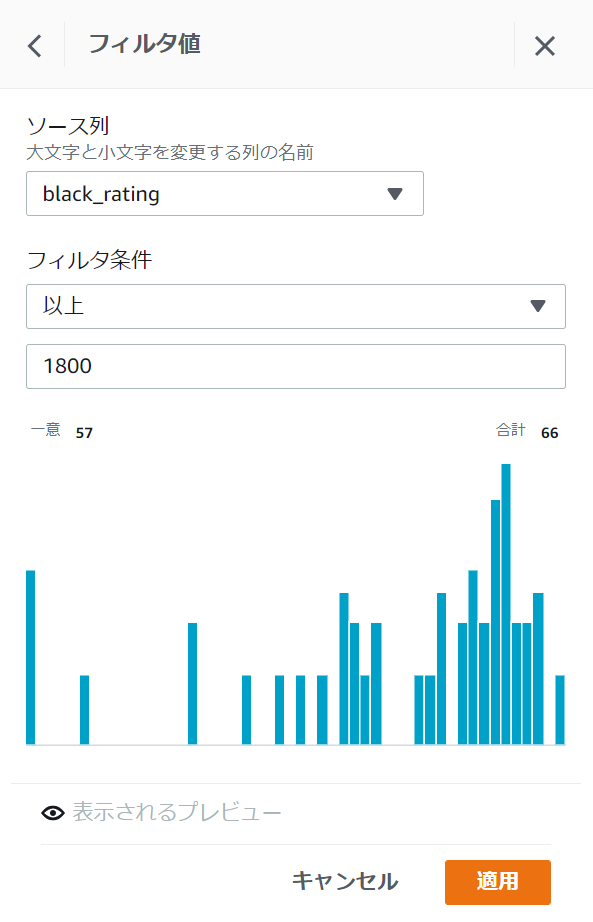
レシピの項目に先ほど設定したフィルタ値2つが表示されています。
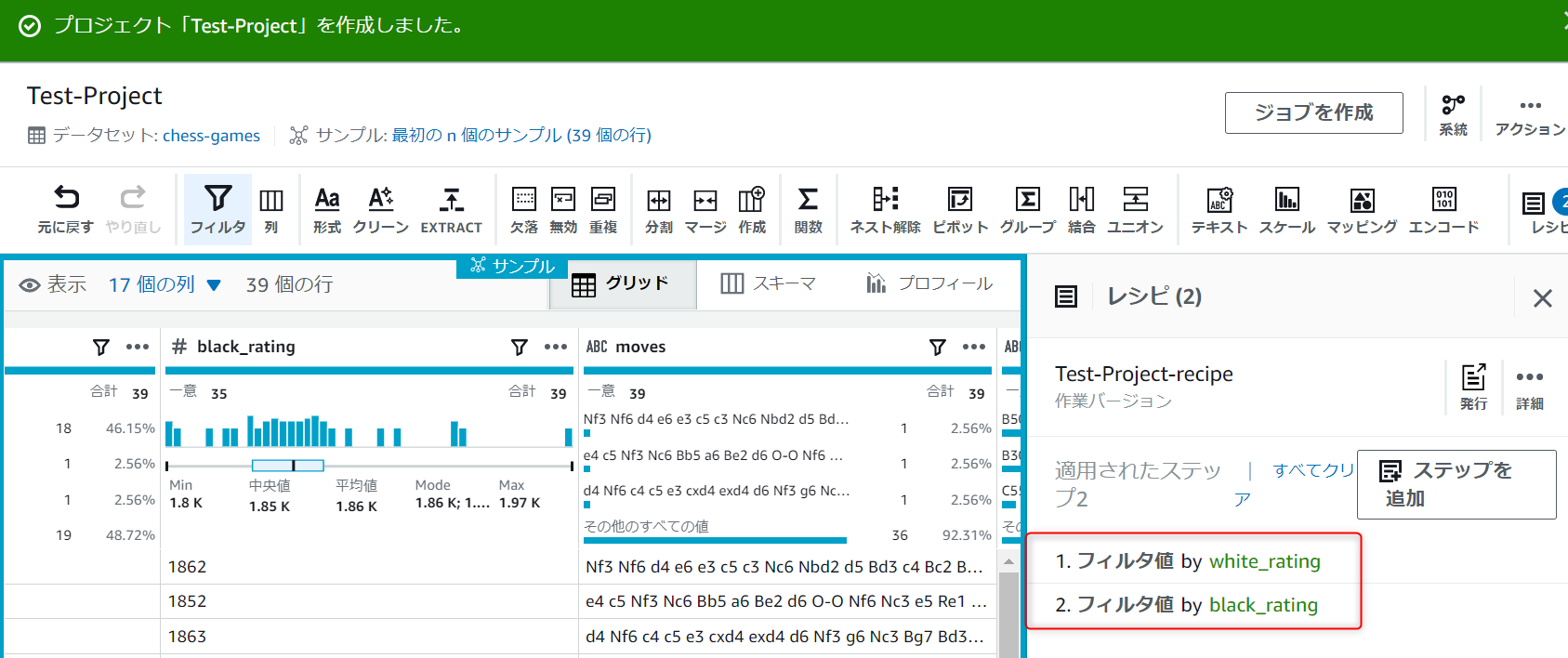
データ要約
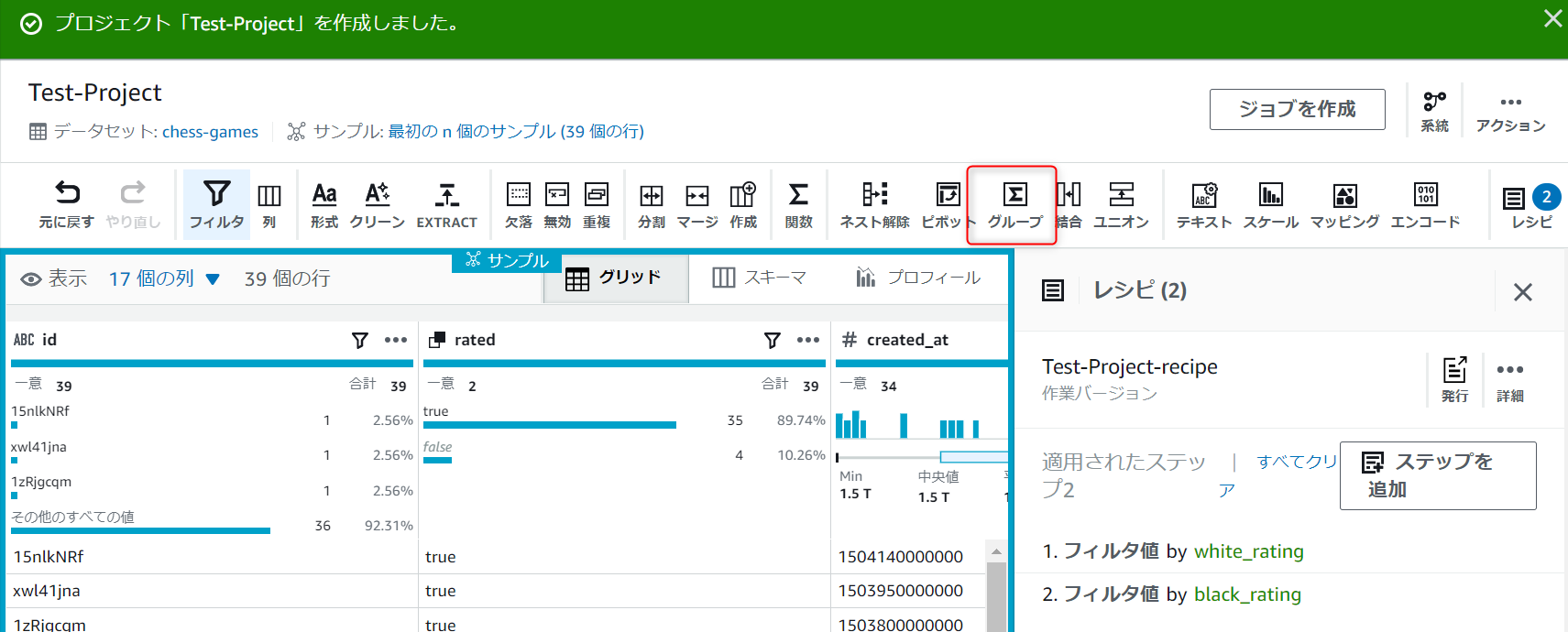
続いてデータの要約を行っていきます。
グループのアイコンを押下します。
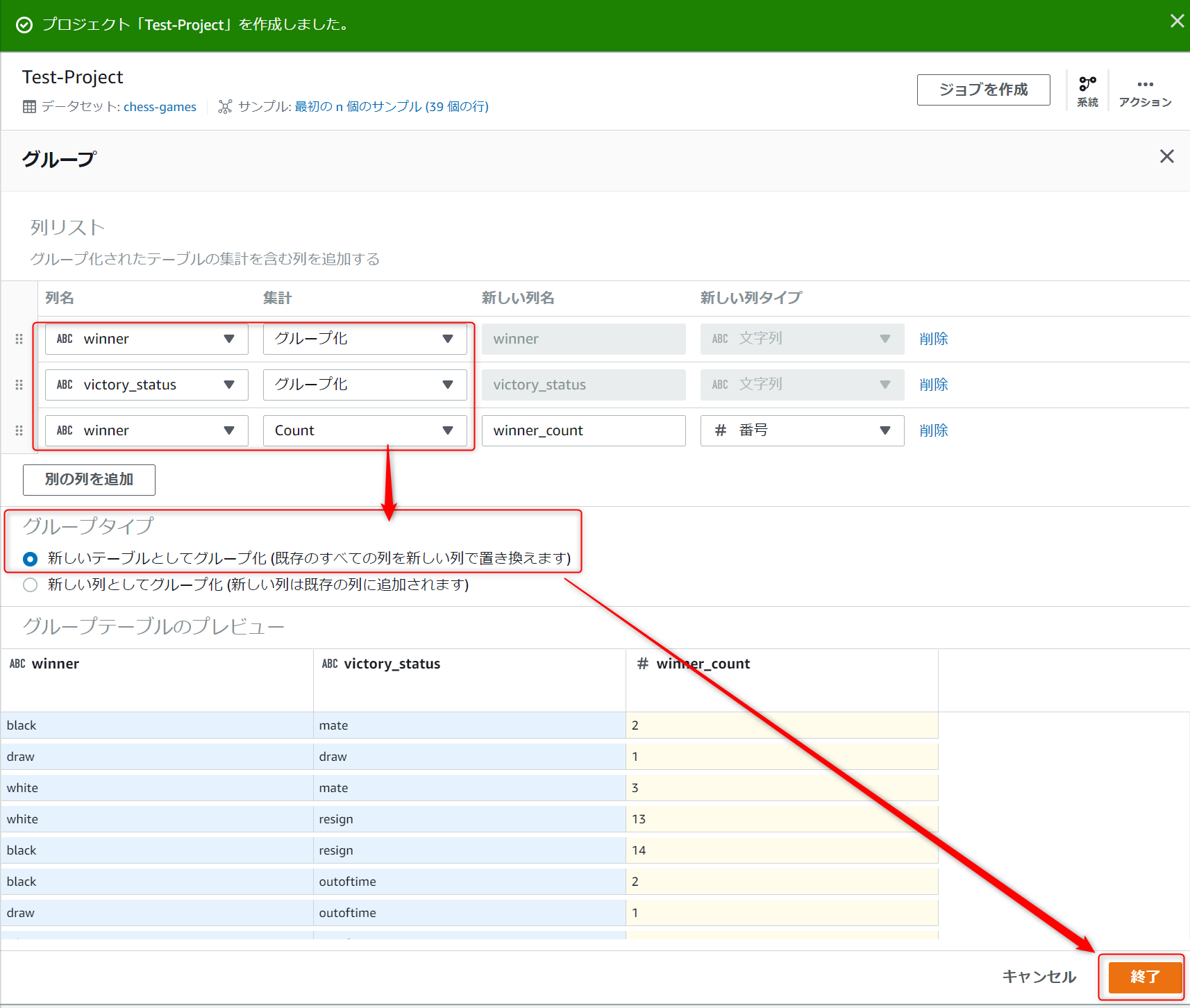
以下のようにグループプロパティを設定します。
このとき"winner"と"victory_status"は「グループ化」で設定し、[別の列を追加]ボタンから"winner"を「カウント」で追加します。
問題なければ終了を押下します。
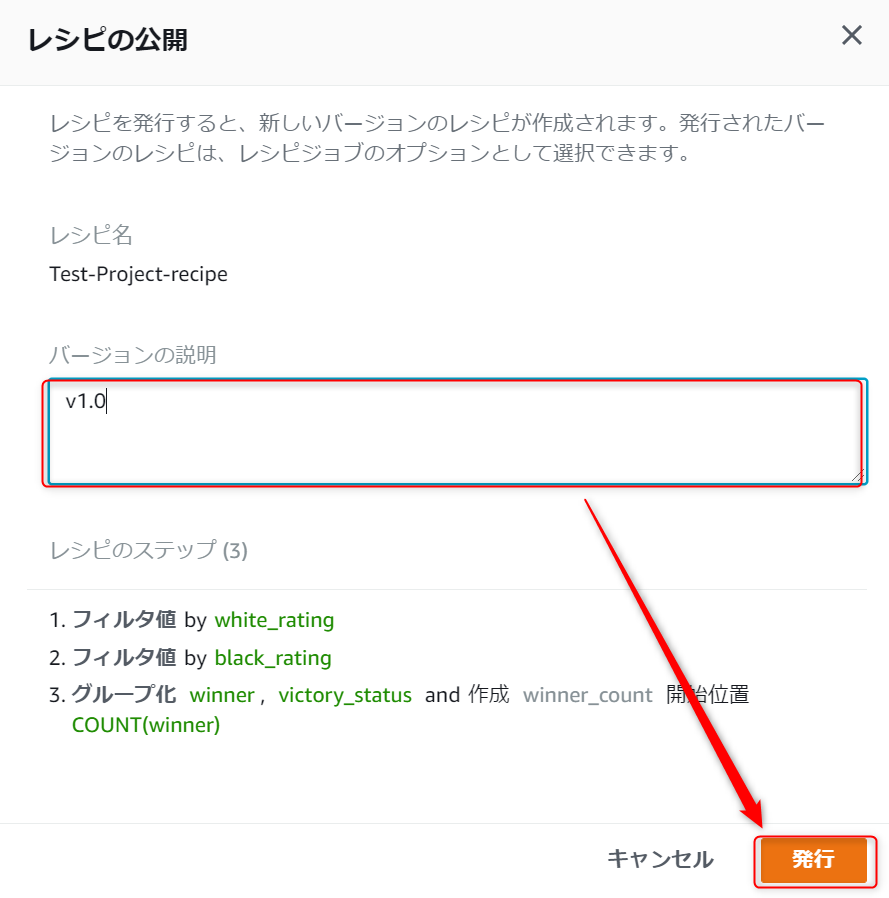
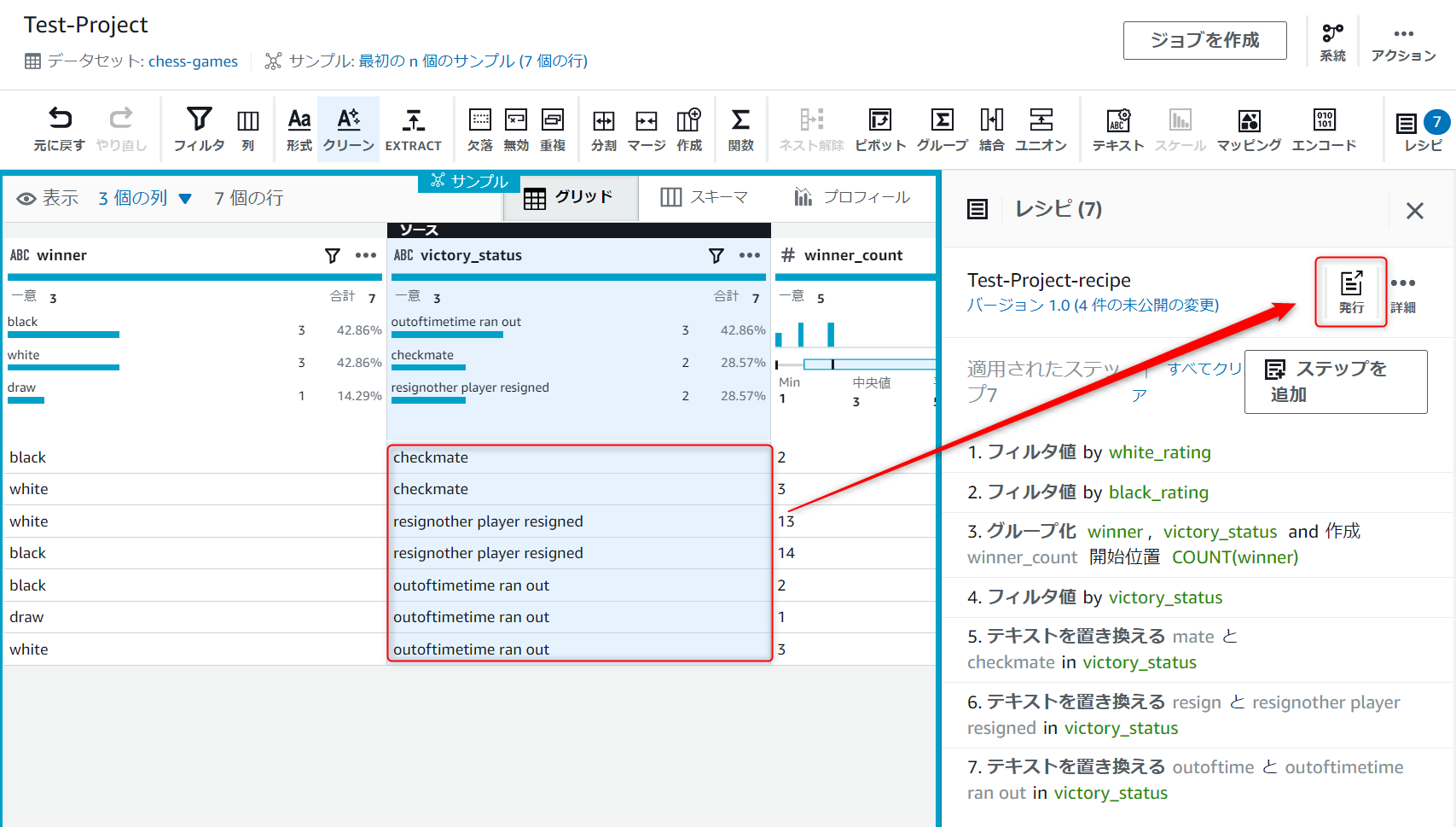
最初の画面に戻ってくるので、右側レシピの発行アイコンを押下します。
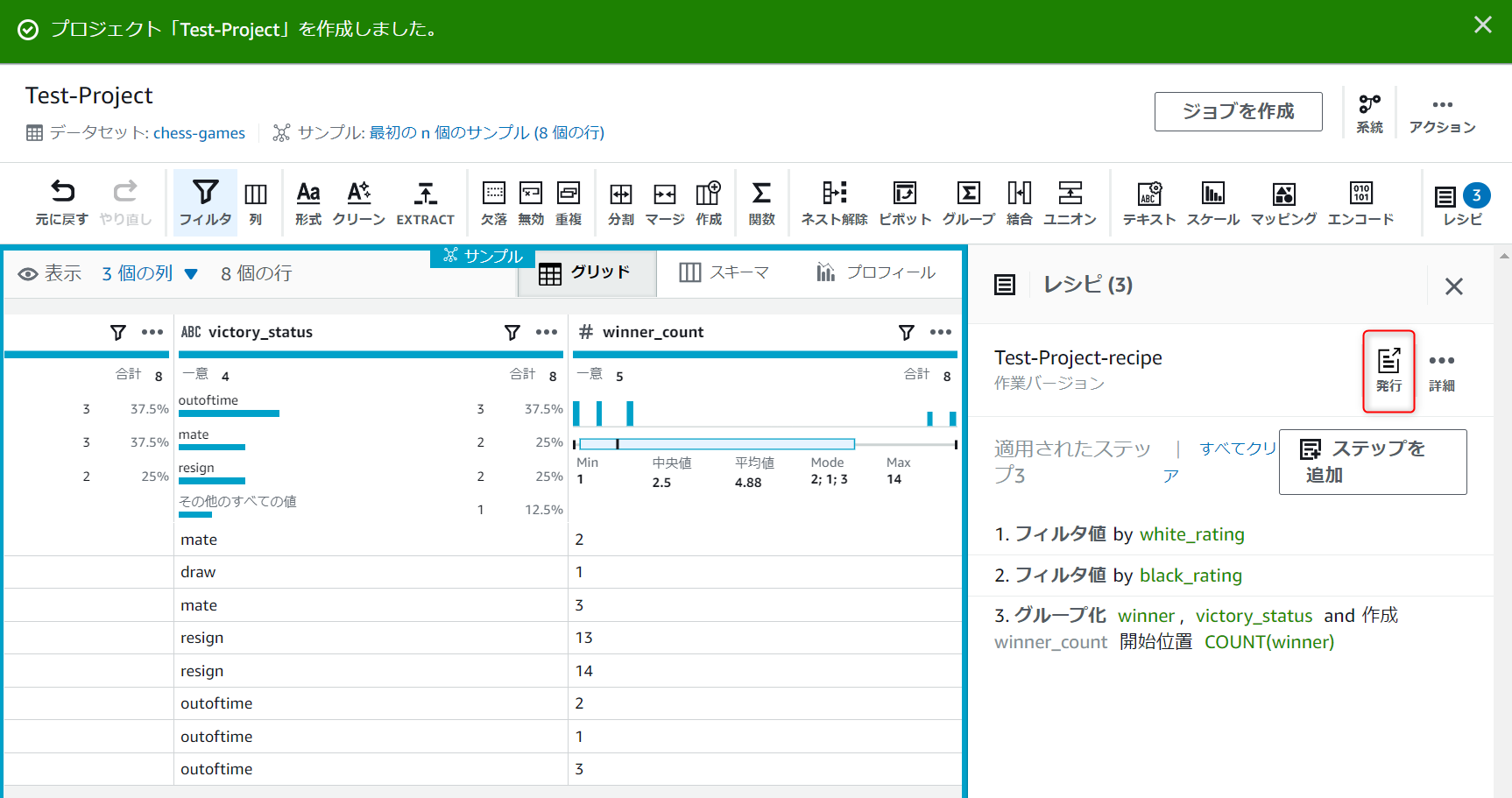
レシピの公開画面が表示されるので、適当にバージョンの説明に入力して発行ボタンを押下します。
Test-Project-recipe下にバージョン1.0と表示されていればOKです。
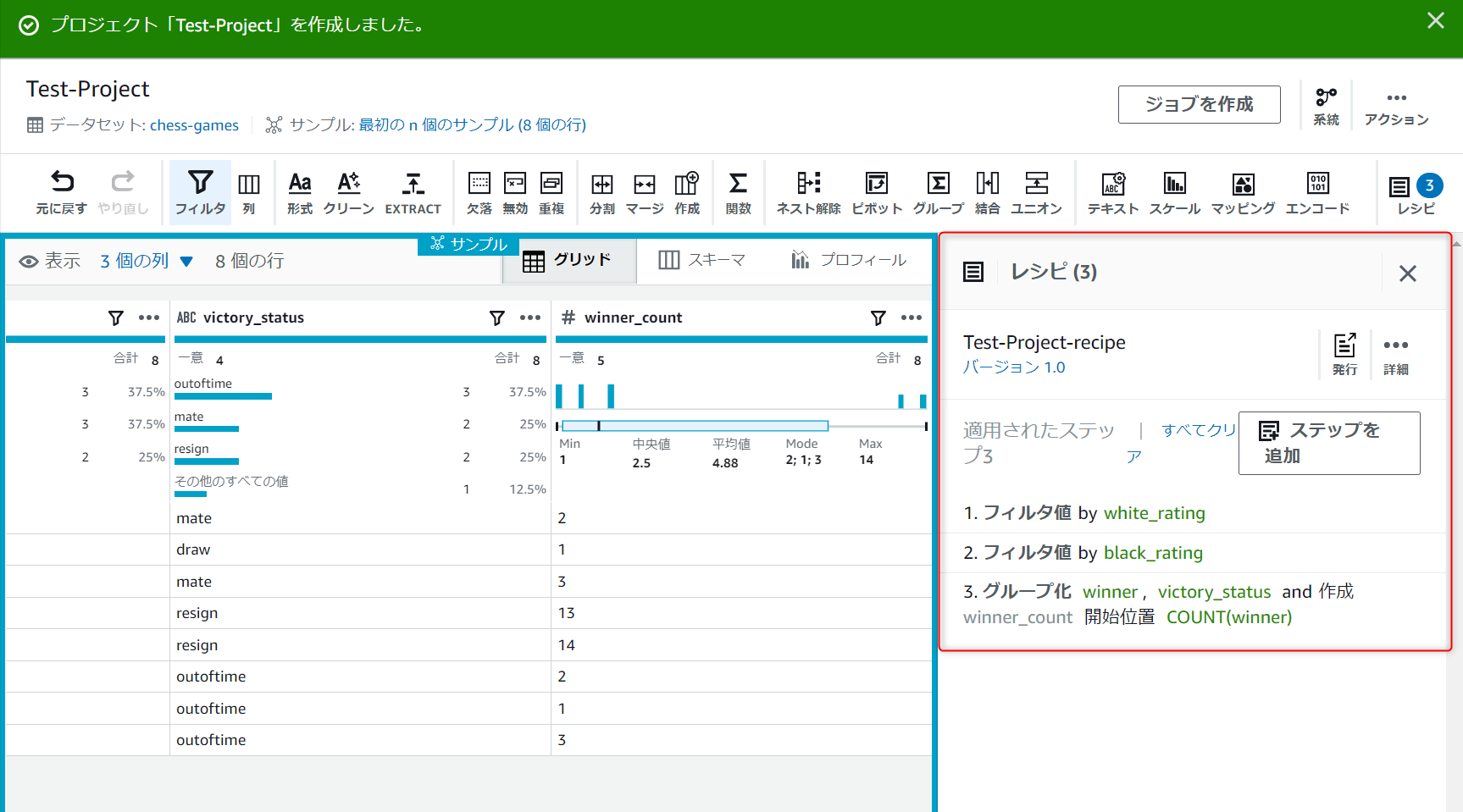
変換処理の追加
先ほどのレシピに変換処理を追加していきます。
引き分け試合の除外
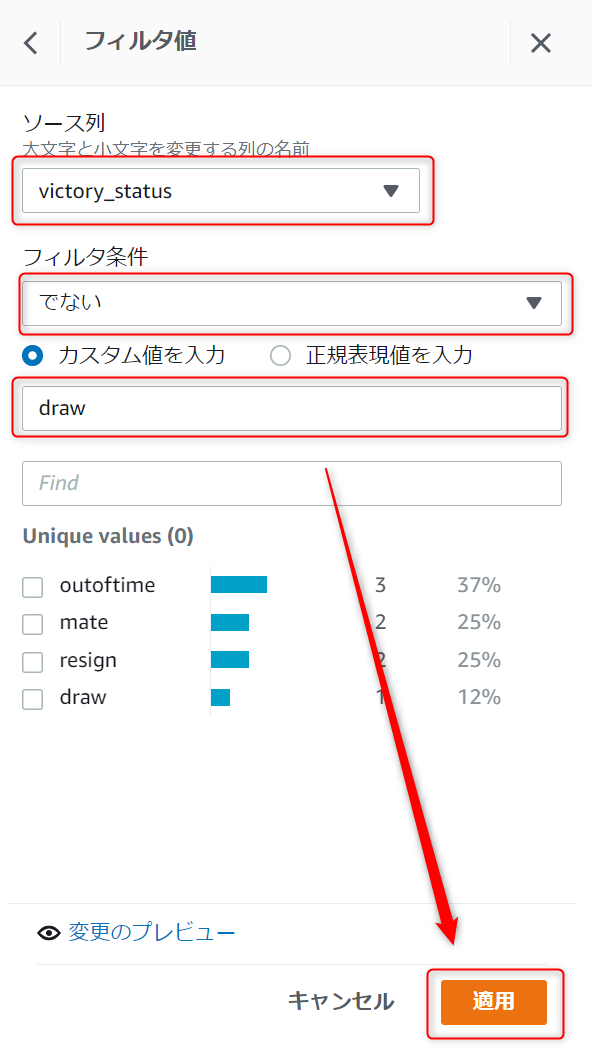
先ほどと同じ手順でフィルタ値設定画面を表示し、ソース列に[victory_status],フィルタ条件に[でない],Unique values値の[draw]にチェックを入れて適用ボタンを押下します。
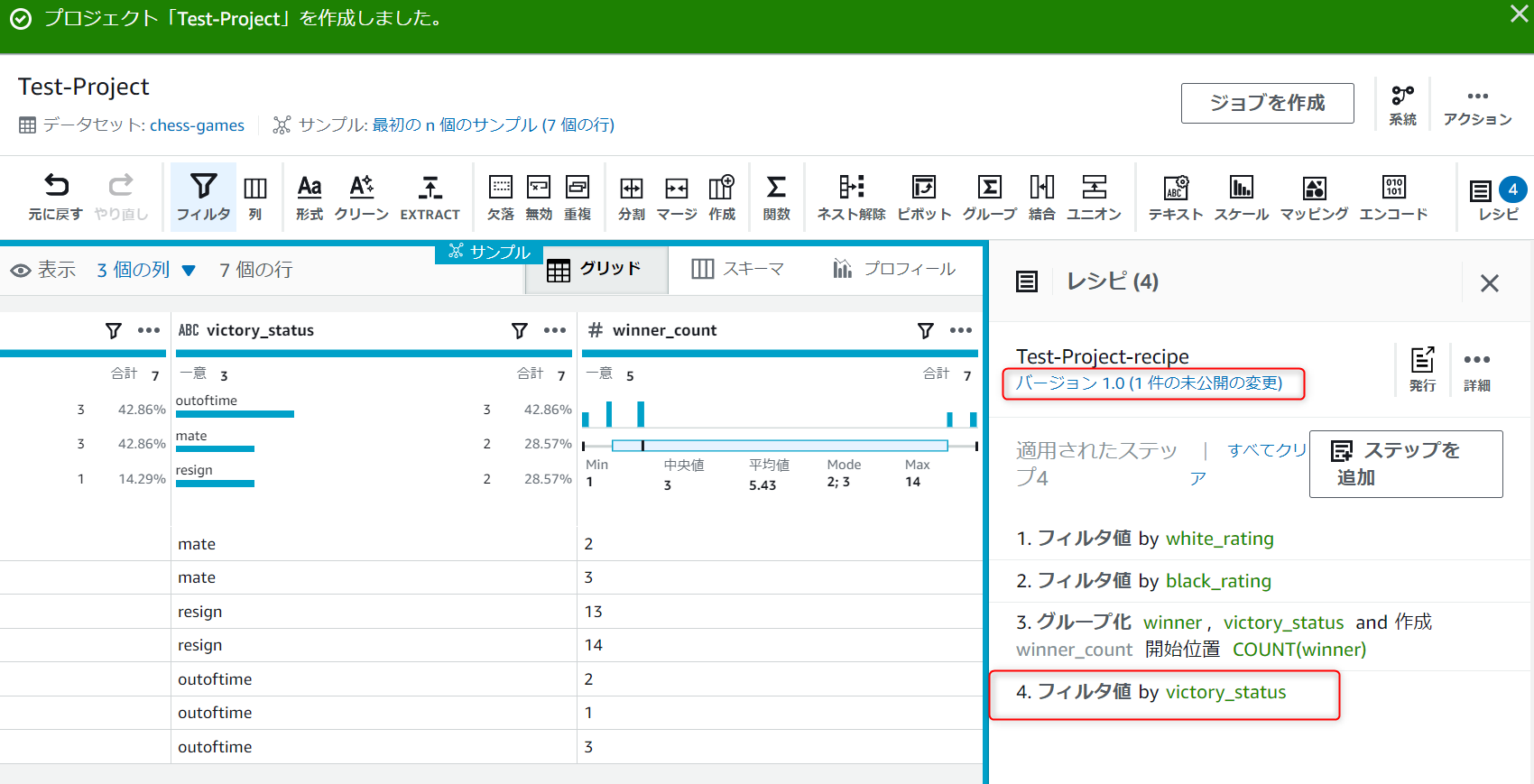
フィルタが追加され、バージョン情報の横に「1件の未公開の変更」という文字が表示されました。
値の置き換え
データの置換を行っていきます。
[クリーン]→[値またはパターンの置き換え]を押下します。
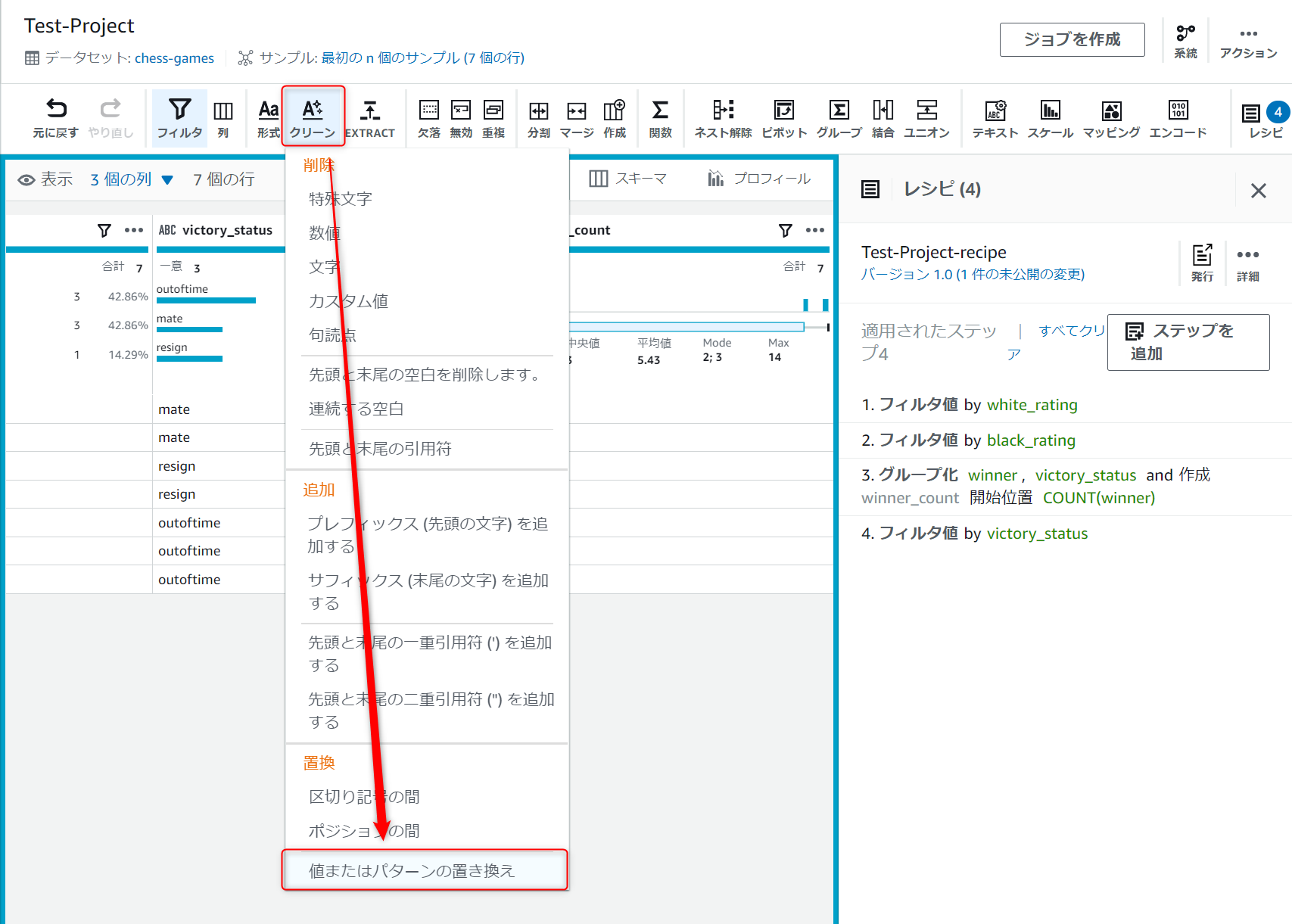
以下のように設定し、"mate"という文字列を"checkmate"に置換する設定をして、適用ボタンを押下します。
※後で気づきましたがソース列はwinnerではなくてvictory_statusが正しいです
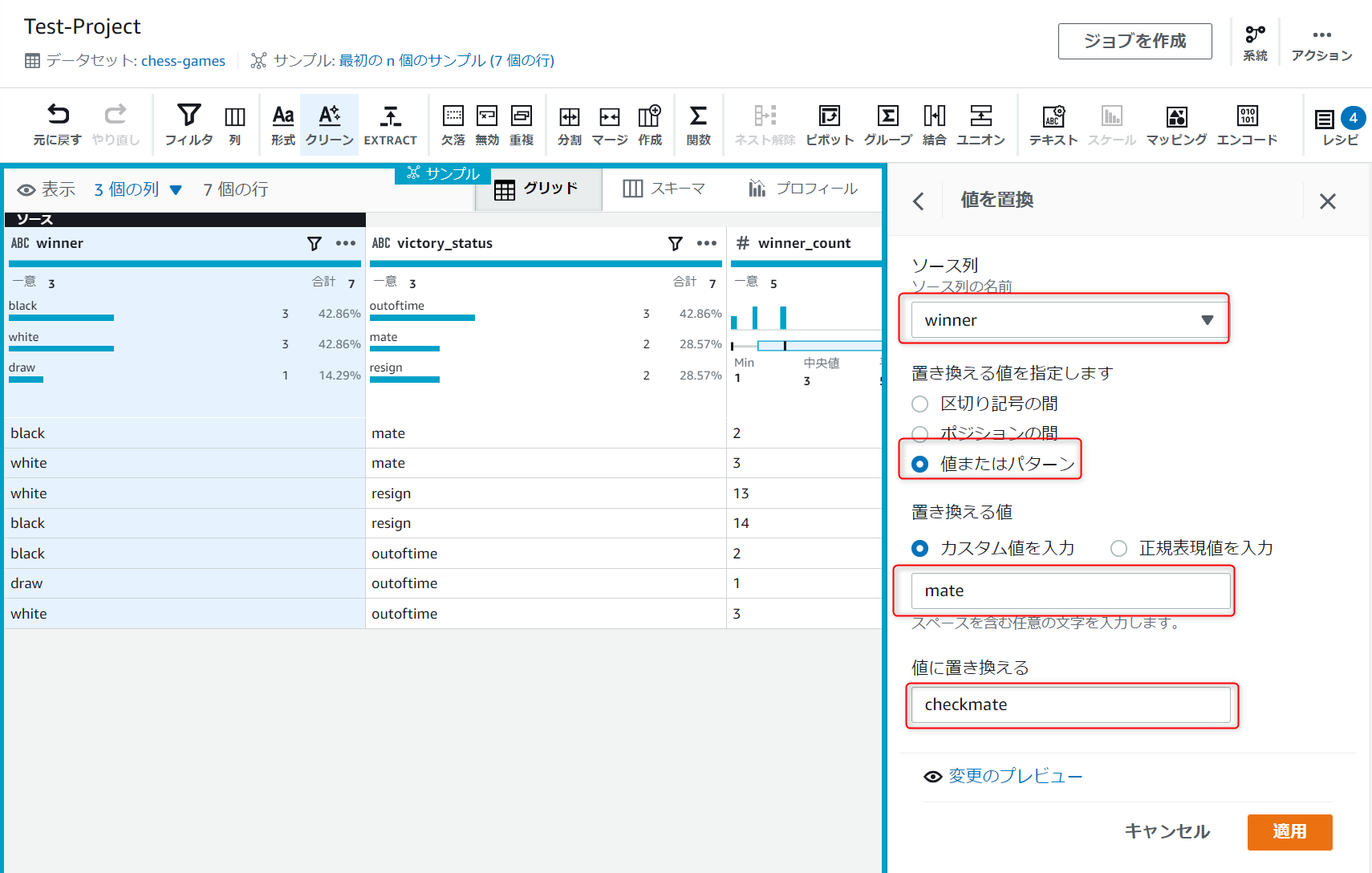
同じ手順で他の値も置換設定します。
※後で気づきましたがソース列はwinnerではなくてvictory_statusが正しいです
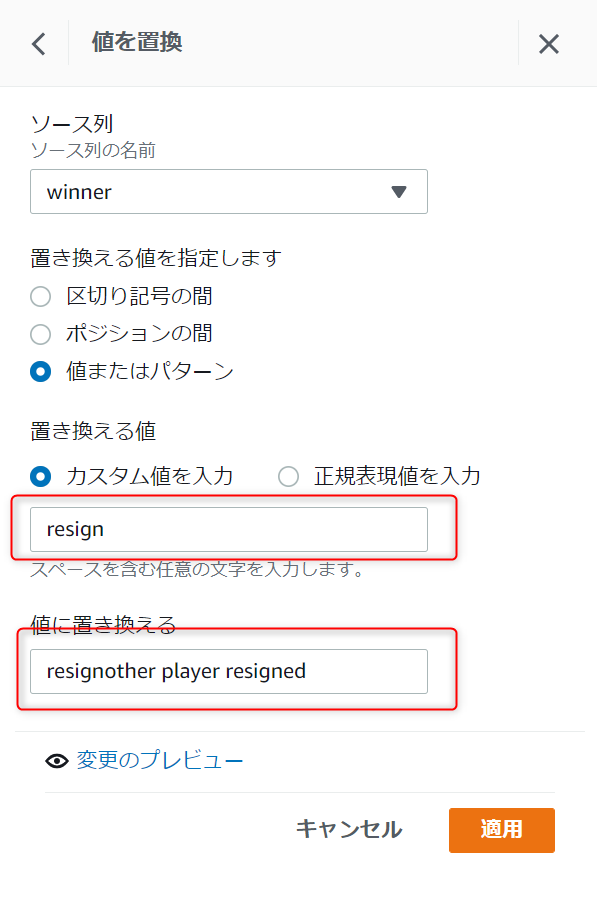
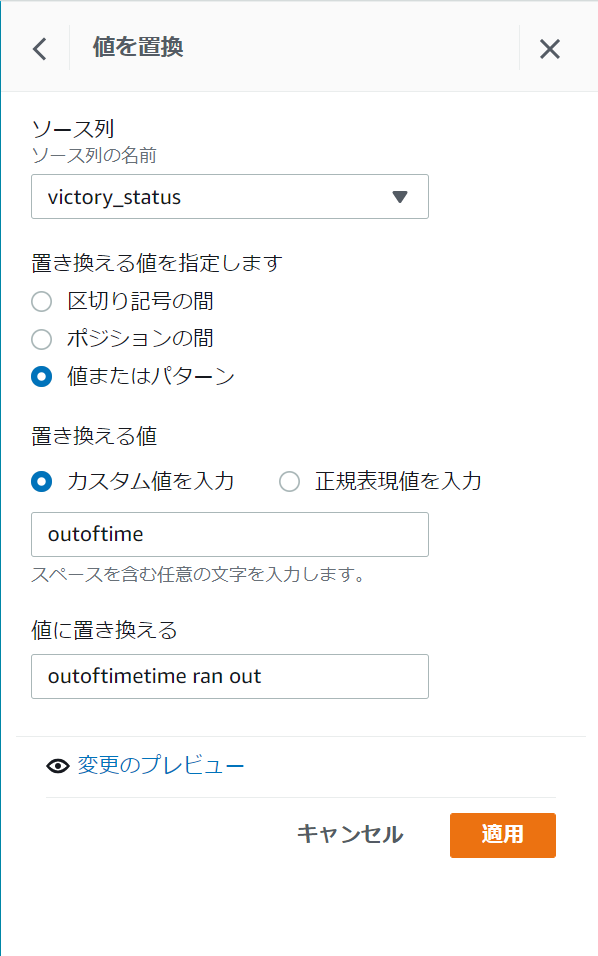
変換されていることが確認出来たらレシピの発行ボタンから変更を保存します。
DataBrewリソース確認
作成したDataBrewリソースを確認していきます。
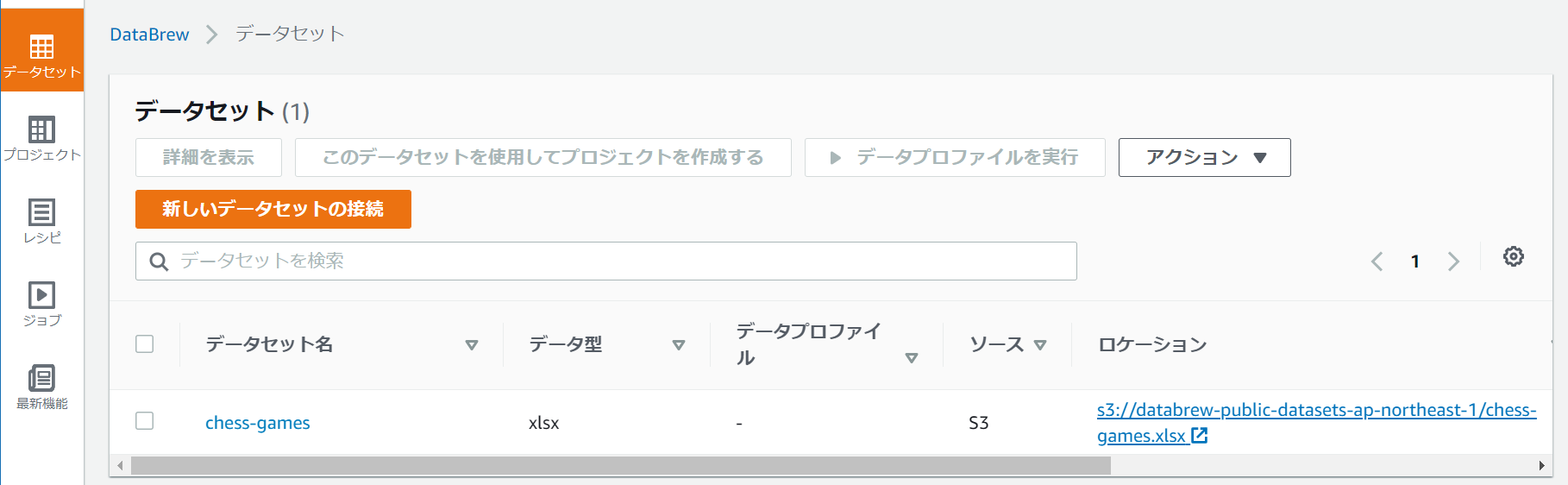
データセットを選択します。
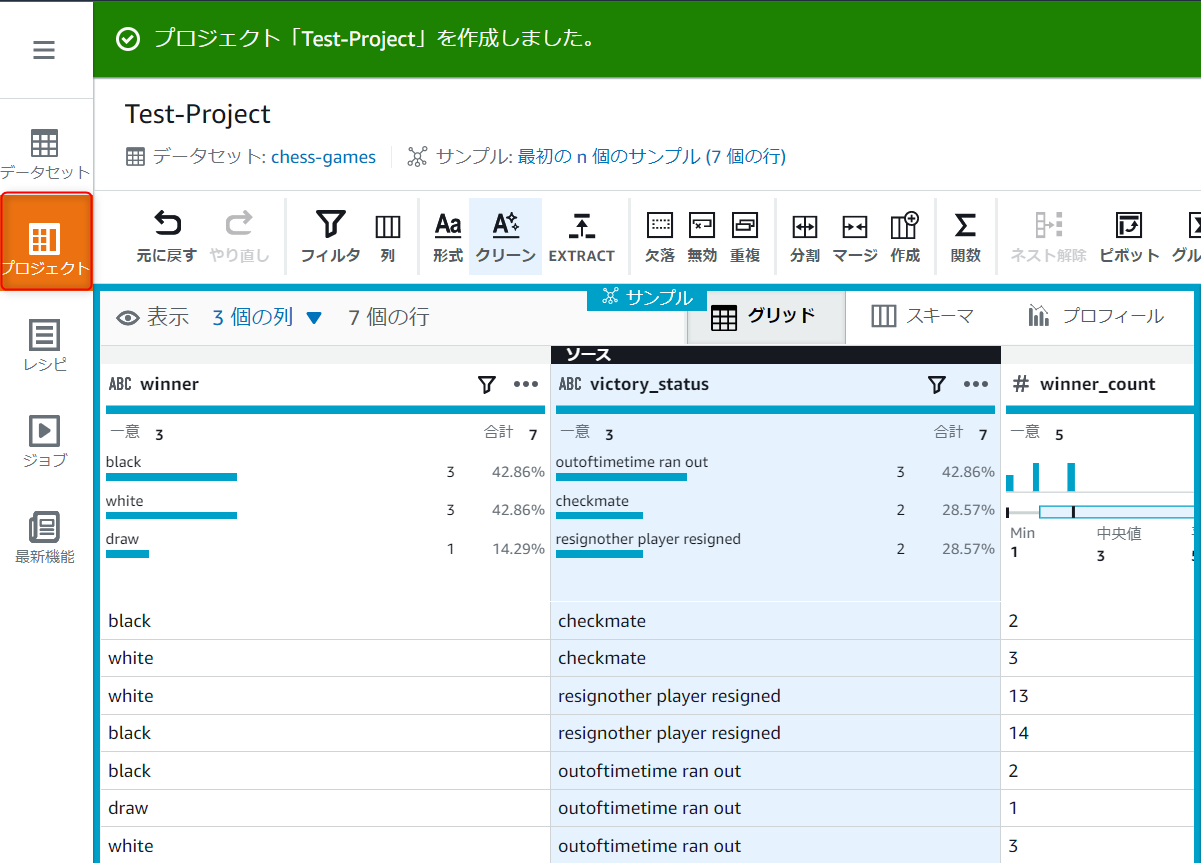
データセットにはサンプルプロジェクトで作成されたデータセットが確認できます。
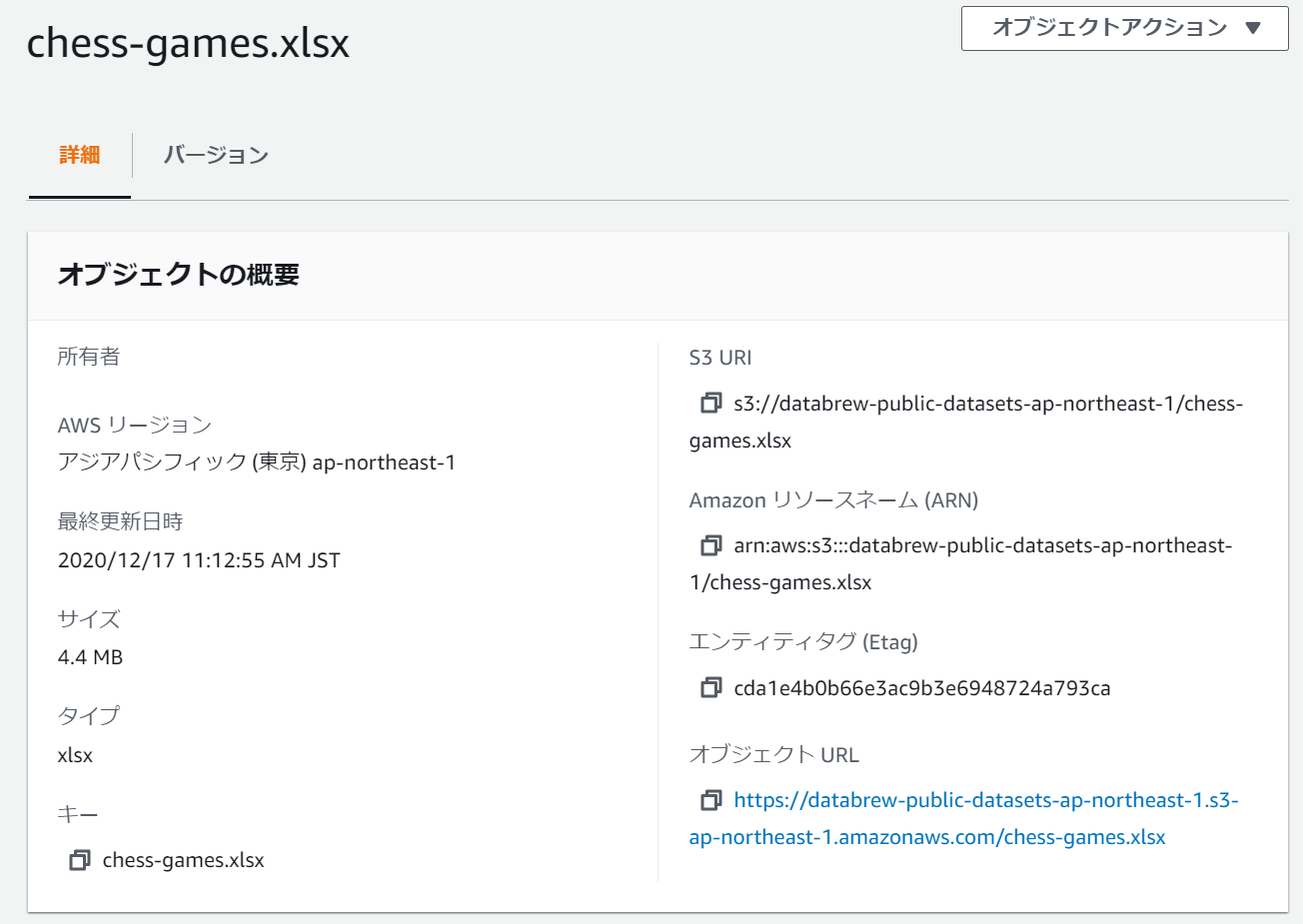
元となるデータはS3に保存されているエクセルファイルとして格納されています。
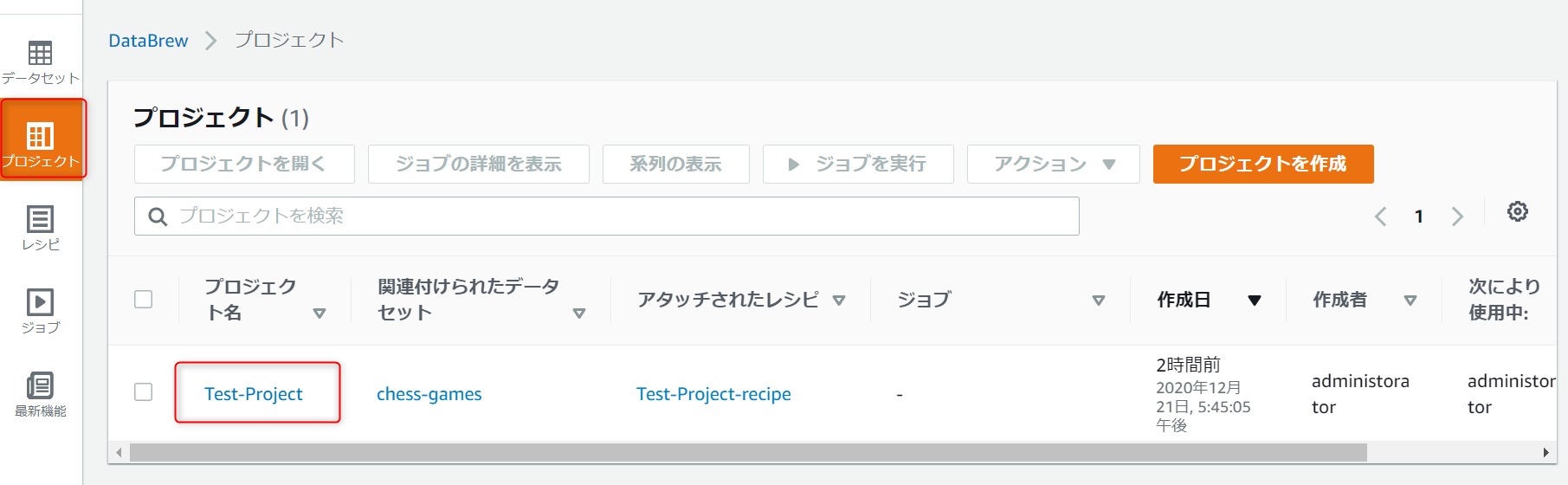
プロジェクトを選択して、先ほどレシピの設定をしていたプロジェクトがあることを確認します。
DataBrewでは、プロジェクトに対してデータセットとレシピが必須になります。
今回はサンプルプロジェクトを使用したため、データセットと空のレシピが自動で作成されています。
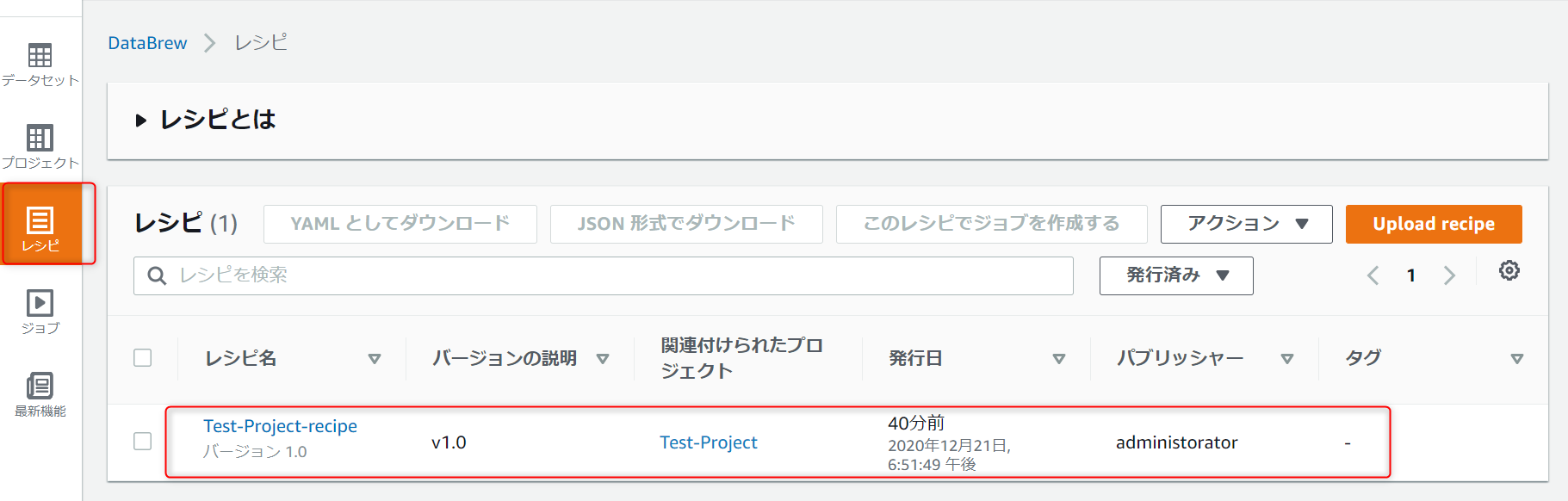
レシピを押下して、作成したレシピが表示されることを確認します。
データプロファイル作成
DataBrewではデータの統計情報をプロファイルとして表示します。
データプロファイルはジョブを作成して実行することで作成されます。
ジョブを選択して、「ジョブを作成」を押下します。
ジョブ名、ジョブタイプ、データセット、ジョブ出力先を設定します。
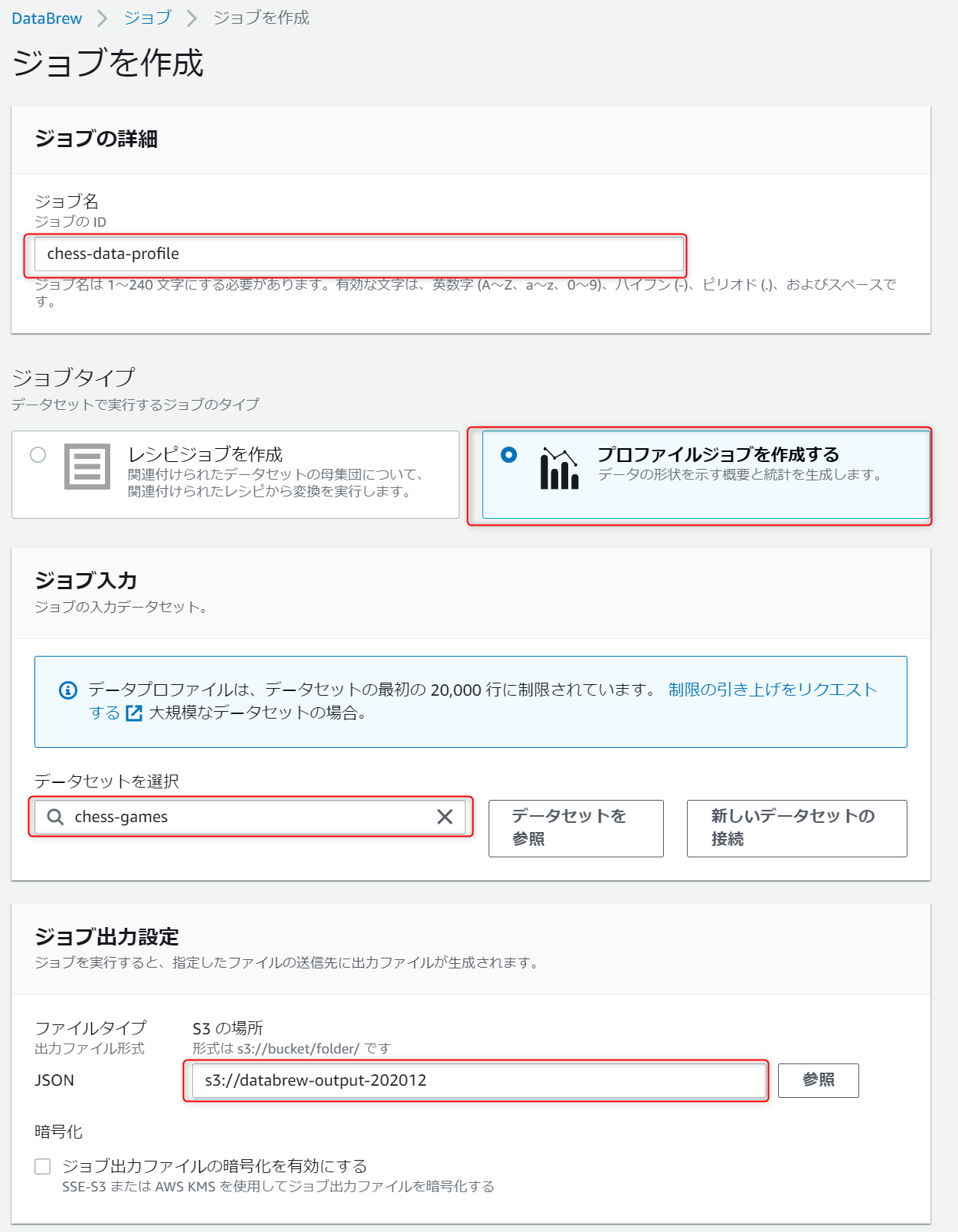
アクセス許可のロールに、DataBrewサービスからS3にアクセス可能な権限を持ったIAMロールを指定します。
ここまで入力できたら設定できたら「ジョブを作成し実行する」を押下します。
ジョブ実行履歴からステータスが実行中になっていることを確認します。
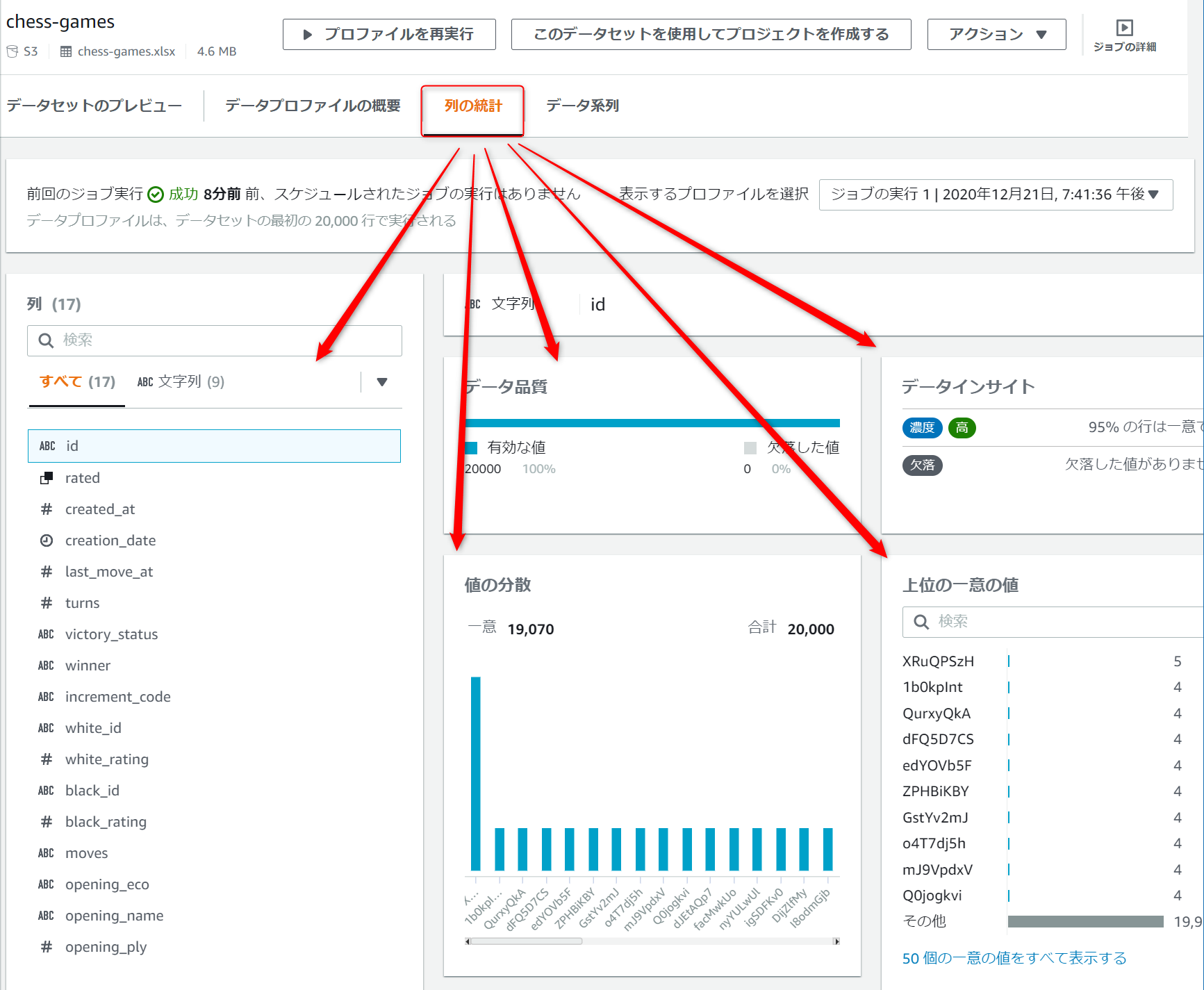
実行が完了したことを確認したら右上のプロフィールを表示アイコンを押下すると、データプロファイルが表示されます。
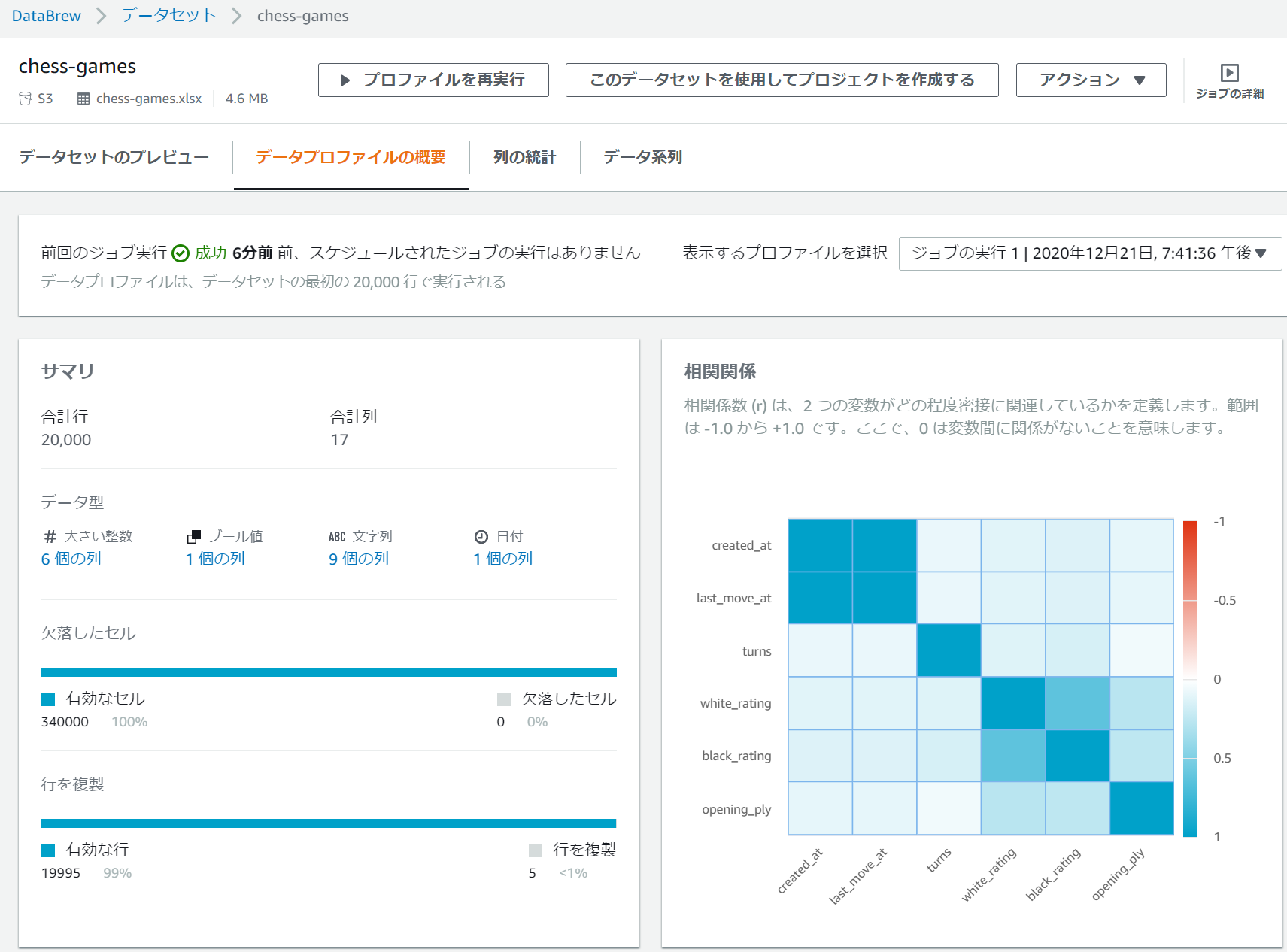
列の統計タブを表示するとデータの品質や値の分散具合、欠落データの値などのデータインサイトを見ることができます。
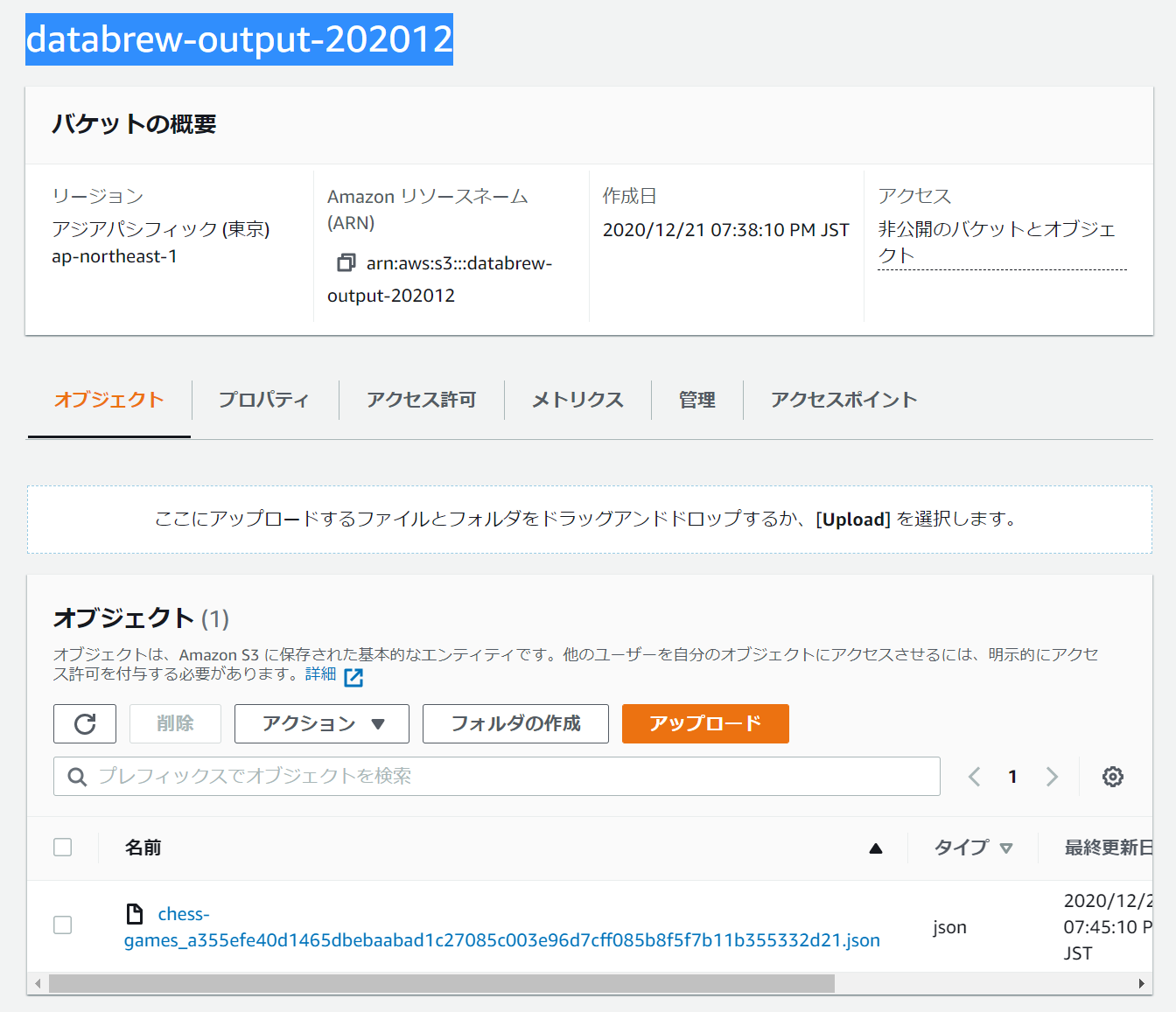
ジョブで処理されたデータはファイルとして指定してS3にアップロードされます。
おわりに
以上、サンプルプロジェクトのデータを元に、DataBrewを使用してフィルタをかけたり、統計の生成などをノーコードで実施してみました。
イマイチ使いきれていない感はありますが、データソースにDataBrewからアクセスさせることができれば、データのクリーニングやフィルタリングなどが簡単に実施することができました。
最初聞いたときは現行のGlueをノーコードで行うことができるようなイメージでしたが、実際にそれと同じレベルで設定するときはより深いサービスへの習熟が必要そうでした。