AIの話に割り込めない
AIと話していると、どうしても「今のは違うよ!」って途中で言いたくなる瞬間、ありますよね。でも、AIは一度話し始めると延々と話し続け、途中で割り込むことができません。これって人間との会話とは大きく異なる点です。人間同士の会話なら、話を遮ったり、途中でツッコミを入れるのは普通ですからね。

どうすりゃいいの?
じゃあ、どうやってこの「割り込みたい」問題を解消するか?以下のような方法が思い付きます。
1. 音声会話型のLLMを活用
最近では、音声で会話できるLLM(大規模言語モデル)が増えてきています。これらは、途中でユーザーが割り込むことを想定して設計されています。
- OpenAI Advanced Voice
- Google Gemini Live
- その他にも、音声会話をスムーズに行えるモデルが次々と登場しています。
2. 話者認識付きのSTT(音声テキスト変換)
話者認識機能を持ったSTTを使えば、誰が話しているのかを正確に識別できるので、ユーザーが途中で割り込んでも、AIがすぐに認識して応答することができます。
- Google Speech や各社のサービス
- Pythonのライブラリにも使えそうなのがあります
ただし、これらは、会議の書き起こしなど、ある程度の量の音声データを解析するような使い方が主流で、リアルタイムな会話に使うには難しそうです。
3. エコーキャンセルを活用
オンライン会議システムやスピーカーフォンでは、エコーキャンセルの機能が組み込まれて、リアルタイムでの会話がスムーズに行えるようになっています。
リアルタイムな処理のために、DSPなどのハードウエアで処理していることが多いです。
がんばればpythonでも実装できるかも?
エコーキャンセルを試してみる
LMSフィルタの適用
さて、実際にエコーキャンセルをどう行うかについてです。基本的には、多くのオンラインリソースで紹介されている方法を参考に、LMS(Least Mean Squares)適用フィルタを利用します。このフィルタは、計算が比較的軽く、リアルタイムの音声処理に適しています。
NLMSアルゴリズムの数式
LMSの改良版として有名な**NLMS(Normalized LMS)**の数式を簡単に紹介します。
w(n+1) = w(n) + μ * x(n) * e(n) / ||x(n)||^2
- w(n): フィルタの重みベクトル
- x(n): 入力信号
- e(n): 誤差信号(d(n) - y(n))
- μ: ステップサイズ(0 < μ <= 1)
- ||x(n)||^2: 入力信号のエネルギーで正規化
この数式によって、フィルタの重みが更新され、エコーを徐々に打ち消していく仕組みです。
数式は得意でないので詳しくは、各自調べてください。
参照信号(スピーカ音声)をどうする?
適用フィルタの処理には、マイク録音音声と、スピーカ音声が必要です。通常であれば、二つのマイクで同時録音するはずですが、一般的なPCにはマイクは一つだけ。
そこで、再生する音声データそのものを使ってみます。つまり、音声合成した音声データ配列をそのまま使います。
音の先頭はどこですか???
適用フィルタを使うためには、音の先頭を一致させる必要があります。
マイクの音とスピーカーの音の先頭が狂っていると、関係ない箇所のデータでフィルタの重みを計算することになるので、めちゃくちゃな音ができあがります(たぶん)。
つまり、pythonで再生した音は、いつマイクで録音されるのか??これを可能なかぎり正確に把握する必要があります。
まずは、sounddeviceを使って、目標音(440Hzと880Hzの合成音、0.2秒)を再生し、マイクでの録音される時間を測定しました。LinuxやMacBookでそれぞれ次のような結果が得られました:
- Linux: 0.8〜1.2秒
- MacBook: 0.5〜0.6秒
どうしてこんなに時間がかかるの?
pythonで再生の関数をコールした瞬間にスピーカーから音がでれば良いのですが、そんなことはありません。実際には、pythonのライブラリ、OSのライブラリ・ドライバ、ハードウエアを経由するので時間がかかっていると思います。

LMS適用フィルタの係数の幅はどれくらい必要?
フィルタの係数の幅は、短かければ計算が軽くなりますが効果が低くなりそうです。反対に長くすれば計算が増えてリアルタイムな処理ができなくなります。
どれくらいの幅が必要か見積もってみました。
スピーカーから直接マイクに音が到達する場合
音の速度は約340 m/secです。スピーカーからマイクまでの距離が30cmの場合、音が到達するまでにかかる時間は約0.8msです。これをサンプリングレート16kHzで考えると、約14サンプルの遅延が生じます。
部屋の壁に反射してマイクに音が入る場合
反射して返ってくる距離が8mの場合、音が到達するまでにかかる時間は約23msです。16kHzでサンプル数に換算すると、約376サンプルの遅延となります。

エコーキャンセルの結果
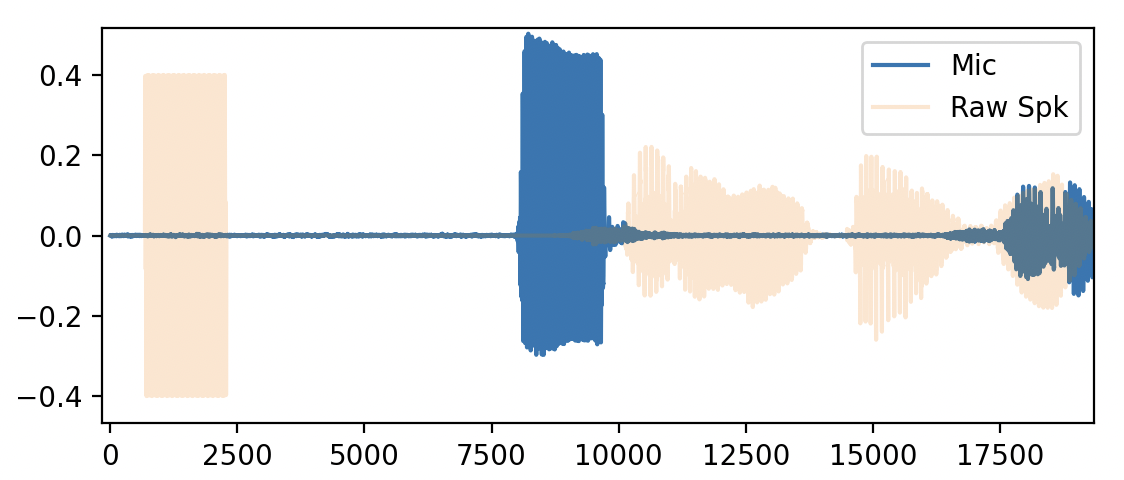
実際にNLMSフィルタを使ってエコーキャンセルを行ってみた結果をお見せします。
- 図2: エコーキャンセルを適用した後のマイクの波形と再生音声の波形を重ねたプロット

結果として、エコーは1/3〜1/4程度軽減されました。しかし、音声認識モデル(WhisperやGoogle Speech)は非常に強力で、この程度のエコー軽減では音声認識されてしまいます。
最後に
今回の実験で、LMSフィルタによるエコーキャンセルがある程度効果を発揮することが確認できましたが、完璧な結果にはまだ至りませんでした。特に、WhisperやGoogle Speechのような高度な音声認識システムに対しては、さらなる調整やアルゴリズムの改良が必要です。
しかし、フィルタ係数やアルゴリズムをさらに最適化することで、リアルタイムでの音声会話AIの実現に近づける可能性は十分にあります。今後も引き続き、この領域での改善と研究を続けていく価値があると感じています。