はじめに
最近、以下の本を使って機械学習プログラミングの勉強をしています。
Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
第2章では、教師あり学習の各種アルゴリズムが紹介されています。
せっかくなので、ここに掲載されている各アルゴリズムを試してみたいなと思ったので、その記録を記事にしていきます。
※めっちゃハイスコア出したる!ってわけではなく、とりあえず自分で手を動かして機械学習を試してみるってのが今回の目的です。
今回は 線形サポートベクターマシン でやってみます。
使用するデータ
超有名な「Kaggleのタイタニック号生存予測」を題材にします。データはここから入手できます。
訓練用データとテスト用データが分かれて提供されております。
データ概要
訓練データ(train.csv)
import pandas as pd
data = pd.read_csv('train.csv')
display(data.head())
display(data.describe())
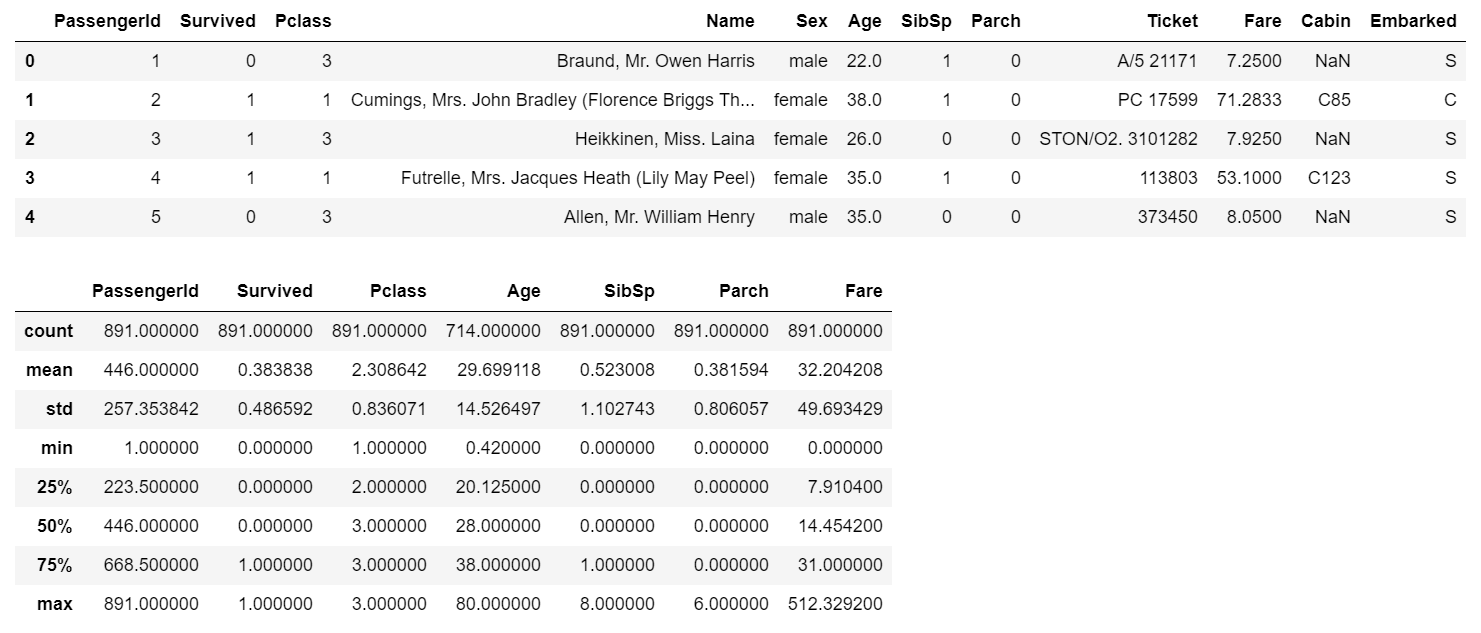
各カラムのnullの個数とデータサイズ
Cabinはほとんどがnullですね。Ageは約20%がnullです。
テストデータ(test.csv)
test = pd.read_csv('titanic/test.csv')
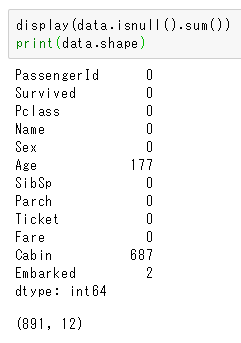
test.isnull().sum()
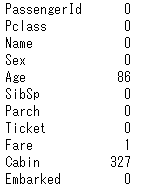
訓練データと同様、Cabinがめっちゃ欠損してます。Ageも欠損が多いですね。
予測に用いる変数
訓練用データには特徴量が12個ありますが
- Pclass…チケットのクラス
- Sex…性別
- Age…年齢
- SibSp…タイタニックに乗船している兄弟or配偶者の数
- Parch…タイタニックに乗船している親or子供の数
- Embarked…タイタニックに乗船した港
以上の6つを使用します。SexとEmbarkedはダミー変数化します。
訓練データの前処理
欠損のあるカラムと文字列が入ったカラム(Sex,Embarked)を処理していきます。
欠損値の扱い
データ概要で見た通り、CabinとAgeとEmbarkedに欠損がありました。
今回は欠損しているデータを無視せずに、何らかの値で欠損値を埋めていきます。Cabinは予測に用いないので無視します。
Ageの欠損値を埋める
今回は 中央値 で埋めます。今後はここも工夫していきたいと思います。
data['Age'] = data['Age'].fillna(data['Age'].median())
Embarkedの欠損値を埋める
Embarkedが欠損しているレコードは以下の2つだけです。
data[data['Embarked'].isnull()]

Fareとの関連
なんとなくFareとの関連を調べてみました。Embarkedの値ごとにFareの分布を見てみます。
import seaborn as sns
fare_c = data[ data['Embarked'] == 'C']['Fare']
fare_s = data[ data['Embarked'] == 'S']['Fare']
fare_q = data[ data['Embarked'] == 'Q']['Fare']
sns.distplot(fare_s, bins=10)
sns.distplot(fare_q, bins=10)
sns.distplot(fare_c, bins=10)
S
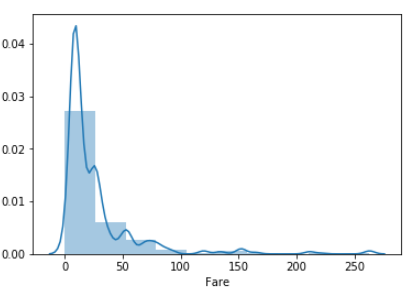
Q
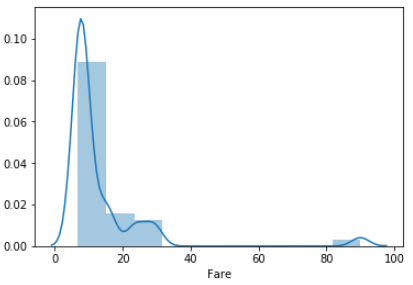
C
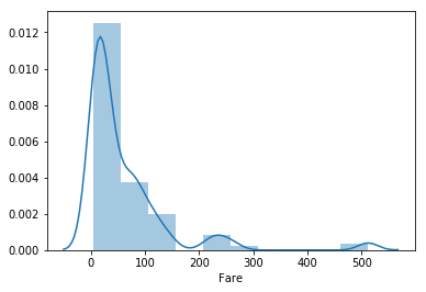
各分布を比較すると、QのFareはほとんどが40までに収まっている一方で、CはFareの最大値は500に近いです。
欠損を埋めたいレコードのFareはどっちも80。分布を見る限りQではないと判断しました。
Ticketとの関連
チケットが「113」で始まるものについて、Embarkedを見てみました。
data[ data['Ticket'].str.startswith('113') ].sort_values(by=['Ticket'])[['Ticket', 'Fare', 'Embarked']]
結果が多いので載せませんが、Sが多かったのでSにしました。いろいろと関連を見てきましたが、「中央値を採用した」と考えてください。
文字列データをダミー変数へ変換
予測で使う特徴量のうち、SexとEmbarkedは文字列なので、ダミー変数に変換します。
data = pd.get_dummies(data, drop_first=True, columns=['Sex', 'Embarked'])
モデルの作成
前処理が終わったので、訓練データを用いてモデルを作成していきます。今回は 線形サポートベクターマシン(以下線形SVM)です。
パラメータの設定
sklearnのLinearSVCを利用、パラメータCをいじります。デフォルトはC=1です。
今回は交差検証法でスコアを確認していきます。Cを10, 1, 0.1, 0.01, 0.001と変えてみます。
from sklearn.model_selection import cross_val_score
from sklearn.svm import LinearSVC
for param in [10, 1, 0.1, 0.01, 0.001]:
lsvc = LinearSVC(C=param)
scores = cross_val_score(lsvc, x_data, y_data, cv=5)
print('C={}'.format(param))
print(scores)
print(np.mean(scores))
print('--------------------')
C=10
[0.74301676 0.67039106 0.65730337 0.4494382 0.66101695]
0.6362332686830602
--------------------
C=1
[0.65921788 0.67597765 0.69662921 0.66853933 0.59322034]
0.6587168818070301
--------------------
C=0.1
[0.77094972 0.79329609 0.78089888 0.75842697 0.79661017]
0.7800363644488042
--------------------
C=0.01
[0.79329609 0.81005587 0.78089888 0.76404494 0.8079096 ]
0.7912410760103512
--------------------
C=0.001
[0.63687151 0.74860335 0.68539326 0.70786517 0.74576271]
0.7048991998331788
--------------------
上記を見る限り、0.01が良さげなスコアを出しているので、C=0.01でモデルを作ります!
clf = LinearSVC(C=0.01).fit(x_data, y_data)
いざ予測!
やっとここまで来ました。あとはテストデータを突っ込むだけです。
テストデータのAgeとFareにも欠損がありましたが、今回は中央値で埋めました。少し手抜きですがお許しください。
# テストデータ
test_t = test[['Pclass', 'Sex_male', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked_Q', 'Embarked_S']]
p_id = test['PassengerId']
# 予測する
y_pred = clf.predict(test_t)
# 提出用にidと予測値をくっつけてcsvに出力する。
ans = pd.concat([p_id, pd.Series(y_pred)], axis=1)
ans.to_csv('ans_linear_svc.csv', index=False, header=False)
結果
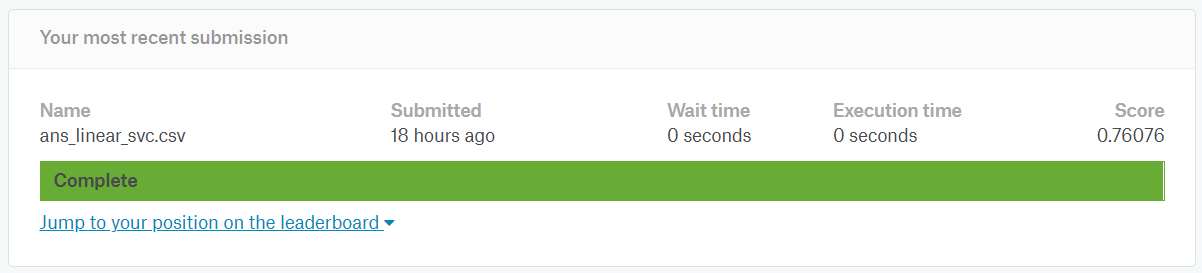
0.76076でした。以前にk近傍法を使った時よりは格段に良いです。
次回やってみたいこと。
他の機械学習モデルを使うのも良いですが、欠損値の埋め方なども工夫していきたい。
継続的に記事を書いていこうと思います。