ハンドブック作った

Reactの翻訳完成率が100%になり、公式のドキュメントが日本語で読めるようになりました![]() ありがてぇ。
ありがてぇ。

紙で読みたい人のために印刷用に整形してPDFにしたので、2019/03/20時点のものはここから落とせます。
追記:PDFにしちゃえばKindleでも読めるらしい。(参考: PDFの技術書をKindleで快適に読む
)
公式のドキュメントにはAPIや使い方だけでなく、流儀や設計なども書いてあるんで、そういうところが日本語で読めるようになるのはまじであざあすでしかない。
Puppeteerを使えば、PDFで保存できるので、プリントアウトしてハンドブック的な奴をサクッと作っみたいと思います!
全体のコードはここに置いてあります!
これからはPuppeteerのevaluate()とpdf()の話しかしませんw さーせん!
他のサイトとかでやりたい人は参考になるかも?
なにはともあれ npm init
とりあえず Puppeteer があればOKなので下記を実行して、
$ npm init -y
$ npm i puppeteer
セットアップ完了。

下記の記事を参考にindex.jsを作ってPDF出力にチャレンジしてみる。
参考: ヘッドレスブラウザの Puppeteer を利用して WEB ページを PDF 出力してみる。
PuppeteerでDocsのページをクローリング
css-ではじまるセレクタの部分はすぐに変わるはずなのでソッコーで動かなくなると思いますw
とりあえず、下記の画像の場所のhrefの一覧をPuppeteerで取得して、
そのリストにアクセスしていって、page.pdf()をキメれば多分やりたいことはできるな。

とりあえずpage.evaluate()をすればPuppeteerがアクセスしたページでJSを実行してくれるっぽいのでクロームのインスペクタでセレクタ名を調べながら下記のcreateTarget関数を書いた。(使い捨てのスクリプトなので雑です。)
page.evaluate()内でのreturnはpage.evaluate()の返り値で取れるからすごい。
あと、page.evaluate()内はコンテキストが違うので、外で定義している変数にはアクセスできない。
// サイドバーの見出しからページの一覧を取得する {見出し: [ページ1, ページ2 ...]} みたいな感じで返す
const createTarget = async page => {
await page.goto("https://ja.reactjs.org/docs/getting-started.html");
return await page.evaluate(({}) => {
const contentsCss = ".css-1j8jxus";
return Array.prototype.reduce.call(
document.querySelectorAll(contentsCss),
(acc, elem) =>
Object.assign(acc, {
[elem.getElementsByTagName("div")[0]
.innerText]: Array.prototype.map.call(
elem.nextElementSibling.children,
children =>
children
.getElementsByTagName("a")[0]
.href.replace("https://ja.reactjs.org/docs/", "")
.replace(".html", "")
)
}),
{}
);
}, {});
};
したら下に、見出しがkeyでページのIDの配列がvalueのObjectが取得できるのでこれを使ってクローリングしていくっ!
{
"INSTALLATION": [
"getting-started",
"add-react-to-a-website",
"create-a-new-react-app",
"cdn-links"
]...
}
PDFの作成!でも微調整が必要。
page.pdf()を使えば今いるページをPDFにしてくれる。素直にやると下記の画像みたいな感じになる。
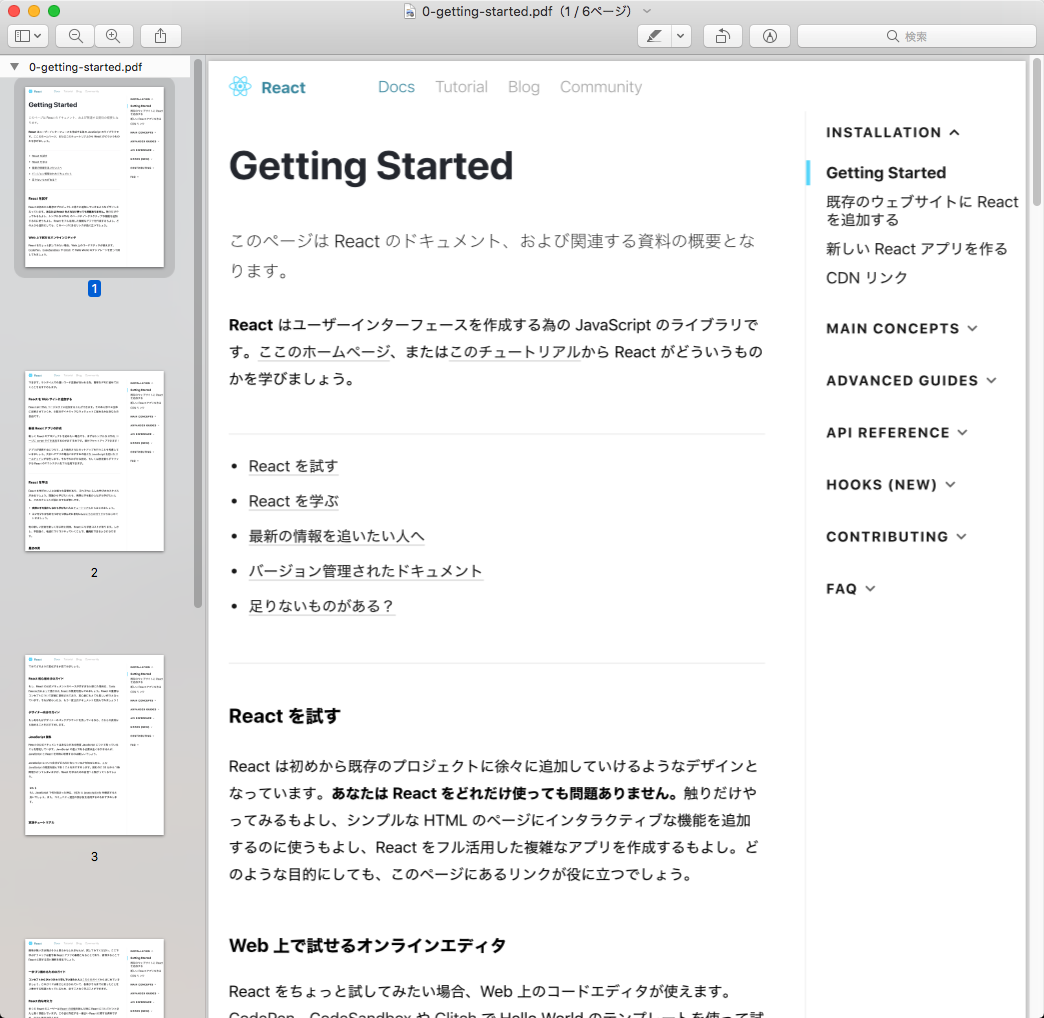

これでもいいけど、実際に印刷する前に下記の点を改善したい。
- ヘッダーがいらない
- フッターがいらない
- サイドバーがいらない(でもどこを見ているのかは見出しレベルでわかるようにしたい)
- 文字はもっと小さくしたい
- ページネーションがいらない
そこで微調整をするためにpage.pdf()にオプションを渡したり、page.evaluate()をしてstyleを変更していく!
page.pdf()にはこんな感じのオプションを設定した。
headerTemplateのプロパティにcreateTarget関数で取れる見出しの情報を見れるようにしたり、scaleプロパティで縮小表示にしたりまぁそんな感じ。
await page.pdf({
displayHeaderFooter: true,
headerTemplate: `<div style="font-size: 10px; margin-left: 40px;"><span>${content}</span> / <span class="title"></span></div>`,
margin: { top: 50, bottom: 50 },
scale: 0.5,
path: `pdf/${content}/${index}-${item}.pdf`
});
スタイルの微調整はこんな感じ。ヘッダー、フッター、サイドバーなどを消したり、文字の間隔を狭めたり。
await page.evaluate(({}) => {
const paginationCss = ".css-uygc5k";
const sideNavCss = ".css-1kbu8hg";
const contentText = ".css-7u1i3w p";
document.getElementsByTagName("header")[0].style.display = "none";
document.getElementsByTagName("footer")[0].style.display = "none";
document.querySelector(sideNavCss).style.display = "none";
document.querySelectorAll(contentText).forEach(p => {
p.style.maxWidth = "100%";
p.style.marginTop = "0px";
});
const pagination = document.querySelector(paginationCss);
if (pagination) pagination.style.display = "none"; // ページネーションがあれば非表示
}, {});
あとはエントリーポイントを作って、実行するだけ!
$ node index.js
うん。結構、本っぽい!
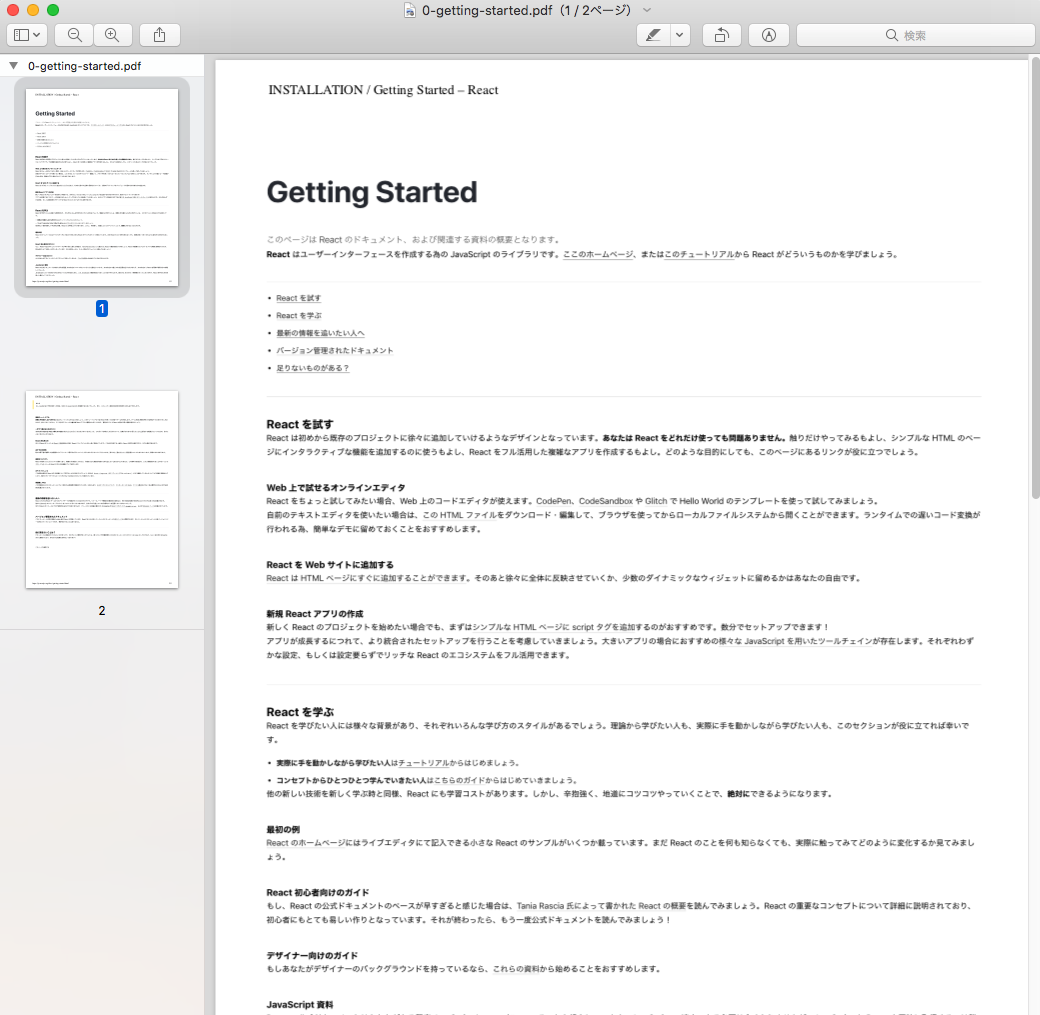
createTarget関数は見出しをキーにして各コンテンツを配列で返しているので下記の画像みたいにディレクトリに別れて出力している。
実行結果はこんな感じ。

実行可能な全体のコードは全体のコードはここに置いてあります!
プリントアウトして本にする
今回はADVANCED GUIDESが読みたいなと思っていたので、これをPDF結合します。
Webで「PDF結合」とか調べると、下記がヒットしたのでそれを使って結合していきます。
https://smallpdf.com/jp/merge-pdf
83pのPDFができました。

さあてネットプリントのクラウドにアップロードしたしコンビニに行って印刷してきますか!
コンビニ高かったんで(1枚 20円)、kinkos(1枚 8円)に行ってやった。
感想
- 寝る前にソファーで読んだりしてる。いい。
- kindleでも読みたいという人の意見もあった。できるっぽい。( PDFの技術書をKindleで快適に読む)
- 久しぶりにdomを触ったら懐かしくもやはり辛かった。
- ただのPuppeteerを使った話になってしまった :-)