はじめに
こんにちは、はなたです。私は情報系学部の修士1年生で、様々なデータの確率分布について調査しております。
今はデータの対象を絞らずに、ひたすらデータを集めている状況であります。
今日はFilmarksという映画レビューサイトから、映画のレビュースコアを取得してみようと思います。
処理の流れ
スクレイピングの対象となるデータ数が多いので、以下のような流れでデータを取得します。
その後でデータをいじくり回します。
- ジャンルごとの映画一覧ページをクローリング(htmlをダウンロード)
1-1. トップページからジャンルとそのURLを取得
1-2. ジャンルの映画一覧ページから、そのジャンルの最大ページ数を取得
1-3. ジャンルの映画一覧ページをすべてダウンロードする - 保存したhtmlからスコアの情報を抜き取る(スクレイピング)
2-1. [ジャンル名, スコア]のリストを作成する
2-1. csvに出力する - 平均スコアを求める
1.クローリング
1-1. トップページからジャンルとそのURLを取得する

トップページの下部にある、この部分から各ジャンルのURLを取得します。
この部分がどんなhtmlになっているか、確認してみましょう。

どうやらul属性でクラスは c-list-line ということが分かりました。取得してみましょう。
from bs4 import BeautifulSoup
import requests
# トップページurl
base_url = 'https://filmarks.com'
r = requests.get(base_url)
soup = BeautifulSoup(r.text, 'lxml')
# c-list-lineを全て取得
c_list_line = soup.find_all('ul', class_='c-list-line')
print(len(c_list_line))
### 出力
17
どうやら同じクラスのものが17個存在します。しかし17個しかないので、目視で確認していくと、後ろから2番目のやつが目的のものと判明しました。
次に各ジャンルのURLを取得します。

ジャンルのURLとジャンル名は、先程取得したc-list-lineの中のa属性から取得できそうです。というわけで、ジャンル名とジャンルのURLを以下のようにして取得します。
# ジャンルの情報が入っているのは後ろから2番目のやつだった
genre = soup.find_all('ul', class_='c-list-line')[-2]
# a属性をすべて取得
genre_links = genre.find_all('a')
# ジャンル名:URL となる辞書を作成する
genre_link_dic = {}
for link in genre_links:
url = base_url + link.get('href')
name = link.text
genre_link_dic[name] = url # 辞書に追加
print(genre_link_dic)
### 出力
{'アニメ': 'https://filmarks.com/list/genre/61', 'ドラマ': 'https://filmarks.com/list/genre/8', '恋愛': 'https://filmarks.com/list/genre/25', 'ホラー': 'https://filmarks.com/list/genre/17', '戦争': 'https:/' ...}
これにて各ジャンルのURLを求めることができました!
1-2.ジャンルの映画一覧ページから、そのジャンルの最大ページ数を取得
各ジャンルの最大ページ数を取得します。ページネーション部分のソースを見てみましょう。
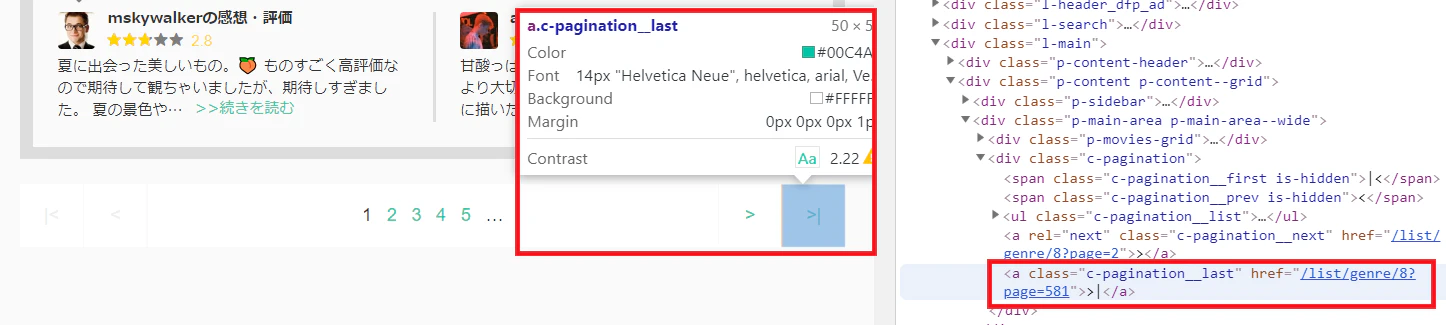
a属性のc-pagination__lastに最終ページのリンクが含まれています。このhrefの値**「/list/genre/8?page=581」**の末尾を切り出せば良さそうです!
切り出し方ですが
・「/list/genre/8?page=581」という文字列を「=」で分割(['/list/genre/8?page', '581']というリストができる)
・リストの末尾にアクセス
で取り出せます。
試しにドラマの最大ページ数を取得してみます。
# ドラマの映画一覧URL
url = 'https://filmarks.com/list/genre/8'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
# ページネーション部分の抽出
pgnation = soup.find('a', class_='c-pagination__last')
# 最大ページを抽出
max_page = pgnation.get('href').split('=')[-1]
print(max_page)
### 出力
'581'
正しく抽出できています!いよいよhtmlのダウンロードに取り掛かります。
1-3.ジャンルの映画一覧ページをすべてダウンロードする
先にコードを書いちゃいます。
# ジャンルごと処理
for g in genre_link_dic:
# 保存するディレクトリを作成 例:/html/アニメ
save_dir = html_dir + g
os.makedirs(save_dir, exist_ok=True)
# ジャンルの映画一覧ページのsoupを取得
g_url = genre_link_dic[g]
g_r = requests.get(g_url)
g_soup = BeautifulSoup(g_r.text, 'lxml')
# 最大ページ数を求める
pgnation = g_soup.find('a', class_='c-pagination__last')
max_page = int(pgnation.get('href').split('=')[-1])
# すべてのページをダウンロードする
for p in tqdm(range(1, max_page+1)):
p_url = g_url + '?page=' + str(p) # 各ページのurl作成
urllib.request.urlretrieve(p_url, '{}/{}.html'.format(save_dir, p))
time.sleep(1) # お約束
ジャンルとページでfor文を回します。スクレイピング、クローリングでよくある流れですね。
2.スクレイピング
スコアの情報を抜き出していきます。
2-1. [ジャンル名, スコア]のリストを作成する
import glob
# 各ジャンルのディレクトリを取得
all_genre = glob.glob('html/*')
# スコア保存用
ans = []
# ジャンルごと処理
for g in all_genre:
# ジャンル名取得
g_name = g.split('\\')[-1]
# ジャンルのhtml一覧を取得
html_files = glob.glob(g + '/*.html')
# htmlファイルごと処理
for html in tqdm(html_files):
# with文でhtmlファイルを開いてsoupへ
with open(html, 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
# スコアが書いてある箇所
scores = soup.find_all('div', class_='c-rating__score')
# スコアが - のものが存在するので場合分け
for s in scores:
score_text = s.text
if score_text != '-':
score_num = float(s.text)
else:
score_num = '-'
ans.append([g_name, score_num]) # ['SF', '3.6']みたいな感じ
保存してあるhtmlファイルについて、ジャンルごとにスコアを取得していきます。
取得したスコアは、ジャンル名と一緒にリストにして、ansというリストにぶち込んでいきます。
2-2. csvに出力する
2-1で作成したansをcsvに出力します。リストをそのままcsvに出力しても良いのですが、どうせそのままpandasで色々処理を行うので、一旦データフレームに変換してから、csvに出力します。
import pandas as pd
df = pd.DataFrame(ans, columns=['genre', 'score'])
df.to_csv('eiga.csv', index=False, header=True, encoding='shift-jis')
文字化け対策のため、文字コードはshift-jisを指定します。
これにて必要なデータを得ることができました!このデータを使用して、各ジャンルのスコア平均値を求めてみます。
3. 平均スコアを求める
まずは scoreが「-」になっているものを除きます。そしてscoreをfloatに型変換し直します(groupbyしようとしたときにエラーが発生してしまったため)
df_ex = df[df['score'] != '-']
df_ex['score'] = df_ex['score'].astype(float)
各ジャンルの平均を見たいので、ジャンルでgroupbyします。そして平均と映画の個数を求めて出力します。
df_group = df_ex.groupby('genre')
df_group.agg(['mean', 'count']).sort_values(('score', 'mean'), ascending=False)
| score | ||
|---|---|---|
| mean | count | |
| genre | ||
| ギャング・マフィア | 3.872381 | 105 |
| 音楽 | 3.809592 | 417 |
| ミュージカル | 3.800737 | 407 |
| スポーツ | 3.675065 | 385 |
| 西部劇 | 3.673846 | 195 |
| 伝記 | 3.639474 | 76 |
| ドキュメンタリー | 3.637195 | 2374 |
| 歴史 | 3.636250 | 80 |
| バイオレンス | 3.577612 | 134 |
| ドラマ | 3.531678 | 26763 |
| 時代劇 | 3.491311 | 656 |
| ファミリー | 3.481495 | 2248 |
| 恋愛 | 3.479487 | 1092 |
| アニメ | 3.476867 | 3147 |
| 戦争 | 3.476355 | 203 |
| クライム | 3.470355 | 479 |
| ミステリー | 3.427027 | 333 |
| ショートフィルム・短編 | 3.422644 | 923 |
| ファンタジー | 3.417634 | 448 |
| アドベンチャー・冒険 | 3.412871 | 808 |
| コメディ | 3.412770 | 4581 |
| 青春 | 3.408247 | 388 |
| オムニバス | 3.343333 | 90 |
| アクション | 3.224086 | 10500 |
| ヤクザ・任侠 | 3.215000 | 260 |
| スリラー | 3.200505 | 792 |
| サスペンス | 3.191709 | 2919 |
| SF | 3.179545 | 836 |
| ホラー | 2.969572 | 4933 |
| パニック | 2.928571 | 238 |
ギャング・マフィアが一番平均スコアが高いという結果に!なんだか以外ですね。
ただし、映画の数がジャンルごとに大きなバラツキがあるので、ギャング・マフィアが一番おもしろいかどうかは断定できません。
ホラーが下から2番目なのも以外ですね。夏の風物詩と思っていたのですが、実はあまり人気がないのでしょうか。
おわりに
Filmarksをクローリング・スクレイピングして、各ジャンルの平均スコアを求めてみました。
もちろん平均スコアだけで各ジャンルの優劣を決めるのはナンセンスですが、意外と面白い結果が出てきたなと思いました。
次回は平均スコアだけでなく、色々な統計特徴量を見たり、分布を可視化するなどして、データの性質を詳しく見ていけたらなと思います。